Изучите показатели GPT-5.5, Claude Opus 4.7, Kimi K2.6 и DeepSeek V4 в бенчмарках. Пожалуйста, сделайте отчёт удобным для чтения.
Я нашёл сопоставимые данные не по всем четырём моделям в одном и том же независимом тестовом прогоне. Поэтому ниже — аккуратная сводка: GPT 5.5, Claude Opus 4.7 и DeepSeek V4 Pro Max сравниваются по одной опубликованн...
Я нашёл сопоставимые данные не по всем четырём моделям в одном и том же независимом тестовом прогоне. Поэтому ниже — аккуратная сводка: GPT 5.5, Claude Opus 4.7 и DeepSeek V4 Pro Max сравниваются по одной опубликованной таблице, а Kimi K2.6 добавлен по отдельной карточке модели; прямое сравнение с Kimi нужно считать ор
Ключевые выводы
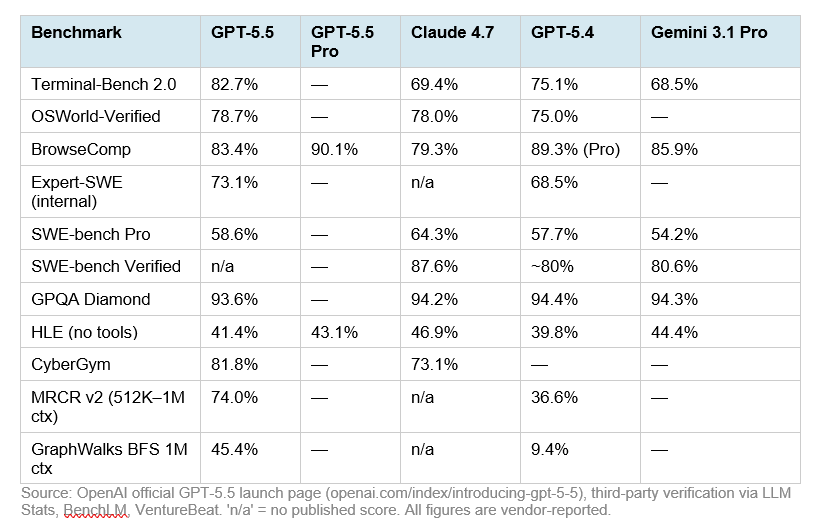
- Claude Opus 4.7 выглядит сильнейшим в GPQA Diamond: 94.2% против 93.6% у GPT-5.5 и 90.1% у DeepSeek-V4-Pro-Max.
- Claude Opus 4.7 также лидирует в Humanity’s Last Exam без инструментов: 46.9% против 41.4% у GPT-5.5, 43.1% у GPT-5.5 Pro и 37.7% у DeepSeek-V4-Pro-Max.
- GPT-5.5 Pro лидирует в Humanity’s Last Exam с инструментами: 57.2% против 54.7% у Claude Opus 4.7, 52.2% у GPT-5.5 и 48.2% у DeepSeek-V4-Pro-Max.
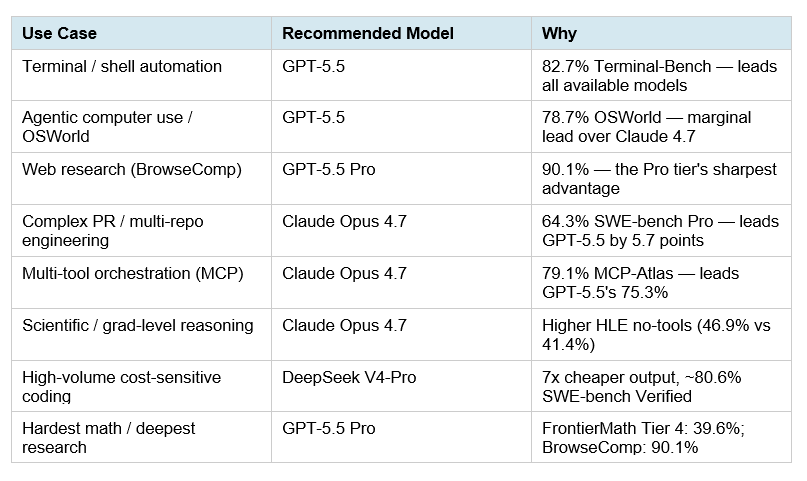
- GPT-5.5 заметно впереди в Terminal-Bench 2.0: 82.7% против 69.4% у Claude Opus 4.7, 67.9% у DeepSeek-V4-Pro-Max и 66.7% у Kimi K2.6.
- Я нашёл сопоставимые данные не по всем четырём моделям в одном и том же независимом тестовом прогоне. Поэтому ниже — аккуратная сводка: GPT-5.5, Claude Opus 4.7 и DeepSeek-V4-Pro-Max сравниваются по одной опубликованной таблице, а Kimi K2.6 добавлен по отдельной карточке модели;
- ## Key findings
Ответ на исследование
Я нашёл сопоставимые данные не по всем четырём моделям в одном и том же независимом тестовом прогоне. Поэтому ниже — аккуратная сводка: GPT-5.5, Claude Opus 4.7 и DeepSeek-V4-Pro-Max сравниваются по одной опубликованной таблице, а Kimi K2.6 добавлен по отдельной карточке модели; прямое сравнение с Kimi нужно считать ориентировочным, а не строго «один к одному» [9][
15].
Key findings
-
Claude Opus 4.7 выглядит сильнейшим в GPQA Diamond: 94.2% против 93.6% у GPT-5.5 и 90.1% у DeepSeek-V4-Pro-Max [
9].
-
Claude Opus 4.7 также лидирует в Humanity’s Last Exam без инструментов: 46.9% против 41.4% у GPT-5.5, 43.1% у GPT-5.5 Pro и 37.7% у DeepSeek-V4-Pro-Max [
9].
-
GPT-5.5 Pro лидирует в Humanity’s Last Exam с инструментами: 57.2% против 54.7% у Claude Opus 4.7, 52.2% у GPT-5.5 и 48.2% у DeepSeek-V4-Pro-Max [
9].
-
GPT-5.5 заметно впереди в Terminal-Bench 2.0: 82.7% против 69.4% у Claude Opus 4.7, 67.9% у DeepSeek-V4-Pro-Max и 66.7% у Kimi K2.6 [
9][
15].
-
Kimi K2.6 выглядит очень сильной открытой/доступной по весам моделью для coding-бенчмарков: карточка модели указывает 80.2 на SWE-Bench Verified, 58.6 на SWE-Bench Pro, 76.7 на SWE-Bench Multilingual и 66.7 на Terminal-Bench 2.0 [
15].
-
DeepSeek-V4-Pro-Max в найденной таблице стабильно ниже GPT-5.5 и Claude Opus 4.7 по GPQA, HLE и Terminal-Bench 2.0, но остаётся близко к Claude в Terminal-Bench 2.0: 67.9% против 69.4% [
9].
Сводная таблица
| Бенчмарк | GPT-5.5 | GPT-5.5 Pro | Claude Opus 4.7 | DeepSeek-V4-Pro-Max | Kimi K2.6 | Кто впереди |
|---|---|---|---|---|---|---|
| GPQA Diamond | 93.6% [ | н/д | 94.2% [ | 90.1% [ | н/д | Claude Opus 4.7 |
| Humanity’s Last Exam, без инструментов | 41.4% [ | 43.1% [ | 46.9% [ | 37.7% [ | н/д | Claude Opus 4.7 |
| Humanity’s Last Exam, с инструментами | 52.2% [ | 57.2% [ | 54.7% [ | 48.2% [ | н/д | GPT-5.5 Pro |
| Terminal-Bench 2.0 | 82.7% [ | н/д | 69.4% [ | 67.9% [ | 66.7 [ | GPT-5.5 |
| SWE-Bench Verified | н/д | н/д | н/д | н/д | 80.2 [ | недостаточно данных |
| SWE-Bench Pro | н/д | н/д | н/д | н/д | 58.6 [ | недостаточно данных |
| SWE-Bench Multilingual | н/д | н/д | н/д | н/д | 76.7 [ | недостаточно данных |
По моделям
GPT-5.5
-
GPT-5.5 показывает лучший найденный результат в Terminal-Bench 2.0 среди сопоставленных моделей: 82.7% [
9].
-
GPT-5.5 уступает Claude Opus 4.7 в GPQA Diamond: 93.6% против 94.2% [
9].
-
GPT-5.5 уступает Claude Opus 4.7 в Humanity’s Last Exam без инструментов: 41.4% против 46.9% [
9].
-
GPT-5.5 Pro, отдельный более сильный режим/вариант в найденной таблице, выходит на первое место в HLE с инструментами: 57.2% [
9].
Claude Opus 4.7
-
Claude Opus 4.7 — лидер по GPQA Diamond среди моделей в найденной таблице: 94.2% [
9].
-
Claude Opus 4.7 — лидер по HLE без инструментов: 46.9% [
9].
-
Claude Opus 4.7 занимает второе место в HLE с инструментами после GPT-5.5 Pro: 54.7% против 57.2% [
9].
-
В Terminal-Bench 2.0 Claude Opus 4.7 значительно уступает GPT-5.5: 69.4% против 82.7% [
9].
Kimi K2.6
-
Kimi K2.6 имеет сильный профиль в coding-задачах: 80.2 на SWE-Bench Verified, 58.6 на SWE-Bench Pro и 76.7 на SWE-Bench Multilingual [
15].
-
Kimi K2.6 набирает 66.7 в Terminal-Bench 2.0, что близко к DeepSeek-V4-Pro-Max 67.9 и Claude Opus 4.7 69.4, но заметно ниже GPT-5.5 82.7 [
9][
15].
-
Kimi K2.6 в найденных источниках описывается как новая сильная open-weights модель, а её карточка модели приводит отдельную таблицу результатов по coding и agentic-бенчмаркам [
14][
15].
DeepSeek V4
-
В найденной сопоставимой таблице указана именно версия DeepSeek-V4-Pro-Max, поэтому выводы по DeepSeek V4 лучше читать как выводы по этой конкретной версии, а не обязательно по всей линейке V4 [
9].
-
DeepSeek-V4-Pro-Max показывает 90.1% на GPQA Diamond, что ниже GPT-5.5 93.6% и Claude Opus 4.7 94.2% [
9].
-
DeepSeek-V4-Pro-Max показывает 37.7% на HLE без инструментов и 48.2% на HLE с инструментами, что ниже GPT-5.5, GPT-5.5 Pro и Claude Opus 4.7 в той же таблице [
9].
-
В Terminal-Bench 2.0 DeepSeek-V4-Pro-Max набирает 67.9%, что почти на уровне Claude Opus 4.7 69.4%, но существенно ниже GPT-5.5 82.7% [
9].
Evidence notes
-
Самая полезная найденная таблица сравнивает DeepSeek-V4-Pro-Max, GPT-5.5, GPT-5.5 Pro и Claude Opus 4.7 по GPQA Diamond, HLE и Terminal-Bench 2.0 [
9].
-
Для Kimi K2.6 наиболее конкретные найденные цифры идут из карточки модели: Terminal-Bench 2.0 — 66.7, SWE-Bench Pro — 58.6, SWE-Bench Multilingual — 76.7, SWE-Bench Verified — 80.2 и OSWorld-Verified — 73.1 [
15].
-
Источник по GPT-5.5 и Claude Opus 4.7 также указывает даты релиза: GPT-5.5 — 23 апреля 2026 года, Claude Opus 4.7 — 16 апреля 2026 года [
10].
Limitations / uncertainty
-
Insufficient evidence для полностью строгого сравнения всех четырёх моделей в одном независимом прогоне с одинаковыми настройками, потому что Kimi K2.6 не присутствует в основной найденной таблице вместе с GPT-5.5, Claude Opus 4.7 и DeepSeek-V4-Pro-Max [
9][
15].
-
Insufficient evidence для уверенного сравнения всех четырёх моделей по SWE-Bench Verified, потому что найденные конкретные SWE-Bench-цифры относятся к Kimi K2.6, а сопоставимые значения для GPT-5.5, Claude Opus 4.7 и DeepSeek-V4-Pro-Max в доступных фрагментах не были полно представлены [
15].
-
Результаты по DeepSeek относятся к варианту DeepSeek-V4-Pro-Max, поэтому их не следует автоматически переносить на все версии DeepSeek V4 [
9].
Summary
Если смотреть только на найденные сопоставимые бенчмарки, Claude Opus 4.7 сильнее в GPQA и HLE без инструментов, GPT-5.5/GPT-5.5 Pro сильнее в Terminal-Bench 2.0 и HLE с инструментами, а DeepSeek-V4-Pro-Max держится близко к Claude в Terminal-Bench, но уступает в reasoning-тестах [9]. Kimi K2.6 выглядит особенно интересной для coding-сценариев благодаря 80.2 на SWE-Bench Verified и 58.6 на SWE-Bench Pro, но её нельзя строго ранжировать против всех трёх остальных моделей без единого общего тестового прогона [
15].
Поддерживающие визуалы














Исследовательский разговор
Вопрос исследования
Изучите показатели GPT-5.5, Claude Opus 4.7, Kimi K2.6 и DeepSeek V4 в бенчмарках. Пожалуйста, сделайте отчёт удобным для чтения.
Цитируемый ответ
Я нашёл сопоставимые данные не по всем четырём моделям в одном и том же независимом тестовом прогоне. Поэтому ниже — аккуратная сводка: GPT-5.5, Claude Opus 4.7 и DeepSeek-V4-Pro-Max сравниваются по одной опубликованной таблице, а Kimi K2.6 добавлен по отдельной карточке модели; прямое сравнение с Kimi нужно считать ориентировочным, а не строго «один к одному» [9][
15].
Key findings
-
Claude Opus 4.7 выглядит сильнейшим в GPQA Diamond: 94.2% против 93.6% у GPT-5.5 и 90.1% у DeepSeek-V4-Pro-Max [
9].
-
Claude Opus 4.7 также лидирует в Humanity’s Last Exam без инструментов: 46.9% против 41.4% у GPT-5.5, 43.1% у GPT-5.5 Pro и 37.7% у DeepSeek-V4-Pro-Max [
9].
-
GPT-5.5 Pro лидирует в Humanity’s Last Exam с инструментами: 57.2% против 54.7% у Claude Opus 4.7, 52.2% у GPT-5.5 и 48.2% у DeepSeek-V4-Pro-Max [
9].
-
GPT-5.5 заметно впереди в Terminal-Bench 2.0: 82.7% против 69.4% у Claude Opus 4.7, 67.9% у DeepSeek-V4-Pro-Max и 66.7% у Kimi K2.6 [
9][
15].
-
Kimi K2.6 выглядит очень сильной открытой/доступной по весам моделью для coding-бенчмарков: карточка модели указывает 80.2 на SWE-Bench Verified, 58.6 на SWE-Bench Pro, 76.7 на SWE-Bench Multilingual и 66.7 на Terminal-Bench 2.0 [
15].
-
DeepSeek-V4-Pro-Max в найденной таблице стабильно ниже GPT-5.5 и Claude Opus 4.7 по GPQA, HLE и Terminal-Bench 2.0, но остаётся близко к Claude в Terminal-Bench 2.0: 67.9% против 69.4% [
9].
Сводная таблица
| Бенчмарк | GPT-5.5 | GPT-5.5 Pro | Claude Opus 4.7 | DeepSeek-V4-Pro-Max | Kimi K2.6 | Кто впереди |
|---|---|---|---|---|---|---|
| GPQA Diamond | 93.6% [ | н/д | 94.2% [ | 90.1% [ | н/д | Claude Opus 4.7 |
| Humanity’s Last Exam, без инструментов | 41.4% [ | 43.1% [ | 46.9% [ | 37.7% [ | н/д | Claude Opus 4.7 |
| Humanity’s Last Exam, с инструментами | 52.2% [ | 57.2% [ | 54.7% [ | 48.2% [ | н/д | GPT-5.5 Pro |
| Terminal-Bench 2.0 | 82.7% [ | н/д | 69.4% [ | 67.9% [ | 66.7 [ | GPT-5.5 |
| SWE-Bench Verified | н/д | н/д | н/д | н/д | 80.2 [ | недостаточно данных |
| SWE-Bench Pro | н/д | н/д | н/д | н/д | 58.6 [ | недостаточно данных |
| SWE-Bench Multilingual | н/д | н/д | н/д | н/д | 76.7 [ | недостаточно данных |
По моделям
GPT-5.5
-
GPT-5.5 показывает лучший найденный результат в Terminal-Bench 2.0 среди сопоставленных моделей: 82.7% [
9].
-
GPT-5.5 уступает Claude Opus 4.7 в GPQA Diamond: 93.6% против 94.2% [
9].
-
GPT-5.5 уступает Claude Opus 4.7 в Humanity’s Last Exam без инструментов: 41.4% против 46.9% [
9].
-
GPT-5.5 Pro, отдельный более сильный режим/вариант в найденной таблице, выходит на первое место в HLE с инструментами: 57.2% [
9].
Claude Opus 4.7
-
Claude Opus 4.7 — лидер по GPQA Diamond среди моделей в найденной таблице: 94.2% [
9].
-
Claude Opus 4.7 — лидер по HLE без инструментов: 46.9% [
9].
-
Claude Opus 4.7 занимает второе место в HLE с инструментами после GPT-5.5 Pro: 54.7% против 57.2% [
9].
-
В Terminal-Bench 2.0 Claude Opus 4.7 значительно уступает GPT-5.5: 69.4% против 82.7% [
9].
Kimi K2.6
-
Kimi K2.6 имеет сильный профиль в coding-задачах: 80.2 на SWE-Bench Verified, 58.6 на SWE-Bench Pro и 76.7 на SWE-Bench Multilingual [
15].
-
Kimi K2.6 набирает 66.7 в Terminal-Bench 2.0, что близко к DeepSeek-V4-Pro-Max 67.9 и Claude Opus 4.7 69.4, но заметно ниже GPT-5.5 82.7 [
9][
15].
-
Kimi K2.6 в найденных источниках описывается как новая сильная open-weights модель, а её карточка модели приводит отдельную таблицу результатов по coding и agentic-бенчмаркам [
14][
15].
DeepSeek V4
-
В найденной сопоставимой таблице указана именно версия DeepSeek-V4-Pro-Max, поэтому выводы по DeepSeek V4 лучше читать как выводы по этой конкретной версии, а не обязательно по всей линейке V4 [
9].
-
DeepSeek-V4-Pro-Max показывает 90.1% на GPQA Diamond, что ниже GPT-5.5 93.6% и Claude Opus 4.7 94.2% [
9].
-
DeepSeek-V4-Pro-Max показывает 37.7% на HLE без инструментов и 48.2% на HLE с инструментами, что ниже GPT-5.5, GPT-5.5 Pro и Claude Opus 4.7 в той же таблице [
9].
-
В Terminal-Bench 2.0 DeepSeek-V4-Pro-Max набирает 67.9%, что почти на уровне Claude Opus 4.7 69.4%, но существенно ниже GPT-5.5 82.7% [
9].
Evidence notes
-
Самая полезная найденная таблица сравнивает DeepSeek-V4-Pro-Max, GPT-5.5, GPT-5.5 Pro и Claude Opus 4.7 по GPQA Diamond, HLE и Terminal-Bench 2.0 [
9].
-
Для Kimi K2.6 наиболее конкретные найденные цифры идут из карточки модели: Terminal-Bench 2.0 — 66.7, SWE-Bench Pro — 58.6, SWE-Bench Multilingual — 76.7, SWE-Bench Verified — 80.2 и OSWorld-Verified — 73.1 [
15].
-
Источник по GPT-5.5 и Claude Opus 4.7 также указывает даты релиза: GPT-5.5 — 23 апреля 2026 года, Claude Opus 4.7 — 16 апреля 2026 года [
10].
Limitations / uncertainty
-
Insufficient evidence для полностью строгого сравнения всех четырёх моделей в одном независимом прогоне с одинаковыми настройками, потому что Kimi K2.6 не присутствует в основной найденной таблице вместе с GPT-5.5, Claude Opus 4.7 и DeepSeek-V4-Pro-Max [
9][
15].
-
Insufficient evidence для уверенного сравнения всех четырёх моделей по SWE-Bench Verified, потому что найденные конкретные SWE-Bench-цифры относятся к Kimi K2.6, а сопоставимые значения для GPT-5.5, Claude Opus 4.7 и DeepSeek-V4-Pro-Max в доступных фрагментах не были полно представлены [
15].
-
Результаты по DeepSeek относятся к варианту DeepSeek-V4-Pro-Max, поэтому их не следует автоматически переносить на все версии DeepSeek V4 [
9].
Summary
Если смотреть только на найденные сопоставимые бенчмарки, Claude Opus 4.7 сильнее в GPQA и HLE без инструментов, GPT-5.5/GPT-5.5 Pro сильнее в Terminal-Bench 2.0 и HLE с инструментами, а DeepSeek-V4-Pro-Max держится близко к Claude в Terminal-Bench, но уступает в reasoning-тестах [9]. Kimi K2.6 выглядит особенно интересной для coding-сценариев благодаря 80.2 на SWE-Bench Verified и 58.6 на SWE-Bench Pro, но её нельзя строго ранжировать против всех трёх остальных моделей без единого общего тестового прогона [
15].
Люди также спрашивают
Каков краткий ответ на вопрос «Изучите показатели GPT-5.5, Claude Opus 4.7, Kimi K2.6 и DeepSeek V4 в бенчмарках. Пожалуйста, сделайте отчёт удобным для чтения.»?
Claude Opus 4.7 выглядит сильнейшим в GPQA Diamond: 94.2% против 93.6% у GPT-5.5 и 90.1% у DeepSeek-V4-Pro-Max.
Какие ключевые моменты необходимо проверить в первую очередь?
Claude Opus 4.7 выглядит сильнейшим в GPQA Diamond: 94.2% против 93.6% у GPT-5.5 и 90.1% у DeepSeek-V4-Pro-Max. Claude Opus 4.7 также лидирует в Humanity’s Last Exam без инструментов: 46.9% против 41.4% у GPT-5.5, 43.1% у GPT-5.5 Pro и 37.7% у DeepSeek-V4-Pro-Max.
Что мне делать дальше на практике?
GPT-5.5 Pro лидирует в Humanity’s Last Exam с инструментами: 57.2% против 54.7% у Claude Opus 4.7, 52.2% у GPT-5.5 и 48.2% у DeepSeek-V4-Pro-Max.
Какую связанную тему мне следует изучить дальше?
Продолжайте с «ศึกษาค้นคว้าเกณฑ์มาตรฐานการทดสอบของ GPT-5.5, Claude Opus 4.7, DeepSeek V4 และ Kimi K2.6 แล้วเปรียบเทียบให้ครอบคลุมมากที่สุดเท่าที่เป็นไปได้», чтобы увидеть другой ракурс и дополнительные цитаты.
Открыть связанную страницуС чем мне это сравнить?
Сверьте этот ответ с «Recherchez les benchmarks de GPT-5.5, Claude Opus 4.7, DeepSeek V4 et Kimi K2.6, puis comparez-les de la manière la plus complète possible.».
Открыть связанную страницуПродолжайте свое исследование
Источники
- [1] DeepSeek V4 vs Claude Opus 4.5 for coding: benchmark comparisonapidog.com
DeepSeek V4 vs Claude Opus 4.5 for coding: benchmark comparison Claude Opus 4.5 leads SWE-bench at 80.9% and produces minimal, precise diffs. DeepSeek V4 handles multi-file, repository-scale refactoring well, particularly with large explicit context. INEZA...
- [2] DeepSeek V4 vs Claude Opus 4.6 vs GPT-5.4: Compararea modelelor AI pentru programare (2026) | NxCodenxcode.io
Diferență de cost de 50x: Prețul API pentru DeepSeek V4 ( $0.28/M input) este de aproximativ 50x mai ieftin dect Claude Opus 4.6 ($15/M input), ceea ce îl face cștigătorul clar pentru echipele sensibile la costuri. Claude Opus conduce în benchmark-urile ver...
- [3] DeepSeek V4 vs Claude Opus 4.6 vs GPT-5.4: השוואת מודלי AI לתכנות (2026) | NxCodenxcode.io
השוואת תמחור כאן ההשוואה הופכת לדרמטית. מודל התמחור של DeepSeek שונה מהותית מזה של ספקי המודלים הסגורים. קטגוריית עלות DeepSeek V4 Claude Opus 4.6 GPT-5.4 --- --- קלט (לכל 1M tokens) $0.28 $15.00 $10.00 פלט (לכל 1M tokens) $1.10 $75.00 $30.00 תוספת תשלום על...
- [4] DeepSeek V4 vs Claude Opus 4.6 vs GPT-5.4: השוואת מודלי AI לתכנות (2026) | NxCodenxcode.io
Perbedaan biaya 50x: DeepSeek V4 API pricing ( $0.28/M input) sekitar 50x lebih murah daripada Claude Opus 4.6 ($15/M input), menjadikannya pemenang yang jelas bagi tim yang sensitif terhadap biaya. Claude Opus memimpin pada verified benchmarks: 80.8% SWE-b...
- [5] DeepSeek V4 vs GPT-5.4 vs Claude Opus 4.6: Verified Comparisonevolink.ai
Context Note Claude Opus 4.7 launched on April 16, 2026 and is now generally available from Anthropic. This article intentionally keeps Claude Opus 4.6 in scope because the URL and query target are specifically about the 4.6 comparison set. Treat this page...
- [6] DeepSeek-V4 arrives with near state-of-the-art intelligence at 1/6th ...venturebeat.com
BenchmarkDeepSeek-V4-Pro-MaxGPT-5.5GPT-5.5 Pro, where shownClaude Opus 4.7Best result among these GPQA Diamond90.1%93.6%—94.2%Claude Opus 4.7 Humanity’s Last Exam, no tools37.7%41.4%43.1%46.9%Claude Opus 4.7 Humanity’s Last Exam, with tools48.2%52.2%57.2%54...
- [7] Kimi K2.6 vs Claude Opus 4.6 vs GPT-5.4 - Verdent AIverdent.ai
Yes. K2.6 weights are on Hugging Face and run on vLLM, SGLang, or KTransformers. Minimum viable hardware is 4× H100 for the INT4 variant at reduced context. Claude and GPT-5.4 are API-only — there is no self-hosted path. If data sovereignty is a requirement...
- [8] Kimi K2.6: The new leading open weights model - Artificial Analysisartificialanalysis.ai
➤ Multimodality: Kimi K2.6 supports Image and Video input and text output natively. The model’s max context length remains 256k. Kimi K2.6 has significantly higher token usage than Kimi K2.5. Kimi K2.5 scores 6 on the AA-Omniscience Index, primarily driven...
- [9] DeepSeek V4 vs Claude Opus 4.6 vs GPT-5.4 - NxCodenxcode.io
Developer guide for Claude Opus 4.7: API setup (claude-opus-4-7), new xhigh effort level, /ultrareview command, task budgets, and migration from 4.6. With code examples and cost optimization tips. 2026-04-16Read more → View All Articles → [...] DeepSeek V4...
- [10] DeepSeek-V4-Pro-Max: Pricing, Benchmarks & Performancellm-stats.com
7Image 54DeepSeek-V4-Pro-Max 0.83 8Image 55GPT-5.4 0.83 9Image 56Claude Opus 4.7 0.79 10Image 57GLM-5.1 0.79 Show 16 more Notice missing or incorrect data?Let us know→ Specifications Parameters 1.6T License MIT Training data 32.0T tokens Released Apr 2026 O...
- [11] AI Model Benchmarks Apr 2026 | Compare GPT-5, Claude 4.5 ...lmcouncil.ai
OTIS Mock AIME 2024-25 Model Score --- 1 Claude Opus 4.7 (xhigh) 97.8% ±2.2 2 GPT-5.2 (high) 96.1% ±2.6 3 GPT-5.2 (xhigh) 96.1% ±2.7 4 Gemini 3.1 Pro Preview 95.6% ±3.1 5 GPT-5.4 (xhigh) 95.3% ±3.2 MATH Level 5 Model Score --- 1 GPT-5 (high) 98.1% ±0.3 2 GP...
- [12] Deep|DeepSeek V4 vs Claude vs GPT-5.4: A 38-Task ... - FundaAIfundaai.substack.com
DeepSeek V4 is DeepSeek’s next-generation foundation model, shipped as two variants through the Pandora API: Pro (deeper, slower — optimized for thoroughness) and Flash (faster, more concise — optimized for production throughput). Both support multi-turn co...
- [13] [PDF] Technical Performance - Stanford HAIhai.stanford.edu
General Reasoning MMMU evaluates multimodal reasoning on college-level subject questions that combine text with visuals such as diagrams, charts, tables, and equations. Some example tasks include extracting constraints from a table and applying them to a wo...
- [14] DeepSeek V4 is here: How it compares to ChatGPT, Claude, Geminimashable.com
Here's how the API pricing compares: DeepSeek V4 costs $1.74 per 1 million input tokens and $3.48 per 1 million output tokens (1 million context window) GPT-5.5 costs at $5 per 1 million input tokens and $30 per 1 million output tokens (1 million context wi...
- [15] DeepSeek V4 Preview: The Complete 2026 Guide - o-mega | AIo-mega.ai
7. Head-to-Head: DeepSeek V4 vs Claude Opus 4.7 Claude Opus 4.7, released just eight days before DeepSeek V4 on April 16, represents Anthropic's most capable model and the current leader in agentic coding tasks. The comparison with V4-Pro reveals a more nua...
- [16] GPT-5.5 vs Claude Opus 4.7: Pricing, Speed, Benchmarks - LLM Statsllm-stats.com
Spec GPT-5.5 Claude Opus 4.7 --- Provider OpenAI Anthropic Release date Apr 23, 2026 Apr 16, 2026 Model ID gpt-5.5 claude-opus-4-7 Input / output (≤200K) $5 / $30 per 1M $5 / $25 per 1M Input / output ( 200K) $5 / $30 per 1M (flat) $10 / $37.50 per 1M Conte...
- [17] GPT-5.5: The Complete Guide (2026) - o-mega | AIo-mega.ai
Domain-Specific Benchmarks Benchmark GPT-5.5 Notes --- Harvey BigLaw Bench 91.7% (43% perfect scores) Legal reasoning, audience calibration Internal Investment Banking 88.5% Financial analysis tasks BixBench (bioinformatics) 80.5% (up from 74.0%) +6.5pts ov...
- [18] Claude Opus 4.7 Isn't a Drop-in Replacement for 4.6blog.dailydoseofds.com
It ended up running around 20% faster than LM Studio on the same hardware. Separately, it refactored an 8-year-old financial matching engine across 13 hours, delivering a 133% peak throughput gain. This is the capability gap that usually separates frontier...
- [19] DeepSeek V4: Features, Benchmarks, and Comparisonsdatacamp.com
DeepSeek V4 vs Competitors Over the last week, we’ve seen the release of OpenAI's GPT-5.5 and Anthropic's Claude Opus 4.7. While those models boast top-tier capabilities, especially in long-context reasoning and agentic coding, DeepSeek V4 competes heavily...
- [20] Gpt-5.5 vs claude opus 4.7 performance comparison - Facebookfacebook.com
Artificial Intelligence LLMs ● Generative AI (Images Video Audio) ● Robots Claude Opus 4.7 came out… Facebook Log In Log In Forgot Account? Image 1 Gpt-5.5 vs claude opus 4.7 performance comparison Summarized by AI from the post below ● Robots Noman Hassan...
- [21] Model Drop: GPT-5.5handyai.substack.com
The pitch the benchmark card is built to support: more intelligence at the same latency, 40% fewer output tokens per Codex task, state-of-the-art performance on most agentic coding and knowledge-work evals. Terminal-Bench 2.0 at 82.7% is a decisive lead on...
- [22] GPT 5.5 is out. Here are the benchmarks. - Facebookfacebook.com
1d 4 Image 3 View all 3 replies []( Robert Eaton Opus 4.7 has been terrible. Getting everything wrong, making same mistake over and over. I went back to 4.6 and everything was fine 1d 4 Image 4Image 5 View all 2 replies []( Patrick Healy Codex $100a month p...
- [23] MoonshotAI: Kimi K2 Thinking – Benchmarks - OpenRouteropenrouter.ai
Kimi K2 is optimized for agentic capabilities, including advanced tool use, reasoning, and code synthesis. It excels across coding (LiveCodeBench, SWE-bench), ...
- [24] Kimi K2.6 Tech Blog: Advancing Open-Source Codingkimi.com
On Kimi Code Bench, our internal coding benchmark covering diverse complicated end-to-end tasks, Kimi K2.6 demonstrates significant improvements over Kimi K2.5.
- [25] moonshotai/Kimi-K2.6 - Hugging Facehuggingface.co
OSWorld-Verified 73.1 75.0 72.7 63.3 Coding Terminal-Bench 2.0 (Terminus-2) 66.7 65.4 65.4 68.5 50.8 SWE-Bench Pro 58.6 57.7 53.4 54.2 50.7 SWE-Bench Multilingual 76.7 77.8 76.9 73.0 SWE-Bench Verified 80.2 80.8 80.6 76.8 SciCode 52.2 56.6 51.9 58.9 48.7 OJ...
- [26] Kimi K2.6 - Intelligence, Performance & Price Analysisartificialanalysis.ai
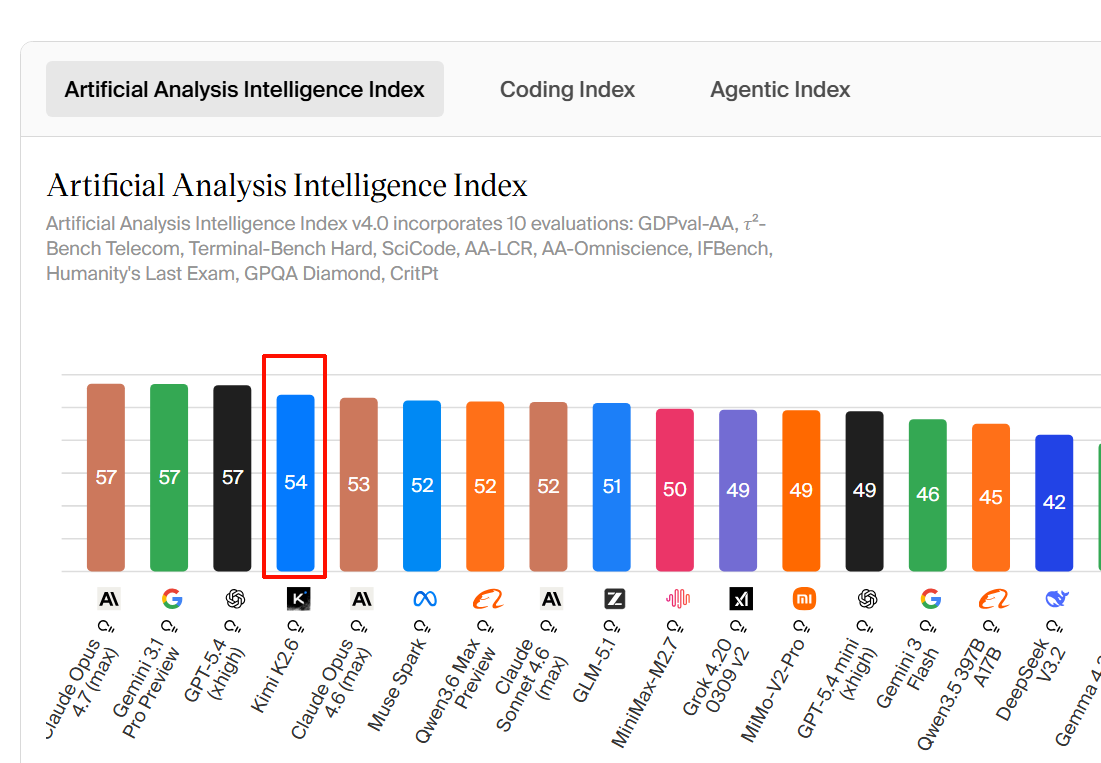
Kimi K2.6 scores 54 on the Artificial Analysis Intelligence Index, placing it well above average among comparable models (averaging 28). When ... 5 days ago
- [27] Kimi K2.6 on GMI Cloud: Architecture, Benchmarks & API Accessgmicloud.ai
Kimi K2.6: Architecture, Benchmarks, and What It Means for Production AI April 22, 2026 .png) Moonshot AI just open-sourced Kimi K2.6, and the results speak for themselves. It tops SWE-Bench Pro, runs 300 parallel sub-agents, and fits on 4x H100s in INT4. B...
- [28] Kimi K2.6 Has Arrived: An Open-Weight Powerhouse for Agentic Workblog.kilo.ai
Additionally, it achieved a strong 92.5% F1-score on DeepSearchQA and an excellent 66.7% on Terminal-Bench 2.0. We found Kimi K2.6 to be ... 6 days ago
- [29] SWE-bench Leaderboardsswebench.com
SWE-bench Logo Official Leaderboards ;. Kimi K2.5 (high reasoning). 70.80 ;. DeepSeek V3.2 (high reasoning). 70.00 ;. Gemini 3 Pro. 69.60 ;. Claude 4.5 ...
- [30] Better Kimi K2.6 benchmark score chart : r/ArtificialInteligence - Redditreddit.com
Artificial Analysis has released a more in-depth benchmark breakdown of Kimi K2 Thinking (2nd image) · r/LocalLLaMA - Artificial Analysis has ... 6 days ago
- [31] Meet Kimi K2.6: Advancing Open-Source Coding Open ... - Facebookfacebook.com
Benchmarks show strong results on SWE Bench, MMMU Pro, VideoMMMU, HLE, and BrowseComp..... Full analysis: com/2026 ... 6 days ago
- [32] moonshotai/Kimi-K2.6 · Add evaluation results for HLE, GPQA, AIME, HMMT, SWE-Bench, and Terminal-Benchhuggingface.co
moonshotai/Kimi-K2.6 · Add evaluation results for HLE, GPQA, AIME, HMMT, SWE-Bench, and Terminal-Bench Image 1: Hugging Face's logoHugging Face Models Datasets Spaces Buckets new Docs Enterprise Pricing Log In Sign Up Image 2 moonshotai / Kimi-K2.6 like 1.0...
- [33] Terminal-Bench 2.0 Leaderboardllm-stats.com
Model Score Size Context Cost License --- --- --- 1 Anthropic Claude Mythos Preview Anthropic 0.820 — — $25.00 / $125.00 2 OpenAI GPT-5.3 Codex OpenAI 0.773 — 400K $1.75 / $14.00 3 OpenAI GPT-5.4 OpenAI 0.751 — 1.0M $2.50 / $15.00 4 Anthropic Claude Opus 4....
- [34] Kimi K2 is the large language model series developed by Moonshot ...github.com
Key Features Total Parameters 1T Activated Parameters 32B Number of Layers (Dense layer included) 61 Number of Dense Layers 1 Attention Hidden Dimension 7168 MoE Hidden Dimension (per Expert) 2048 Number of Attention Heads 64 Number of Experts 384 Selected...
- [35] MoonshotAI: Kimi K2.6 Reviewdesignforonline.com
Performance Indices Source: Artificial Analysis This model was released recently. Independent benchmark evaluations are typically completed within days of release — these figures are preliminary and are likely to be updated as testing is finalised. Benchmar...
- [36] terminal-bench@2.0 Leaderboardtbench.ai
98 OpenHands Kimi K2 Instruct 2025-11-02 OpenHands Moonshot AI 26.7%± 2.7 99 Mini-SWE-Agent Gemini 2.5 Pro 2025-11-03 Princeton Google 26.1%± 2.5 100 Mini-SWE-Agent Grok Code Fast 1 2025-11-03 Princeton xAI 25.8%± 2.6 101 Mini-SWE-Agent Grok 4 2025-11-03 Pr...
- [37] .eval_results/swe_bench_verified.yaml · moonshotai/Kimi-K2.6 at mainhuggingface.co
Hugging Face's logo moonshotai / Kimi-K2.6 like 1.04k Follow Moonshot AI 9.2k bigeagle's picture --- - dataset: id: SWE-bench/SWE-bench\ Verified task\ id: swe\ bench\ %\ resolved value: 80.2 date: '2026-04-20' source: url: name: Model Card user: SaylorTwift
- [38] .eval_results/aime_2026.yaml · unsloth/Kimi-K2.6 at mainhuggingface.co
Hugging Face's logo unsloth / Kimi-K2.6 like 13 Follow Unsloth AI 20.2k danielhanchen's picture --- - dataset: id: MathArena/aime\ 2026 task\ id: MathArena/aime\ 2026 value: 96.4 date: '2026-04-20' source: url: name: Model Card user: SaylorTwift
- [39] Commits · moonshotai/Kimi-K2.6huggingface.co
Hugging Face's logo moonshotai / Kimi-K2.6 like 1.04k Follow Moonshot AI 9.2k Commit History Add evaluation results for HLE, GPQA, AIME, HMMT, SWE-Bench, and Terminal-Bench ( 4) d9cb81b
- [40] moonshotai/Kimi-K2.6 at mainhuggingface.co
Hugging Face's logo moonshotai / Kimi-K2.6 like 1.04k Follow Moonshot AI 9.2k bigeagle's picture
- [41] Kimi K2.6 raises the bar for open-source models. Moonshot ...x.com
- HLE with tools: 54.0 vs 53.0 (agentic reasoning) - DeepSearchQA: 92.5 vs 91.3 (deep research) - LiveCodeBench: 89.6 vs 88.8 Opus 4.6 still wins on SWE-bench Multilingual and BrowseComp, but the gap is under a point in both. 𝗧𝗵𝗲 𝗽𝗮𝗿𝘁 𝘁𝗵𝗮𝘁 𝗮𝗰𝘁...