Изучите показатели GPT-5.5, Claude Opus 4.7, Kimi K2.6 и DeepSeek V4 в бенчмарках. Пожалуйста, сделайте отчёт удобным для чтения.
Я нашёл сопоставимые данные не по всем четырём моделям в одном и том же независимом тестовом прогоне. Поэтому ниже — аккуратная сводка: GPT 5.5, Claude Opus 4.7 и DeepSeek V4 Pro Max сравниваются по одной опубликованн...
Я нашёл сопоставимые данные не по всем четырём моделям в одном и том же независимом тестовом прогоне. Поэтому ниже — аккуратная сводка: GPT 5.5, Claude Opus 4.7 и DeepSeek V4 Pro Max сравниваются по одной опубликованной таблице, а Kimi K2.6 добавлен по отдельной карточке модели; прямое сравнение с Kimi нужно считать ор
Key takeaways
- Claude Opus 4.7 выглядит сильнейшим в GPQA Diamond: 94.2% против 93.6% у GPT-5.5 и 90.1% у DeepSeek-V4-Pro-Max.
- Claude Opus 4.7 также лидирует в Humanity’s Last Exam без инструментов: 46.9% против 41.4% у GPT-5.5, 43.1% у GPT-5.5 Pro и 37.7% у DeepSeek-V4-Pro-Max.
- GPT-5.5 Pro лидирует в Humanity’s Last Exam с инструментами: 57.2% против 54.7% у Claude Opus 4.7, 52.2% у GPT-5.5 и 48.2% у DeepSeek-V4-Pro-Max.
- GPT-5.5 заметно впереди в Terminal-Bench 2.0: 82.7% против 69.4% у Claude Opus 4.7, 67.9% у DeepSeek-V4-Pro-Max и 66.7% у Kimi K2.6.
- Я нашёл сопоставимые данные не по всем четырём моделям в одном и том же независимом тестовом прогоне. Поэтому ниже — аккуратная сводка: GPT-5.5, Claude Opus 4.7 и DeepSeek-V4-Pro-Max сравниваются по одной опубликованной таблице, а Kimi K2.6 добавлен по отдельной карточке модели;
- ## Key findings
Research answer
Я нашёл сопоставимые данные не по всем четырём моделям в одном и том же независимом тестовом прогоне. Поэтому ниже — аккуратная сводка: GPT-5.5, Claude Opus 4.7 и DeepSeek-V4-Pro-Max сравниваются по одной опубликованной таблице, а Kimi K2.6 добавлен по отдельной карточке модели; прямое сравнение с Kimi нужно считать ориентировочным, а не строго «один к одному» [9][
15].
Key findings
-
Claude Opus 4.7 выглядит сильнейшим в GPQA Diamond: 94.2% против 93.6% у GPT-5.5 и 90.1% у DeepSeek-V4-Pro-Max [
9].
-
Claude Opus 4.7 также лидирует в Humanity’s Last Exam без инструментов: 46.9% против 41.4% у GPT-5.5, 43.1% у GPT-5.5 Pro и 37.7% у DeepSeek-V4-Pro-Max [
9].
-
GPT-5.5 Pro лидирует в Humanity’s Last Exam с инструментами: 57.2% против 54.7% у Claude Opus 4.7, 52.2% у GPT-5.5 и 48.2% у DeepSeek-V4-Pro-Max [
9].
-
GPT-5.5 заметно впереди в Terminal-Bench 2.0: 82.7% против 69.4% у Claude Opus 4.7, 67.9% у DeepSeek-V4-Pro-Max и 66.7% у Kimi K2.6 [
9][
15].
-
Kimi K2.6 выглядит очень сильной открытой/доступной по весам моделью для coding-бенчмарков: карточка модели указывает 80.2 на SWE-Bench Verified, 58.6 на SWE-Bench Pro, 76.7 на SWE-Bench Multilingual и 66.7 на Terminal-Bench 2.0 [
15].
-
DeepSeek-V4-Pro-Max в найденной таблице стабильно ниже GPT-5.5 и Claude Opus 4.7 по GPQA, HLE и Terminal-Bench 2.0, но остаётся близко к Claude в Terminal-Bench 2.0: 67.9% против 69.4% [
9].
Сводная таблица
| Бенчмарк | GPT-5.5 | GPT-5.5 Pro | Claude Opus 4.7 | DeepSeek-V4-Pro-Max | Kimi K2.6 | Кто впереди |
|---|---|---|---|---|---|---|
| GPQA Diamond | 93.6% [ | н/д | 94.2% [ | 90.1% [ | н/д | Claude Opus 4.7 |
| Humanity’s Last Exam, без инструментов | 41.4% [ | 43.1% [ | 46.9% [ | 37.7% [ | н/д | Claude Opus 4.7 |
| Humanity’s Last Exam, с инструментами | 52.2% [ | 57.2% [ | 54.7% [ | 48.2% [ | н/д | GPT-5.5 Pro |
| Terminal-Bench 2.0 | 82.7% [ | н/д | 69.4% [ | 67.9% [ | 66.7 [ | GPT-5.5 |
| SWE-Bench Verified | н/д | н/д | н/д | н/д | 80.2 [ | недостаточно данных |
| SWE-Bench Pro | н/д | н/д | н/д | н/д | 58.6 [ | недостаточно данных |
| SWE-Bench Multilingual | н/д | н/д | н/д | н/д | 76.7 [ | недостаточно данных |
По моделям
GPT-5.5
-
GPT-5.5 показывает лучший найденный результат в Terminal-Bench 2.0 среди сопоставленных моделей: 82.7% [
9].
-
GPT-5.5 уступает Claude Opus 4.7 в GPQA Diamond: 93.6% против 94.2% [
9].
-
GPT-5.5 уступает Claude Opus 4.7 в Humanity’s Last Exam без инструментов: 41.4% против 46.9% [
9].
-
GPT-5.5 Pro, отдельный более сильный режим/вариант в найденной таблице, выходит на первое место в HLE с инструментами: 57.2% [
9].
Claude Opus 4.7
-
Claude Opus 4.7 — лидер по GPQA Diamond среди моделей в найденной таблице: 94.2% [
9].
-
Claude Opus 4.7 — лидер по HLE без инструментов: 46.9% [
9].
-
Claude Opus 4.7 занимает второе место в HLE с инструментами после GPT-5.5 Pro: 54.7% против 57.2% [
9].
-
В Terminal-Bench 2.0 Claude Opus 4.7 значительно уступает GPT-5.5: 69.4% против 82.7% [
9].
Kimi K2.6
-
Kimi K2.6 имеет сильный профиль в coding-задачах: 80.2 на SWE-Bench Verified, 58.6 на SWE-Bench Pro и 76.7 на SWE-Bench Multilingual [
15].
-
Kimi K2.6 набирает 66.7 в Terminal-Bench 2.0, что близко к DeepSeek-V4-Pro-Max 67.9 и Claude Opus 4.7 69.4, но заметно ниже GPT-5.5 82.7 [
9][
15].
-
Kimi K2.6 в найденных источниках описывается как новая сильная open-weights модель, а её карточка модели приводит отдельную таблицу результатов по coding и agentic-бенчмаркам [
14][
15].
DeepSeek V4
-
В найденной сопоставимой таблице указана именно версия DeepSeek-V4-Pro-Max, поэтому выводы по DeepSeek V4 лучше читать как выводы по этой конкретной версии, а не обязательно по всей линейке V4 [
9].
-
DeepSeek-V4-Pro-Max показывает 90.1% на GPQA Diamond, что ниже GPT-5.5 93.6% и Claude Opus 4.7 94.2% [
9].
-
DeepSeek-V4-Pro-Max показывает 37.7% на HLE без инструментов и 48.2% на HLE с инструментами, что ниже GPT-5.5, GPT-5.5 Pro и Claude Opus 4.7 в той же таблице [
9].
-
В Terminal-Bench 2.0 DeepSeek-V4-Pro-Max набирает 67.9%, что почти на уровне Claude Opus 4.7 69.4%, но существенно ниже GPT-5.5 82.7% [
9].
Evidence notes
-
Самая полезная найденная таблица сравнивает DeepSeek-V4-Pro-Max, GPT-5.5, GPT-5.5 Pro и Claude Opus 4.7 по GPQA Diamond, HLE и Terminal-Bench 2.0 [
9].
-
Для Kimi K2.6 наиболее конкретные найденные цифры идут из карточки модели: Terminal-Bench 2.0 — 66.7, SWE-Bench Pro — 58.6, SWE-Bench Multilingual — 76.7, SWE-Bench Verified — 80.2 и OSWorld-Verified — 73.1 [
15].
-
Источник по GPT-5.5 и Claude Opus 4.7 также указывает даты релиза: GPT-5.5 — 23 апреля 2026 года, Claude Opus 4.7 — 16 апреля 2026 года [
10].
Limitations / uncertainty
-
Insufficient evidence для полностью строгого сравнения всех четырёх моделей в одном независимом прогоне с одинаковыми настройками, потому что Kimi K2.6 не присутствует в основной найденной таблице вместе с GPT-5.5, Claude Opus 4.7 и DeepSeek-V4-Pro-Max [
9][
15].
-
Insufficient evidence для уверенного сравнения всех четырёх моделей по SWE-Bench Verified, потому что найденные конкретные SWE-Bench-цифры относятся к Kimi K2.6, а сопоставимые значения для GPT-5.5, Claude Opus 4.7 и DeepSeek-V4-Pro-Max в доступных фрагментах не были полно представлены [
15].
-
Результаты по DeepSeek относятся к варианту DeepSeek-V4-Pro-Max, поэтому их не следует автоматически переносить на все версии DeepSeek V4 [
9].
Summary
Если смотреть только на найденные сопоставимые бенчмарки, Claude Opus 4.7 сильнее в GPQA и HLE без инструментов, GPT-5.5/GPT-5.5 Pro сильнее в Terminal-Bench 2.0 и HLE с инструментами, а DeepSeek-V4-Pro-Max держится близко к Claude в Terminal-Bench, но уступает в reasoning-тестах [9]. Kimi K2.6 выглядит особенно интересной для coding-сценариев благодаря 80.2 на SWE-Bench Verified и 58.6 на SWE-Bench Pro, но её нельзя строго ранжировать против всех трёх остальных моделей без единого общего тестового прогона [
15].
Supporting visuals














Research conversation
Research question
Изучите показатели GPT-5.5, Claude Opus 4.7, Kimi K2.6 и DeepSeek V4 в бенчмарках. Пожалуйста, сделайте отчёт удобным для чтения.
Cited answer
Я нашёл сопоставимые данные не по всем четырём моделям в одном и том же независимом тестовом прогоне. Поэтому ниже — аккуратная сводка: GPT-5.5, Claude Opus 4.7 и DeepSeek-V4-Pro-Max сравниваются по одной опубликованной таблице, а Kimi K2.6 добавлен по отдельной карточке модели; прямое сравнение с Kimi нужно считать ориентировочным, а не строго «один к одному» [9][
15].
Key findings
-
Claude Opus 4.7 выглядит сильнейшим в GPQA Diamond: 94.2% против 93.6% у GPT-5.5 и 90.1% у DeepSeek-V4-Pro-Max [
9].
-
Claude Opus 4.7 также лидирует в Humanity’s Last Exam без инструментов: 46.9% против 41.4% у GPT-5.5, 43.1% у GPT-5.5 Pro и 37.7% у DeepSeek-V4-Pro-Max [
9].
-
GPT-5.5 Pro лидирует в Humanity’s Last Exam с инструментами: 57.2% против 54.7% у Claude Opus 4.7, 52.2% у GPT-5.5 и 48.2% у DeepSeek-V4-Pro-Max [
9].
-
GPT-5.5 заметно впереди в Terminal-Bench 2.0: 82.7% против 69.4% у Claude Opus 4.7, 67.9% у DeepSeek-V4-Pro-Max и 66.7% у Kimi K2.6 [
9][
15].
-
Kimi K2.6 выглядит очень сильной открытой/доступной по весам моделью для coding-бенчмарков: карточка модели указывает 80.2 на SWE-Bench Verified, 58.6 на SWE-Bench Pro, 76.7 на SWE-Bench Multilingual и 66.7 на Terminal-Bench 2.0 [
15].
-
DeepSeek-V4-Pro-Max в найденной таблице стабильно ниже GPT-5.5 и Claude Opus 4.7 по GPQA, HLE и Terminal-Bench 2.0, но остаётся близко к Claude в Terminal-Bench 2.0: 67.9% против 69.4% [
9].
Сводная таблица
| Бенчмарк | GPT-5.5 | GPT-5.5 Pro | Claude Opus 4.7 | DeepSeek-V4-Pro-Max | Kimi K2.6 | Кто впереди |
|---|---|---|---|---|---|---|
| GPQA Diamond | 93.6% [ | н/д | 94.2% [ | 90.1% [ | н/д | Claude Opus 4.7 |
| Humanity’s Last Exam, без инструментов | 41.4% [ | 43.1% [ | 46.9% [ | 37.7% [ | н/д | Claude Opus 4.7 |
| Humanity’s Last Exam, с инструментами | 52.2% [ | 57.2% [ | 54.7% [ | 48.2% [ | н/д | GPT-5.5 Pro |
| Terminal-Bench 2.0 | 82.7% [ | н/д | 69.4% [ | 67.9% [ | 66.7 [ | GPT-5.5 |
| SWE-Bench Verified | н/д | н/д | н/д | н/д | 80.2 [ | недостаточно данных |
| SWE-Bench Pro | н/д | н/д | н/д | н/д | 58.6 [ | недостаточно данных |
| SWE-Bench Multilingual | н/д | н/д | н/д | н/д | 76.7 [ | недостаточно данных |
По моделям
GPT-5.5
-
GPT-5.5 показывает лучший найденный результат в Terminal-Bench 2.0 среди сопоставленных моделей: 82.7% [
9].
-
GPT-5.5 уступает Claude Opus 4.7 в GPQA Diamond: 93.6% против 94.2% [
9].
-
GPT-5.5 уступает Claude Opus 4.7 в Humanity’s Last Exam без инструментов: 41.4% против 46.9% [
9].
-
GPT-5.5 Pro, отдельный более сильный режим/вариант в найденной таблице, выходит на первое место в HLE с инструментами: 57.2% [
9].
Claude Opus 4.7
-
Claude Opus 4.7 — лидер по GPQA Diamond среди моделей в найденной таблице: 94.2% [
9].
-
Claude Opus 4.7 — лидер по HLE без инструментов: 46.9% [
9].
-
Claude Opus 4.7 занимает второе место в HLE с инструментами после GPT-5.5 Pro: 54.7% против 57.2% [
9].
-
В Terminal-Bench 2.0 Claude Opus 4.7 значительно уступает GPT-5.5: 69.4% против 82.7% [
9].
Kimi K2.6
-
Kimi K2.6 имеет сильный профиль в coding-задачах: 80.2 на SWE-Bench Verified, 58.6 на SWE-Bench Pro и 76.7 на SWE-Bench Multilingual [
15].
-
Kimi K2.6 набирает 66.7 в Terminal-Bench 2.0, что близко к DeepSeek-V4-Pro-Max 67.9 и Claude Opus 4.7 69.4, но заметно ниже GPT-5.5 82.7 [
9][
15].
-
Kimi K2.6 в найденных источниках описывается как новая сильная open-weights модель, а её карточка модели приводит отдельную таблицу результатов по coding и agentic-бенчмаркам [
14][
15].
DeepSeek V4
-
В найденной сопоставимой таблице указана именно версия DeepSeek-V4-Pro-Max, поэтому выводы по DeepSeek V4 лучше читать как выводы по этой конкретной версии, а не обязательно по всей линейке V4 [
9].
-
DeepSeek-V4-Pro-Max показывает 90.1% на GPQA Diamond, что ниже GPT-5.5 93.6% и Claude Opus 4.7 94.2% [
9].
-
DeepSeek-V4-Pro-Max показывает 37.7% на HLE без инструментов и 48.2% на HLE с инструментами, что ниже GPT-5.5, GPT-5.5 Pro и Claude Opus 4.7 в той же таблице [
9].
-
В Terminal-Bench 2.0 DeepSeek-V4-Pro-Max набирает 67.9%, что почти на уровне Claude Opus 4.7 69.4%, но существенно ниже GPT-5.5 82.7% [
9].
Evidence notes
-
Самая полезная найденная таблица сравнивает DeepSeek-V4-Pro-Max, GPT-5.5, GPT-5.5 Pro и Claude Opus 4.7 по GPQA Diamond, HLE и Terminal-Bench 2.0 [
9].
-
Для Kimi K2.6 наиболее конкретные найденные цифры идут из карточки модели: Terminal-Bench 2.0 — 66.7, SWE-Bench Pro — 58.6, SWE-Bench Multilingual — 76.7, SWE-Bench Verified — 80.2 и OSWorld-Verified — 73.1 [
15].
-
Источник по GPT-5.5 и Claude Opus 4.7 также указывает даты релиза: GPT-5.5 — 23 апреля 2026 года, Claude Opus 4.7 — 16 апреля 2026 года [
10].
Limitations / uncertainty
-
Insufficient evidence для полностью строгого сравнения всех четырёх моделей в одном независимом прогоне с одинаковыми настройками, потому что Kimi K2.6 не присутствует в основной найденной таблице вместе с GPT-5.5, Claude Opus 4.7 и DeepSeek-V4-Pro-Max [
9][
15].
-
Insufficient evidence для уверенного сравнения всех четырёх моделей по SWE-Bench Verified, потому что найденные конкретные SWE-Bench-цифры относятся к Kimi K2.6, а сопоставимые значения для GPT-5.5, Claude Opus 4.7 и DeepSeek-V4-Pro-Max в доступных фрагментах не были полно представлены [
15].
-
Результаты по DeepSeek относятся к варианту DeepSeek-V4-Pro-Max, поэтому их не следует автоматически переносить на все версии DeepSeek V4 [
9].
Summary
Если смотреть только на найденные сопоставимые бенчмарки, Claude Opus 4.7 сильнее в GPQA и HLE без инструментов, GPT-5.5/GPT-5.5 Pro сильнее в Terminal-Bench 2.0 и HLE с инструментами, а DeepSeek-V4-Pro-Max держится близко к Claude в Terminal-Bench, но уступает в reasoning-тестах [9]. Kimi K2.6 выглядит особенно интересной для coding-сценариев благодаря 80.2 на SWE-Bench Verified и 58.6 на SWE-Bench Pro, но её нельзя строго ранжировать против всех трёх остальных моделей без единого общего тестового прогона [
15].
People also ask
What is the short answer to "Изучите показатели GPT-5.5, Claude Opus 4.7, Kimi K2.6 и DeepSeek V4 в бенчмарках. Пожалуйста, сделайте отчёт удобным для чтения."?
Claude Opus 4.7 выглядит сильнейшим в GPQA Diamond: 94.2% против 93.6% у GPT-5.5 и 90.1% у DeepSeek-V4-Pro-Max.
What are the key points to validate first?
Claude Opus 4.7 выглядит сильнейшим в GPQA Diamond: 94.2% против 93.6% у GPT-5.5 и 90.1% у DeepSeek-V4-Pro-Max. Claude Opus 4.7 также лидирует в Humanity’s Last Exam без инструментов: 46.9% против 41.4% у GPT-5.5, 43.1% у GPT-5.5 Pro и 37.7% у DeepSeek-V4-Pro-Max.
What should I do next in practice?
GPT-5.5 Pro лидирует в Humanity’s Last Exam с инструментами: 57.2% против 54.7% у Claude Opus 4.7, 52.2% у GPT-5.5 и 48.2% у DeepSeek-V4-Pro-Max.
Which related topic should I explore next?
Continue with "GPT-5.5, Claude Opus 4.7, Kimi K2.6 और DeepSeek V4 के बेंचमार्क पर शोध करें और एक अच्छी शोध रिपोर्ट तैयार करें।" for another angle and extra citations.
Open related pageWhat should I compare this against?
Cross-check this answer against "Lakukan riset mendalam tentang benchmark Claude Opus 4.7, GPT-5.5, DeepSeek V4, dan Kimi K2.6.".
Open related pageContinue your research
Sources
- [1] DeepSeek V4 vs Claude Opus 4.5 for coding: benchmark comparisonapidog.com
DeepSeek V4 vs Claude Opus 4.5 for coding: benchmark comparison Claude Opus 4.5 leads SWE-bench at 80.9% and produces minimal, precise diffs. DeepSeek V4 handles multi-file, repository-scale refactoring well, particularly with large explicit context. INEZA Felin-Michel INEZA Felin-Michel 10 April 2026 DeepSeek V4 vs Claude Opus 4.5 for coding: benchmark comparison ## TL;DR Claude Opus 4.5 leads SWE-bench at 80.9% and produces minimal, precise diffs. DeepSeek V4 handles multi-file, repository-scale refactoring well, particularly with large explicit context. Neither is universally better: use…
- [2] DeepSeek V4 vs Claude Opus 4.6 vs GPT-5.4: Compararea modelelor AI pentru programare (2026) | NxCodenxcode.io
Diferență de cost de 50x: Prețul API pentru DeepSeek V4 (~$0.28/M input) este de aproximativ 50x mai ieftin dect Claude Opus 4.6 ($15/M input), ceea ce îl face cștigătorul clar pentru echipele sensibile la costuri. Claude Opus conduce în benchmark-urile verificate: Scorul de 80.8% SWE-bench Verified este confirmat independent; scorul de 80%+ pretins de DeepSeek V4 și cel de ~80% al GPT-5.4 sunt validate mai puțin riguros. Trei puncte forte diferite: DeepSeek excelează la eficiența costurilor + lungimea contextului, Claude Opus la raționamentul multi-fișier + înțelegerea intenției, iar GPT-5.4…
- [3] DeepSeek V4 vs Claude Opus 4.6 vs GPT-5.4: השוואת מודלי AI לתכנות (2026) | NxCodenxcode.io
השוואת תמחור כאן ההשוואה הופכת לדרמטית. מודל התמחור של DeepSeek שונה מהותית מזה של ספקי המודלים הסגורים. | קטגוריית עלות | DeepSeek V4 | Claude Opus 4.6 | GPT-5.4 | --- --- | | קלט (לכל 1M tokens) | ~$0.28 | $15.00 | $10.00 | | פלט (לכל 1M tokens) | ~$1.10 | $75.00 | $30.00 | | תוספת תשלום על הקשר מורחב | ללא (1M מובנה) | ללא (1M beta) | כן (מעבר ל-128K) | | עלות עבור 100K קלט + 10K פלט | ~$0.039 | $2.25 | $1.30 | DeepSeek V4 זול בערך פי 50 מ-Claude Opus 4.6 על tokens של קלט וזול פי 27 מ-GPT-5.4. עבור tokens של פלט, הפער רחב עוד יותר — זול פי 68 מ-Claude ופי 27 מ-GPT-5.4. עבור צוות המעבד 1…
- [4] DeepSeek V4 vs Claude Opus 4.6 vs GPT-5.4: השוואת מודלי AI לתכנות (2026) | NxCodenxcode.io
Perbedaan biaya 50x: DeepSeek V4 API pricing (~$0.28/M input) sekitar 50x lebih murah daripada Claude Opus 4.6 ($15/M input), menjadikannya pemenang yang jelas bagi tim yang sensitif terhadap biaya. Claude Opus memimpin pada verified benchmarks: 80.8% SWE-bench Verified dikonfirmasi secara independen; klaim DeepSeek V4 sebesar 80%+ dan GPT-5.4 sebesar ~80% kurang divalidasi secara ketat. Tiga kekuatan yang berbeda: DeepSeek unggul dalam efisiensi biaya + context length, Claude Opus pada multi-file reasoning + pemahaman intent, dan GPT-5.4 pada kontrol reasoning + computer use. Diversifikasi s…
- [5] DeepSeek V4 vs GPT-5.4 vs Claude Opus 4.6: Verified Comparisonevolink.ai
Context Note Claude Opus 4.7 launched on April 16, 2026 and is now generally available from Anthropic. This article intentionally keeps Claude Opus 4.6 in scope because the URL and query target are specifically about the
4.6comparison set. Treat this page as a historical and still-useful comparison baseline rather than the final word on the latest Claude release. If you are comparing DeepSeek V4, GPT-5.4, and Claude Opus 4.6, the most important change is this: as of April 24, 2026, DeepSeek V4 is no longer a rumor-only comparison target. DeepSeek's official API docs now list `deepseek-v4-f… - [6] DeepSeek-V4 arrives with near state-of-the-art intelligence at 1/6th ...venturebeat.com
BenchmarkDeepSeek-V4-Pro-MaxGPT-5.5GPT-5.5 Pro, where shownClaude Opus 4.7Best result among these GPQA Diamond90.1%93.6%—94.2%Claude Opus 4.7 Humanity’s Last Exam, no tools37.7%41.4%43.1%46.9%Claude Opus 4.7 Humanity’s Last Exam, with tools48.2%52.2%57.2%54.7%GPT-5.5 Pro Terminal-Bench 2.067.9%82.7%—69.4%GPT-5.5 SWE-Bench Pro / SWE Pro55.4%58.6%—64.3%Claude Opus 4.7 BrowseComp83.4%84.4%90.1%79.3%GPT-5.5 Pro MCP Atlas / MCPAtlas Public73.6%75.3%—79.1%Claude Opus 4.7 The shared academic-reasoning results favor the closed models: On GPQA Diamond, DeepSeek-V4-Pro-Max scores 90.1%, while GPT-5.5 r…
- [7] Kimi K2.6 vs Claude Opus 4.6 vs GPT-5.4 - Verdent AIverdent.ai
Yes. K2.6 weights are on Hugging Face and run on vLLM, SGLang, or KTransformers. Minimum viable hardware is 4× H100 for the INT4 variant at reduced context. Claude and GPT-5.4 are API-only — there is no self-hosted path. If data sovereignty is a requirement, K2.6 is the only option among these three. ### How stale are these numbers likely to get? Quickly. Anthropic released Opus 4.7 on April 16, 2026, four days before K2.6 launched. Opus 4.7's SWE-Bench Verified is 87.6%, already well ahead of K2.6's 80.2%. OpenAI updates the GPT-5.4 family and the SEAL leaderboard rolls continuously. This ta…
- [8] Kimi K2.6: The new leading open weights model - Artificial Analysisartificialanalysis.ai
➤ Multimodality: Kimi K2.6 supports Image and Video input and text output natively. The model’s max context length remains 256k. Kimi K2.6 has significantly higher token usage than Kimi K2.5. Kimi K2.5 scores 6 on the AA-Omniscience Index, primarily driven by low hallucination rate. Here’s the full suite of Kimi K2.6 evaluation results: See Artificial Analysis for further details and benchmarks of Kimi K2.6: Want to dive deeper? Discuss this model with our Discord community: ## Read the latest ### Opus 4.7: Everything you need to know Benchmarks and Analysis of Opus 4.7 April 17, 2026 ### Sub…
- [9] DeepSeek V4 vs Claude Opus 4.6 vs GPT-5.4 - NxCodenxcode.io
Developer guide for Claude Opus 4.7: API setup (claude-opus-4-7), new xhigh effort level, /ultrareview command, task budgets, and migration from 4.6. With code examples and cost optimization tips. 2026-04-16Read more → View All Articles → [...] # DeepSeek V4 vs Claude Opus 4.6 vs GPT-5.4: Which AI Coding Model Wins in 2026? The best AI coding model in 2026 depends on your budget and use case. Claude Opus 4.6 leads with a verified 80.8% on SWE-bench and excels at multi-file reasoning. GPT-5.4 offers unique Computer Use and five-level reasoning controls. DeepSeek V4 claims comparable benchmark…
- [10] DeepSeek-V4-Pro-Max: Pricing, Benchmarks & Performancellm-stats.com
7Image 54DeepSeek-V4-Pro-Max 0.83 8Image 55GPT-5.4 0.83 9Image 56Claude Opus 4.7 0.79 10Image 57GLM-5.1 0.79 Show 16 more Notice missing or incorrect data?Let us know→ ### Specifications Parameters 1.6T License MIT Training data 32.0T tokens Released Apr 2026 Output tokens 393K moe:true thinking:true ### Modalities In text Out text ### Resources API ReferencePlaygroundWeightsRepository CallingBox The voice stack, already built Telephony, STT, TTS, and orchestration in one API. Give your AI agents a phone number and have them make calls for you. Start for freeRead the docs $0.05 /min all-in 7…
- [11] AI Model Benchmarks Apr 2026 | Compare GPT-5, Claude 4.5 ...lmcouncil.ai
OTIS Mock AIME 2024-25 | | Model | Score | --- | 1 | Claude Opus 4.7 (xhigh) | 97.8% ±2.2 | | 2 | GPT-5.2 (high) | 96.1% ±2.6 | | 3 | GPT-5.2 (xhigh) | 96.1% ±2.7 | | 4 | Gemini 3.1 Pro Preview | 95.6% ±3.1 | | 5 | GPT-5.4 (xhigh) | 95.3% ±3.2 | ### MATH Level 5 | | Model | Score | --- | 1 | GPT-5 (high) | 98.1% ±0.3 | | 2 | GPT-5 (medium) | 97.9% ±0.3 | | 3 | GPT-5 mini (high) | 97.8% ±0.3 | | 4 | o4-mini (high) | 97.8% ±0.3 | | 5 | o3 (high) | 97.8% ±0.3 | ### FrontierMath | | Model | Score | --- | 1 | GPT-5.4 Pro (xhigh) | 50.0% ±2.9 | | 2 | GPT-5.4 (xhigh) | 47.6% ±2.9 | | 3 | Claude…
- [12] Deep|DeepSeek V4 vs Claude vs GPT-5.4: A 38-Task ... - FundaAIfundaai.substack.com
DeepSeek V4 is DeepSeek’s next-generation foundation model, shipped as two variants through the Pandora API: Pro (deeper, slower — optimized for thoroughness) and Flash (faster, more concise — optimized for production throughput). Both support multi-turn conversations with full tool calling. We obtained early access and benchmarked them against other frontier model configurations across 38 tasks spanning coding, reasoning, writing, and complex multi-step analysis with live data. DeepSeek V4 Pro performs in the same analytical tier as Claude Opus 4.7, while Claude Opus 4.6 (Thinking) and Claud…
- [13] [PDF] Technical Performance - Stanford HAIhai.stanford.edu
General Reasoning MMMU evaluates multimodal reasoning on college-level subject questions that combine text with visuals such as diagrams, charts, tables, and equations. Some example tasks include extracting constraints from a table and applying them to a word problem, or using a diagram to answer a domain-specific question in areas like engineering or medicine. As of February 2026, the leading model, Gemini 3.1 Pro Preview, scored 88.2% on MMMU and within 0.4 percentage points of the best human expert reference (Figure 2.4.1). Other Gemini variants follow closely, including Gemini 3 Flash (87…
- [14] DeepSeek V4 is here: How it compares to ChatGPT, Claude, Geminimashable.com
Here's how the API pricing compares: DeepSeek V4 costs $1.74 per 1 million input tokens and $3.48 per 1 million output tokens (1 million context window) GPT-5.5 costs at $5 per 1 million input tokens and $30 per 1 million output tokens (1 million context window) Claude Opus 4.7 costs at $5 per 1 million input tokens and $25 per 1 million output tokens (1 million context window) Google Gemini 3.1 Pro costs $2 per 1 million input tokens and $12 per 1 million output tokens As you can see, DeepSeek is about one-sixth the cost of the latest U.S. models, which is a huge edge. Even the more affordab…
- [15] DeepSeek V4 Preview: The Complete 2026 Guide - o-mega | AIo-mega.ai
7. Head-to-Head: DeepSeek V4 vs Claude Opus 4.7 Claude Opus 4.7, released just eight days before DeepSeek V4 on April 16, represents Anthropic's most capable model and the current leader in agentic coding tasks. The comparison with V4-Pro reveals a more nuanced competitive picture than the GPT-5.5 matchup. On SWE-bench Verified, Claude Opus 4.7 leads with 87.6% versus V4-Pro's 80.6%, a 7-point gap. On SWE-bench Pro, Opus 4.7 leads with 64.3% versus V4-Pro's 55.4%, an 8.9-point gap. This is the widest gap of any benchmark comparison, and it reflects Anthropic's specific investment in multi-…
- [16] GPT-5.5 vs Claude Opus 4.7: Pricing, Speed, Benchmarks - LLM Statsllm-stats.com
| Spec | GPT-5.5 | Claude Opus 4.7 | --- | Provider | OpenAI | Anthropic | | Release date | Apr 23, 2026 | Apr 16, 2026 | | Model ID |
gpt-5.5|claude-opus-4-7| | Input / output (≤200K) | $5 / $30 per 1M | $5 / $25 per 1M | | Input / output (>200K) | $5 / $30 per 1M (flat) | $10 / $37.50 per 1M | | Context window (input / output) | 1M / 128K | 1M / 128K | | Modalities | Text + image, text out | Text + image (~3.75 MP), text out | | Reasoning controls | xhigh effort tier | low / medium / high / xhigh / max | | Batch / Flex tier | 0.5× standard | 0.5× standard | | Self-verification on age… - [17] GPT-5.5: The Complete Guide (2026) - o-mega | AIo-mega.ai
Domain-Specific Benchmarks | Benchmark | GPT-5.5 | Notes | --- | Harvey BigLaw Bench | 91.7% (43% perfect scores) | Legal reasoning, audience calibration | | Internal Investment Banking | 88.5% | Financial analysis tasks | | BixBench (bioinformatics) | 80.5% (up from 74.0%) | +6.5pts over GPT-5.4 | | GeneBench (genetics) | 25.0% (Pro: 33.2%) | Multi-day expert projects | | CyberGym | 81.8% | Cybersecurity tasks | | Expanded CTF | 88.1% | Capture the flag challenges | | FinanceAgent v1.1 | 60.0% | Claude Opus 4.7 leads (~64.4%) | [...] ARC-AGI-2, the abstract reasoning benchmark designed t…
- [18] Claude Opus 4.7 Isn't a Drop-in Replacement for 4.6blog.dailydoseofds.com
It ended up running around 20% faster than LM Studio on the same hardware. Separately, it refactored an 8-year-old financial matching engine across 13 hours, delivering a 133% peak throughput gain. This is the capability gap that usually separates frontier closed models from open ones. K2.6 closes a meaningful chunk of it. You get weights you can actually deploy, a Modified MIT license, 5-6x lower inference cost, and performance that no longer forces you to compromise on agentic workloads. Read more in the official blog here → We’ll publish a thorough evaluation and a model deep dive on Kimi…
- [19] DeepSeek V4: Features, Benchmarks, and Comparisonsdatacamp.com
DeepSeek V4 vs Competitors Over the last week, we’ve seen the release of OpenAI's GPT-5.5 and Anthropic's Claude Opus 4.7. While those models boast top-tier capabilities, especially in long-context reasoning and agentic coding, DeepSeek V4 competes heavily on value and open accessibility. Here is how DeepSeek-V4-Pro compares to the new flagship models from OpenAI and Anthropic: Feature/BenchmarkDeepSeek V4 ProGPT-5.5Claude Opus 4.7 API Pricing (Input / Output per 1M)$1.74 / $3.48$5.00 / $30.00$5.00 / $25.00 Context Window 1M tokens
1M tokens1M tokens SWE-bench Pro (Coding)55.4%58.6%64.3%… - [20] Gpt-5.5 vs claude opus 4.7 performance comparison - Facebookfacebook.com
Artificial Intelligence LLMs ● Generative AI (Images Video Audio) ● Robots | Claude Opus 4.7 came out… | Facebook Log In Log In Forgot Account? Image 1 Gpt-5.5 vs claude opus 4.7 performance comparison Summarized by AI from the post below ● Robots Noman Hassan · 18h · Claude Opus 4.7 came out… and for a moment, it felt like the race was over. Developers were impressed. It could reason better, write better, and handle complex tasks with less guidance. People started saying, “This is the closest thing to real intelligence we’ve seen.” Then 23 April 2026 happened. OpenAI dropped GPT-5.5. And t…
- [21] Model Drop: GPT-5.5handyai.substack.com
The pitch the benchmark card is built to support: more intelligence at the same latency, ~40% fewer output tokens per Codex task, state-of-the-art performance on most agentic coding and knowledge-work evals. Terminal-Bench 2.0 at 82.7% is a decisive lead on Opus 4.7 and Gemini 3.1 Pro. Expert-SWE at 73.1% introduces a brand-new OpenAI internal benchmark built around 20-hour coding tasks, which matches the workload Codex users have been running for months. GDPval across 44 occupations at 84.9% maps to real-world knowledge work, and OSWorld-Verified at 78.7% is the first time OpenAI’s mainline…
- [22] GPT 5.5 is out. Here are the benchmarks. - Facebookfacebook.com
1d 4 Image 3 View all 3 replies []( Robert Eaton Opus 4.7 has been terrible. Getting everything wrong, making same mistake over and over. I went back to 4.6 and everything was fine 1d 4 Image 4Image 5 View all 2 replies []( Patrick Healy Codex $100a month package while building then go to $20 a month package & you run a local model hybrid is the best set up for a business. Personal use just go full local 1d 3 Image 6 View 1 reply View more comments 3 of 20 See more on Facebook See more on Facebook Email or phone number Password Log In Forgot password? or Create new account
- [23] MoonshotAI: Kimi K2 Thinking – Benchmarks - OpenRouteropenrouter.ai
Kimi K2 is optimized for agentic capabilities, including advanced tool use, reasoning, and code synthesis. It excels across coding (LiveCodeBench, SWE-bench), ...
- [24] Kimi K2.6 Tech Blog: Advancing Open-Source Codingkimi.com
On Kimi Code Bench, our internal coding benchmark covering diverse complicated end-to-end tasks, Kimi K2.6 demonstrates significant improvements over Kimi K2.5.
- [25] moonshotai/Kimi-K2.6 - Hugging Facehuggingface.co
| OSWorld-Verified | 73.1 | 75.0 | 72.7 63.3 | | Coding | | Terminal-Bench 2.0 (Terminus-2) | 66.7 | 65.4 | 65.4 | 68.5 | 50.8 | | SWE-Bench Pro | 58.6 | 57.7 | 53.4 | 54.2 | 50.7 | | SWE-Bench Multilingual | 76.7 77.8 | 76.9 | 73.0 | | SWE-Bench Verified | 80.2 80.8 | 80.6 | 76.8 | | SciCode | 52.2 | 56.6 | 51.9 | 58.9 | 48.7 | | OJBench (python) | 60.6 60.3 | 70.7 | 54.7 | | LiveCodeBench (v6) | 89.6 88.8 | 91.7 | 85.0 | | Reasoning & Knowledge | | HLE-Full | 34.7 | 39.8 | 40.0 | 44.4 | 30.1 | | AIME 2026 | 96.4 | 99.2 | 96.7 | 98.3 | 95.8 | | HMMT 2026 (Feb) | 92.7 | 97.7 | 96.2 | 94.7 | 8…
- [26] Kimi K2.6 - Intelligence, Performance & Price Analysisartificialanalysis.ai
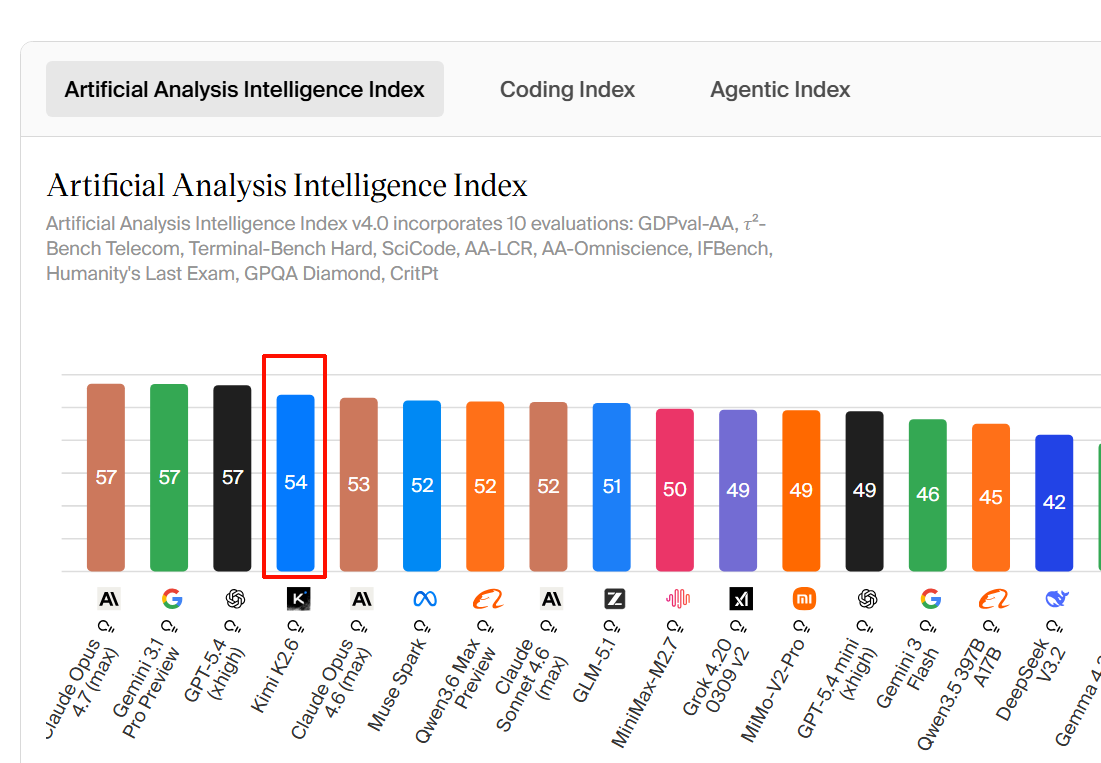
Kimi K2.6 scores 54 on the Artificial Analysis Intelligence Index, placing it well above average among comparable models (averaging 28). When ... 5 days ago
- [27] Kimi K2.6 on GMI Cloud: Architecture, Benchmarks & API Accessgmicloud.ai
Kimi K2.6: Architecture, Benchmarks, and What It Means for Production AI April 22, 2026 .png) Moonshot AI just open-sourced Kimi K2.6, and the results speak for themselves. It tops SWE-Bench Pro, runs 300 parallel sub-agents, and fits on 4x H100s in INT4. Built for autonomous coding, agent orchestration, and full-stack design. ## What Kimi K2.6 Is Kimi K2.6 is an open-source, native multimodal agentic model released by Moonshot AI on April 20, 2026, under a Modified MIT License. It is built for three things: long-horizon autonomous coding, coding-driven UI and full-stack design, and agent s…
- [28] Kimi K2.6 Has Arrived: An Open-Weight Powerhouse for Agentic Workblog.kilo.ai
Additionally, it achieved a strong 92.5% F1-score on DeepSearchQA and an excellent 66.7% on Terminal-Bench 2.0. We found Kimi K2.6 to be ... 6 days ago
- [29] SWE-bench Leaderboardsswebench.com
SWE-bench Logo Official Leaderboards ;. Kimi K2.5 (high reasoning). 70.80 ;. DeepSeek V3.2 (high reasoning). 70.00 ;. Gemini 3 Pro. 69.60 ;. Claude 4.5 ...
- [30] Better Kimi K2.6 benchmark score chart : r/ArtificialInteligence - Redditreddit.com
Artificial Analysis has released a more in-depth benchmark breakdown of Kimi K2 Thinking (2nd image) · r/LocalLLaMA - Artificial Analysis has ... 6 days ago
- [31] Meet Kimi K2.6: Advancing Open-Source Coding Open ... - Facebookfacebook.com
Benchmarks show strong results on SWE Bench, MMMU Pro, VideoMMMU, HLE, and BrowseComp..... Full analysis: https://www.marktechpost. com/2026 ... 6 days ago
- [32] moonshotai/Kimi-K2.6 · Add evaluation results for HLE, GPQA, AIME, HMMT, SWE-Bench, and Terminal-Benchhuggingface.co
moonshotai/Kimi-K2.6 · Add evaluation results for HLE, GPQA, AIME, HMMT, SWE-Bench, and Terminal-Bench Image 1: Hugging Face's logoHugging Face Models Datasets Spaces Buckets new Docs Enterprise Pricing Log In Sign Up # Image 2 moonshotai / Kimi-K2.6 like 1.03k Follow Image 3Moonshot AI 9.18k Image-Text-to-TextTransformersSafetensorskimi_k25feature-extractioncompressed-tensorsconversationalcustom_codeEval Results arxiv:2602.02276 License:modified-mit Model cardFiles Files and versions xetCommunity 20 Deploy Use this model ## Add evaluation results for HLE, GPQA, AIME, HMMT, SWE-Bench, and T…
- [33] Terminal-Bench 2.0 Leaderboardllm-stats.com
| # | Model | Score | Size | Context | Cost | License | --- --- --- | 1 | Anthropic Claude Mythos Preview Anthropic | 0.820 | — | — | $25.00 / $125.00 | | | 2 | OpenAI GPT-5.3 Codex OpenAI | 0.773 | — | 400K | $1.75 / $14.00 | | | 3 | OpenAI GPT-5.4 OpenAI | 0.751 | — | 1.0M | $2.50 / $15.00 | | | 4 | Anthropic Claude Opus 4.7New Anthropic | 0.694 | — | 1.0M | $5.00 / $25.00 | | | 5 | Zhipu AI GLM-5.1 Zhipu AI | 0.690 | 754B | 200K | $1.40 / $4.40 | | | 6 | Google Gemini 3.1 Pro Google | 0.685 | — | 1.0M | $2.50 / $15.00 | | | 7 | Moonshot AI Kimi K2.6New Moonshot AI | 0.667 | 1.0T | 262K | $…
- [34] Kimi K2 is the large language model series developed by Moonshot ...github.com
Key Features | | Total Parameters | 1T | | Activated Parameters | 32B | | Number of Layers (Dense layer included) | 61 | | Number of Dense Layers | 1 | | Attention Hidden Dimension | 7168 | | MoE Hidden Dimension (per Expert) | 2048 | | Number of Attention Heads | 64 | | Number of Experts | 384 | | Selected Experts per Token | 8 | | Number of Shared Experts | 1 | | Vocabulary Size | 160K | | Context Length | 128K | | Attention Mechanism | MLA | | Activation Function | SwiGLU | ## 3. Evaluation Results [...] | MMLU-Redux | EM | 92.7 | 90.5 | 89.2 | 93.6 | 94.2 | 92.4 | 90.6 | | MMLU-Pro |…
- [35] MoonshotAI: Kimi K2.6 Reviewdesignforonline.com
Performance Indices Source: Artificial Analysis This model was released recently. Independent benchmark evaluations are typically completed within days of release — these figures are preliminary and are likely to be updated as testing is finalised. ## Benchmark Scores ### Intelligence ### Technical ### Content Benchmark data from Artificial Analysis and Hugging Face How does MoonshotAI: Kimi K2.6 stack up? Compare side-by-side with other similar models. ## Model Information | | | --- | | OpenRouter ID |
moonshotai/kimi-k2.6| | Provider | moonshotai | | Release Date | April 20, 2026 | |… - [36] terminal-bench@2.0 Leaderboardtbench.ai
| | 98 | OpenHands | Kimi K2 Instruct | 2025-11-02 | OpenHands | Moonshot AI | 26.7%± 2.7 | | | 99 | Mini-SWE-Agent | Gemini 2.5 Pro | 2025-11-03 | Princeton | Google | 26.1%± 2.5 | | | 100 | Mini-SWE-Agent | Grok Code Fast 1 | 2025-11-03 | Princeton | xAI | 25.8%± 2.6 | | | 101 | Mini-SWE-Agent | Grok 4 | 2025-11-03 | Princeton | xAI | 25.4%± 2.9 | | | 102 | OpenHands | Qwen 3 Coder 480B | 2025-11-02 | OpenHands | Alibaba | 25.4%± 2.6 | | | 103 | Terminus 2 | GLM 4.6 | 2025-11-01 | AfterQuery | Z.ai | 24.5%± 2.4 | | | 104 | Terminus 2 | GPT-5-Mini | 2025-10-31 | AfterQuery | OpenAI | 24.0%±…
- [37] .eval_results/swe_bench_verified.yaml · moonshotai/Kimi-K2.6 at mainhuggingface.co
Hugging Face's logo # moonshotai / Kimi-K2.6 like 1.04k Follow Moonshot AI 9.2k bigeagle's picture | | | --- | | | - dataset: | | | id: SWE-bench/SWE-bench_Verified | | | task_id: swe_bench_%_resolved | | | value: 80.2 | | | date: '2026-04-20' | | | source: | | | url: | | | name: Model Card | | | user: SaylorTwift | | | |
- [38] .eval_results/aime_2026.yaml · unsloth/Kimi-K2.6 at mainhuggingface.co
Hugging Face's logo # unsloth / Kimi-K2.6 like 13 Follow Unsloth AI 20.2k danielhanchen's picture | | | --- | | | - dataset: | | | id: MathArena/aime_2026 | | | task_id: MathArena/aime_2026 | | | value: 96.4 | | | date: '2026-04-20' | | | source: | | | url: | | | name: Model Card | | | user: SaylorTwift | | | |
- [39] Commits · moonshotai/Kimi-K2.6huggingface.co
Hugging Face's logo # moonshotai / Kimi-K2.6 like 1.04k Follow Moonshot AI 9.2k # Commit History ### Add evaluation results for HLE, GPQA, AIME, HMMT, SWE-Bench, and Terminal-Bench (#4) d9cb81b
- [40] moonshotai/Kimi-K2.6 at mainhuggingface.co
Hugging Face's logo # moonshotai / Kimi-K2.6 like 1.04k Follow Moonshot AI 9.2k bigeagle's picture
- [41] Kimi K2.6 raises the bar for open-source models. Moonshot ...x.com
- HLE with tools: 54.0 vs 53.0 (agentic reasoning) - DeepSearchQA: 92.5 vs 91.3 (deep research) - LiveCodeBench: 89.6 vs 88.8 Opus 4.6 still wins on SWE-bench Multilingual and BrowseComp, but the gap is under a point in both. 𝗧𝗵𝗲 𝗽𝗮𝗿𝘁 𝘁𝗵𝗮𝘁 𝗮𝗰𝘁𝘂𝗮𝗹𝗹𝘆 𝗺𝗮𝘁𝘁𝗲𝗿𝘀 Benchmarks are the easy story. The harder and more interesting story is long-horizon execution. K2.6 ran a single autonomous task for over 12 hours, making 4,000+ tool calls, to port and optimize inference for a small LLM in Zig, a language most models barely touch. It ended up running around 20% faster than LM S…