Nghiên cứu và kiểm chứng thông tin: Claude Opus 4.7 khác gì so với Opus 4.6 và Sonnet 4.6?
Claude Opus 4.7 là bản mạnh nhất đang được Anthropic phát hành rộng rãi, và khác Opus 4.6 chủ yếu ở chỗ nâng rõ chất lượng cho agentic coding, software engineering khó, nhiệm vụ dài hơi, độ bám chỉ dẫn và khả năng thị...
Claude Opus 4.7 là bản mạnh nhất đang được Anthropic phát hành rộng rãi, và khác Opus 4.6 chủ yếu ở chỗ nâng rõ chất lượng cho agentic coding, software engineering khó, nhiệm vụ dài hơi, độ bám chỉ dẫn và khả năng thị giác, trong khi vẫn giữ cùng mức giá Opus. [3][8] So với Sonnet 4.6, Opus 4.7 mạnh hơn cho tác vụ phức
Bài học chính
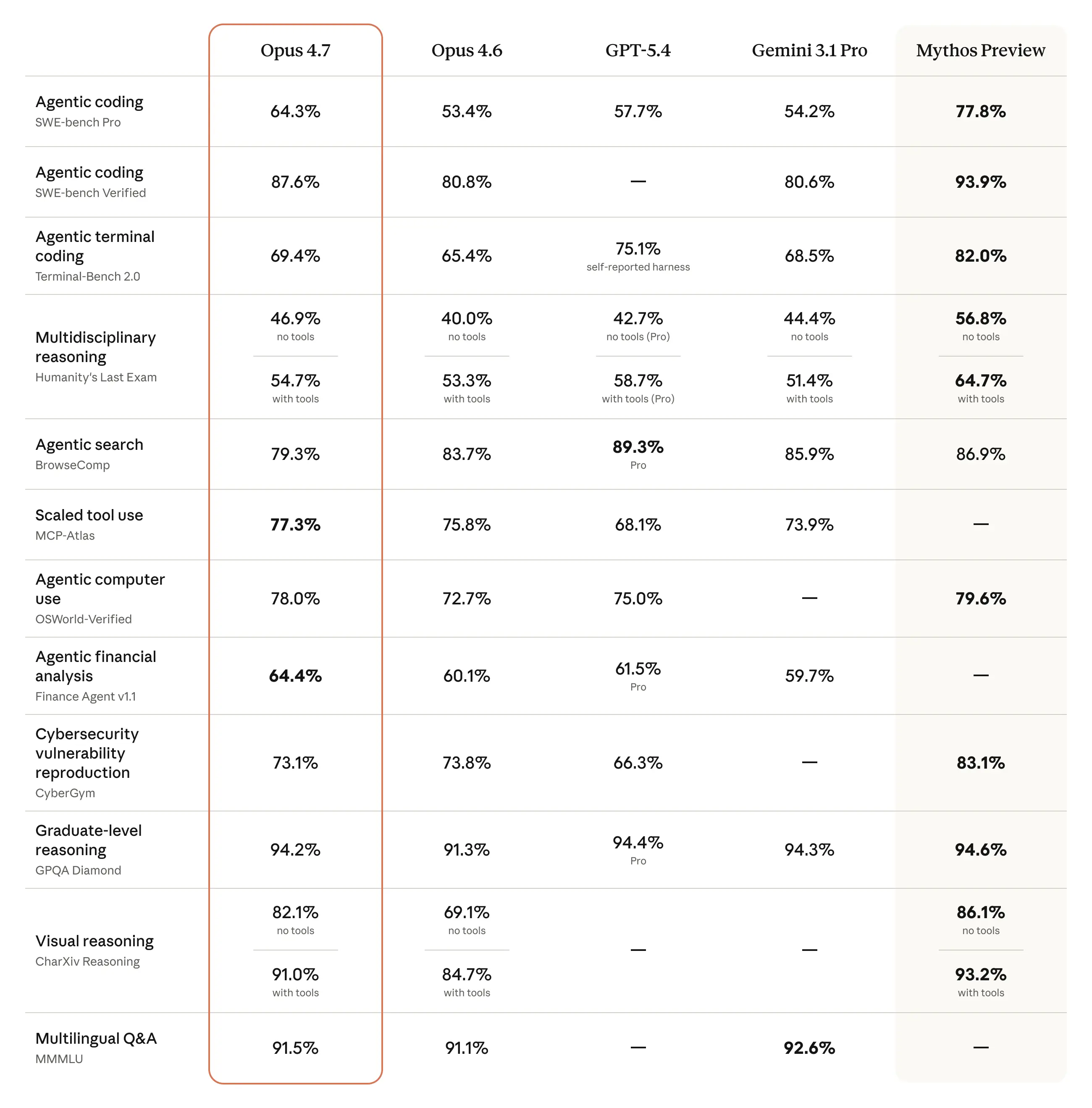
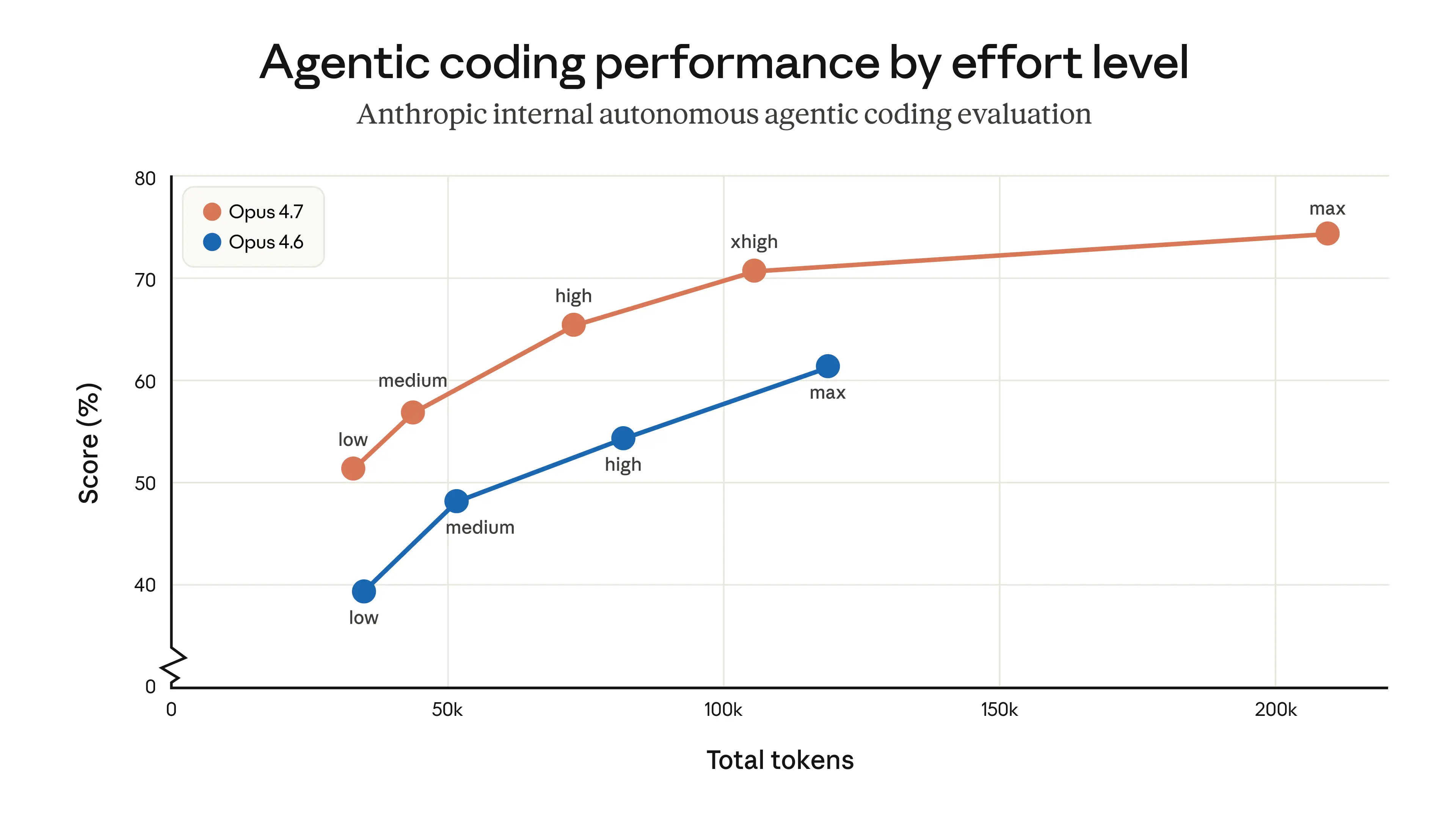
So với Opus 4.6, Opus 4.7 là bản nâng cấp về chất lượng hơn là đổi phân khúc: Anthropic nói 4.7 có “step-change” trong agentic coding so với 4.6, và là cải thiện đáng kể trong advanced software engineering, đặc biệt ở các bài toán khó nhất.
Anthropic mô tả Opus 4.7 làm các tác vụ dài hơi chặt chẽ và nhất quán hơn, chú ý chỉ dẫn chính xác hơn, và biết tự kiểm tra đầu ra trước khi báo lại; đây là điểm khác biệt vận hành quan trọng so với định vị của Opus 4.6.
Về thị giác, Anthropic nói Opus 4.7 có vision tốt hơn đáng kể và nhìn được ảnh ở độ phân giải cao hơn Opus 4.6.
Về giá và khả dụng, Opus 4.7 giữ nguyên giá của Opus 4.6 là $5 cho mỗi triệu input tokens và $25 cho mỗi triệu output tokens, và được phát hành rộng rãi trên Claude, API, Bedrock, Vertex AI và Microsoft Foundry.
Claude Opus 4.7 là bản mạnh nhất đang được Anthropic phát hành rộng rãi, và khác Opus 4.6 chủ yếu ở chỗ nâng rõ chất lượng cho agentic coding, software engineering khó, nhiệm vụ dài hơi, độ bám chỉ dẫn và khả năng thị giác, trong khi vẫn giữ cùng mức giá Opus. [3][8] So với Sonne
Key findings
Câu trả lời nghiên cứu
Claude Opus 4.7 là bản mạnh nhất đang được Anthropic phát hành rộng rãi, và khác Opus 4.6 chủ yếu ở chỗ nâng rõ chất lượng cho agentic coding, software engineering khó, nhiệm vụ dài hơi, độ bám chỉ dẫn và khả năng thị giác, trong khi vẫn giữ cùng mức giá Opus. [3][8] So với Sonnet 4.6, Opus 4.7 mạnh hơn cho tác vụ phức tạp nhưng đắt hơn và chậm hơn; cả hai cùng có context window 1M tokens, nhưng Opus 4.7 có max output 128k còn Sonnet 4.6 là 64k. [3]
Key findings
So với Opus 4.6, Opus 4.7 là bản nâng cấp về chất lượng hơn là đổi phân khúc: Anthropic nói 4.7 có “step-change” trong agentic coding so với 4.6, và là cải thiện đáng kể trong advanced software engineering, đặc biệt ở các bài toán khó nhất. [3][8]
Anthropic mô tả Opus 4.7 làm các tác vụ dài hơi chặt chẽ và nhất quán hơn, chú ý chỉ dẫn chính xác hơn, và biết tự kiểm tra đầu ra trước khi báo lại; đây là điểm khác biệt vận hành quan trọng so với định vị của Opus 4.6. [8]
Về thị giác, Anthropic nói Opus 4.7 có vision tốt hơn đáng kể và nhìn được ảnh ở độ phân giải cao hơn Opus 4.6. [8]
Về giá và khả dụng, Opus 4.7 giữ nguyên giá của Opus 4.6 là $5 cho mỗi triệu input tokens và $25 cho mỗi triệu output tokens, và được phát hành rộng rãi trên Claude, API, Bedrock, Vertex AI và Microsoft Foundry. [7][8]
Opus 4.6 trước đó đã mang vào dòng Opus các cải tiến lớn về coding, lập kế hoạch cẩn thận hơn, làm agentic tasks lâu hơn, xử lý codebase lớn tin cậy hơn, code review/debugging tốt hơn, và 1M token context window ở trạng thái beta. [7]
So với Sonnet 4.6, khác biệt lớn nhất của Opus 4.7 là định vị: docs của Anthropic xếp Opus 4.7 là “most capable generally available model” cho complex reasoning và agentic coding, còn Sonnet 4.6 là “best combination of speed and intelligence”. [3]
Về thông số hiện tại, Opus 4.7 và Sonnet 4.6 đều có context window 1M tokens, nhưng Opus 4.7 có max output 128k còn Sonnet 4.6 là 64k; Opus 4.7 có latency “moderate” còn Sonnet 4.6 là “fast”; giá của Opus 4.7 là $5/$25 còn Sonnet 4.6 là $3/$15 cho mỗi triệu input/output tokens. [3]
Docs hiện tại cũng liệt kê Opus 4.7 có adaptive thinking nhưng không có extended thinking, trong khi Sonnet 4.6 có cả adaptive thinking lẫn extended thinking. [3]
Sonnet 4.6 bản thân cũng là một nâng cấp lớn: Anthropic mô tả đây là nâng cấp toàn diện ở coding, computer use, long-context reasoning, agent planning, knowledge work và design, đồng thời là model mặc định trên claude.ai và Claude Cowork cho người dùng Free/Pro. [9]
Suy luận thực dụng từ cách Anthropic định vị sản phẩm: nếu bạn ưu tiên chất lượng tối đa cho coding/agent workflows khó và dài, Opus 4.7 hợp hơn; nếu bạn ưu tiên cost/performance và độ nhanh cho production diện rộng, Sonnet 4.6 hợp hơn. [3][8][9]
Evidence notes
Mình ưu tiên nguồn chính thức của Anthropic, nên các khác biệt về giá, khả dụng, context window, max output và positioning có độ tin cậy cao. [3][7][8][9]
Tuy vậy, phần “mạnh hơn bao nhiêu” về hiệu năng chủ yếu vẫn là tuyên bố và benchmark do Anthropic công bố trên tài liệu chính thức của họ, chưa phải kiểm chứng độc lập trong câu trả lời này. [7][8][9]
Nếu bạn cần bảng benchmark định lượng đầy đủ giữa cả ba model trên từng bài test, hiện là Insufficient evidence trong bộ nguồn mình đã truy xuất trực tiếp ở đây. [8][9]
Ngoài ra, mình chưa kiểm tra thêm benchmark bên thứ ba để đối chiếu độc lập với các tuyên bố của Anthropic. [7][8][9]
Summary
Tóm lại, Opus 4.7 là bản kế nhiệm mạnh hơn Opus 4.6 chủ yếu ở agentic coding, software engineering khó, tác vụ dài hơi, độ nhất quán và vision, nhưng không đổi giá Opus. [7][8] So với Sonnet 4.6, Opus 4.7 mạnh hơn và có output lớn hơn, còn Sonnet 4.6 nhanh hơn, rẻ hơn và được định vị là lựa chọn speed/intelligence tốt hơn cho nhiều workload production. [3][9]
Nếu bạn muốn, mình có thể làm tiếp một bảng 3 cột rất ngắn: “Opus 4.7 vs Opus 4.6 vs Sonnet 4.6” để bạn dùng ngay cho quyết định chọn model.
Hỗ trợ hình ảnh
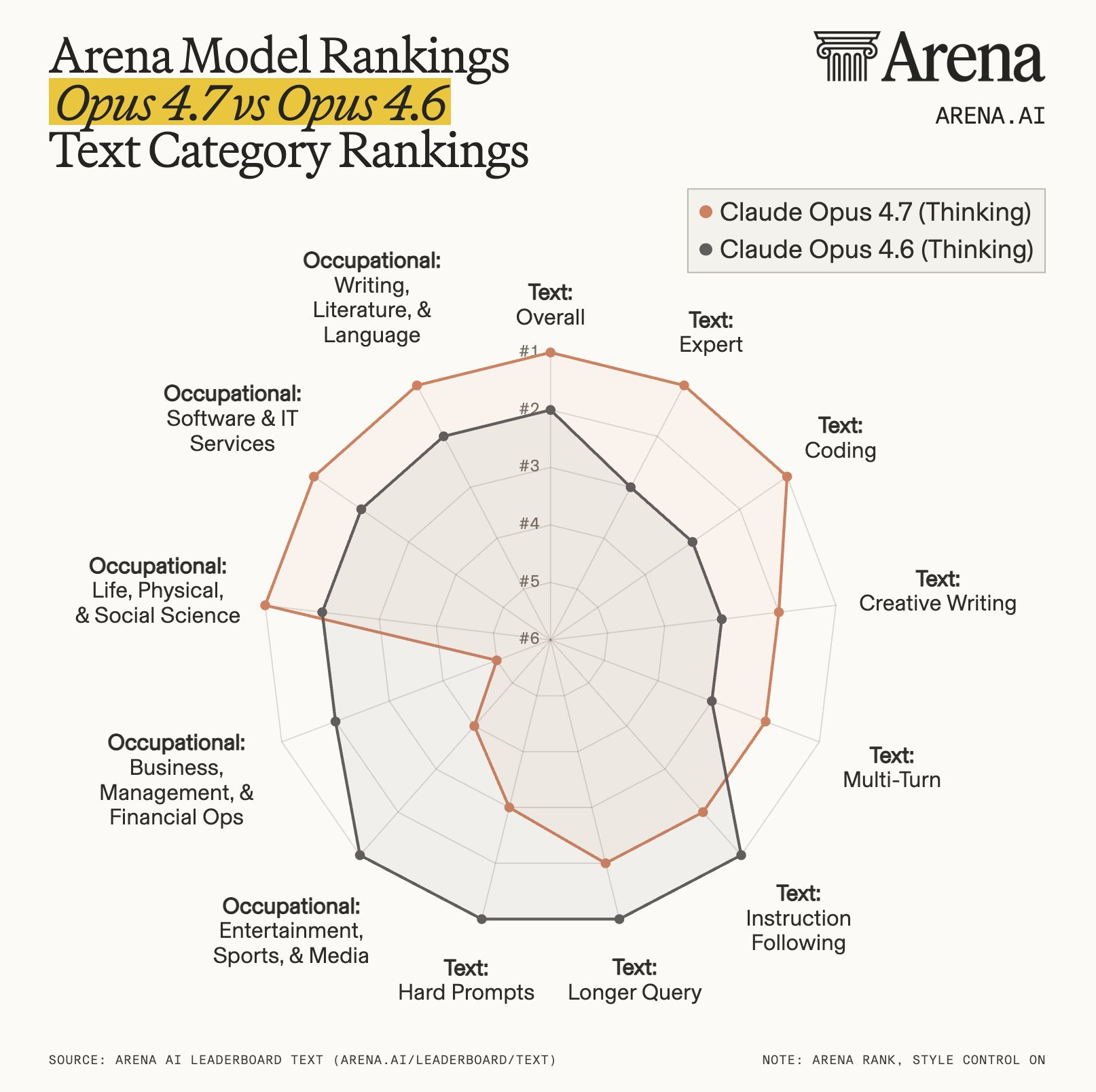
Claude Help Center76f3062d78ebbb04863fb1de3ef9cca0Introducing Claude Opus 4.7 \ AnthropicA graphic illustration featuring a stylized silhouette of a human head with neural network connections on the left and a playful abstract drawing of a face with question marks on the right, referencing the Anthropic Claude Opus 4.7 announcement.Introducing Claude Opus 4.7 \ AnthropicA comparative table displaying performance metrics of different AI models, highlighting the advancements of Anthropic's Claude Opus 4.7 over previous versions and competitors, with specific emphasis on its high score of 93.9% in Agentic coding.Introducing Claude Opus 4.7 \ AnthropicA bar chart compares the scores of different models and tests, showing that "Opus 4.7" has the highest average score among the groups, with error bars indicating some variation in the results.Introducing Claude Opus 4.7 \ AnthropicA line chart compares the performance of Claude Opus 4.7 and 4.6 in internal autonomous agentic coding evaluation, showing scores increasing with effort level.Introducing Claude Opus 4.7 \ AnthropicA bar chart comparing the correctness percentages of different AI models, with Anthropic Claude Opus 4.7 showing the highest score at 80.6%.ogThe Ultimate Guide to Claude Opus 4.7 - by Paweł HurynClaude Opus 4.7 is rated higher than Claude Opus 4.6 across various text categories, especially excelling in occupational and overall text ratings.Why is Claude Opus 4.7 less durable than 4.6The image displays a capability map for Claude Opus 4.7, contrasting real upgrade scenarios for various tasks with degradation in specific scenarios, highlighting the strengths of multi-file agent coding, IDE tasks, tool use, visual recognition, and computer use on the left, and challenging scenarios like long document1 million context window is now generally available forA line graph compares mean match ratios of different language models, showing that Opus 4.6 and Sonnet 4.6 maintain higher accuracy across increasing input tokens compared to GPT-5.4, Gemini 3.1 Pro, and Sonnet 4.5.Claude Opus 4.6 Pricing Guide 2026: API Costs, Plans, andA pricing comparison chart displaying different plans for Anthropic's Claude models, including details for API pricing, subscription, and team/enterprise options, with highlights on costs, features, and savings.Claude Sonnet 4.6: Specs, Benchmarks & Pricing 2026The image displays a comparison table of AI models, highlighting features, performance percentages, and release dates, with a focus on Claude Sonnet 4.6 released in February 2026.
Trao đổi nghiên cứu
Bạn
Câu hỏi nghiên cứu
Tìm kiếm và kiểm chứng thông tin: Claude Opus 4.7 khác gì so với Opus 4.6 và Sonnet 4.6?
Studio Global AI12 nguồn
Câu trả lời được trích dẫn
Mình chưa thể kiểm chứng chắc chắn “Claude Opus 4.7” khác gì so với Opus 4.6 và Sonnet 4.6, vì trong tập kết quả hiện có mình không thấy tài liệu chính thức từ Anthropic xác nhận hoặc mô tả rõ Opus 4.7; phần này hiện là Insufficient evidence. [1][4][5][6]
Những gì có thể tóm tắt khá chắc từ các nguồn bên thứ ba hiện có là: Opus 4.6 mạnh hơn, Sonnet 4.6 rẻ hơn và cân bằng hơn cho production; còn Opus 4.7 thì bằng chứng hiện tại chưa đủ để kết luận. [4][5][8]
Về Opus 4.7: trong các kết quả mình thu được, chỉ có một nguồn bên thứ ba nhắc trực tiếp tới “Claude Opus 4.7 vs 4.6”, nhưng không có release note hay doc chính thức của Anthropic đi kèm trong tập nguồn này, nên chưa nên coi đó là thông tin đã được xác minh. [6]
Về Opus 4.6 vs Sonnet 4.6: nhiều trang so sánh bên thứ ba liệt kê cả hai model với context window 1.0M tokens và max output 128K tokens, tức khác biệt chính không nằm ở kích thước ngữ cảnh. [9][10]
Opus 4.6 được các nguồn so sánh định vị là model mạnh hơn về coding và benchmark tổng thể. [4][5]
Sonnet 4.6 được mô tả là lựa chọn cân bằng hơn về tốc độ/chi phí, và một nguồn so sánh ghi nhận Sonnet 4.6 rẻ hơn khoảng 1.7x mỗi token so với Opus 4.6. [5][8]
Nói thực dụng: nếu bạn ưu tiên chất lượng tối đa, các nguồn hiện có nghiêng về Opus 4.6; nếu bạn ưu tiên cost/performance cho triển khai rộng, các nguồn hiện có nghiêng về Sonnet 4.6. [4][5][8]
Độ tin cậy cần lưu ý: các nguồn mình có ở đây chủ yếu là aggregator/comparison site như OpenRouter, llm-stats, AIViewer, Krater và Simtheory, chứ không phải tài liệu gốc của Anthropic. [1][4][5][9][10]
Nếu bạn muốn, mình có thể làm tiếp 1 trong 2 hướng:
viết cho bạn một bảng so sánh ngắn “đã kiểm chứng được / chưa kiểm chứng được”, hoặc
kiểm tra trực tiếp nếu bạn gửi link docs/release note Anthropic mà bạn đang tham chiếu.
Bạn
Câu hỏi nghiên cứu
Nghiên cứu và kiểm chứng thông tin: Claude Opus 4.7 khác gì so với Opus 4.6 và Sonnet 4.6?
Studio Global AI13 nguồn
Câu trả lời được trích dẫn
Claude Opus 4.7 là bản mạnh nhất đang được Anthropic phát hành rộng rãi, và khác Opus 4.6 chủ yếu ở chỗ nâng rõ chất lượng cho agentic coding, software engineering khó, nhiệm vụ dài hơi, độ bám chỉ dẫn và khả năng thị giác, trong khi vẫn giữ cùng mức giá Opus. [3][8] So với Sonnet 4.6, Opus 4.7 mạnh hơn cho tác vụ phức tạp nhưng đắt hơn và chậm hơn; cả hai cùng có context window 1M tokens, nhưng Opus 4.7 có max output 128k còn Sonnet 4.6 là 64k. [3]
Key findings
So với Opus 4.6, Opus 4.7 là bản nâng cấp về chất lượng hơn là đổi phân khúc: Anthropic nói 4.7 có “step-change” trong agentic coding so với 4.6, và là cải thiện đáng kể trong advanced software engineering, đặc biệt ở các bài toán khó nhất. [3][8]
Anthropic mô tả Opus 4.7 làm các tác vụ dài hơi chặt chẽ và nhất quán hơn, chú ý chỉ dẫn chính xác hơn, và biết tự kiểm tra đầu ra trước khi báo lại; đây là điểm khác biệt vận hành quan trọng so với định vị của Opus 4.6. [8]
Về thị giác, Anthropic nói Opus 4.7 có vision tốt hơn đáng kể và nhìn được ảnh ở độ phân giải cao hơn Opus 4.6. [8]
Về giá và khả dụng, Opus 4.7 giữ nguyên giá của Opus 4.6 là $5 cho mỗi triệu input tokens và $25 cho mỗi triệu output tokens, và được phát hành rộng rãi trên Claude, API, Bedrock, Vertex AI và Microsoft Foundry. [7][8]
Opus 4.6 trước đó đã mang vào dòng Opus các cải tiến lớn về coding, lập kế hoạch cẩn thận hơn, làm agentic tasks lâu hơn, xử lý codebase lớn tin cậy hơn, code review/debugging tốt hơn, và 1M token context window ở trạng thái beta. [7]
So với Sonnet 4.6, khác biệt lớn nhất của Opus 4.7 là định vị: docs của Anthropic xếp Opus 4.7 là “most capable generally available model” cho complex reasoning và agentic coding, còn Sonnet 4.6 là “best combination of speed and intelligence”. [3]
Về thông số hiện tại, Opus 4.7 và Sonnet 4.6 đều có context window 1M tokens, nhưng Opus 4.7 có max output 128k còn Sonnet 4.6 là 64k; Opus 4.7 có latency “moderate” còn Sonnet 4.6 là “fast”; giá của Opus 4.7 là $5/$25 còn Sonnet 4.6 là $3/$15 cho mỗi triệu input/output tokens. [3]
Docs hiện tại cũng liệt kê Opus 4.7 có adaptive thinking nhưng không có extended thinking, trong khi Sonnet 4.6 có cả adaptive thinking lẫn extended thinking. [3]
Sonnet 4.6 bản thân cũng là một nâng cấp lớn: Anthropic mô tả đây là nâng cấp toàn diện ở coding, computer use, long-context reasoning, agent planning, knowledge work và design, đồng thời là model mặc định trên claude.ai và Claude Cowork cho người dùng Free/Pro. [9]
Suy luận thực dụng từ cách Anthropic định vị sản phẩm: nếu bạn ưu tiên chất lượng tối đa cho coding/agent workflows khó và dài, Opus 4.7 hợp hơn; nếu bạn ưu tiên cost/performance và độ nhanh cho production diện rộng, Sonnet 4.6 hợp hơn. [3][8][9]
Evidence notes
Mình ưu tiên nguồn chính thức của Anthropic, nên các khác biệt về giá, khả dụng, context window, max output và positioning có độ tin cậy cao. [3][7][8][9]
Tuy vậy, phần “mạnh hơn bao nhiêu” về hiệu năng chủ yếu vẫn là tuyên bố và benchmark do Anthropic công bố trên tài liệu chính thức của họ, chưa phải kiểm chứng độc lập trong câu trả lời này. [7][8][9]
Nếu bạn cần bảng benchmark định lượng đầy đủ giữa cả ba model trên từng bài test, hiện là Insufficient evidence trong bộ nguồn mình đã truy xuất trực tiếp ở đây. [8][9]
Ngoài ra, mình chưa kiểm tra thêm benchmark bên thứ ba để đối chiếu độc lập với các tuyên bố của Anthropic. [7][8][9]
Summary
Tóm lại, Opus 4.7 là bản kế nhiệm mạnh hơn Opus 4.6 chủ yếu ở agentic coding, software engineering khó, tác vụ dài hơi, độ nhất quán và vision, nhưng không đổi giá Opus. [7][8] So với Sonnet 4.6, Opus 4.7 mạnh hơn và có output lớn hơn, còn Sonnet 4.6 nhanh hơn, rẻ hơn và được định vị là lựa chọn speed/intelligence tốt hơn cho nhiều workload production. [3][9]
Nếu bạn muốn, mình có thể làm tiếp một bảng 3 cột rất ngắn: “Opus 4.7 vs Opus 4.6 vs Sonnet 4.6” để bạn dùng ngay cho quyết định chọn model.
Người ta cũng hỏi
Câu trả lời ngắn gọn cho "Nghiên cứu và kiểm chứng thông tin: Claude Opus 4.7 khác gì so với Opus 4.6 và Sonnet 4.6?" là gì?
So với Opus 4.6, Opus 4.7 là bản nâng cấp về chất lượng hơn là đổi phân khúc: Anthropic nói 4.7 có “step-change” trong agentic coding so với 4.6, và là cải thiện đáng kể trong advanced software engineering, đặc biệt ở các bài toán khó nhất.
Những điểm chính cần xác nhận đầu tiên là gì?
So với Opus 4.6, Opus 4.7 là bản nâng cấp về chất lượng hơn là đổi phân khúc: Anthropic nói 4.7 có “step-change” trong agentic coding so với 4.6, và là cải thiện đáng kể trong advanced software engineering, đặc biệt ở các bài toán khó nhất. Anthropic mô tả Opus 4.7 làm các tác vụ dài hơi chặt chẽ và nhất quán hơn, chú ý chỉ dẫn chính xác hơn, và biết tự kiểm tra đầu ra trước khi báo lại; đây là điểm khác biệt vận hành quan trọng so với định vị của Opus 4.6.
Tôi nên làm gì tiếp theo trong thực tế?
Về thị giác, Anthropic nói Opus 4.7 có vision tốt hơn đáng kể và nhìn được ảnh ở độ phân giải cao hơn Opus 4.6.
Tôi nên khám phá chủ đề liên quan nào tiếp theo?
Tiếp tục với "Tìm kiếm và kiểm chứng thông tin: Tạo ảnh bằng Gemini như thế nào?" để có góc nhìn khác và trích dẫn bổ sung.
Usage analytics for Claude Cowork. For more information, see View usage analytics for Team and Enterprise plans. Users on Pro and Max plans can give Claude access to computer use. Users on Pro and Max plans can access a persistent agent thread via Claude Desktop or Claude for iOS/Android to manage tasks in Cowork. Claude Code access added to Team plan Standard seats. Max plan users can now access Claude’s memory capabilities. Claude’s memory on Enterprise plans. Premium seats with Claude Code for Team and Enterprise plans. Introduced a premium seat tier for Team and Enterp…
Start building with Claude. Everything you need to integrate Claude into your applications. From first API call to production. What do you want to build? import anthropic import anthropic client = anthropic.Anthropic() client = anthropic.Anthropic() message = client.messages.create(message = client.messages.create( model="claude-opus-4-7", model ="claude-opus-4-7", max_tokens=1024, max_tokens = 1024, messages=[{ messages =[{ "role": "user", "role": "user", "content": "Hello, Claude" "content": "Hello, Claude" }] }]))print(message.content[0].text) print(message.content[0].text). ## Choose ho…
Skip to main contentSkip to footer. . * Extended thinking with tool use (beta): Both models can use tools—like web search—during extended thinking, allowing Claude to alternate between reasoning and tool use to improve responses. Get started today on [Claude](https:…
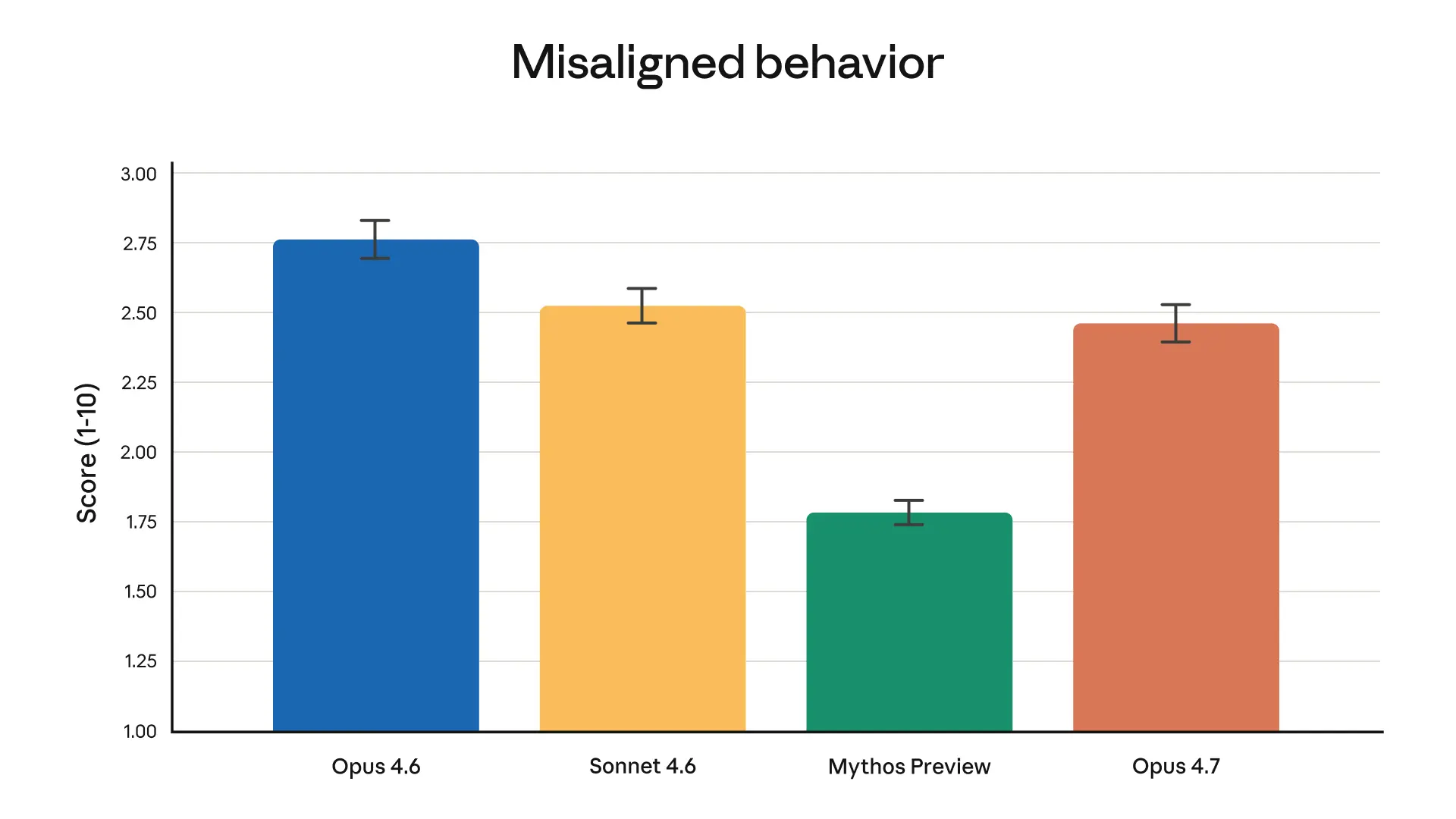
As we show in our extensive system card, Opus 4.6 also shows an overall safety profile as good as, or better than, any other frontier model in the industry, with low rates of misaligned behavior across safety evaluations. . ![Image 3: Bar chart comparing Opus 4.6 to other models on Deep…
The following are summaries of key safety evaluations from our Claude Sonnet 4.6 system card. The following are summaries of key safety evaluations from our Claude Opus 4.6 system card. Additional evaluations were conducted as part of our safety process; for our complete publicly reported evaluation results, please refer to the full system card. We tested Claude…
Nghiên cứu và kiểm chứng thông tin: Claude Opus 4.7 khác gì so với Opus 4.6 và Sonnet 4.6?
Claude Opus 4.7 là bản mạnh nhất đang được Anthropic phát hành rộng rãi, và khác Opus 4.6 chủ yếu ở chỗ nâng rõ chất lượng cho agentic coding, software engineering khó, nhiệm vụ dài hơi, độ bám chỉ dẫn và khả năng thị...
Claude Opus 4.7 là bản mạnh nhất đang được Anthropic phát hành rộng rãi, và khác Opus 4.6 chủ yếu ở chỗ nâng rõ chất lượng cho agentic coding, software engineering khó, nhiệm vụ dài hơi, độ bám chỉ dẫn và khả năng thị giác, trong khi vẫn giữ cùng mức giá Opus. [3][8] So với Sonnet 4.6, Opus 4.7 mạnh hơn cho tác vụ phức
Bài học chính
So với Opus 4.6, Opus 4.7 là bản nâng cấp về chất lượng hơn là đổi phân khúc: Anthropic nói 4.7 có “step-change” trong agentic coding so với 4.6, và là cải thiện đáng kể trong advanced software engineering, đặc biệt ở các bài toán khó nhất.
Anthropic mô tả Opus 4.7 làm các tác vụ dài hơi chặt chẽ và nhất quán hơn, chú ý chỉ dẫn chính xác hơn, và biết tự kiểm tra đầu ra trước khi báo lại; đây là điểm khác biệt vận hành quan trọng so với định vị của Opus 4.6.
Về thị giác, Anthropic nói Opus 4.7 có vision tốt hơn đáng kể và nhìn được ảnh ở độ phân giải cao hơn Opus 4.6.
Về giá và khả dụng, Opus 4.7 giữ nguyên giá của Opus 4.6 là $5 cho mỗi triệu input tokens và $25 cho mỗi triệu output tokens, và được phát hành rộng rãi trên Claude, API, Bedrock, Vertex AI và Microsoft Foundry.
Claude Opus 4.7 là bản mạnh nhất đang được Anthropic phát hành rộng rãi, và khác Opus 4.6 chủ yếu ở chỗ nâng rõ chất lượng cho agentic coding, software engineering khó, nhiệm vụ dài hơi, độ bám chỉ dẫn và khả năng thị giác, trong khi vẫn giữ cùng mức giá Opus. [3][8] So với Sonne
Key findings
Câu trả lời nghiên cứu
Claude Opus 4.7 là bản mạnh nhất đang được Anthropic phát hành rộng rãi, và khác Opus 4.6 chủ yếu ở chỗ nâng rõ chất lượng cho agentic coding, software engineering khó, nhiệm vụ dài hơi, độ bám chỉ dẫn và khả năng thị giác, trong khi vẫn giữ cùng mức giá Opus. [3][8] So với Sonnet 4.6, Opus 4.7 mạnh hơn cho tác vụ phức tạp nhưng đắt hơn và chậm hơn; cả hai cùng có context window 1M tokens, nhưng Opus 4.7 có max output 128k còn Sonnet 4.6 là 64k. [3]
Key findings
So với Opus 4.6, Opus 4.7 là bản nâng cấp về chất lượng hơn là đổi phân khúc: Anthropic nói 4.7 có “step-change” trong agentic coding so với 4.6, và là cải thiện đáng kể trong advanced software engineering, đặc biệt ở các bài toán khó nhất. [3][8]
Anthropic mô tả Opus 4.7 làm các tác vụ dài hơi chặt chẽ và nhất quán hơn, chú ý chỉ dẫn chính xác hơn, và biết tự kiểm tra đầu ra trước khi báo lại; đây là điểm khác biệt vận hành quan trọng so với định vị của Opus 4.6. [8]
Về thị giác, Anthropic nói Opus 4.7 có vision tốt hơn đáng kể và nhìn được ảnh ở độ phân giải cao hơn Opus 4.6. [8]
Về giá và khả dụng, Opus 4.7 giữ nguyên giá của Opus 4.6 là $5 cho mỗi triệu input tokens và $25 cho mỗi triệu output tokens, và được phát hành rộng rãi trên Claude, API, Bedrock, Vertex AI và Microsoft Foundry. [7][8]
Opus 4.6 trước đó đã mang vào dòng Opus các cải tiến lớn về coding, lập kế hoạch cẩn thận hơn, làm agentic tasks lâu hơn, xử lý codebase lớn tin cậy hơn, code review/debugging tốt hơn, và 1M token context window ở trạng thái beta. [7]
So với Sonnet 4.6, khác biệt lớn nhất của Opus 4.7 là định vị: docs của Anthropic xếp Opus 4.7 là “most capable generally available model” cho complex reasoning và agentic coding, còn Sonnet 4.6 là “best combination of speed and intelligence”. [3]
Về thông số hiện tại, Opus 4.7 và Sonnet 4.6 đều có context window 1M tokens, nhưng Opus 4.7 có max output 128k còn Sonnet 4.6 là 64k; Opus 4.7 có latency “moderate” còn Sonnet 4.6 là “fast”; giá của Opus 4.7 là $5/$25 còn Sonnet 4.6 là $3/$15 cho mỗi triệu input/output tokens. [3]
Docs hiện tại cũng liệt kê Opus 4.7 có adaptive thinking nhưng không có extended thinking, trong khi Sonnet 4.6 có cả adaptive thinking lẫn extended thinking. [3]
Sonnet 4.6 bản thân cũng là một nâng cấp lớn: Anthropic mô tả đây là nâng cấp toàn diện ở coding, computer use, long-context reasoning, agent planning, knowledge work và design, đồng thời là model mặc định trên claude.ai và Claude Cowork cho người dùng Free/Pro. [9]
Suy luận thực dụng từ cách Anthropic định vị sản phẩm: nếu bạn ưu tiên chất lượng tối đa cho coding/agent workflows khó và dài, Opus 4.7 hợp hơn; nếu bạn ưu tiên cost/performance và độ nhanh cho production diện rộng, Sonnet 4.6 hợp hơn. [3][8][9]
Evidence notes
Mình ưu tiên nguồn chính thức của Anthropic, nên các khác biệt về giá, khả dụng, context window, max output và positioning có độ tin cậy cao. [3][7][8][9]
Tuy vậy, phần “mạnh hơn bao nhiêu” về hiệu năng chủ yếu vẫn là tuyên bố và benchmark do Anthropic công bố trên tài liệu chính thức của họ, chưa phải kiểm chứng độc lập trong câu trả lời này. [7][8][9]
Nếu bạn cần bảng benchmark định lượng đầy đủ giữa cả ba model trên từng bài test, hiện là Insufficient evidence trong bộ nguồn mình đã truy xuất trực tiếp ở đây. [8][9]
Ngoài ra, mình chưa kiểm tra thêm benchmark bên thứ ba để đối chiếu độc lập với các tuyên bố của Anthropic. [7][8][9]
Summary
Tóm lại, Opus 4.7 là bản kế nhiệm mạnh hơn Opus 4.6 chủ yếu ở agentic coding, software engineering khó, tác vụ dài hơi, độ nhất quán và vision, nhưng không đổi giá Opus. [7][8] So với Sonnet 4.6, Opus 4.7 mạnh hơn và có output lớn hơn, còn Sonnet 4.6 nhanh hơn, rẻ hơn và được định vị là lựa chọn speed/intelligence tốt hơn cho nhiều workload production. [3][9]
Nếu bạn muốn, mình có thể làm tiếp một bảng 3 cột rất ngắn: “Opus 4.7 vs Opus 4.6 vs Sonnet 4.6” để bạn dùng ngay cho quyết định chọn model.
Hỗ trợ hình ảnh
Claude Help Center76f3062d78ebbb04863fb1de3ef9cca0Introducing Claude Opus 4.7 \ AnthropicA graphic illustration featuring a stylized silhouette of a human head with neural network connections on the left and a playful abstract drawing of a face with question marks on the right, referencing the Anthropic Claude Opus 4.7 announcement.Introducing Claude Opus 4.7 \ AnthropicA comparative table displaying performance metrics of different AI models, highlighting the advancements of Anthropic's Claude Opus 4.7 over previous versions and competitors, with specific emphasis on its high score of 93.9% in Agentic coding.Introducing Claude Opus 4.7 \ AnthropicA bar chart compares the scores of different models and tests, showing that "Opus 4.7" has the highest average score among the groups, with error bars indicating some variation in the results.Introducing Claude Opus 4.7 \ AnthropicA line chart compares the performance of Claude Opus 4.7 and 4.6 in internal autonomous agentic coding evaluation, showing scores increasing with effort level.Introducing Claude Opus 4.7 \ AnthropicA bar chart comparing the correctness percentages of different AI models, with Anthropic Claude Opus 4.7 showing the highest score at 80.6%.ogThe Ultimate Guide to Claude Opus 4.7 - by Paweł HurynClaude Opus 4.7 is rated higher than Claude Opus 4.6 across various text categories, especially excelling in occupational and overall text ratings.Why is Claude Opus 4.7 less durable than 4.6The image displays a capability map for Claude Opus 4.7, contrasting real upgrade scenarios for various tasks with degradation in specific scenarios, highlighting the strengths of multi-file agent coding, IDE tasks, tool use, visual recognition, and computer use on the left, and challenging scenarios like long document1 million context window is now generally available forA line graph compares mean match ratios of different language models, showing that Opus 4.6 and Sonnet 4.6 maintain higher accuracy across increasing input tokens compared to GPT-5.4, Gemini 3.1 Pro, and Sonnet 4.5.Claude Opus 4.6 Pricing Guide 2026: API Costs, Plans, andA pricing comparison chart displaying different plans for Anthropic's Claude models, including details for API pricing, subscription, and team/enterprise options, with highlights on costs, features, and savings.Claude Sonnet 4.6: Specs, Benchmarks & Pricing 2026The image displays a comparison table of AI models, highlighting features, performance percentages, and release dates, with a focus on Claude Sonnet 4.6 released in February 2026.
Trao đổi nghiên cứu
Bạn
Câu hỏi nghiên cứu
Tìm kiếm và kiểm chứng thông tin: Claude Opus 4.7 khác gì so với Opus 4.6 và Sonnet 4.6?
Studio Global AI12 nguồn
Câu trả lời được trích dẫn
Mình chưa thể kiểm chứng chắc chắn “Claude Opus 4.7” khác gì so với Opus 4.6 và Sonnet 4.6, vì trong tập kết quả hiện có mình không thấy tài liệu chính thức từ Anthropic xác nhận hoặc mô tả rõ Opus 4.7; phần này hiện là Insufficient evidence. [1][4][5][6]
Những gì có thể tóm tắt khá chắc từ các nguồn bên thứ ba hiện có là: Opus 4.6 mạnh hơn, Sonnet 4.6 rẻ hơn và cân bằng hơn cho production; còn Opus 4.7 thì bằng chứng hiện tại chưa đủ để kết luận. [4][5][8]
Về Opus 4.7: trong các kết quả mình thu được, chỉ có một nguồn bên thứ ba nhắc trực tiếp tới “Claude Opus 4.7 vs 4.6”, nhưng không có release note hay doc chính thức của Anthropic đi kèm trong tập nguồn này, nên chưa nên coi đó là thông tin đã được xác minh. [6]
Về Opus 4.6 vs Sonnet 4.6: nhiều trang so sánh bên thứ ba liệt kê cả hai model với context window 1.0M tokens và max output 128K tokens, tức khác biệt chính không nằm ở kích thước ngữ cảnh. [9][10]
Opus 4.6 được các nguồn so sánh định vị là model mạnh hơn về coding và benchmark tổng thể. [4][5]
Sonnet 4.6 được mô tả là lựa chọn cân bằng hơn về tốc độ/chi phí, và một nguồn so sánh ghi nhận Sonnet 4.6 rẻ hơn khoảng 1.7x mỗi token so với Opus 4.6. [5][8]
Nói thực dụng: nếu bạn ưu tiên chất lượng tối đa, các nguồn hiện có nghiêng về Opus 4.6; nếu bạn ưu tiên cost/performance cho triển khai rộng, các nguồn hiện có nghiêng về Sonnet 4.6. [4][5][8]
Độ tin cậy cần lưu ý: các nguồn mình có ở đây chủ yếu là aggregator/comparison site như OpenRouter, llm-stats, AIViewer, Krater và Simtheory, chứ không phải tài liệu gốc của Anthropic. [1][4][5][9][10]
Nếu bạn muốn, mình có thể làm tiếp 1 trong 2 hướng:
viết cho bạn một bảng so sánh ngắn “đã kiểm chứng được / chưa kiểm chứng được”, hoặc
kiểm tra trực tiếp nếu bạn gửi link docs/release note Anthropic mà bạn đang tham chiếu.
Bạn
Câu hỏi nghiên cứu
Nghiên cứu và kiểm chứng thông tin: Claude Opus 4.7 khác gì so với Opus 4.6 và Sonnet 4.6?
Studio Global AI13 nguồn
Câu trả lời được trích dẫn
Claude Opus 4.7 là bản mạnh nhất đang được Anthropic phát hành rộng rãi, và khác Opus 4.6 chủ yếu ở chỗ nâng rõ chất lượng cho agentic coding, software engineering khó, nhiệm vụ dài hơi, độ bám chỉ dẫn và khả năng thị giác, trong khi vẫn giữ cùng mức giá Opus. [3][8] So với Sonnet 4.6, Opus 4.7 mạnh hơn cho tác vụ phức tạp nhưng đắt hơn và chậm hơn; cả hai cùng có context window 1M tokens, nhưng Opus 4.7 có max output 128k còn Sonnet 4.6 là 64k. [3]
Key findings
So với Opus 4.6, Opus 4.7 là bản nâng cấp về chất lượng hơn là đổi phân khúc: Anthropic nói 4.7 có “step-change” trong agentic coding so với 4.6, và là cải thiện đáng kể trong advanced software engineering, đặc biệt ở các bài toán khó nhất. [3][8]
Anthropic mô tả Opus 4.7 làm các tác vụ dài hơi chặt chẽ và nhất quán hơn, chú ý chỉ dẫn chính xác hơn, và biết tự kiểm tra đầu ra trước khi báo lại; đây là điểm khác biệt vận hành quan trọng so với định vị của Opus 4.6. [8]
Về thị giác, Anthropic nói Opus 4.7 có vision tốt hơn đáng kể và nhìn được ảnh ở độ phân giải cao hơn Opus 4.6. [8]
Về giá và khả dụng, Opus 4.7 giữ nguyên giá của Opus 4.6 là $5 cho mỗi triệu input tokens và $25 cho mỗi triệu output tokens, và được phát hành rộng rãi trên Claude, API, Bedrock, Vertex AI và Microsoft Foundry. [7][8]
Opus 4.6 trước đó đã mang vào dòng Opus các cải tiến lớn về coding, lập kế hoạch cẩn thận hơn, làm agentic tasks lâu hơn, xử lý codebase lớn tin cậy hơn, code review/debugging tốt hơn, và 1M token context window ở trạng thái beta. [7]
So với Sonnet 4.6, khác biệt lớn nhất của Opus 4.7 là định vị: docs của Anthropic xếp Opus 4.7 là “most capable generally available model” cho complex reasoning và agentic coding, còn Sonnet 4.6 là “best combination of speed and intelligence”. [3]
Về thông số hiện tại, Opus 4.7 và Sonnet 4.6 đều có context window 1M tokens, nhưng Opus 4.7 có max output 128k còn Sonnet 4.6 là 64k; Opus 4.7 có latency “moderate” còn Sonnet 4.6 là “fast”; giá của Opus 4.7 là $5/$25 còn Sonnet 4.6 là $3/$15 cho mỗi triệu input/output tokens. [3]
Docs hiện tại cũng liệt kê Opus 4.7 có adaptive thinking nhưng không có extended thinking, trong khi Sonnet 4.6 có cả adaptive thinking lẫn extended thinking. [3]
Sonnet 4.6 bản thân cũng là một nâng cấp lớn: Anthropic mô tả đây là nâng cấp toàn diện ở coding, computer use, long-context reasoning, agent planning, knowledge work và design, đồng thời là model mặc định trên claude.ai và Claude Cowork cho người dùng Free/Pro. [9]
Suy luận thực dụng từ cách Anthropic định vị sản phẩm: nếu bạn ưu tiên chất lượng tối đa cho coding/agent workflows khó và dài, Opus 4.7 hợp hơn; nếu bạn ưu tiên cost/performance và độ nhanh cho production diện rộng, Sonnet 4.6 hợp hơn. [3][8][9]
Evidence notes
Mình ưu tiên nguồn chính thức của Anthropic, nên các khác biệt về giá, khả dụng, context window, max output và positioning có độ tin cậy cao. [3][7][8][9]
Tuy vậy, phần “mạnh hơn bao nhiêu” về hiệu năng chủ yếu vẫn là tuyên bố và benchmark do Anthropic công bố trên tài liệu chính thức của họ, chưa phải kiểm chứng độc lập trong câu trả lời này. [7][8][9]
Nếu bạn cần bảng benchmark định lượng đầy đủ giữa cả ba model trên từng bài test, hiện là Insufficient evidence trong bộ nguồn mình đã truy xuất trực tiếp ở đây. [8][9]
Ngoài ra, mình chưa kiểm tra thêm benchmark bên thứ ba để đối chiếu độc lập với các tuyên bố của Anthropic. [7][8][9]
Summary
Tóm lại, Opus 4.7 là bản kế nhiệm mạnh hơn Opus 4.6 chủ yếu ở agentic coding, software engineering khó, tác vụ dài hơi, độ nhất quán và vision, nhưng không đổi giá Opus. [7][8] So với Sonnet 4.6, Opus 4.7 mạnh hơn và có output lớn hơn, còn Sonnet 4.6 nhanh hơn, rẻ hơn và được định vị là lựa chọn speed/intelligence tốt hơn cho nhiều workload production. [3][9]
Nếu bạn muốn, mình có thể làm tiếp một bảng 3 cột rất ngắn: “Opus 4.7 vs Opus 4.6 vs Sonnet 4.6” để bạn dùng ngay cho quyết định chọn model.
Người ta cũng hỏi
Câu trả lời ngắn gọn cho "Nghiên cứu và kiểm chứng thông tin: Claude Opus 4.7 khác gì so với Opus 4.6 và Sonnet 4.6?" là gì?
So với Opus 4.6, Opus 4.7 là bản nâng cấp về chất lượng hơn là đổi phân khúc: Anthropic nói 4.7 có “step-change” trong agentic coding so với 4.6, và là cải thiện đáng kể trong advanced software engineering, đặc biệt ở các bài toán khó nhất.
Những điểm chính cần xác nhận đầu tiên là gì?
So với Opus 4.6, Opus 4.7 là bản nâng cấp về chất lượng hơn là đổi phân khúc: Anthropic nói 4.7 có “step-change” trong agentic coding so với 4.6, và là cải thiện đáng kể trong advanced software engineering, đặc biệt ở các bài toán khó nhất. Anthropic mô tả Opus 4.7 làm các tác vụ dài hơi chặt chẽ và nhất quán hơn, chú ý chỉ dẫn chính xác hơn, và biết tự kiểm tra đầu ra trước khi báo lại; đây là điểm khác biệt vận hành quan trọng so với định vị của Opus 4.6.
Tôi nên làm gì tiếp theo trong thực tế?
Về thị giác, Anthropic nói Opus 4.7 có vision tốt hơn đáng kể và nhìn được ảnh ở độ phân giải cao hơn Opus 4.6.
Tôi nên khám phá chủ đề liên quan nào tiếp theo?
Tiếp tục với "Tìm kiếm và kiểm chứng thông tin: Tạo ảnh bằng Gemini như thế nào?" để có góc nhìn khác và trích dẫn bổ sung.
Usage analytics for Claude Cowork. For more information, see View usage analytics for Team and Enterprise plans. Users on Pro and Max plans can give Claude access to computer use. Users on Pro and Max plans can access a persistent agent thread via Claude Desktop or Claude for iOS/Android to manage tasks in Cowork. Claude Code access added to Team plan Standard seats. Max plan users can now access Claude’s memory capabilities. Claude’s memory on Enterprise plans. Premium seats with Claude Code for Team and Enterprise plans. Introduced a premium seat tier for Team and Enterp…
Start building with Claude. Everything you need to integrate Claude into your applications. From first API call to production. What do you want to build? import anthropic import anthropic client = anthropic.Anthropic() client = anthropic.Anthropic() message = client.messages.create(message = client.messages.create( model="claude-opus-4-7", model ="claude-opus-4-7", max_tokens=1024, max_tokens = 1024, messages=[{ messages =[{ "role": "user", "role": "user", "content": "Hello, Claude" "content": "Hello, Claude" }] }]))print(message.content[0].text) print(message.content[0].text). ## Choose ho…
Skip to main contentSkip to footer. . * Extended thinking with tool use (beta): Both models can use tools—like web search—during extended thinking, allowing Claude to alternate between reasoning and tool use to improve responses. Get started today on [Claude](https:…
As we show in our extensive system card, Opus 4.6 also shows an overall safety profile as good as, or better than, any other frontier model in the industry, with low rates of misaligned behavior across safety evaluations. . 





 .
.  . Read more. Read more. Read more. [Rea…
. Read more. Read more. Read more. [Rea… . * Extended thinking with tool use (beta): Both models can use tools—like web search—during extended thinking, allowing Claude to alternate between reasoning and tool use to improve responses. Get started today on [Claude](https:…
. * Extended thinking with tool use (beta): Both models can use tools—like web search—during extended thinking, allowing Claude to alternate between reasoning and tool use to improve responses. Get started today on [Claude](https:…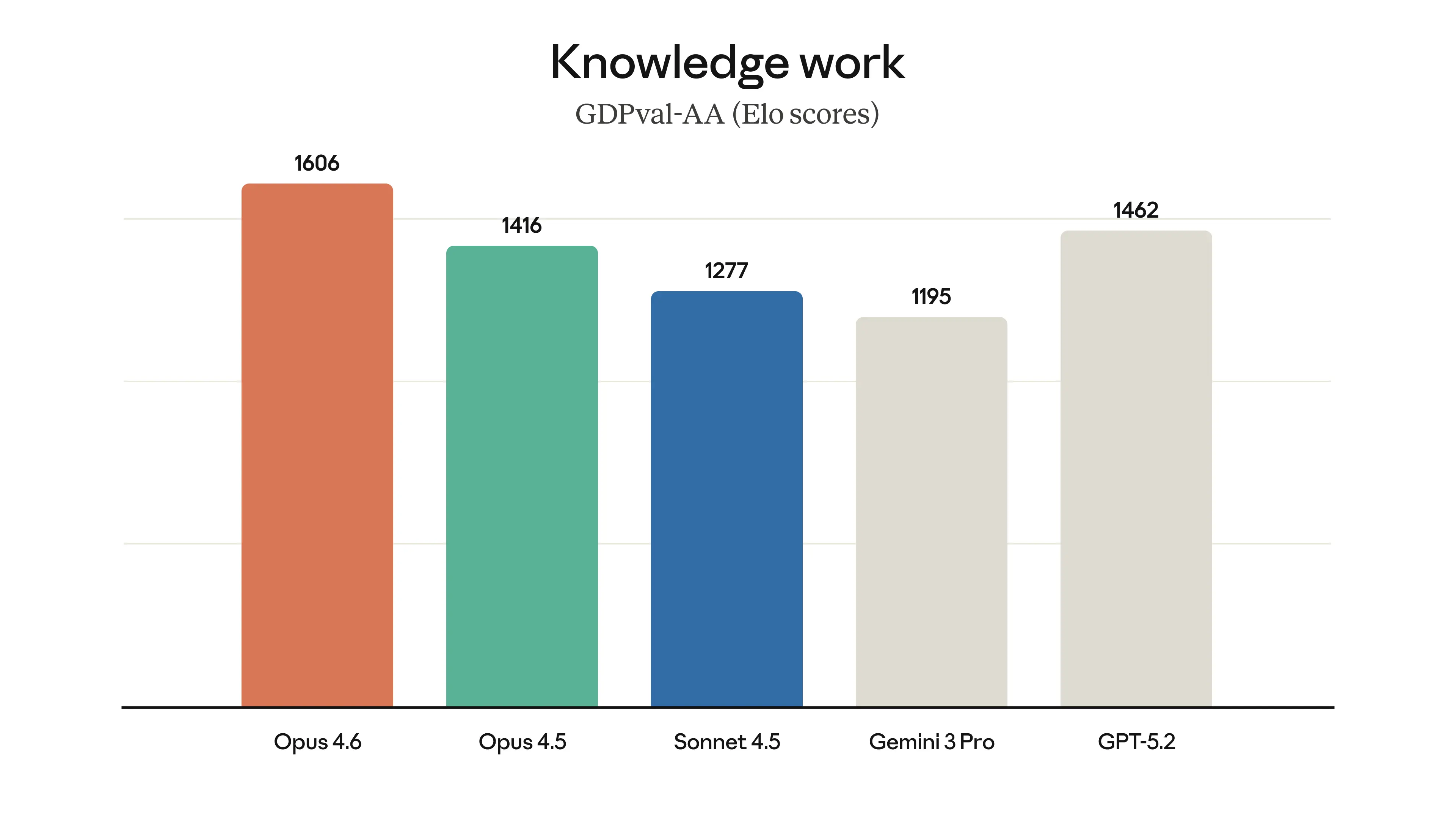 .  .
.  .  . For those on our Free and Pro plans, Claude Sonnet 4.6 is now the default model in claude.ai and Claude Cowork. As with every new Claude model, we’ve run extensive safety evaluations of Sonnet 4.6, which overall showed it to be as safe as, or safer than,…
. For those on our Free and Pro plans, Claude Sonnet 4.6 is now the default model in claude.ai and Claude Cowork. As with every new Claude model, we’ve run extensive safety evaluations of Sonnet 4.6, which overall showed it to be as safe as, or safer than,… .
.  .
.