Nghiên cứu benchmarks của GPT-5.5, Claude Opus 4.7, DeepSeek V4, Kimi K2.6 và so sánh chúng một cách toàn diện nhất
Dựa trên bộ bằng chứng được cung cấp, không thể so sánh đầy đủ cả 5 mô hình vì không có dữ liệu benchmark cho Kimi K2.6; Insufficient evidence. Trong các benchmark có số liệu, Claude Opus 4.7 đứng đầu GPQA Diamond và...
Dựa trên bộ bằng chứng được cung cấp, không thể so sánh đầy đủ cả 5 mô hình vì không có dữ liệu benchmark cho Kimi K2.6; Insufficient evidence. Trong các benchmark có số liệu, Claude Opus 4.7 đứng đầu GPQA Diamond và Humanity’s Last Exam không dùng công cụ, GPT 5.5 Pro đứng đầu Humanity’s Last Exam có công cụ, còn GPT
Bài học chính
- Dựa trên bộ bằng chứng được cung cấp, không thể so sánh đầy đủ cả 5 mô hình vì không có dữ liệu benchmark cho Kimi K2.6; Insufficient evidence. Trong các benchmark có số liệu, Claude Opus 4.7 đứng đầu GPQA Diamond và Humanity’s Last Exam không dùng công cụ, GPT-5.5 Pro đứng đầu Humanity’s Last Exam
- **Claude Opus 4.7 mạnh nhất trong nhóm benchmark tri thức/lý luận khó không dùng công cụ**: Claude Opus 4.7 đạt 94.2% trên GPQA Diamond, cao hơn GPT-5.5 ở 93.6% và DeepSeek-V4-Pro-Max ở 90.1%. Claude Opus 4.7 cũng đạt 46.9% trên Humanity’s Last Exam không dùng công cụ, cao hơn GP
- **GPT-5.5 Pro dẫn đầu khi có công cụ**: Trên Humanity’s Last Exam có công cụ, GPT-5.5 Pro đạt 57.2%, cao hơn Claude Opus 4.7 ở 54.7%, GPT-5.5 ở 52.2% và DeepSeek-V4-Pro-Max ở 48.2%.
- **GPT-5.5 nổi bật nhất ở tác vụ terminal/agentic CLI**: Trên Terminal-Bench 2.0, GPT-5.5 đạt 82.7%, cao hơn Claude Opus 4.7 ở 69.4% và DeepSeek-V4-Pro-Max ở 67.9%. Terminal-Bench 2.0 được mô tả là benchmark đo khả năng hoàn thành workflow CLI thực tế gồm thao tác file, chạy scrip
- **DeepSeek-V4-Pro-Max có vị trí tốt về hiệu năng/chi phí nhưng chưa dẫn benchmark chính trong evidence**: Nguồn mô tả DeepSeek-V4 là “near state-of-the-art” với chi phí khoảng 1/6 so với Opus 4.7 và GPT-5.5, nhưng trong các số liệu benchmark được trích, DeepSeek-V4-Pro-Max không
- Dựa trên bộ bằng chứng được cung cấp, không thể so sánh đầy đủ cả 5 mô hình vì không có dữ liệu benchmark cho Kimi K2.6; Insufficient evidence. Trong các benchmark có số liệu, Claude Opus 4.7 đứng đầu GPQA Diamond và Humanity’s Last Exam không dùng công cụ, GPT-5.5 Pro đứng đầu H
- ## Key findings
Câu trả lời nghiên cứu
Dựa trên bộ bằng chứng được cung cấp, không thể so sánh đầy đủ cả 5 mô hình vì không có dữ liệu benchmark cho Kimi K2.6; Insufficient evidence. Trong các benchmark có số liệu, Claude Opus 4.7 đứng đầu GPQA Diamond và Humanity’s Last Exam không dùng công cụ, GPT-5.5 Pro đứng đầu Humanity’s Last Exam có công cụ, còn GPT-5.5 đứng đầu Terminal-Bench 2.0 [3]. DeepSeek-V4-Pro-Max ở gần nhóm đầu nhưng thua mô hình dẫn đầu trong các benchmark được trích dẫn, dù được mô tả là có chi phí khoảng 1/6 so với Opus 4.7 và GPT-5.5 [
3].
Key findings
-
Claude Opus 4.7 mạnh nhất trong nhóm benchmark tri thức/lý luận khó không dùng công cụ: Claude Opus 4.7 đạt 94.2% trên GPQA Diamond, cao hơn GPT-5.5 ở 93.6% và DeepSeek-V4-Pro-Max ở 90.1% [
3]. Claude Opus 4.7 cũng đạt 46.9% trên Humanity’s Last Exam không dùng công cụ, cao hơn GPT-5.5 Pro 43.1%, GPT-5.5 41.4% và DeepSeek-V4-Pro-Max 37.7% [
3].
-
GPT-5.5 Pro dẫn đầu khi có công cụ: Trên Humanity’s Last Exam có công cụ, GPT-5.5 Pro đạt 57.2%, cao hơn Claude Opus 4.7 ở 54.7%, GPT-5.5 ở 52.2% và DeepSeek-V4-Pro-Max ở 48.2% [
3].
-
GPT-5.5 nổi bật nhất ở tác vụ terminal/agentic CLI: Trên Terminal-Bench 2.0, GPT-5.5 đạt 82.7%, cao hơn Claude Opus 4.7 ở 69.4% và DeepSeek-V4-Pro-Max ở 67.9% [
3]. Terminal-Bench 2.0 được mô tả là benchmark đo khả năng hoàn thành workflow CLI thực tế gồm thao tác file, chạy script, debug và phối hợp công cụ [
7].
-
DeepSeek-V4-Pro-Max có vị trí tốt về hiệu năng/chi phí nhưng chưa dẫn benchmark chính trong evidence: Nguồn [
3] mô tả DeepSeek-V4 là “near state-of-the-art” với chi phí khoảng 1/6 so với Opus 4.7 và GPT-5.5, nhưng trong các số liệu benchmark được trích, DeepSeek-V4-Pro-Max không đứng đầu GPQA Diamond, Humanity’s Last Exam hoặc Terminal-Bench 2.0 [
3].
-
DeepSeek V4 có tín hiệu rủi ro hallucination: Nguồn [
2] cho biết DeepSeek V4 Pro Max đạt -10 trên AA-Omniscience, cải thiện 11 điểm so với V3.2 Reasoning ở -21, chủ yếu nhờ độ chính xác cao hơn [
2]. Cùng nguồn nói V4 Pro và V4 Flash có tỷ lệ hallucination “rất cao”, nhưng phần evidence bị cắt ở con số “94…”, nên không thể xác nhận chính xác tỷ lệ phần trăm [
2].
-
Kimi K2.6 không thể đánh giá từ bộ evidence này: Không có nguồn nào trong evidence cung cấp điểm benchmark, giá, độ trễ, coding score, reasoning score hoặc hallucination score cho Kimi K2.6; Insufficient evidence.
Bảng so sánh benchmark có số liệu
| Benchmark / năng lực | GPT-5.5 | GPT-5.5 Pro | Claude Opus 4.7 | DeepSeek-V4-Pro-Max | Kimi K2.6 | Mô hình dẫn đầu trong evidence |
|---|---|---|---|---|---|---|
| GPQA Diamond | 93.6% | Không có số liệu | 94.2% | 90.1% | Insufficient evidence | Claude Opus 4.7 [ |
| Humanity’s Last Exam, không dùng công cụ | 41.4% | 43.1% | 46.9% | 37.7% | Insufficient evidence | Claude Opus 4.7 [ |
| Humanity’s Last Exam, có công cụ | 52.2% | 57.2% | 54.7% | 48.2% | Insufficient evidence | GPT-5.5 Pro [ |
| Terminal-Bench 2.0 | 82.7% | Không có số liệu | 69.4% | 67.9% | Insufficient evidence | GPT-5.5 [ |
| AA-Omniscience | Không có số liệu | Không có số liệu | Không có số liệu | -10 | Insufficient evidence | Không đủ dữ liệu đối chiếu giữa 5 mô hình [ |
| SWE-Bench Pro | Không đủ số liệu | Không đủ số liệu | Có mốc 0.64 trong snippet | Snippet hiển thị “#11 of 11” nhưng không có điểm đầy đủ | Insufficient evidence | Không đủ dữ liệu lập ranking đầy đủ [ |
So sánh theo từng mục đích sử dụng
-
Nếu ưu tiên lý luận khoa học/tri thức khó: Claude Opus 4.7 có lợi thế nhẹ trên GPQA Diamond với 94.2%, so với GPT-5.5 ở 93.6% và DeepSeek-V4-Pro-Max ở 90.1% [
3].
-
Nếu ưu tiên bài kiểm tra tổng hợp cực khó không dùng tool: Claude Opus 4.7 dẫn Humanity’s Last Exam không dùng công cụ với 46.9%, cao hơn GPT-5.5 Pro 43.1% và GPT-5.5 41.4% [
3].
-
Nếu ưu tiên bài toán có tool: GPT-5.5 Pro là lựa chọn mạnh nhất trong evidence vì đạt 57.2% trên Humanity’s Last Exam có công cụ, cao hơn Claude Opus 4.7 ở 54.7% [
3].
-
Nếu ưu tiên workflow terminal, automation và tác vụ agentic CLI: GPT-5.5 vượt rõ rệt với 82.7% trên Terminal-Bench 2.0, trong khi Claude Opus 4.7 đạt 69.4% và DeepSeek-V4-Pro-Max đạt 67.9% [
3].
-
Nếu ưu tiên chi phí/hiệu năng: DeepSeek-V4 đáng chú ý vì được mô tả là đạt mức gần state-of-the-art với chi phí khoảng 1/6 so với Opus 4.7 và GPT-5.5 [
3]. Tuy nhiên, evidence không cung cấp bảng giá chi tiết hoặc giá token, nên không thể kiểm chứng sâu hơn về tổng chi phí sử dụng thực tế.
-
Nếu ưu tiên độ tin cậy và giảm hallucination: Evidence chỉ có dữ liệu hallucination cho DeepSeek V4, trong đó nguồn [
2] nói hallucination vẫn rất cao dù AA-Omniscience cải thiện [
2]. Không có dữ liệu hallucination tương đương cho GPT-5.5, Claude Opus 4.7 hoặc Kimi K2.6 trong evidence, nên không thể kết luận mô hình nào đáng tin cậy nhất về mặt này.
Evidence notes
-
Nguồn chính cho bảng so sánh số liệu giữa GPT-5.5, GPT-5.5 Pro, Claude Opus 4.7 và DeepSeek-V4-Pro-Max là [
3]. Các kết luận về mô hình đứng đầu từng benchmark trong bảng đều dựa trên các số liệu được trích trong [
3].
-
GPT-5.5 có tài liệu hệ thống riêng về đánh giá an toàn/điều khiển chuỗi suy luận: system card nói GPT-5.5 được đo bằng CoT-Control, một bộ đánh giá hơn 13,000 tác vụ xây dựng từ các benchmark như GPQA và MMLU-Pro [
1]. Tuy nhiên, evidence không cung cấp kết quả CoT-Control tương ứng cho Claude Opus 4.7, DeepSeek V4 hoặc Kimi K2.6, nên không thể dùng CoT-Control để so sánh ngang hàng [
1].
-
Nguồn [
6] cũng lặp lại rằng GPT-5.5 được đánh giá controllability bằng CoT-Control với hơn 13,000 tác vụ từ các benchmark đã có như GPQA và MMLU-Pro [
6]. Đây là bằng chứng hữu ích về phạm vi đánh giá GPT-5.5, nhưng không đủ để lập ranking giữa 5 mô hình [
6].
-
Nguồn [
4] có nhắc đến SWE-Bench Pro cho DeepSeek-V4-Pro-Max và hiển thị Claude Opus 4.7 ở mức 0.64 trong snippet, nhưng phần evidence không đủ đầy đủ để so sánh SWE-Bench Pro giữa tất cả mô hình [
4].
Limitations / uncertainty
-
Thiếu hoàn toàn dữ liệu Kimi K2.6: Không có benchmark nào cho Kimi K2.6 trong evidence, nên mọi xếp hạng có Kimi đều là Insufficient evidence.
-
Thiếu nguồn chính thức cho Claude Opus 4.7 và DeepSeek V4 trong bảng chính: Các số liệu so sánh trực tiếp chủ yếu đến từ nguồn [
3], không phải model card chính thức của từng nhà cung cấp trong evidence [
3].
-
Thiếu nhiều benchmark quan trọng: Evidence không cung cấp số liệu đầy đủ cho MMLU-Pro, AIME, LiveCodeBench, SWE-Bench Verified, MMMU, latency, context window, throughput hoặc giá token cho cả 5 mô hình.
-
Không thể kết luận “mô hình tốt nhất toàn diện” một cách tuyệt đối: Với evidence hiện có, chỉ có thể nói Claude Opus 4.7 dẫn một số benchmark reasoning không dùng tool, GPT-5.5/GPT-5.5 Pro dẫn các benchmark tool/terminal được trích, còn DeepSeek-V4-Pro-Max có lợi thế được mô tả về chi phí nhưng có cảnh báo hallucination [
2][
3].
Summary
-
Tốt nhất về GPQA Diamond: Claude Opus 4.7, 94.2% [
3].
-
Tốt nhất về Humanity’s Last Exam không tool: Claude Opus 4.7, 46.9% [
3].
-
Tốt nhất về Humanity’s Last Exam có tool: GPT-5.5 Pro, 57.2% [
3].
-
Tốt nhất về Terminal-Bench 2.0: GPT-5.5, 82.7% [
3].
-
Đáng chú ý về chi phí/hiệu năng: DeepSeek-V4, được mô tả là gần state-of-the-art với chi phí khoảng 1/6 so với Opus 4.7 và GPT-5.5 [
3].
-
Không thể đánh giá: Kimi K2.6, vì không có dữ liệu benchmark trong evidence; Insufficient evidence.
Hỗ trợ hình ảnh






Trao đổi nghiên cứu
Câu hỏi nghiên cứu
Nghiên cứu benchmarks của GPT-5.5, Claude Opus 4.7, DeepSeek V4, Kimi K2.6 và so sánh chúng một cách toàn diện nhất
Câu trả lời được trích dẫn
Dựa trên bộ bằng chứng được cung cấp, không thể so sánh đầy đủ cả 5 mô hình vì không có dữ liệu benchmark cho Kimi K2.6; Insufficient evidence. Trong các benchmark có số liệu, Claude Opus 4.7 đứng đầu GPQA Diamond và Humanity’s Last Exam không dùng công cụ, GPT-5.5 Pro đứng đầu Humanity’s Last Exam có công cụ, còn GPT-5.5 đứng đầu Terminal-Bench 2.0 [3]. DeepSeek-V4-Pro-Max ở gần nhóm đầu nhưng thua mô hình dẫn đầu trong các benchmark được trích dẫn, dù được mô tả là có chi phí khoảng 1/6 so với Opus 4.7 và GPT-5.5 [
3].
Key findings
-
Claude Opus 4.7 mạnh nhất trong nhóm benchmark tri thức/lý luận khó không dùng công cụ: Claude Opus 4.7 đạt 94.2% trên GPQA Diamond, cao hơn GPT-5.5 ở 93.6% và DeepSeek-V4-Pro-Max ở 90.1% [
3]. Claude Opus 4.7 cũng đạt 46.9% trên Humanity’s Last Exam không dùng công cụ, cao hơn GPT-5.5 Pro 43.1%, GPT-5.5 41.4% và DeepSeek-V4-Pro-Max 37.7% [
3].
-
GPT-5.5 Pro dẫn đầu khi có công cụ: Trên Humanity’s Last Exam có công cụ, GPT-5.5 Pro đạt 57.2%, cao hơn Claude Opus 4.7 ở 54.7%, GPT-5.5 ở 52.2% và DeepSeek-V4-Pro-Max ở 48.2% [
3].
-
GPT-5.5 nổi bật nhất ở tác vụ terminal/agentic CLI: Trên Terminal-Bench 2.0, GPT-5.5 đạt 82.7%, cao hơn Claude Opus 4.7 ở 69.4% và DeepSeek-V4-Pro-Max ở 67.9% [
3]. Terminal-Bench 2.0 được mô tả là benchmark đo khả năng hoàn thành workflow CLI thực tế gồm thao tác file, chạy script, debug và phối hợp công cụ [
7].
-
DeepSeek-V4-Pro-Max có vị trí tốt về hiệu năng/chi phí nhưng chưa dẫn benchmark chính trong evidence: Nguồn [
3] mô tả DeepSeek-V4 là “near state-of-the-art” với chi phí khoảng 1/6 so với Opus 4.7 và GPT-5.5, nhưng trong các số liệu benchmark được trích, DeepSeek-V4-Pro-Max không đứng đầu GPQA Diamond, Humanity’s Last Exam hoặc Terminal-Bench 2.0 [
3].
-
DeepSeek V4 có tín hiệu rủi ro hallucination: Nguồn [
2] cho biết DeepSeek V4 Pro Max đạt -10 trên AA-Omniscience, cải thiện 11 điểm so với V3.2 Reasoning ở -21, chủ yếu nhờ độ chính xác cao hơn [
2]. Cùng nguồn nói V4 Pro và V4 Flash có tỷ lệ hallucination “rất cao”, nhưng phần evidence bị cắt ở con số “94…”, nên không thể xác nhận chính xác tỷ lệ phần trăm [
2].
-
Kimi K2.6 không thể đánh giá từ bộ evidence này: Không có nguồn nào trong evidence cung cấp điểm benchmark, giá, độ trễ, coding score, reasoning score hoặc hallucination score cho Kimi K2.6; Insufficient evidence.
Bảng so sánh benchmark có số liệu
| Benchmark / năng lực | GPT-5.5 | GPT-5.5 Pro | Claude Opus 4.7 | DeepSeek-V4-Pro-Max | Kimi K2.6 | Mô hình dẫn đầu trong evidence |
|---|---|---|---|---|---|---|
| GPQA Diamond | 93.6% | Không có số liệu | 94.2% | 90.1% | Insufficient evidence | Claude Opus 4.7 [ |
| Humanity’s Last Exam, không dùng công cụ | 41.4% | 43.1% | 46.9% | 37.7% | Insufficient evidence | Claude Opus 4.7 [ |
| Humanity’s Last Exam, có công cụ | 52.2% | 57.2% | 54.7% | 48.2% | Insufficient evidence | GPT-5.5 Pro [ |
| Terminal-Bench 2.0 | 82.7% | Không có số liệu | 69.4% | 67.9% | Insufficient evidence | GPT-5.5 [ |
| AA-Omniscience | Không có số liệu | Không có số liệu | Không có số liệu | -10 | Insufficient evidence | Không đủ dữ liệu đối chiếu giữa 5 mô hình [ |
| SWE-Bench Pro | Không đủ số liệu | Không đủ số liệu | Có mốc 0.64 trong snippet | Snippet hiển thị “#11 of 11” nhưng không có điểm đầy đủ | Insufficient evidence | Không đủ dữ liệu lập ranking đầy đủ [ |
So sánh theo từng mục đích sử dụng
-
Nếu ưu tiên lý luận khoa học/tri thức khó: Claude Opus 4.7 có lợi thế nhẹ trên GPQA Diamond với 94.2%, so với GPT-5.5 ở 93.6% và DeepSeek-V4-Pro-Max ở 90.1% [
3].
-
Nếu ưu tiên bài kiểm tra tổng hợp cực khó không dùng tool: Claude Opus 4.7 dẫn Humanity’s Last Exam không dùng công cụ với 46.9%, cao hơn GPT-5.5 Pro 43.1% và GPT-5.5 41.4% [
3].
-
Nếu ưu tiên bài toán có tool: GPT-5.5 Pro là lựa chọn mạnh nhất trong evidence vì đạt 57.2% trên Humanity’s Last Exam có công cụ, cao hơn Claude Opus 4.7 ở 54.7% [
3].
-
Nếu ưu tiên workflow terminal, automation và tác vụ agentic CLI: GPT-5.5 vượt rõ rệt với 82.7% trên Terminal-Bench 2.0, trong khi Claude Opus 4.7 đạt 69.4% và DeepSeek-V4-Pro-Max đạt 67.9% [
3].
-
Nếu ưu tiên chi phí/hiệu năng: DeepSeek-V4 đáng chú ý vì được mô tả là đạt mức gần state-of-the-art với chi phí khoảng 1/6 so với Opus 4.7 và GPT-5.5 [
3]. Tuy nhiên, evidence không cung cấp bảng giá chi tiết hoặc giá token, nên không thể kiểm chứng sâu hơn về tổng chi phí sử dụng thực tế.
-
Nếu ưu tiên độ tin cậy và giảm hallucination: Evidence chỉ có dữ liệu hallucination cho DeepSeek V4, trong đó nguồn [
2] nói hallucination vẫn rất cao dù AA-Omniscience cải thiện [
2]. Không có dữ liệu hallucination tương đương cho GPT-5.5, Claude Opus 4.7 hoặc Kimi K2.6 trong evidence, nên không thể kết luận mô hình nào đáng tin cậy nhất về mặt này.
Evidence notes
-
Nguồn chính cho bảng so sánh số liệu giữa GPT-5.5, GPT-5.5 Pro, Claude Opus 4.7 và DeepSeek-V4-Pro-Max là [
3]. Các kết luận về mô hình đứng đầu từng benchmark trong bảng đều dựa trên các số liệu được trích trong [
3].
-
GPT-5.5 có tài liệu hệ thống riêng về đánh giá an toàn/điều khiển chuỗi suy luận: system card nói GPT-5.5 được đo bằng CoT-Control, một bộ đánh giá hơn 13,000 tác vụ xây dựng từ các benchmark như GPQA và MMLU-Pro [
1]. Tuy nhiên, evidence không cung cấp kết quả CoT-Control tương ứng cho Claude Opus 4.7, DeepSeek V4 hoặc Kimi K2.6, nên không thể dùng CoT-Control để so sánh ngang hàng [
1].
-
Nguồn [
6] cũng lặp lại rằng GPT-5.5 được đánh giá controllability bằng CoT-Control với hơn 13,000 tác vụ từ các benchmark đã có như GPQA và MMLU-Pro [
6]. Đây là bằng chứng hữu ích về phạm vi đánh giá GPT-5.5, nhưng không đủ để lập ranking giữa 5 mô hình [
6].
-
Nguồn [
4] có nhắc đến SWE-Bench Pro cho DeepSeek-V4-Pro-Max và hiển thị Claude Opus 4.7 ở mức 0.64 trong snippet, nhưng phần evidence không đủ đầy đủ để so sánh SWE-Bench Pro giữa tất cả mô hình [
4].
Limitations / uncertainty
-
Thiếu hoàn toàn dữ liệu Kimi K2.6: Không có benchmark nào cho Kimi K2.6 trong evidence, nên mọi xếp hạng có Kimi đều là Insufficient evidence.
-
Thiếu nguồn chính thức cho Claude Opus 4.7 và DeepSeek V4 trong bảng chính: Các số liệu so sánh trực tiếp chủ yếu đến từ nguồn [
3], không phải model card chính thức của từng nhà cung cấp trong evidence [
3].
-
Thiếu nhiều benchmark quan trọng: Evidence không cung cấp số liệu đầy đủ cho MMLU-Pro, AIME, LiveCodeBench, SWE-Bench Verified, MMMU, latency, context window, throughput hoặc giá token cho cả 5 mô hình.
-
Không thể kết luận “mô hình tốt nhất toàn diện” một cách tuyệt đối: Với evidence hiện có, chỉ có thể nói Claude Opus 4.7 dẫn một số benchmark reasoning không dùng tool, GPT-5.5/GPT-5.5 Pro dẫn các benchmark tool/terminal được trích, còn DeepSeek-V4-Pro-Max có lợi thế được mô tả về chi phí nhưng có cảnh báo hallucination [
2][
3].
Summary
-
Tốt nhất về GPQA Diamond: Claude Opus 4.7, 94.2% [
3].
-
Tốt nhất về Humanity’s Last Exam không tool: Claude Opus 4.7, 46.9% [
3].
-
Tốt nhất về Humanity’s Last Exam có tool: GPT-5.5 Pro, 57.2% [
3].
-
Tốt nhất về Terminal-Bench 2.0: GPT-5.5, 82.7% [
3].
-
Đáng chú ý về chi phí/hiệu năng: DeepSeek-V4, được mô tả là gần state-of-the-art với chi phí khoảng 1/6 so với Opus 4.7 và GPT-5.5 [
3].
-
Không thể đánh giá: Kimi K2.6, vì không có dữ liệu benchmark trong evidence; Insufficient evidence.
Người ta cũng hỏi
Câu trả lời ngắn gọn cho "Nghiên cứu benchmarks của GPT-5.5, Claude Opus 4.7, DeepSeek V4, Kimi K2.6 và so sánh chúng một cách toàn diện nhất" là gì?
Dựa trên bộ bằng chứng được cung cấp, không thể so sánh đầy đủ cả 5 mô hình vì không có dữ liệu benchmark cho Kimi K2.6; Insufficient evidence. Trong các benchmark có số liệu, Claude Opus 4.7 đứng đầu GPQA Diamond và Humanity’s Last Exam không dùng công cụ, GPT-5.5 Pro đứng đầu Humanity’s Last Exam
Những điểm chính cần xác nhận đầu tiên là gì?
Dựa trên bộ bằng chứng được cung cấp, không thể so sánh đầy đủ cả 5 mô hình vì không có dữ liệu benchmark cho Kimi K2.6; Insufficient evidence. Trong các benchmark có số liệu, Claude Opus 4.7 đứng đầu GPQA Diamond và Humanity’s Last Exam không dùng công cụ, GPT-5.5 Pro đứng đầu Humanity’s Last Exam **Claude Opus 4.7 mạnh nhất trong nhóm benchmark tri thức/lý luận khó không dùng công cụ**: Claude Opus 4.7 đạt 94.2% trên GPQA Diamond, cao hơn GPT-5.5 ở 93.6% và DeepSeek-V4-Pro-Max ở 90.1%. Claude Opus 4.7 cũng đạt 46.9% trên Humanity’s Last Exam không dùng công cụ, cao hơn GP
Tôi nên làm gì tiếp theo trong thực tế?
**GPT-5.5 Pro dẫn đầu khi có công cụ**: Trên Humanity’s Last Exam có công cụ, GPT-5.5 Pro đạt 57.2%, cao hơn Claude Opus 4.7 ở 54.7%, GPT-5.5 ở 52.2% và DeepSeek-V4-Pro-Max ở 48.2%.
Tôi nên khám phá chủ đề liên quan nào tiếp theo?
Tiếp tục với "Tìm kiếm và kiểm chứng thông tin: Tạo ảnh bằng Gemini như thế nào?" để có góc nhìn khác và trích dẫn bổ sung.
Mở trang liên quanTôi nên so sánh điều này với cái gì?
Kiểm tra chéo câu trả lời này với "Nghiên cứu và kiểm chứng thông tin: Claude Opus 4.7 khác gì so với Opus 4.6 và Sonnet 4.6?".
Mở trang liên quanTiếp tục nghiên cứu của bạn
Nguồn
- [1] DeepSeek is back among the leading open weights models with V4 ...artificialanalysis.ai
Gains in knowledge but an increase in hallucination rate: DeepSeek V4 Pro (Max) scores -10 on AA-Omniscience, an 11 point improvement over V3.2 (Reasoning, -21), driven primarily by higher accuracy. V4 Flash (Max) scores -23, broadly in line with V3.2. V4 P...
- [2] DeepSeek-V4 arrives with near state-of-the-art intelligence at 1/6th ...venturebeat.com
BenchmarkDeepSeek-V4-Pro-MaxGPT-5.5GPT-5.5 Pro, where shownClaude Opus 4.7Best result among these GPQA Diamond90.1%93.6%—94.2%Claude Opus 4.7 Humanity’s Last Exam, no tools37.7%41.4%43.1%46.9%Claude Opus 4.7 Humanity’s Last Exam, with tools48.2%52.2%57.2%54...
- [3] DeepSeek-V4-Pro-Max: Pricing, Benchmarks & Performancellm-stats.com
SWE-Bench ProView → 11 of 11 Image 35: LLM Stats Logo SWE-Bench Pro is an advanced version of SWE-Bench that evaluates language models on complex, real-world software engineering tasks requiring extended reasoning and multi-step problem solving. More 1Image...
- [4] GPT-5.5 is here: benchmarks, pricing, and what changes ... - Appwriteappwrite.io
Star on GitHub 55.8KGo to Console Start building for free Sign upGo to Console Start building for free Products Docs Pricing Customers Blog Changelog Star on GitHub 55.8K Blog/GPT-5.5 is here: benchmarks, pricing, and what changes for developers Apr 24, 202...
- [5] GPT-5.5: The Complete Guide (2026) - o-mega | AIo-mega.ai
Terminal-Bench 2.0 measures the ability to complete real CLI workflows: multi-step tasks involving file manipulation, script execution, debugging, and tool coordination. GPT-5.5's 82.7% score is the highest ever recorded, though the margin over Claude Mytho...
- [6] SWE-bench February 2026 leaderboard updatesimonwillison.net
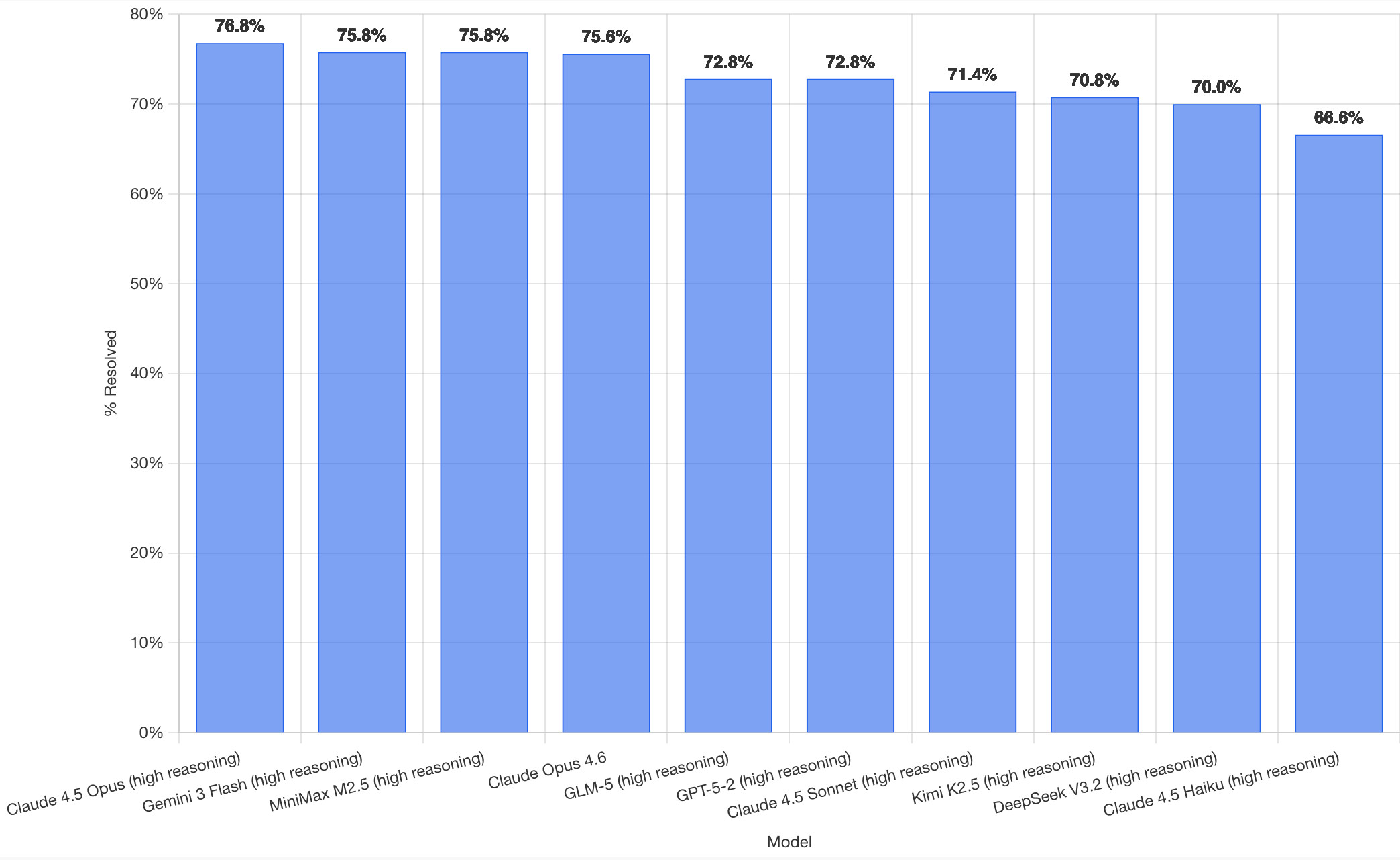
Here's how the top ten models performed: Image 1: Bar chart showing "% Resolved" by "Model". Bars in descending order: Claude 4.5 Opus (high reasoning) 76.8%, Gemini 3 Flash (high reasoning) 75.8%, MiniMax M2.5 (high reasoning) 75.8%, Claude Opus 4.6 75.6%,...
- [7] GPQA Leaderboard 2026 - Compare AI Model Scorespricepertoken.com
Z Z AI GLM 4.7 $0.390 $1.750 66.4 Try AL Alibaba Qwen3 30B A3B Instruct 2507 $0.090 $0.300 65.9 Try Image 89: Anthropic Anthropic Claude 3.7 Sonnet $3.000 $15.000 65.6 Try X Xiaomi MiMo-V2-Flash $0.090 $0.290 65.6 Try Image 90: ByteDance Seed ByteDance Seed...
- [8] GPT-5.5: Pricing, Benchmarks & Performance - LLM Statsllm-stats.com
9Image 42GPT-5 mini 0.22 10Image 43o3 0.16 GPQAView → 4 of 10 Image 44: LLM Stats Logo A challenging dataset of 448 multiple-choice questions written by domain experts in biology, physics, and chemistry. Questions are Google-proof and extremely difficult, w...
- [9] Kimi K2.6 vs DeepSeek-V4 Pro - Detailed Performance & Feature Comparisondocsbot.ai
Benchmark Kimi K2.6 DeepSeek-V4 Pro --- AIME 2026 American Invitational Mathematics Examination 2026 - Evaluates advanced mathematical problem-solving abilities (contest-level math) 96.4% Thinking mode Source Not available APEX Agents Evaluates long-horizon...
- [10] I reviewed how DeepSeek V4-Pro, Kimi 2.6, Opus 4.6, and Opus 4.7 ...news.ycombinator.com
ozgune 1 day ago parent context favorite on: DeepSeek v4 I reviewed how DeepSeek V4-Pro, Kimi 2.6, Opus 4.6, and Opus 4.7 across the same AI benchmarks. All results are for Max editions, except for Kimi. Summary: Opus 4.6 forms the baseline all three are tr...
- [11] LLM Leaderboard 2026 — Compare Top AI Models - Vellumvellum.ai
93.6% GPT-5.5 92.4% GPT 5.2 91.9% Gemini 3 Pro Best in Reasoning (GPQA Diamond) Model Score --- Claude 3 Opus 95.4% Claude Opus 4.7 94.2% GPT-5.5 93.6% GPT 5.2 92.4% Gemini 3 Pro 91.9% Best in High School Math (AIME 2025) 100%96%93%89%86% 100% Gemini 3 Pro...
- [12] DeepSeek V4 vs Claude vs GPT-5.4: A 38-Task Benchmark ... - FundaAIfundaai.substack.com
Coding (8 tasks): Standard DeepSeek Pro and Flash score about 8.1 avg. DeepSeek Pro (Thinking) scores 8.48 on 4 completed coding tasks and Flash (Thinking) scores 8.44 on 6 completed coding tasks, but hard coding timeouts make the thinking-mode results less...
- [13] OpenAI's GPT-5.5 masters agentic coding with 82.7% benchmark ...interestingengineering.com
On SWE-Bench Pro, it reached 58.6%, solving more real-world GitHub issues in a single pass than earlier versions. The model also outperformed ... 3 days ago
- [14] The Ultimate Guide to GPT-5.5 and SWE-Bench Pro - Skyworkskywork.ai
Specifically, it scores 64.30% on the Pro benchmark, compared to OpenAI's 58.60% (Digital Applied, 2026-04-23 12:00). However, OpenAI's model ... 2 days ago
- [15] Introducing GPT-5.5 - OpenAIopenai.com
Computer use and vision EvalGPT-5.5GPT‑5.4GPT-5.5 ProGPT‑5.4 ProClaudeOpus 4.7Gemini 3.1 Pro OSWorld-Verified 78.7%75.0%--78.0%- MMMU Pro (no tools)81.2%81.2%---80.5% MMMU Pro (with tools)83.2%82.1%---- Tool use EvalGPT-5.5GPT‑5.4GPT-5.5 ProGPT‑5.4 ProClaud...
- [16] Everything You Need to Know About GPT-5.5 - Vellumvellum.ai
GPT-5.5 benchmarks vs Claude Opus 4.7 — Terminal-Bench, SWE ... Source: GPT-5.5 System Card and Introducing GPT-5.5 by OpenAI, April 23, 2026. 1 day ago
- [17] GPT-5.5 pushes OpenAI further into the “agent era” of AI ... - Facebookfacebook.com
Benchmark Domination • SWE-Bench Verified: 77.9% (beats Claude's 77.2% and Gemini's 76.2%) • Internal SWE-Lancer: 79.9% (+13.6 point leap from ... 21 hours ago
- [18] Model Drop: GPT-5.5 - by Jake Handyhandyai.substack.com
Terminal-Bench 2.0 at 82.7% is a decisive lead on Opus 4.7 and Gemini 3.1 Pro. Expert-SWE at 73.1% introduces a brand-new OpenAI internal ... 3 days ago
- [19] GPT-5.5 benchmark results have been released : r/singularity - Redditreddit.com
Mostly only a small jump. They didn't bother including SWE-Bench Pro where it went from 57.6% to 58.6% (Mythos got 77.8%). 3 days ago
- [20] [PDF] GPT-5.5 System Card - Deployment Safety Hubdeploymentsafety.openai.com
We measure GPT-5.5’s controllability by running CoT-Control, an evaluation suite described in (Yueh-Han, 2026 ) that tracks the model’s ability to follow user instructions about their CoT. CoT-Control includes over 13,000 tasks built from established benchm...
- [21] GPT-5.5 System Card - OpenAI Deployment Safety Hubdeploymentsafety.openai.com
We measure GPT-5.5’s controllability by running CoT-Control, an evaluation suite described in (Yueh-Han, 2026 ) that tracks the model’s ability to follow user instructions about their CoT. CoT-Control includes over 13,000 tasks built from established benchm...
- [22] OpenAI's GPT-5.5: Benchmarks, Safety Classification, and Availabilitydatacamp.com
OpenAI's GPT-5.5: Benchmarks, Safety Classification, and Availability OpenAI's latest release focuses on execution, research, and dramatically improved inference efficiency. Apr 23, 2026 · 5 min read OpenAI's latest model, GPT-5.5, matches GPT-5.4 in per-to...
- [23] OpenAI GPT-5.5 Benchmark (CodeRabbit)coderabbit.ai
CodeRabbit logoCodeRabbit logo AgentEnterpriseCustomersPricingBlog Resources Docs Trust Center Contact Us FAQ Whitepapers Log InGet a free trial What changed in OpenAI GPT-5.5: Better judgment, stronger coding, better signal by Juan Pablo Flores Abhilash Ha...
- [24] AI Benchmarks 2026 - MMLU, GPQA, SWE-bench, MATH & More | AI Models Mapaimodelsmap.com
Model Provider Type Score Tier --- --- --- 1 🥇GPT-5.4 OpenAI standard 94.0% Elite 2 🥈GPT-5.2 OpenAI standard 93.5% Elite 3 🥉GPT-5 OpenAI standard 93.0% Elite 4 Gemini 3 Pro Google hybrid 92.5% Elite 5 o3 OpenAI reasoning 92.3% Elite 6 Claude Opus 4.6 Ant...
- [25] AI Benchmarks 2026 - MMLU, GPQA, SWE-bench, MATH & More | LM Market Caplmmarketcap.com
Model Provider Type Score Tier --- --- --- 1 🥇GPT-5.4 OpenAI standard 94.0% Elite 2 🥈GPT-5.2 OpenAI standard 93.5% Elite 3 🥉GPT-5 OpenAI standard 93.0% Elite 4 Gemini 3 Pro Google hybrid 92.5% Elite 5 o3 OpenAI reasoning 92.3% Elite 6 Claude Opus 4.6 Ant...
- [26] Independent GPT-5 Benchmarks: SWE-bench, AIME, GPQA Resultsbinaryverseai.com
MMMU (Massive Multi-disciplinary Multimodal Understanding) A benchmark assessing a model’s ability to understand and reason across multiple data types, including text, charts, diagrams, and images from diverse domains. MMLU Pro Massive Multitask Language Un...
- [27] GPT-5.5 just dropped (April 23) and it's the strongest agentic leap ...x.com
and it’s the strongest agentic leap from OpenAI yet. OpenAI released GPT-5.5 as their “smartest & most intuitive model yet” — built for real computer work with minimal hand-holding. Image 3: ✅It plans multi-step tasks, uses tools autonomously, checks its ow...
- [28] OpenAI launched GPT-5.5 on April 23, 2026. This new AI model is ...facebook.com
OpenAI launched GPT-5.5 on April... - Artificial Intelligence Facebook Log In Log In Forgot Account? Artificial Intelligence's Post []( Artificial Intelligence 19h · OpenAI launched GPT-5.5 on April 23, 2026. This new AI model is more intuitive and better f...