Lakukan riset mendalam tentang benchmark Claude Opus 4.7, GPT-5.5, DeepSeek V4, dan Kimi K2.6.
Berdasarkan bukti yang tersedia, benchmark yang paling bisa dibahas secara konkret hanya untuk Claude Opus 4.7. Untuk GPT 5.5, bukti yang tersedia hanya satu unggahan X tanpa angka benchmark lengkap; untuk DeepSeek V4...
Berdasarkan bukti yang tersedia, benchmark yang paling bisa dibahas secara konkret hanya untuk Claude Opus 4.7. Untuk GPT 5.5, bukti yang tersedia hanya satu unggahan X tanpa angka benchmark lengkap; untuk DeepSeek V4 dan Kimi K2.6 tidak ada bukti benchmark langsung dalam sumber yang diberikan. Karena itu, perbandingan
Poin-poin penting
Claude Opus 4.7 dilaporkan mencetak 87.6% pada SWE-bench Verified, 94.2% pada GPQA, memiliki konteks 1 juta token, peningkatan vision 3.3x, mode effort “xhigh”, dan harga $5/$25 menurut LLM Stats.
Claude Opus 4.7 juga dilaporkan menempati peringkat #2 dari 110 model pada leaderboard provisional BenchLM dengan skor keseluruhan 97/100, serta peringkat #2 dari 14 pada verified leaderboard.
Pada GPQA Diamond, laporan The Next Web menyebut Claude Opus 4.7 mencetak 94.2%, GPT-5.4 Pro 94.4%, dan Gemini 3.1 Pro 94.3%; sumber itu menilai selisihnya berada dalam noise dan benchmark ini sudah cenderung jenuh di antara model frontier.
Untuk coding, bukti yang tersedia mendukung bahwa Claude Opus 4.7 sangat kuat, tetapi angka SWE-bench yang tersedia tidak sepenuhnya konsisten antar-sumber: LLM Stats menyebut 87.6% untuk SWE-bench Verified, sementara Stanford HAI hanya memberi konteks lebih lama bahwa per Februa
Berdasarkan bukti yang tersedia, benchmark yang paling bisa dibahas secara konkret hanya untuk Claude Opus 4.7. Untuk GPT-5.5, bukti yang tersedia hanya satu unggahan X tanpa angka benchmark lengkap; untuk DeepSeek V4 dan Kimi K2.6 tidak ada bukti benchmark langsung dalam sumber
## Key findings
Jawaban penelitian
Berdasarkan bukti yang tersedia, benchmark yang paling bisa dibahas secara konkret hanya untuk Claude Opus 4.7. Untuk GPT-5.5, bukti yang tersedia hanya satu unggahan X tanpa angka benchmark lengkap; untuk DeepSeek V4 dan Kimi K2.6 tidak ada bukti benchmark langsung dalam sumber yang diberikan. Karena itu, perbandingan empat model ini belum bisa dibuat secara kuat; Insufficient evidence untuk klaim komparatif penuh.
Key findings
Claude Opus 4.7 dilaporkan mencetak 87.6% pada SWE-bench Verified, 94.2% pada GPQA, memiliki konteks 1 juta token, peningkatan vision 3.3x, mode effort “xhigh”, dan harga $5/$25 menurut LLM Stats [7].
Claude Opus 4.7 juga dilaporkan menempati peringkat #2 dari 110 model pada leaderboard provisional BenchLM dengan skor keseluruhan 97/100, serta peringkat #2 dari 14 pada verified leaderboard [4].
Pada GPQA Diamond, laporan The Next Web menyebut Claude Opus 4.7 mencetak 94.2%, GPT-5.4 Pro 94.4%, dan Gemini 3.1 Pro 94.3%; sumber itu menilai selisihnya berada dalam noise dan benchmark ini sudah cenderung jenuh di antara model frontier [6].
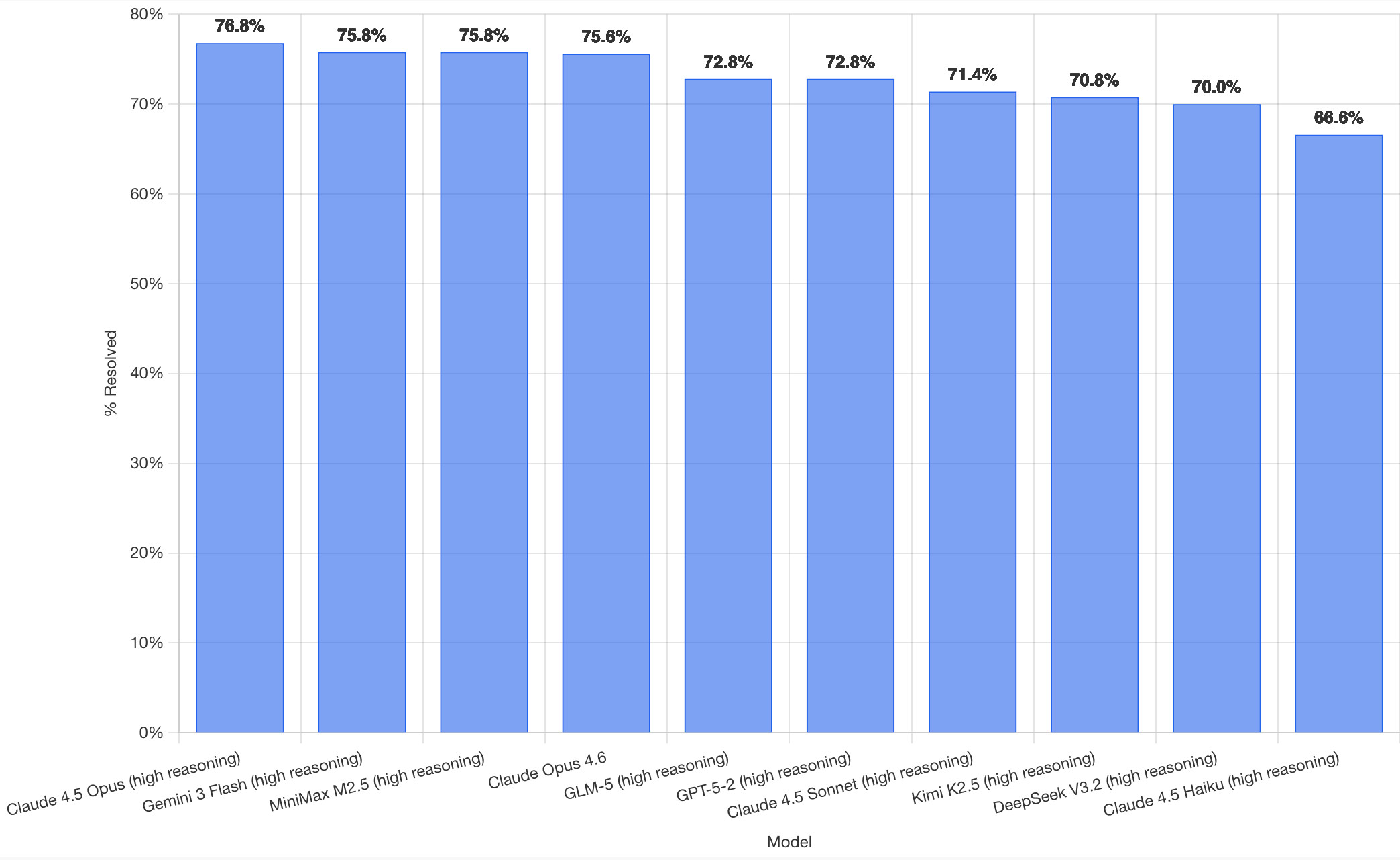
Untuk coding, bukti yang tersedia mendukung bahwa Claude Opus 4.7 sangat kuat, tetapi angka SWE-bench yang tersedia tidak sepenuhnya konsisten antar-sumber: LLM Stats menyebut 87.6% untuk SWE-bench Verified [7], sementara Stanford HAI hanya memberi konteks lebih lama bahwa per Februari 2026 Claude 4.5 Opus high reasoning berada sekitar 76.8% dan model lain seperti KimiK2.5, GPT-5.2, serta Gemini 3 Flash high reasoning berada di kisaran 70–76% [1].
Untuk analisis finansial, MindStudio menyebut contoh gap antara skor FinanceBench 82.7% dan kesiapan deployment produksi, tetapi bukti snippet yang tersedia tidak cukup untuk memastikan konteks metodologi, pembanding, atau apakah angka itu diklaim sebagai skor resmi Claude Opus 4.7 [3].
Untuk GPT-5.5, satu-satunya bukti langsung yang tersedia adalah unggahan X yang menyatakan GPT-5.5 underperform terhadap Mythos pada SWE-Bench Pro dan HLE, setara pada GPQA Diamond, BrowseComp, dan OSWorld-Verified, serta lebih baik pada Terminal-Bench 2.0 [31]. Bukti ini lemah untuk riset benchmark karena tidak menyediakan angka, metodologi, atau sumber primer [31].
Untuk DeepSeek V4, tidak ada benchmark langsung dalam bukti yang diberikan; satu-satunya data terkait DeepSeek menyebut DeepSeek V3.2 sebagai #3 rekomendasi coding April 2026 dengan 89.2% SWE-bench menurut MangoMind, bukan DeepSeek V4 [2]. Insufficient evidence.
Untuk Kimi K2.6, tidak ada benchmark langsung dalam bukti yang diberikan; Stanford HAI hanya menyebut KimiK2.5 berada dalam kelompok 70–76% pada SWE-bench Verified per Februari 2026, bukan Kimi K2.6 [1]. Insufficient evidence.
Sumber paling kuat yang tersedia adalah Stanford HAI karena bersifat teknis dan institusional, tetapi datanya tidak mencakup Claude Opus 4.7, GPT-5.5, DeepSeek V4, atau Kimi K2.6 secara langsung; sumber itu hanya memberi baseline per Februari 2026 untuk Claude 4.5 Opus, KimiK2.5, GPT-5.2, dan model lain [1].
LLM Stats, BenchLM, MindStudio, Vellum, The Next Web, dan MangoMind memberikan konteks pasar serta benchmark yang lebih baru, tetapi sebagian tampak sebagai ringkasan pihak ketiga dan bukan dokumentasi primer dari lab model [2][3][4][5][6][7].
Vellum mencantumkan area benchmark untuk Claude Opus 4.7 seperti SWE-bench Verified, SWE-bench Pro, Terminal-Bench 2.0, MCP-Atlas, Finance Agent v1.1, OSWorld-Verified, BrowseComp, GPQA, dan benchmark reasoning lain, tetapi snippet yang tersedia tidak memberikan angka spesifik yang bisa dipakai untuk perbandingan [5].
MangoMind menyediakan daftar rekomendasi April 2026 untuk coding, tetapi model yang disebut adalah Claude Opus 4.6, GPT-5.4 Pro, dan DeepSeek V3.2, bukan versi target Claude Opus 4.7, GPT-5.5, DeepSeek V4, atau Kimi K2.6 [2].
Limitations / uncertainty
Tidak ada bukti primer dari Anthropic, OpenAI, DeepSeek, atau Moonshot/Kimi dalam evidence yang tersedia, sehingga angka-angka harus diperlakukan sebagai laporan pihak ketiga, bukan hasil resmi yang sepenuhnya terverifikasi.
Tidak tersedia angka benchmark langsung untuk DeepSeek V4 dan Kimi K2.6, sehingga klaim bahwa salah satu lebih unggul dari Claude Opus 4.7 atau GPT-5.5 tidak dapat didukung.
Tidak tersedia angka benchmark lengkap untuk GPT-5.5; unggahan X hanya menyebut perbandingan relatif terhadap Mythos tanpa metodologi dan tanpa skor numerik [31].
Ada indikasi pergeseran benchmark: GPQA Diamond tampak hampir jenuh pada model frontier karena Claude Opus 4.7, GPT-5.4 Pro, dan Gemini 3.1 Pro berada di sekitar 94.2–94.4% menurut The Next Web [6]. Ini berarti benchmark seperti SWE-bench Pro, Terminal-Bench, OSWorld, BrowseComp, dan evaluasi agentic kemungkinan lebih berguna untuk membedakan model, tetapi bukti angka lintas empat model target belum tersedia.
Summary
Claude Opus 4.7 adalah satu-satunya model dalam daftar yang memiliki bukti benchmark cukup konkret: 87.6% pada SWE-bench Verified, 94.2% pada GPQA, dan skor BenchLM 97/100 menurut sumber pihak ketiga [7][4]. GPT-5.5 hanya memiliki bukti lemah berupa klaim relatif dari X tanpa angka lengkap [31]. DeepSeek V4 dan Kimi K2.6 tidak memiliki data benchmark langsung dalam evidence yang tersedia, sehingga status benchmark keduanya adalah Insufficient evidence.
Visual pendukung
Unlocking Mattermost for AI: A Deep Dive into Kakehashi's Fetch MCP ServerA Deep Dive into SushiMCP: Your AI Agent's Secret Weapon for Code ContextThe Ultimate Guide to Music Bots Discord: Features, Setup, and AI TrendsPanda Video: A Comprehensive Guide for AI Users and SEO EnthusiastsUnlocking SEO Insights: A Deep Dive into the AITDK SEO ExtensionThe Ultimate Guide to deepseek - ai assistant in 2026AI Benchmarks 2026: Monthly Leaderboards & Rankings | MangoMindMangoMind TeamNASA is right to focus on 'hardware rich' approach following Artemis II heat shield gambleHumanoid robot takes over data collection, administrative job at UK’s construction site'Dr'Dr. of Bubbles' Lucy Rogers on Robot Wars, new book, and why failure fuels innovationUS’ heat-activated knot robots leap hundreds of times their height without electronicsAI WarAI War? White House accuses China of industrial-scale theft of US AI frontier modelsVideo: China’s SamuRoid humanoid robot offers smarter interactions in a compact formThe RV is becoming an energy platformThe RV is becoming an energy platform. These companies are building it that wayBar chart showing "% Resolved" by "Model"Bar chart showing "% Resolved" by "Model". Bars in descending order: Claude 4.5 Opus (high reasoning) 76.8%, Gemini 3 Flash (high reasoning) 75.8%, MiniMax M2.5 (high reasoning) 75.8%, Claude Opus 4.6 75.6%, GLM-5 (high reasoning) 72.8%, GPT-5.2 (high reasoning) 72.8%, Claude 4.5 Sonnet (high reasoning) 72.8%, Kimi K2.Musk is asking chip suppliers to move at ‘light speed’ for his Terafab AI chip plantClaude Opus 4.7 Benchmark Full Analysis: Empirical Data LeadingThe image displays benchmark results for the Claude Opus 4.7 model released in April 2026, highlighting its leading performance in seven major rankings, including SW-E-bench, SW-E-bench Pro, GPQA Diamond reasoning, and Vision multimodal, with notable accuracy percentages and performance improvements.
Percakapan penelitian
kamu
Pertanyaan penelitian
Lakukan riset mendalam tentang benchmark Claude Opus 4.7, GPT-5.5, DeepSeek V4, dan Kimi K2.6.
Studio Global AI32 sumber
Jawaban yang dikutip
Berdasarkan bukti yang tersedia, benchmark yang paling bisa dibahas secara konkret hanya untuk Claude Opus 4.7. Untuk GPT-5.5, bukti yang tersedia hanya satu unggahan X tanpa angka benchmark lengkap; untuk DeepSeek V4 dan Kimi K2.6 tidak ada bukti benchmark langsung dalam sumber yang diberikan. Karena itu, perbandingan empat model ini belum bisa dibuat secara kuat; Insufficient evidence untuk klaim komparatif penuh.
Key findings
Claude Opus 4.7 dilaporkan mencetak 87.6% pada SWE-bench Verified, 94.2% pada GPQA, memiliki konteks 1 juta token, peningkatan vision 3.3x, mode effort “xhigh”, dan harga $5/$25 menurut LLM Stats [7].
Claude Opus 4.7 juga dilaporkan menempati peringkat #2 dari 110 model pada leaderboard provisional BenchLM dengan skor keseluruhan 97/100, serta peringkat #2 dari 14 pada verified leaderboard [4].
Pada GPQA Diamond, laporan The Next Web menyebut Claude Opus 4.7 mencetak 94.2%, GPT-5.4 Pro 94.4%, dan Gemini 3.1 Pro 94.3%; sumber itu menilai selisihnya berada dalam noise dan benchmark ini sudah cenderung jenuh di antara model frontier [6].
Untuk coding, bukti yang tersedia mendukung bahwa Claude Opus 4.7 sangat kuat, tetapi angka SWE-bench yang tersedia tidak sepenuhnya konsisten antar-sumber: LLM Stats menyebut 87.6% untuk SWE-bench Verified [7], sementara Stanford HAI hanya memberi konteks lebih lama bahwa per Februari 2026 Claude 4.5 Opus high reasoning berada sekitar 76.8% dan model lain seperti KimiK2.5, GPT-5.2, serta Gemini 3 Flash high reasoning berada di kisaran 70–76% [1].
Untuk analisis finansial, MindStudio menyebut contoh gap antara skor FinanceBench 82.7% dan kesiapan deployment produksi, tetapi bukti snippet yang tersedia tidak cukup untuk memastikan konteks metodologi, pembanding, atau apakah angka itu diklaim sebagai skor resmi Claude Opus 4.7 [3].
Untuk GPT-5.5, satu-satunya bukti langsung yang tersedia adalah unggahan X yang menyatakan GPT-5.5 underperform terhadap Mythos pada SWE-Bench Pro dan HLE, setara pada GPQA Diamond, BrowseComp, dan OSWorld-Verified, serta lebih baik pada Terminal-Bench 2.0 [31]. Bukti ini lemah untuk riset benchmark karena tidak menyediakan angka, metodologi, atau sumber primer [31].
Untuk DeepSeek V4, tidak ada benchmark langsung dalam bukti yang diberikan; satu-satunya data terkait DeepSeek menyebut DeepSeek V3.2 sebagai #3 rekomendasi coding April 2026 dengan 89.2% SWE-bench menurut MangoMind, bukan DeepSeek V4 [2]. Insufficient evidence.
Untuk Kimi K2.6, tidak ada benchmark langsung dalam bukti yang diberikan; Stanford HAI hanya menyebut KimiK2.5 berada dalam kelompok 70–76% pada SWE-bench Verified per Februari 2026, bukan Kimi K2.6 [1]. Insufficient evidence.
Sumber paling kuat yang tersedia adalah Stanford HAI karena bersifat teknis dan institusional, tetapi datanya tidak mencakup Claude Opus 4.7, GPT-5.5, DeepSeek V4, atau Kimi K2.6 secara langsung; sumber itu hanya memberi baseline per Februari 2026 untuk Claude 4.5 Opus, KimiK2.5, GPT-5.2, dan model lain [1].
LLM Stats, BenchLM, MindStudio, Vellum, The Next Web, dan MangoMind memberikan konteks pasar serta benchmark yang lebih baru, tetapi sebagian tampak sebagai ringkasan pihak ketiga dan bukan dokumentasi primer dari lab model [2][3][4][5][6][7].
Vellum mencantumkan area benchmark untuk Claude Opus 4.7 seperti SWE-bench Verified, SWE-bench Pro, Terminal-Bench 2.0, MCP-Atlas, Finance Agent v1.1, OSWorld-Verified, BrowseComp, GPQA, dan benchmark reasoning lain, tetapi snippet yang tersedia tidak memberikan angka spesifik yang bisa dipakai untuk perbandingan [5].
MangoMind menyediakan daftar rekomendasi April 2026 untuk coding, tetapi model yang disebut adalah Claude Opus 4.6, GPT-5.4 Pro, dan DeepSeek V3.2, bukan versi target Claude Opus 4.7, GPT-5.5, DeepSeek V4, atau Kimi K2.6 [2].
Limitations / uncertainty
Tidak ada bukti primer dari Anthropic, OpenAI, DeepSeek, atau Moonshot/Kimi dalam evidence yang tersedia, sehingga angka-angka harus diperlakukan sebagai laporan pihak ketiga, bukan hasil resmi yang sepenuhnya terverifikasi.
Tidak tersedia angka benchmark langsung untuk DeepSeek V4 dan Kimi K2.6, sehingga klaim bahwa salah satu lebih unggul dari Claude Opus 4.7 atau GPT-5.5 tidak dapat didukung.
Tidak tersedia angka benchmark lengkap untuk GPT-5.5; unggahan X hanya menyebut perbandingan relatif terhadap Mythos tanpa metodologi dan tanpa skor numerik [31].
Ada indikasi pergeseran benchmark: GPQA Diamond tampak hampir jenuh pada model frontier karena Claude Opus 4.7, GPT-5.4 Pro, dan Gemini 3.1 Pro berada di sekitar 94.2–94.4% menurut The Next Web [6]. Ini berarti benchmark seperti SWE-bench Pro, Terminal-Bench, OSWorld, BrowseComp, dan evaluasi agentic kemungkinan lebih berguna untuk membedakan model, tetapi bukti angka lintas empat model target belum tersedia.
Summary
Claude Opus 4.7 adalah satu-satunya model dalam daftar yang memiliki bukti benchmark cukup konkret: 87.6% pada SWE-bench Verified, 94.2% pada GPQA, dan skor BenchLM 97/100 menurut sumber pihak ketiga [7][4]. GPT-5.5 hanya memiliki bukti lemah berupa klaim relatif dari X tanpa angka lengkap [31]. DeepSeek V4 dan Kimi K2.6 tidak memiliki data benchmark langsung dalam evidence yang tersedia, sehingga status benchmark keduanya adalah Insufficient evidence.
Orang-orang juga bertanya
Apa jawaban singkat untuk "Lakukan riset mendalam tentang benchmark Claude Opus 4.7, GPT-5.5, DeepSeek V4, dan Kimi K2.6."?
Claude Opus 4.7 dilaporkan mencetak 87.6% pada SWE-bench Verified, 94.2% pada GPQA, memiliki konteks 1 juta token, peningkatan vision 3.3x, mode effort “xhigh”, dan harga $5/$25 menurut LLM Stats.
Apa poin penting yang harus divalidasi terlebih dahulu?
Claude Opus 4.7 dilaporkan mencetak 87.6% pada SWE-bench Verified, 94.2% pada GPQA, memiliki konteks 1 juta token, peningkatan vision 3.3x, mode effort “xhigh”, dan harga $5/$25 menurut LLM Stats. Claude Opus 4.7 juga dilaporkan menempati peringkat #2 dari 110 model pada leaderboard provisional BenchLM dengan skor keseluruhan 97/100, serta peringkat #2 dari 14 pada verified leaderboard.
Apa yang harus saya lakukan selanjutnya dalam latihan?
Pada GPQA Diamond, laporan The Next Web menyebut Claude Opus 4.7 mencetak 94.2%, GPT-5.4 Pro 94.4%, dan Gemini 3.1 Pro 94.3%; sumber itu menilai selisihnya berada dalam noise dan benchmark ini sudah cenderung jenuh di antara model frontier.
Topik terkait manakah yang harus saya jelajahi selanjutnya?
Lanjutkan dengan "GPT-5.5, Claude Opus 4.7, Kimi K2.6 और DeepSeek V4 के बेंचमार्क पर शोध करें और एक अच्छी शोध रिपोर्ट तैयार करें।" untuk sudut pandang lain dan kutipan tambahan.
5. Monthly Updates AI moves fast. We re-test all models monthly and publish updated rankings to reflect the latest releases. ## 🎯 Quick Recommendations ### Best AI for Coding (April 2026) 1. •Claude Opus 4.6 - 93.2% SWE-bench 2. •GPT-5.4 Pro - 91.1% SWE-bench 3. •DeepSeek V3.2 - 89.2% SWE-bench ### Best AI for Reasoning 1. •GPT-5.4 Pro - 94.5% GPQA Diamond 2. •Claude Opus 4.6 - 93.1% GPQA Diamond 3. •Gemini 3.1 Pro - 92.4% GPQA Diamond ### Best AI for Creative Writing 1. •GPT-5.4 Pro - Highest creativity scores 2. •Claude Opus 4.6 - Best narrative coherence 3. •Gemini 3.1 Pro - Most dive…
Star on GitHub 55.8KGo to Console Start building for free Sign upGo to Console Start building for free Products Docs Pricing Customers Blog Changelog Star on GitHub 55.8K Blog/GPT-5.5 is here: benchmarks, pricing, and what changes for developers Apr 24, 2026•8 min # GPT-5.5 is here: benchmarks, pricing, and what changes for developers OpenAI shipped GPT-5.5 on April 23, 2026. Here's a source-backed look at benchmarks, pricing versus GPT-5.4 and Claude Opus 4.7, the system card, and where the model still falls short. Image 13: Atharva Deosthale #### Atharva Deosthale Developer Advocate SHARE 7…
MCP-Atlas: Claude Opus 4.7 scores 79.1% versus GPT-5.5's 75.3%. For teams heavily invested in multi-tool orchestration via the Model Context Protocol, Claude's lead on this benchmark reflects better tool-call reliability in complex, chained scenarios. A note on methodology: OpenAI's system card includes an asterisk on SWE-bench Pro noting 'evidence of memorization' from other labs. Anthropic has published a filter re-score analysis showing their Opus 4.7 margin holds on decontaminated subsets. OpenAI did not publish a matched re-run. Keep this context in mind when comparing SWE-bench Pro scor…
Evaluations ##### Coding EvalGPT-5.5GPT‑5.4GPT-5.5 ProGPT‑5.4 ProClaude Opus 4.7Gemini 3.1 Pro SWE-Bench Pro (Public) 58.6%57.7%--64.3%54.2% Terminal-Bench 2.0 82.7%75.1%--69.4%68.5% Expert-SWE (Internal)73.1%68.5%---- Labs have noted evidence of memorization(opens in a new window) on this eval ##### Professional EvalGPT-5.5GPT‑5.4GPT-5.5 ProGPT‑5.4 ProClaudeOpus 4.7Gemini 3.1 Pro GDPval (wins or ties)84.9%83.0%82.3%82.0%80.3%67.3% FinanceAgent v1.1 60.0%56.0%-61.5%64.4%59.7% Investment Banking Modeling Tasks (Internal)88.5%87.3%88.6%83.6%-- OfficeQA Pro 54.1%53.2%--43.6%18.1% ##### Compu…
On SWE-Bench Pro, it reached 58.6%, solving more real-world GitHub issues in a single pass than earlier versions. The model also outperformed its predecessor in long-horizon engineering tasks measured by internal benchmarks. These tasks often take human developers up to 20 hours to complete. > Introducing GPT-5.5 > > A new class of intelligence for real work and powering agents, built to understand complex goals, use tools, check its work, and carry more tasks through to completion. It marks a new way of getting computer work done. > > Now available in ChatGPT and Codex. pic.twitter.com/rPLTk…
| Consider applying for YC's Summer 2026 batch! Applications are open till May 4 Guidelines | FAQ | Lists | API | Security | Legal | Apply to YC | Contact | [...] | | | | 6thbit 1 day ago | parent | context | favorite | on: GPT-5.5
Mythos 5.5 SWE-bench Pro 77.8% 58.6% Terminal-bench-2.0 82.0% 82.7% GPQA Diamond 94.6% 93.6% H. Last Exam 56.8% 41.4% H. Last Exam (tools) 64.7% 52.2% BrowseComp 86.9% 84.4% (90.1% Pro) OSWorld-Verified 79.6% 78.7%
Still far from Mythos on SWE-bench but quite comparable otherwise. Source for mythos values: | | | | | | --- | | | | | aliljet 1 day ago | next…
leo 🐾 on X: "Perspective helps! GPT-5.5 underperforms Mythos on: - SWE-Bench Pro - HLE It is basically on-par on: - GPQA Diamond - BrowseComp - OSWorld-Verified It is better on: - Terminal-Bench 2.0 All while being more token efficient, smaller and cheaper than Mythos (and actually" / X Don’t miss what’s happening People on X are the first to know. Log in Sign up # Quote Image 3 leo Image 4: 🐾 @synthwavedd · Apr 23 GPT-5.5 benchmarks are out Benchmark results are more incremental, but in real world use it feels like a larger jump, especially for 5.5 Pro in my experience. Sort of similar t…
On SWE-bench Verified, top models are tightly clustered in the low-to-mid 70s (Figure 2.5.1). As of February 2026, Claude 4.5 Opus (high reasoning) led at approximately 76.8%, with several others including KimiK2.5, GPT-5.2, and Gemini 3 Flash (high reasoning) grouped between 70% and 76%. This is a pattern seen across several benchmarks in this chapter, where high-performing models score within a few percentage points of each other. SWE-bench 101 2.5 PERFORMANCE IN SPECIFIC DOMAINS | TECHNICAL PERFORMANCE | AI INDEX REPORT 2026 44.00% 46.00% 47.00% 48.00% 48.33% 49.67% 56.67% 58.33% 60.00% 60…
This matters for teams evaluating Opus 4.7 for production use because the model’s capability gains are only useful if they’re integrated into something that works end-to-end. The gap between “this model scores 82.7% on FinanceBench” and “we have a deployed tool our finance team actually uses” is usually infrastructure, not intelligence. You can try Remy at mindstudio.ai/remy. ## Frequently Asked Questions ### What score did Claude Opus 4.7 get on SWE-bench? Claude Opus 4.7 scored 82.4% on SWE-bench Verified. This is a meaningful gain over Opus 4.6’s approximately 71% and reflects genuine impr…
Core Rankings Specialized Use Cases Dashboards Directories Guides & Lists Tools # Claude Opus 4.7 According to BenchLM.ai, Claude Opus 4.7 ranks #2 out of 110 models on the provisional leaderboard with an overall score of 97/100. It also ranks #2 out of 14 on the verified leaderboard. This places it among the top tier of AI models available in 2026, competing directly with the strongest models from leading AI labs. Claude Opus 4.7 is a proprietary model with a 1M token context window. It processes queries without explicit chain-of-thought reasoning, offering faster response times and lower to…
Apr 16, 2026•16 min•ByNicolas Zeeb Guides CONTENTS Key observations of reported benchmarks Coding capabilities SWE-bench Verified SWE-bench Pro Terminal-Bench 2.0 Agentic capabilities MCP-Atlas (Scaled tool use) Finance Agent v1.1 OSWorld-Verified (Computer use) BrowseComp (Agentic search) Reasoning capabilities GPQA Diamond (Graduate-level science) Humanity's Last Exam Multimodal and vision capabilities CharXiv Reasoning (Visual reasoning) Multilingual Q&A (MMMLU) Safety and alignment What these benchmarks really mean for your agents When to use Opus 4.6 vs Opus 4.7 Use Opus 4.7 with your Ve…
On graduate-level reasoning, measured by GPQA Diamond, the field has converged. Opus 4.7 scores 94.2%, GPT-5.4 Pro scores 94.4%, and Gemini 3.1 Pro scores 94.3%. The differences are within noise. The frontier models have effectively saturated this benchmark, which means the competitive differentiation is shifting away from raw reasoning scores and toward applied performance on complex, multi-step tasks. ## The agentic step [...] ## Get the TNW newsletter Get the most important tech news in your inbox each week. Published April 16, 2026 - 3:49 pm UTC Back to top The heart of tech []( []( []( […
LLM Stats Logo Make AI phone calls with one API call # Claude Opus 4.7: Benchmarks, Pricing, Context & What's New Claude Opus 4.7 scores 87.6% on SWE-bench Verified, 94.2% on GPQA, 1M token context, 3.3x higher-resolution vision, new xhigh effort level. $5/$25 pricing. Jonathan Chavez The Takeaway Claude Opus 4.7 is a direct upgrade to Opus 4.6 at the same price ($5/$25 per million tokens), with 87.6% on SWE-bench Verified (+6.8pp), a new xhigh effort level, 3.3x higher-resolution vision, and self-verification on long-running agentic tasks. Claude Opus 4.7: Benchmarks, Pricing, Context & What…
Image 15: logo > In our evals, we saw a double-digit jump in accuracy of tool calls and planning in our core orchestrator agents. As users leverage Hebbia to plan and execute on use cases like retrieval, slide creation, or document generation, Claude Opus 4.7 shows the potential to improve agent decision-making in these workflows. > > Adithya Ramanathan > > Head of Applied Research Image 16: logo > On Rakuten-SWE-Bench, Claude Opus 4.7 resolves 3x more production tasks than Opus 4.6, with double-digit gains in Code Quality and Test Quality. This is a meaningful lift and a clear upgrade for th…
Update: If you look at the transcript Claude claims to have switched to Playwright, which is confusing because I didn't think I had that configured. Posted 19th February 2026 at 4:48 am ## Recent articles Changes in the system prompt between Claude Opus 4.6 and 4.7 - 18th April 2026 Join us at PyCon US 2026 in Long Beach - we have new AI and security tracks this year - 17th April 2026 Qwen3.6-35B-A3B on my laptop drew me a better pelican than Claude Opus 4.7 - 16th April 2026 This is a link post by Simon Willison, posted on 19th February 2026. benchmarks 14django 588ai 1969openai 406generativ…
Core Rankings Specialized Use Cases Dashboards Directories Guides & Lists Tools # Software Engineering Benchmark Verified (SWE-bench Verified) A curated, human-verified subset of SWE-bench that tests models on resolving real GitHub issues from popular open-source Python repositories like Django, Flask, and scikit-learn. ## Top models on SWE-bench Verified — April 24, 2026 As of April 24, 2026, Claude Mythos Preview leads the SWE-bench Verified leaderboard with 93.9% , followed by Claude Opus 4.7 (Adaptive) (87.6%) and GPT-5.3 Codex (85%). Claude Mythos Preview Anthropic Claude Opus 4.7 (Adapt…
Q1: What is Claude Opus 4.7? Claude Opus 4.7 is the flagship Large Language Model released by Anthropic on April 16, 2026. It leads in multiple benchmarks, including coding (SWE-bench Verified 87.6%), Agent tool invocation, and scientific reasoning (GPQA Diamond 94.2%), outperforming GPT-5.4 and Gemini 3.1 Pro. Compared to Opus 4.6, it introduces the new "xhigh effort" deep reasoning mode, all while maintaining the same official pricing. Q2: Which is better, Claude Opus 4.7 or GPT-5.4? [...] | Dimension | Claude Opus 4.7 | Claude Opus 4.6 | GPT-5.4 | Gemini 3.1 Pro | --- --- | Release Date |…
Claude Opus 4.7 is available now. Credit: Samuel Boivin/NurPhoto via Getty Images Anthropic has been shipping products and making news at a blistering pace in 2026, and on Thursday, the AI company announced the launch of Claude Opus 4.7. Claude Opus 4.7 is Anthropic's most intelligent model available to the general public. Notably, Anthropic said in a press release") that Opus 4.7 is not as powerful as Claude Mythos, which Anthropic deemed too dangerous for public release. Claude Opus is a family of hybrid reasoning models capable of multi-step reasoning and advanced coding. Until the announc…
The Claude Opus 4.7 benchmarks on software engineering tasks show the clearest improvement. On SWE-Bench, the industry-standard benchmark for evaluating autonomous code repair across real GitHub issues, Opus 4.7 shows a meaningful step up from Opus 4.6, with early reported scores suggesting improvements in the range of 8–12 percentage points depending on task category (Source: community-reported testing via r/ClaudeAI and independent evaluations). On HumanEval, which tests functional code generation, Opus 4.7 continues to perform competitively. [...] ## Conclusion — the honest verdict on Clau…
Assessed April 24, 2026 Rankings consider pricing, capabilities, benchmarks, and real-world applicability and are refreshed as new models launch. Feedback? ## Specifications ## Performance Profile ## Performance Indices Source: Artificial Analysis This model was released recently. Independent benchmark evaluations are typically completed within days of release — these figures are preliminary and are likely to be updated as testing is finalised. ## Benchmark Scores ### Intelligence ### Technical ### Content Benchmark data from Artificial Analysis and Hugging Face How does GPT-5.5 (medium) stac…
We measure GPT-5.5’s controllability by running CoT-Control, an evaluation suite described in (Yueh-Han, 2026 ) that tracks the model’s ability to follow user instructions about their CoT. CoT-Control includes over 13,000 tasks built from established benchmarks: GPQA (Rein et al., 2023 ), MMLU-Pro (Hendrycks et al., 2020 ), HLE (Phan et al., 2025 ), BFCL (Patil et al., 2025 [11: From tool use to agentic evaluation of large language models.” Proceedings of the 42nd international conference on machine learning . Available at: .")]) and SWE-Bench Verified. Each task is created by pairing a bench…
959494949393 HLE 27 41 55 69 655552514037 BrowseComp BrowseComp is a benchmark comprising 1,266 questions that challenge AI agents to persistently navigate the internet in search of hard-to-find, entangled information. The benchmark measures agents' ability to exercise persistence in information gathering, demonstrate creativity in web navigation, and find concise, verifiable answers. Despite the difficulty of the questions, BrowseComp is simple and easy-to-use, as predicted answers are short and easily verifiable against reference answers. agents, reasoning, search 74 79 84 89 878684837978 S…
Terminal-Bench 2.0 measures the ability to complete real CLI workflows: multi-step tasks involving file manipulation, script execution, debugging, and tool coordination. GPT-5.5's 82.7% score is the highest ever recorded, though the margin over Claude Mythos Preview (~82.0%) is razor-thin - VentureBeat. The SWE-bench results reveal a nuanced picture. On SWE-bench Verified (the standard version), GPT-5.5 scores 88.7%, a strong result. But on SWE-bench Pro (harder, multi-file problems), Claude Opus 4.7 leads at 64.3% versus GPT-5.5's 58.6%. And the gated Claude Mythos Preview dominates at 77.8%…
2025 was the year of AI speed. 2026 will be the year of AI quality. The year 2025 will be remembered as the moment AI-assisted software development entered its acceleration era. Improvements in the capabilities of coding agents, copilots, and automated workflows allowed teams to move faster than ever. But alongside t... Get Started in 2 clicks. No credit card needed Install in VS Code Our early testing shows the model communicates more directly, finds higher-signal issues, and performs better in practical coding and review workflows. Note: During release, you can try GPT-5.5 in ChatGPT an…
ML News # GPT-5.5 Benchmark Scores OpenAI has introduced GPT 5.5 as its most capable model so far, emphasizing a shift from simple question answering toward systems that can carry out complex, multi step tasks Brett Young Share Comment Star Created on April 23, 2026|Updated on April 23, 2026 Comment OpenAI has introduced GPT 5.5 as its most capable model so far, emphasizing a shift from simple question answering toward systems that can carry out complex, multi step tasks. The model is designed to better understand what a user is trying to accomplish and then independently plan, execute, and…
Core Rankings Specialized Use Cases Dashboards Directories Guides & Lists Tools # GPT-5.5 According to BenchLM.ai, GPT-5.5 ranks #5 out of 112 models on the provisional leaderboard with an overall score of 89/100. It also ranks #2 out of 16 on the verified leaderboard. This places it among the top tier of AI models available in 2026, competing directly with the strongest models from leading AI labs. GPT-5.5 is a proprietary model with a 1M token context window. It uses explicit chain-of-thought reasoning, which typically improves performance on math and complex reasoning tasks at the cost of…
The Coding Case The strongest benchmark improvements show up in agentic coding. On Expert-SWE, an internal evaluation covering long-horizon coding tasks that OpenAI estimates take human engineers a median of 20 hours to complete, GPT-5.5 scores 73.1% against GPT-5.4's 68.5%. The gains hold on Terminal-Bench 2.0 and SWE-Bench Pro as well, and across all three, GPT-5.5 uses fewer tokens to get there. [...] The week of April 14, 2026 produced three significant AI releases aimed at the same enterprise audience. Alibaba… ### Google's New Deep Research Max Agent Scores 93% on Benchmarks Google'…
LaporanURL Publik26 Apr 202632 sumber
Lakukan riset mendalam tentang benchmark Claude Opus 4.7, GPT-5.5, DeepSeek V4, dan Kimi K2.6.
Berdasarkan bukti yang tersedia, benchmark yang paling bisa dibahas secara konkret hanya untuk Claude Opus 4.7. Untuk GPT 5.5, bukti yang tersedia hanya satu unggahan X tanpa angka benchmark lengkap; untuk DeepSeek V4...
Berdasarkan bukti yang tersedia, benchmark yang paling bisa dibahas secara konkret hanya untuk Claude Opus 4.7. Untuk GPT 5.5, bukti yang tersedia hanya satu unggahan X tanpa angka benchmark lengkap; untuk DeepSeek V4 dan Kimi K2.6 tidak ada bukti benchmark langsung dalam sumber yang diberikan. Karena itu, perbandingan
Poin-poin penting
Claude Opus 4.7 dilaporkan mencetak 87.6% pada SWE-bench Verified, 94.2% pada GPQA, memiliki konteks 1 juta token, peningkatan vision 3.3x, mode effort “xhigh”, dan harga $5/$25 menurut LLM Stats.
Claude Opus 4.7 juga dilaporkan menempati peringkat #2 dari 110 model pada leaderboard provisional BenchLM dengan skor keseluruhan 97/100, serta peringkat #2 dari 14 pada verified leaderboard.
Pada GPQA Diamond, laporan The Next Web menyebut Claude Opus 4.7 mencetak 94.2%, GPT-5.4 Pro 94.4%, dan Gemini 3.1 Pro 94.3%; sumber itu menilai selisihnya berada dalam noise dan benchmark ini sudah cenderung jenuh di antara model frontier.
Untuk coding, bukti yang tersedia mendukung bahwa Claude Opus 4.7 sangat kuat, tetapi angka SWE-bench yang tersedia tidak sepenuhnya konsisten antar-sumber: LLM Stats menyebut 87.6% untuk SWE-bench Verified, sementara Stanford HAI hanya memberi konteks lebih lama bahwa per Februa
Berdasarkan bukti yang tersedia, benchmark yang paling bisa dibahas secara konkret hanya untuk Claude Opus 4.7. Untuk GPT-5.5, bukti yang tersedia hanya satu unggahan X tanpa angka benchmark lengkap; untuk DeepSeek V4 dan Kimi K2.6 tidak ada bukti benchmark langsung dalam sumber
## Key findings
Jawaban penelitian
Berdasarkan bukti yang tersedia, benchmark yang paling bisa dibahas secara konkret hanya untuk Claude Opus 4.7. Untuk GPT-5.5, bukti yang tersedia hanya satu unggahan X tanpa angka benchmark lengkap; untuk DeepSeek V4 dan Kimi K2.6 tidak ada bukti benchmark langsung dalam sumber yang diberikan. Karena itu, perbandingan empat model ini belum bisa dibuat secara kuat; Insufficient evidence untuk klaim komparatif penuh.
Key findings
Claude Opus 4.7 dilaporkan mencetak 87.6% pada SWE-bench Verified, 94.2% pada GPQA, memiliki konteks 1 juta token, peningkatan vision 3.3x, mode effort “xhigh”, dan harga $5/$25 menurut LLM Stats [7].
Claude Opus 4.7 juga dilaporkan menempati peringkat #2 dari 110 model pada leaderboard provisional BenchLM dengan skor keseluruhan 97/100, serta peringkat #2 dari 14 pada verified leaderboard [4].
Pada GPQA Diamond, laporan The Next Web menyebut Claude Opus 4.7 mencetak 94.2%, GPT-5.4 Pro 94.4%, dan Gemini 3.1 Pro 94.3%; sumber itu menilai selisihnya berada dalam noise dan benchmark ini sudah cenderung jenuh di antara model frontier [6].
Untuk coding, bukti yang tersedia mendukung bahwa Claude Opus 4.7 sangat kuat, tetapi angka SWE-bench yang tersedia tidak sepenuhnya konsisten antar-sumber: LLM Stats menyebut 87.6% untuk SWE-bench Verified [7], sementara Stanford HAI hanya memberi konteks lebih lama bahwa per Februari 2026 Claude 4.5 Opus high reasoning berada sekitar 76.8% dan model lain seperti KimiK2.5, GPT-5.2, serta Gemini 3 Flash high reasoning berada di kisaran 70–76% [1].
Untuk analisis finansial, MindStudio menyebut contoh gap antara skor FinanceBench 82.7% dan kesiapan deployment produksi, tetapi bukti snippet yang tersedia tidak cukup untuk memastikan konteks metodologi, pembanding, atau apakah angka itu diklaim sebagai skor resmi Claude Opus 4.7 [3].
Untuk GPT-5.5, satu-satunya bukti langsung yang tersedia adalah unggahan X yang menyatakan GPT-5.5 underperform terhadap Mythos pada SWE-Bench Pro dan HLE, setara pada GPQA Diamond, BrowseComp, dan OSWorld-Verified, serta lebih baik pada Terminal-Bench 2.0 [31]. Bukti ini lemah untuk riset benchmark karena tidak menyediakan angka, metodologi, atau sumber primer [31].
Untuk DeepSeek V4, tidak ada benchmark langsung dalam bukti yang diberikan; satu-satunya data terkait DeepSeek menyebut DeepSeek V3.2 sebagai #3 rekomendasi coding April 2026 dengan 89.2% SWE-bench menurut MangoMind, bukan DeepSeek V4 [2]. Insufficient evidence.
Untuk Kimi K2.6, tidak ada benchmark langsung dalam bukti yang diberikan; Stanford HAI hanya menyebut KimiK2.5 berada dalam kelompok 70–76% pada SWE-bench Verified per Februari 2026, bukan Kimi K2.6 [1]. Insufficient evidence.
Sumber paling kuat yang tersedia adalah Stanford HAI karena bersifat teknis dan institusional, tetapi datanya tidak mencakup Claude Opus 4.7, GPT-5.5, DeepSeek V4, atau Kimi K2.6 secara langsung; sumber itu hanya memberi baseline per Februari 2026 untuk Claude 4.5 Opus, KimiK2.5, GPT-5.2, dan model lain [1].
LLM Stats, BenchLM, MindStudio, Vellum, The Next Web, dan MangoMind memberikan konteks pasar serta benchmark yang lebih baru, tetapi sebagian tampak sebagai ringkasan pihak ketiga dan bukan dokumentasi primer dari lab model [2][3][4][5][6][7].
Vellum mencantumkan area benchmark untuk Claude Opus 4.7 seperti SWE-bench Verified, SWE-bench Pro, Terminal-Bench 2.0, MCP-Atlas, Finance Agent v1.1, OSWorld-Verified, BrowseComp, GPQA, dan benchmark reasoning lain, tetapi snippet yang tersedia tidak memberikan angka spesifik yang bisa dipakai untuk perbandingan [5].
MangoMind menyediakan daftar rekomendasi April 2026 untuk coding, tetapi model yang disebut adalah Claude Opus 4.6, GPT-5.4 Pro, dan DeepSeek V3.2, bukan versi target Claude Opus 4.7, GPT-5.5, DeepSeek V4, atau Kimi K2.6 [2].
Limitations / uncertainty
Tidak ada bukti primer dari Anthropic, OpenAI, DeepSeek, atau Moonshot/Kimi dalam evidence yang tersedia, sehingga angka-angka harus diperlakukan sebagai laporan pihak ketiga, bukan hasil resmi yang sepenuhnya terverifikasi.
Tidak tersedia angka benchmark langsung untuk DeepSeek V4 dan Kimi K2.6, sehingga klaim bahwa salah satu lebih unggul dari Claude Opus 4.7 atau GPT-5.5 tidak dapat didukung.
Tidak tersedia angka benchmark lengkap untuk GPT-5.5; unggahan X hanya menyebut perbandingan relatif terhadap Mythos tanpa metodologi dan tanpa skor numerik [31].
Ada indikasi pergeseran benchmark: GPQA Diamond tampak hampir jenuh pada model frontier karena Claude Opus 4.7, GPT-5.4 Pro, dan Gemini 3.1 Pro berada di sekitar 94.2–94.4% menurut The Next Web [6]. Ini berarti benchmark seperti SWE-bench Pro, Terminal-Bench, OSWorld, BrowseComp, dan evaluasi agentic kemungkinan lebih berguna untuk membedakan model, tetapi bukti angka lintas empat model target belum tersedia.
Summary
Claude Opus 4.7 adalah satu-satunya model dalam daftar yang memiliki bukti benchmark cukup konkret: 87.6% pada SWE-bench Verified, 94.2% pada GPQA, dan skor BenchLM 97/100 menurut sumber pihak ketiga [7][4]. GPT-5.5 hanya memiliki bukti lemah berupa klaim relatif dari X tanpa angka lengkap [31]. DeepSeek V4 dan Kimi K2.6 tidak memiliki data benchmark langsung dalam evidence yang tersedia, sehingga status benchmark keduanya adalah Insufficient evidence.
Visual pendukung
Unlocking Mattermost for AI: A Deep Dive into Kakehashi's Fetch MCP ServerA Deep Dive into SushiMCP: Your AI Agent's Secret Weapon for Code ContextThe Ultimate Guide to Music Bots Discord: Features, Setup, and AI TrendsPanda Video: A Comprehensive Guide for AI Users and SEO EnthusiastsUnlocking SEO Insights: A Deep Dive into the AITDK SEO ExtensionThe Ultimate Guide to deepseek - ai assistant in 2026AI Benchmarks 2026: Monthly Leaderboards & Rankings | MangoMindMangoMind TeamNASA is right to focus on 'hardware rich' approach following Artemis II heat shield gambleHumanoid robot takes over data collection, administrative job at UK’s construction site'Dr'Dr. of Bubbles' Lucy Rogers on Robot Wars, new book, and why failure fuels innovationUS’ heat-activated knot robots leap hundreds of times their height without electronicsAI WarAI War? White House accuses China of industrial-scale theft of US AI frontier modelsVideo: China’s SamuRoid humanoid robot offers smarter interactions in a compact formThe RV is becoming an energy platformThe RV is becoming an energy platform. These companies are building it that wayBar chart showing "% Resolved" by "Model"Bar chart showing "% Resolved" by "Model". Bars in descending order: Claude 4.5 Opus (high reasoning) 76.8%, Gemini 3 Flash (high reasoning) 75.8%, MiniMax M2.5 (high reasoning) 75.8%, Claude Opus 4.6 75.6%, GLM-5 (high reasoning) 72.8%, GPT-5.2 (high reasoning) 72.8%, Claude 4.5 Sonnet (high reasoning) 72.8%, Kimi K2.Musk is asking chip suppliers to move at ‘light speed’ for his Terafab AI chip plantClaude Opus 4.7 Benchmark Full Analysis: Empirical Data LeadingThe image displays benchmark results for the Claude Opus 4.7 model released in April 2026, highlighting its leading performance in seven major rankings, including SW-E-bench, SW-E-bench Pro, GPQA Diamond reasoning, and Vision multimodal, with notable accuracy percentages and performance improvements.
Percakapan penelitian
kamu
Pertanyaan penelitian
Lakukan riset mendalam tentang benchmark Claude Opus 4.7, GPT-5.5, DeepSeek V4, dan Kimi K2.6.
Studio Global AI32 sumber
Jawaban yang dikutip
Berdasarkan bukti yang tersedia, benchmark yang paling bisa dibahas secara konkret hanya untuk Claude Opus 4.7. Untuk GPT-5.5, bukti yang tersedia hanya satu unggahan X tanpa angka benchmark lengkap; untuk DeepSeek V4 dan Kimi K2.6 tidak ada bukti benchmark langsung dalam sumber yang diberikan. Karena itu, perbandingan empat model ini belum bisa dibuat secara kuat; Insufficient evidence untuk klaim komparatif penuh.
Key findings
Claude Opus 4.7 dilaporkan mencetak 87.6% pada SWE-bench Verified, 94.2% pada GPQA, memiliki konteks 1 juta token, peningkatan vision 3.3x, mode effort “xhigh”, dan harga $5/$25 menurut LLM Stats [7].
Claude Opus 4.7 juga dilaporkan menempati peringkat #2 dari 110 model pada leaderboard provisional BenchLM dengan skor keseluruhan 97/100, serta peringkat #2 dari 14 pada verified leaderboard [4].
Pada GPQA Diamond, laporan The Next Web menyebut Claude Opus 4.7 mencetak 94.2%, GPT-5.4 Pro 94.4%, dan Gemini 3.1 Pro 94.3%; sumber itu menilai selisihnya berada dalam noise dan benchmark ini sudah cenderung jenuh di antara model frontier [6].
Untuk coding, bukti yang tersedia mendukung bahwa Claude Opus 4.7 sangat kuat, tetapi angka SWE-bench yang tersedia tidak sepenuhnya konsisten antar-sumber: LLM Stats menyebut 87.6% untuk SWE-bench Verified [7], sementara Stanford HAI hanya memberi konteks lebih lama bahwa per Februari 2026 Claude 4.5 Opus high reasoning berada sekitar 76.8% dan model lain seperti KimiK2.5, GPT-5.2, serta Gemini 3 Flash high reasoning berada di kisaran 70–76% [1].
Untuk analisis finansial, MindStudio menyebut contoh gap antara skor FinanceBench 82.7% dan kesiapan deployment produksi, tetapi bukti snippet yang tersedia tidak cukup untuk memastikan konteks metodologi, pembanding, atau apakah angka itu diklaim sebagai skor resmi Claude Opus 4.7 [3].
Untuk GPT-5.5, satu-satunya bukti langsung yang tersedia adalah unggahan X yang menyatakan GPT-5.5 underperform terhadap Mythos pada SWE-Bench Pro dan HLE, setara pada GPQA Diamond, BrowseComp, dan OSWorld-Verified, serta lebih baik pada Terminal-Bench 2.0 [31]. Bukti ini lemah untuk riset benchmark karena tidak menyediakan angka, metodologi, atau sumber primer [31].
Untuk DeepSeek V4, tidak ada benchmark langsung dalam bukti yang diberikan; satu-satunya data terkait DeepSeek menyebut DeepSeek V3.2 sebagai #3 rekomendasi coding April 2026 dengan 89.2% SWE-bench menurut MangoMind, bukan DeepSeek V4 [2]. Insufficient evidence.
Untuk Kimi K2.6, tidak ada benchmark langsung dalam bukti yang diberikan; Stanford HAI hanya menyebut KimiK2.5 berada dalam kelompok 70–76% pada SWE-bench Verified per Februari 2026, bukan Kimi K2.6 [1]. Insufficient evidence.
Sumber paling kuat yang tersedia adalah Stanford HAI karena bersifat teknis dan institusional, tetapi datanya tidak mencakup Claude Opus 4.7, GPT-5.5, DeepSeek V4, atau Kimi K2.6 secara langsung; sumber itu hanya memberi baseline per Februari 2026 untuk Claude 4.5 Opus, KimiK2.5, GPT-5.2, dan model lain [1].
LLM Stats, BenchLM, MindStudio, Vellum, The Next Web, dan MangoMind memberikan konteks pasar serta benchmark yang lebih baru, tetapi sebagian tampak sebagai ringkasan pihak ketiga dan bukan dokumentasi primer dari lab model [2][3][4][5][6][7].
Vellum mencantumkan area benchmark untuk Claude Opus 4.7 seperti SWE-bench Verified, SWE-bench Pro, Terminal-Bench 2.0, MCP-Atlas, Finance Agent v1.1, OSWorld-Verified, BrowseComp, GPQA, dan benchmark reasoning lain, tetapi snippet yang tersedia tidak memberikan angka spesifik yang bisa dipakai untuk perbandingan [5].
MangoMind menyediakan daftar rekomendasi April 2026 untuk coding, tetapi model yang disebut adalah Claude Opus 4.6, GPT-5.4 Pro, dan DeepSeek V3.2, bukan versi target Claude Opus 4.7, GPT-5.5, DeepSeek V4, atau Kimi K2.6 [2].
Limitations / uncertainty
Tidak ada bukti primer dari Anthropic, OpenAI, DeepSeek, atau Moonshot/Kimi dalam evidence yang tersedia, sehingga angka-angka harus diperlakukan sebagai laporan pihak ketiga, bukan hasil resmi yang sepenuhnya terverifikasi.
Tidak tersedia angka benchmark langsung untuk DeepSeek V4 dan Kimi K2.6, sehingga klaim bahwa salah satu lebih unggul dari Claude Opus 4.7 atau GPT-5.5 tidak dapat didukung.
Tidak tersedia angka benchmark lengkap untuk GPT-5.5; unggahan X hanya menyebut perbandingan relatif terhadap Mythos tanpa metodologi dan tanpa skor numerik [31].
Ada indikasi pergeseran benchmark: GPQA Diamond tampak hampir jenuh pada model frontier karena Claude Opus 4.7, GPT-5.4 Pro, dan Gemini 3.1 Pro berada di sekitar 94.2–94.4% menurut The Next Web [6]. Ini berarti benchmark seperti SWE-bench Pro, Terminal-Bench, OSWorld, BrowseComp, dan evaluasi agentic kemungkinan lebih berguna untuk membedakan model, tetapi bukti angka lintas empat model target belum tersedia.
Summary
Claude Opus 4.7 adalah satu-satunya model dalam daftar yang memiliki bukti benchmark cukup konkret: 87.6% pada SWE-bench Verified, 94.2% pada GPQA, dan skor BenchLM 97/100 menurut sumber pihak ketiga [7][4]. GPT-5.5 hanya memiliki bukti lemah berupa klaim relatif dari X tanpa angka lengkap [31]. DeepSeek V4 dan Kimi K2.6 tidak memiliki data benchmark langsung dalam evidence yang tersedia, sehingga status benchmark keduanya adalah Insufficient evidence.
Orang-orang juga bertanya
Apa jawaban singkat untuk "Lakukan riset mendalam tentang benchmark Claude Opus 4.7, GPT-5.5, DeepSeek V4, dan Kimi K2.6."?
Claude Opus 4.7 dilaporkan mencetak 87.6% pada SWE-bench Verified, 94.2% pada GPQA, memiliki konteks 1 juta token, peningkatan vision 3.3x, mode effort “xhigh”, dan harga $5/$25 menurut LLM Stats.
Apa poin penting yang harus divalidasi terlebih dahulu?
Claude Opus 4.7 dilaporkan mencetak 87.6% pada SWE-bench Verified, 94.2% pada GPQA, memiliki konteks 1 juta token, peningkatan vision 3.3x, mode effort “xhigh”, dan harga $5/$25 menurut LLM Stats. Claude Opus 4.7 juga dilaporkan menempati peringkat #2 dari 110 model pada leaderboard provisional BenchLM dengan skor keseluruhan 97/100, serta peringkat #2 dari 14 pada verified leaderboard.
Apa yang harus saya lakukan selanjutnya dalam latihan?
Pada GPQA Diamond, laporan The Next Web menyebut Claude Opus 4.7 mencetak 94.2%, GPT-5.4 Pro 94.4%, dan Gemini 3.1 Pro 94.3%; sumber itu menilai selisihnya berada dalam noise dan benchmark ini sudah cenderung jenuh di antara model frontier.
Topik terkait manakah yang harus saya jelajahi selanjutnya?
Lanjutkan dengan "GPT-5.5, Claude Opus 4.7, Kimi K2.6 और DeepSeek V4 के बेंचमार्क पर शोध करें और एक अच्छी शोध रिपोर्ट तैयार करें।" untuk sudut pandang lain dan kutipan tambahan.
5. Monthly Updates AI moves fast. We re-test all models monthly and publish updated rankings to reflect the latest releases. ## 🎯 Quick Recommendations ### Best AI for Coding (April 2026) 1. •Claude Opus 4.6 - 93.2% SWE-bench 2. •GPT-5.4 Pro - 91.1% SWE-bench 3. •DeepSeek V3.2 - 89.2% SWE-bench ### Best AI for Reasoning 1. •GPT-5.4 Pro - 94.5% GPQA Diamond 2. •Claude Opus 4.6 - 93.1% GPQA Diamond 3. •Gemini 3.1 Pro - 92.4% GPQA Diamond ### Best AI for Creative Writing 1. •GPT-5.4 Pro - Highest creativity scores 2. •Claude Opus 4.6 - Best narrative coherence 3. •Gemini 3.1 Pro - Most dive…
Star on GitHub 55.8KGo to Console Start building for free Sign upGo to Console Start building for free Products Docs Pricing Customers Blog Changelog Star on GitHub 55.8K Blog/GPT-5.5 is here: benchmarks, pricing, and what changes for developers Apr 24, 2026•8 min # GPT-5.5 is here: benchmarks, pricing, and what changes for developers OpenAI shipped GPT-5.5 on April 23, 2026. Here's a source-backed look at benchmarks, pricing versus GPT-5.4 and Claude Opus 4.7, the system card, and where the model still falls short. Image 13: Atharva Deosthale #### Atharva Deosthale Developer Advocate SHARE 7…
MCP-Atlas: Claude Opus 4.7 scores 79.1% versus GPT-5.5's 75.3%. For teams heavily invested in multi-tool orchestration via the Model Context Protocol, Claude's lead on this benchmark reflects better tool-call reliability in complex, chained scenarios. A note on methodology: OpenAI's system card includes an asterisk on SWE-bench Pro noting 'evidence of memorization' from other labs. Anthropic has published a filter re-score analysis showing their Opus 4.7 margin holds on decontaminated subsets. OpenAI did not publish a matched re-run. Keep this context in mind when comparing SWE-bench Pro scor…
Evaluations ##### Coding EvalGPT-5.5GPT‑5.4GPT-5.5 ProGPT‑5.4 ProClaude Opus 4.7Gemini 3.1 Pro SWE-Bench Pro (Public) 58.6%57.7%--64.3%54.2% Terminal-Bench 2.0 82.7%75.1%--69.4%68.5% Expert-SWE (Internal)73.1%68.5%---- Labs have noted evidence of memorization(opens in a new window) on this eval ##### Professional EvalGPT-5.5GPT‑5.4GPT-5.5 ProGPT‑5.4 ProClaudeOpus 4.7Gemini 3.1 Pro GDPval (wins or ties)84.9%83.0%82.3%82.0%80.3%67.3% FinanceAgent v1.1 60.0%56.0%-61.5%64.4%59.7% Investment Banking Modeling Tasks (Internal)88.5%87.3%88.6%83.6%-- OfficeQA Pro 54.1%53.2%--43.6%18.1% ##### Compu…
On SWE-Bench Pro, it reached 58.6%, solving more real-world GitHub issues in a single pass than earlier versions. The model also outperformed its predecessor in long-horizon engineering tasks measured by internal benchmarks. These tasks often take human developers up to 20 hours to complete. > Introducing GPT-5.5 > > A new class of intelligence for real work and powering agents, built to understand complex goals, use tools, check its work, and carry more tasks through to completion. It marks a new way of getting computer work done. > > Now available in ChatGPT and Codex. pic.twitter.com/rPLTk…
| Consider applying for YC's Summer 2026 batch! Applications are open till May 4 Guidelines | FAQ | Lists | API | Security | Legal | Apply to YC | Contact | [...] | | | | 6thbit 1 day ago | parent | context | favorite | on: GPT-5.5
Mythos 5.5 SWE-bench Pro 77.8% 58.6% Terminal-bench-2.0 82.0% 82.7% GPQA Diamond 94.6% 93.6% H. Last Exam 56.8% 41.4% H. Last Exam (tools) 64.7% 52.2% BrowseComp 86.9% 84.4% (90.1% Pro) OSWorld-Verified 79.6% 78.7%
Still far from Mythos on SWE-bench but quite comparable otherwise. Source for mythos values: | | | | | | --- | | | | | aliljet 1 day ago | next…
leo 🐾 on X: "Perspective helps! GPT-5.5 underperforms Mythos on: - SWE-Bench Pro - HLE It is basically on-par on: - GPQA Diamond - BrowseComp - OSWorld-Verified It is better on: - Terminal-Bench 2.0 All while being more token efficient, smaller and cheaper than Mythos (and actually" / X Don’t miss what’s happening People on X are the first to know. Log in Sign up # Quote Image 3 leo Image 4: 🐾 @synthwavedd · Apr 23 GPT-5.5 benchmarks are out Benchmark results are more incremental, but in real world use it feels like a larger jump, especially for 5.5 Pro in my experience. Sort of similar t…
On SWE-bench Verified, top models are tightly clustered in the low-to-mid 70s (Figure 2.5.1). As of February 2026, Claude 4.5 Opus (high reasoning) led at approximately 76.8%, with several others including KimiK2.5, GPT-5.2, and Gemini 3 Flash (high reasoning) grouped between 70% and 76%. This is a pattern seen across several benchmarks in this chapter, where high-performing models score within a few percentage points of each other. SWE-bench 101 2.5 PERFORMANCE IN SPECIFIC DOMAINS | TECHNICAL PERFORMANCE | AI INDEX REPORT 2026 44.00% 46.00% 47.00% 48.00% 48.33% 49.67% 56.67% 58.33% 60.00% 60…
This matters for teams evaluating Opus 4.7 for production use because the model’s capability gains are only useful if they’re integrated into something that works end-to-end. The gap between “this model scores 82.7% on FinanceBench” and “we have a deployed tool our finance team actually uses” is usually infrastructure, not intelligence. You can try Remy at mindstudio.ai/remy. ## Frequently Asked Questions ### What score did Claude Opus 4.7 get on SWE-bench? Claude Opus 4.7 scored 82.4% on SWE-bench Verified. This is a meaningful gain over Opus 4.6’s approximately 71% and reflects genuine impr…
Core Rankings Specialized Use Cases Dashboards Directories Guides & Lists Tools # Claude Opus 4.7 According to BenchLM.ai, Claude Opus 4.7 ranks #2 out of 110 models on the provisional leaderboard with an overall score of 97/100. It also ranks #2 out of 14 on the verified leaderboard. This places it among the top tier of AI models available in 2026, competing directly with the strongest models from leading AI labs. Claude Opus 4.7 is a proprietary model with a 1M token context window. It processes queries without explicit chain-of-thought reasoning, offering faster response times and lower to…
Apr 16, 2026•16 min•ByNicolas Zeeb Guides CONTENTS Key observations of reported benchmarks Coding capabilities SWE-bench Verified SWE-bench Pro Terminal-Bench 2.0 Agentic capabilities MCP-Atlas (Scaled tool use) Finance Agent v1.1 OSWorld-Verified (Computer use) BrowseComp (Agentic search) Reasoning capabilities GPQA Diamond (Graduate-level science) Humanity's Last Exam Multimodal and vision capabilities CharXiv Reasoning (Visual reasoning) Multilingual Q&A (MMMLU) Safety and alignment What these benchmarks really mean for your agents When to use Opus 4.6 vs Opus 4.7 Use Opus 4.7 with your Ve…
On graduate-level reasoning, measured by GPQA Diamond, the field has converged. Opus 4.7 scores 94.2%, GPT-5.4 Pro scores 94.4%, and Gemini 3.1 Pro scores 94.3%. The differences are within noise. The frontier models have effectively saturated this benchmark, which means the competitive differentiation is shifting away from raw reasoning scores and toward applied performance on complex, multi-step tasks. ## The agentic step [...] ## Get the TNW newsletter Get the most important tech news in your inbox each week. Published April 16, 2026 - 3:49 pm UTC Back to top The heart of tech []( []( []( […
LLM Stats Logo Make AI phone calls with one API call # Claude Opus 4.7: Benchmarks, Pricing, Context & What's New Claude Opus 4.7 scores 87.6% on SWE-bench Verified, 94.2% on GPQA, 1M token context, 3.3x higher-resolution vision, new xhigh effort level. $5/$25 pricing. Jonathan Chavez The Takeaway Claude Opus 4.7 is a direct upgrade to Opus 4.6 at the same price ($5/$25 per million tokens), with 87.6% on SWE-bench Verified (+6.8pp), a new xhigh effort level, 3.3x higher-resolution vision, and self-verification on long-running agentic tasks. Claude Opus 4.7: Benchmarks, Pricing, Context & What…
Image 15: logo > In our evals, we saw a double-digit jump in accuracy of tool calls and planning in our core orchestrator agents. As users leverage Hebbia to plan and execute on use cases like retrieval, slide creation, or document generation, Claude Opus 4.7 shows the potential to improve agent decision-making in these workflows. > > Adithya Ramanathan > > Head of Applied Research Image 16: logo > On Rakuten-SWE-Bench, Claude Opus 4.7 resolves 3x more production tasks than Opus 4.6, with double-digit gains in Code Quality and Test Quality. This is a meaningful lift and a clear upgrade for th…
Update: If you look at the transcript Claude claims to have switched to Playwright, which is confusing because I didn't think I had that configured. Posted 19th February 2026 at 4:48 am ## Recent articles Changes in the system prompt between Claude Opus 4.6 and 4.7 - 18th April 2026 Join us at PyCon US 2026 in Long Beach - we have new AI and security tracks this year - 17th April 2026 Qwen3.6-35B-A3B on my laptop drew me a better pelican than Claude Opus 4.7 - 16th April 2026 This is a link post by Simon Willison, posted on 19th February 2026. benchmarks 14django 588ai 1969openai 406generativ…
Core Rankings Specialized Use Cases Dashboards Directories Guides & Lists Tools # Software Engineering Benchmark Verified (SWE-bench Verified) A curated, human-verified subset of SWE-bench that tests models on resolving real GitHub issues from popular open-source Python repositories like Django, Flask, and scikit-learn. ## Top models on SWE-bench Verified — April 24, 2026 As of April 24, 2026, Claude Mythos Preview leads the SWE-bench Verified leaderboard with 93.9% , followed by Claude Opus 4.7 (Adaptive) (87.6%) and GPT-5.3 Codex (85%). Claude Mythos Preview Anthropic Claude Opus 4.7 (Adapt…
Q1: What is Claude Opus 4.7? Claude Opus 4.7 is the flagship Large Language Model released by Anthropic on April 16, 2026. It leads in multiple benchmarks, including coding (SWE-bench Verified 87.6%), Agent tool invocation, and scientific reasoning (GPQA Diamond 94.2%), outperforming GPT-5.4 and Gemini 3.1 Pro. Compared to Opus 4.6, it introduces the new "xhigh effort" deep reasoning mode, all while maintaining the same official pricing. Q2: Which is better, Claude Opus 4.7 or GPT-5.4? [...] | Dimension | Claude Opus 4.7 | Claude Opus 4.6 | GPT-5.4 | Gemini 3.1 Pro | --- --- | Release Date |…
Claude Opus 4.7 is available now. Credit: Samuel Boivin/NurPhoto via Getty Images Anthropic has been shipping products and making news at a blistering pace in 2026, and on Thursday, the AI company announced the launch of Claude Opus 4.7. Claude Opus 4.7 is Anthropic's most intelligent model available to the general public. Notably, Anthropic said in a press release") that Opus 4.7 is not as powerful as Claude Mythos, which Anthropic deemed too dangerous for public release. Claude Opus is a family of hybrid reasoning models capable of multi-step reasoning and advanced coding. Until the announc…
The Claude Opus 4.7 benchmarks on software engineering tasks show the clearest improvement. On SWE-Bench, the industry-standard benchmark for evaluating autonomous code repair across real GitHub issues, Opus 4.7 shows a meaningful step up from Opus 4.6, with early reported scores suggesting improvements in the range of 8–12 percentage points depending on task category (Source: community-reported testing via r/ClaudeAI and independent evaluations). On HumanEval, which tests functional code generation, Opus 4.7 continues to perform competitively. [...] ## Conclusion — the honest verdict on Clau…
Assessed April 24, 2026 Rankings consider pricing, capabilities, benchmarks, and real-world applicability and are refreshed as new models launch. Feedback? ## Specifications ## Performance Profile ## Performance Indices Source: Artificial Analysis This model was released recently. Independent benchmark evaluations are typically completed within days of release — these figures are preliminary and are likely to be updated as testing is finalised. ## Benchmark Scores ### Intelligence ### Technical ### Content Benchmark data from Artificial Analysis and Hugging Face How does GPT-5.5 (medium) stac…
We measure GPT-5.5’s controllability by running CoT-Control, an evaluation suite described in (Yueh-Han, 2026 ) that tracks the model’s ability to follow user instructions about their CoT. CoT-Control includes over 13,000 tasks built from established benchmarks: GPQA (Rein et al., 2023 ), MMLU-Pro (Hendrycks et al., 2020 ), HLE (Phan et al., 2025 ), BFCL (Patil et al., 2025 [11: From tool use to agentic evaluation of large language models.” Proceedings of the 42nd international conference on machine learning . Available at: .")]) and SWE-Bench Verified. Each task is created by pairing a bench…
959494949393 HLE 27 41 55 69 655552514037 BrowseComp BrowseComp is a benchmark comprising 1,266 questions that challenge AI agents to persistently navigate the internet in search of hard-to-find, entangled information. The benchmark measures agents' ability to exercise persistence in information gathering, demonstrate creativity in web navigation, and find concise, verifiable answers. Despite the difficulty of the questions, BrowseComp is simple and easy-to-use, as predicted answers are short and easily verifiable against reference answers. agents, reasoning, search 74 79 84 89 878684837978 S…
Terminal-Bench 2.0 measures the ability to complete real CLI workflows: multi-step tasks involving file manipulation, script execution, debugging, and tool coordination. GPT-5.5's 82.7% score is the highest ever recorded, though the margin over Claude Mythos Preview (~82.0%) is razor-thin - VentureBeat. The SWE-bench results reveal a nuanced picture. On SWE-bench Verified (the standard version), GPT-5.5 scores 88.7%, a strong result. But on SWE-bench Pro (harder, multi-file problems), Claude Opus 4.7 leads at 64.3% versus GPT-5.5's 58.6%. And the gated Claude Mythos Preview dominates at 77.8%…
2025 was the year of AI speed. 2026 will be the year of AI quality. The year 2025 will be remembered as the moment AI-assisted software development entered its acceleration era. Improvements in the capabilities of coding agents, copilots, and automated workflows allowed teams to move faster than ever. But alongside t... Get Started in 2 clicks. No credit card needed Install in VS Code Our early testing shows the model communicates more directly, finds higher-signal issues, and performs better in practical coding and review workflows. Note: During release, you can try GPT-5.5 in ChatGPT an…
ML News # GPT-5.5 Benchmark Scores OpenAI has introduced GPT 5.5 as its most capable model so far, emphasizing a shift from simple question answering toward systems that can carry out complex, multi step tasks Brett Young Share Comment Star Created on April 23, 2026|Updated on April 23, 2026 Comment OpenAI has introduced GPT 5.5 as its most capable model so far, emphasizing a shift from simple question answering toward systems that can carry out complex, multi step tasks. The model is designed to better understand what a user is trying to accomplish and then independently plan, execute, and…
Core Rankings Specialized Use Cases Dashboards Directories Guides & Lists Tools # GPT-5.5 According to BenchLM.ai, GPT-5.5 ranks #5 out of 112 models on the provisional leaderboard with an overall score of 89/100. It also ranks #2 out of 16 on the verified leaderboard. This places it among the top tier of AI models available in 2026, competing directly with the strongest models from leading AI labs. GPT-5.5 is a proprietary model with a 1M token context window. It uses explicit chain-of-thought reasoning, which typically improves performance on math and complex reasoning tasks at the cost of…
The Coding Case The strongest benchmark improvements show up in agentic coding. On Expert-SWE, an internal evaluation covering long-horizon coding tasks that OpenAI estimates take human engineers a median of 20 hours to complete, GPT-5.5 scores 73.1% against GPT-5.4's 68.5%. The gains hold on Terminal-Bench 2.0 and SWE-Bench Pro as well, and across all three, GPT-5.5 uses fewer tokens to get there. [...] The week of April 14, 2026 produced three significant AI releases aimed at the same enterprise audience. Alibaba… ### Google's New Deep Research Max Agent Scores 93% on Benchmarks Google'…