Research benchmarks for GPT-5.5, Claude Opus 4.7, DeepSeek V4, and Kimi K2.6, and compare them as comprehensively as possible. Create a research report on this.
The available evidence supports a clear but incomplete picture: Claude Opus 4.7 leads the cited GPQA Diamond and Humanity’s Last Exam no tools results and is reported 1 in Vision & Document Arena [4][1]. GPT 5.5 leads...
The available evidence supports a clear but incomplete picture: Claude Opus 4.7 leads the cited GPQA Diamond and Humanity’s Last Exam no tools results and is reported 1 in Vision & Document Arena [4][1]. GPT 5.5 leads the cited Terminal Bench 2.0, OSWorld Verified, and FrontierMath results, while GPT 5.5 Pro leads Huma
Key takeaways
- Claude Opus 4.7 has the strongest cited results on GPQA Diamond at 94.2% versus GPT-5.5 at 93.6% and DeepSeek-V4-Pro-Max at 90.1%.
- Claude Opus 4.7 also leads the cited Humanity’s Last Exam no-tools result at 46.9%, ahead of GPT-5.5 Pro at 43.1%, GPT-5.5 at 41.4%, and DeepSeek-V4-Pro-Max at 37.7%.
- GPT-5.5 Pro leads the cited Humanity’s Last Exam with-tools result at 57.2%, ahead of Claude Opus 4.7 at 54.7%, GPT-5.5 at 52.2%, and DeepSeek-V4-Pro-Max at 48.2%.
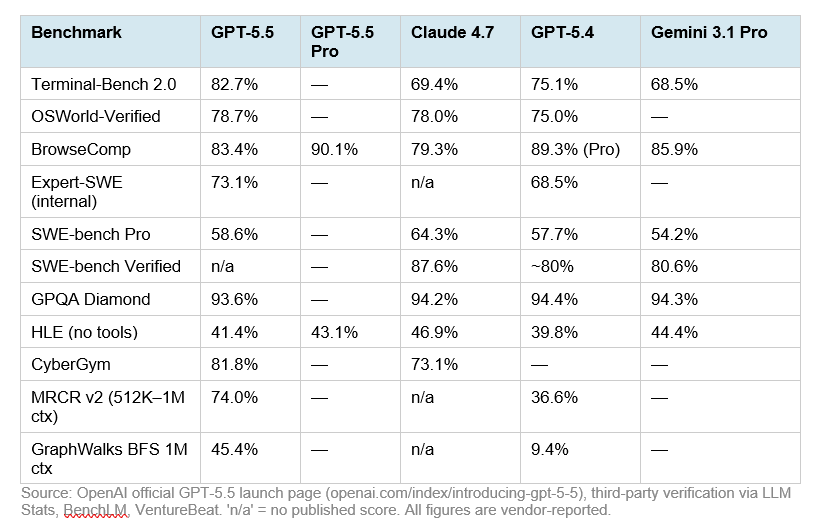
- GPT-5.5 is strongest in the cited terminal/agentic-computing benchmarks: it scores 82.7% on Terminal-Bench 2.0, compared with Claude Opus 4.7 at 69.4% and DeepSeek-V4-Pro-Max at 67.9%.
- The available evidence supports a clear but incomplete picture: Claude Opus 4.7 leads the cited GPQA Diamond and Humanity’s Last Exam no-tools results and is reported #1 in Vision & Document Arena [4][1]. GPT-5.5 leads the cited Terminal-Bench 2.0, OSWorld-Verified, and FrontierM
- ## Key findings
Research answer
The available evidence supports a clear but incomplete picture: Claude Opus 4.7 leads the cited GPQA Diamond and Humanity’s Last Exam no-tools results and is reported #1 in Vision & Document Arena [4][
1]. GPT-5.5 leads the cited Terminal-Bench 2.0, OSWorld-Verified, and FrontierMath results, while GPT-5.5 Pro leads Humanity’s Last Exam with tools [
4][
5]. DeepSeek V4 is reported as near-frontier at much lower cost and as the top open-weight model on one coding benchmark, but Kimi K2.6 has insufficient numeric evidence in the provided excerpts for a full benchmark comparison [
4][
18][
1].
Key findings
-
Claude Opus 4.7 has the strongest cited results on GPQA Diamond at 94.2% versus GPT-5.5 at 93.6% and DeepSeek-V4-Pro-Max at 90.1% [
4].
-
Claude Opus 4.7 also leads the cited Humanity’s Last Exam no-tools result at 46.9%, ahead of GPT-5.5 Pro at 43.1%, GPT-5.5 at 41.4%, and DeepSeek-V4-Pro-Max at 37.7% [
4].
-
GPT-5.5 Pro leads the cited Humanity’s Last Exam with-tools result at 57.2%, ahead of Claude Opus 4.7 at 54.7%, GPT-5.5 at 52.2%, and DeepSeek-V4-Pro-Max at 48.2% [
4].
-
GPT-5.5 is strongest in the cited terminal/agentic-computing benchmarks: it scores 82.7% on Terminal-Bench 2.0, compared with Claude Opus 4.7 at 69.4% and DeepSeek-V4-Pro-Max at 67.9% [
4][
5].
-
GPT-5.5 narrowly leads Claude Opus 4.7 on OSWorld-Verified, 78.7% versus 78.0% [
5].
-
GPT-5.5 leads Claude Opus 4.7 on FrontierMath Tiers 1–3, 51.7% versus 43.8% [
5].
-
Claude Opus 4.7 is reported #1 in Vision & Document Arena, with a +4 point improvement over Opus 4.6 in Document Arena and wins in diagram, homework, and OCR subcategories [
1].
-
DeepSeek V4 is described as achieving near state-of-the-art intelligence at about one-sixth the cost of Opus 4.7 and GPT-5.5, but the available evidence does not provide the underlying price schedule or methodology [
4].
-
DeepSeek V4 is claimed to be the #1 open-weight model on a Vibe Code Benchmark, ahead of Kimi K2.6 at #2, but this evidence comes from a Reddit snippet rather than a full benchmark report [
18].
-
Kimi K2.6 is described as a leading open-model refresh, but the provided evidence does not include enough numeric Kimi K2.6 scores to compare it comprehensively with GPT-5.5, Claude Opus 4.7, or DeepSeek V4 [
1].
Benchmark comparison table
| Benchmark / capability | GPT-5.5 | GPT-5.5 Pro | Claude Opus 4.7 | DeepSeek V4 | Kimi K2.6 | Leader in available evidence |
|---|---|---|---|---|---|---|
| GPQA Diamond | 93.6% [ | Insufficient evidence | 94.2% [ | 90.1% for DeepSeek-V4-Pro-Max [ | Insufficient evidence | Claude Opus 4.7 [ |
| Humanity’s Last Exam, no tools | 41.4% [ | 43.1% [ | 46.9% [ | 37.7% for DeepSeek-V4-Pro-Max [ | Insufficient evidence | Claude Opus 4.7 [ |
| Humanity’s Last Exam, with tools | 52.2% [ | 57.2% [ | 54.7% [ | 48.2% for DeepSeek-V4-Pro-Max [ | Insufficient evidence | GPT-5.5 Pro [ |
| Terminal-Bench 2.0 | 82.7% [ | Insufficient evidence | 69.4% [ | 67.9% for DeepSeek-V4-Pro-Max [ | Insufficient evidence | GPT-5.5 [ |
| OSWorld-Verified | 78.7% [ | Insufficient evidence | 78.0% [ | Insufficient evidence | Insufficient evidence | GPT-5.5 [ |
| FrontierMath Tiers 1–3 | 51.7% [ | Insufficient evidence | 43.8% [ | Insufficient evidence | Insufficient evidence | GPT-5.5 [ |
| Vision & Document Arena | Insufficient evidence | Insufficient evidence | Reported #1 overall [ | Insufficient evidence | Insufficient evidence | Claude Opus 4.7 [ |
| Vibe Code Benchmark | Insufficient evidence | Insufficient evidence | Insufficient evidence | Claimed #1 open-weight model [ | Claimed #2 open-weight model [ | DeepSeek V4 among open-weight models, low-confidence evidence [ |
| Context window | Insufficient evidence | Insufficient evidence | 1,000k tokens in one cited comparison [ | 1,000k tokens for DeepSeek V4 Pro in one cited comparison [ | Insufficient evidence | Tie between Claude Opus 4.7 and DeepSeek V4 Pro in available evidence [ |
Model-by-model assessment
GPT-5.5
-
GPT-5.5’s clearest advantage is agentic computing and operational task performance, led by its 82.7% Terminal-Bench 2.0 score [
4][
5].
-
GPT-5.5 also edges Claude Opus 4.7 on OSWorld-Verified, 78.7% versus 78.0% [
5].
-
GPT-5.5 shows a larger advantage over Claude Opus 4.7 on FrontierMath Tiers 1–3, 51.7% versus 43.8% [
5].
-
GPT-5.5 trails Claude Opus 4.7 on GPQA Diamond by 0.6 points, 93.6% versus 94.2% [
4].
-
GPT-5.5 Pro is the best cited model on Humanity’s Last Exam with tools, scoring 57.2% versus Claude Opus 4.7 at 54.7% [
4].
-
Additional GPT-5.5-only domain benchmarks include 91.7% on Harvey BigLaw Bench with 43% perfect scores, 88.5% on an internal investment-banking benchmark, and 80.5% on BixBench bioinformatics [
7]. These results are not directly comparable to the other three models because the provided excerpt does not include their scores on those same benchmarks [
7].
Claude Opus 4.7
-
Claude Opus 4.7 is the strongest cited model on GPQA Diamond, scoring 94.2% [
4].
-
Claude Opus 4.7 is also the strongest cited model on Humanity’s Last Exam without tools, scoring 46.9% [
4].
-
Claude Opus 4.7 ranks below GPT-5.5 Pro on Humanity’s Last Exam with tools, 54.7% versus 57.2% [
4].
-
Claude Opus 4.7 trails GPT-5.5 on Terminal-Bench 2.0 by more than 13 points, 69.4% versus 82.7% [
4][
5].
-
Claude Opus 4.7 is reported #1 in Vision & Document Arena and is said to lead in diagram, homework, and OCR subcategories [
1].
-
Claude Opus 4.7 has a cited 1,000k-token context window in an Artificial Analysis comparison with DeepSeek V4 Pro [
3].
DeepSeek V4
-
DeepSeek-V4-Pro-Max is competitive but trails GPT-5.5 and Claude Opus 4.7 on the cited GPQA Diamond, Humanity’s Last Exam, and Terminal-Bench 2.0 results [
4].
-
DeepSeek-V4-Pro-Max scores 90.1% on GPQA Diamond, 37.7% on Humanity’s Last Exam without tools, 48.2% on Humanity’s Last Exam with tools, and 67.9% on Terminal-Bench 2.0 [
4].
-
DeepSeek V4 is described as delivering near state-of-the-art intelligence at about one-sixth the cost of Opus 4.7 and GPT-5.5, but the excerpt does not provide enough detail to verify cost normalization or workload assumptions [
4].
-
DeepSeek V4 Pro is cited with a 1,000k-token context window in a comparison against Claude Opus 4.7 [
3].
-
A Reddit snippet claims DeepSeek V4 is the #1 open-weight model on a Vibe Code Benchmark and ranks above Kimi K2.6, but this should be treated as low-confidence evidence because the provided excerpt lacks a full methodology or score table [
18].
Kimi K2.6
-
Kimi K2.6 has the weakest quantitative coverage in the available evidence [
1][
18].
-
One source describes Kimi K2.6 as a leading open-model refresh, but the provided excerpt does not expose benchmark scores that can be compared against GPT-5.5, Claude Opus 4.7, or DeepSeek V4 [
1].
-
The only direct Kimi ranking in the available evidence is a Reddit snippet claiming Kimi K2.6 is #2 behind DeepSeek V4 on a Vibe Code Benchmark among open-weight models [
18].
-
Insufficient evidence: the provided material does not support a comprehensive numerical evaluation of Kimi K2.6 across reasoning, math, coding, agentic-computing, multimodal, or long-context benchmarks.
Evidence notes
-
The most usable quantitative cross-model evidence comes from the cited table comparing DeepSeek-V4-Pro-Max, GPT-5.5, GPT-5.5 Pro where available, and Claude Opus 4.7 across GPQA Diamond, Humanity’s Last Exam, and Terminal-Bench 2.0 [
4].
-
GPT-5.5 versus Claude Opus 4.7 is additionally supported by a separate source reporting the same Terminal-Bench 2.0 figures and adding OSWorld-Verified and FrontierMath results [
5].
-
The cited Artificial Analysis comparison provides context-window information for DeepSeek V4 Pro and Claude Opus 4.7, both listed at 1,000k tokens in that comparison [
3].
-
The Vision & Document Arena evidence supports Claude Opus 4.7’s multimodal/document strength, but it does not provide numeric scores for GPT-5.5, DeepSeek V4, or Kimi K2.6 [
1].
-
The Mashable and Design for Online snippets do not provide benchmark values in the supplied evidence, so they cannot support quantitative conclusions here [
2][
6].
Limitations / uncertainty
-
Insufficient evidence: no primary model cards, official benchmark reports, full prompt settings, confidence intervals, or independent reproducibility details are included in the provided evidence.
-
Insufficient evidence: Kimi K2.6 lacks numeric benchmark coverage in the provided excerpts, so any Kimi ranking beyond the Vibe Code claim is unsupported [
1][
18].
-
The benchmark comparisons mix model variants and modes, including GPT-5.5, GPT-5.5 Pro, DeepSeek-V4-Pro-Max, DeepSeek V4 Pro, and Claude Opus 4.7 with differing reasoning or effort settings [
3][
4].
-
The Vibe Code claim for DeepSeek V4 and Kimi K2.6 is low confidence because the available evidence is a Reddit snippet without benchmark scores or methodology [
18].
-
The cost-performance claim for DeepSeek V4 is promising but under-specified because the provided evidence reports “1/6th the cost” without enough details to normalize by token pricing, latency, benchmark workload, or deployment assumptions [
4].
Summary
-
Best cited reasoning/science model: Claude Opus 4.7, based on GPQA Diamond and Humanity’s Last Exam without tools [
4].
-
Best cited tool-augmented exam result: GPT-5.5 Pro, based on Humanity’s Last Exam with tools [
4].
-
Best cited terminal/agentic-computing model: GPT-5.5, based on Terminal-Bench 2.0 [
4][
5].
-
Best cited OS/world-operation and math results between GPT-5.5 and Claude Opus 4.7: GPT-5.5, based on OSWorld-Verified and FrontierMath [
5].
-
Best cited multimodal/document model: Claude Opus 4.7, based on Vision & Document Arena reporting [
1].
-
Best cited open-weight coding claim: DeepSeek V4 over Kimi K2.6 on Vibe Code, but this is low-confidence because the evidence is only a Reddit snippet [
18].
-
Most under-evidenced model: Kimi K2.6, because the provided evidence does not include enough quantitative benchmark results for a comprehensive comparison [
1][
18].
Supporting visuals









Research conversation
Research question
Research benchmarks for GPT-5.5, Claude Opus 4.7, DeepSeek V4, and Kimi K2.6, and compare them as comprehensively as possible. Create a research report on this.
Cited answer
The available evidence supports a clear but incomplete picture: Claude Opus 4.7 leads the cited GPQA Diamond and Humanity’s Last Exam no-tools results and is reported #1 in Vision & Document Arena [4][
1]. GPT-5.5 leads the cited Terminal-Bench 2.0, OSWorld-Verified, and FrontierMath results, while GPT-5.5 Pro leads Humanity’s Last Exam with tools [
4][
5]. DeepSeek V4 is reported as near-frontier at much lower cost and as the top open-weight model on one coding benchmark, but Kimi K2.6 has insufficient numeric evidence in the provided excerpts for a full benchmark comparison [
4][
18][
1].
Key findings
-
Claude Opus 4.7 has the strongest cited results on GPQA Diamond at 94.2% versus GPT-5.5 at 93.6% and DeepSeek-V4-Pro-Max at 90.1% [
4].
-
Claude Opus 4.7 also leads the cited Humanity’s Last Exam no-tools result at 46.9%, ahead of GPT-5.5 Pro at 43.1%, GPT-5.5 at 41.4%, and DeepSeek-V4-Pro-Max at 37.7% [
4].
-
GPT-5.5 Pro leads the cited Humanity’s Last Exam with-tools result at 57.2%, ahead of Claude Opus 4.7 at 54.7%, GPT-5.5 at 52.2%, and DeepSeek-V4-Pro-Max at 48.2% [
4].
-
GPT-5.5 is strongest in the cited terminal/agentic-computing benchmarks: it scores 82.7% on Terminal-Bench 2.0, compared with Claude Opus 4.7 at 69.4% and DeepSeek-V4-Pro-Max at 67.9% [
4][
5].
-
GPT-5.5 narrowly leads Claude Opus 4.7 on OSWorld-Verified, 78.7% versus 78.0% [
5].
-
GPT-5.5 leads Claude Opus 4.7 on FrontierMath Tiers 1–3, 51.7% versus 43.8% [
5].
-
Claude Opus 4.7 is reported #1 in Vision & Document Arena, with a +4 point improvement over Opus 4.6 in Document Arena and wins in diagram, homework, and OCR subcategories [
1].
-
DeepSeek V4 is described as achieving near state-of-the-art intelligence at about one-sixth the cost of Opus 4.7 and GPT-5.5, but the available evidence does not provide the underlying price schedule or methodology [
4].
-
DeepSeek V4 is claimed to be the #1 open-weight model on a Vibe Code Benchmark, ahead of Kimi K2.6 at #2, but this evidence comes from a Reddit snippet rather than a full benchmark report [
18].
-
Kimi K2.6 is described as a leading open-model refresh, but the provided evidence does not include enough numeric Kimi K2.6 scores to compare it comprehensively with GPT-5.5, Claude Opus 4.7, or DeepSeek V4 [
1].
Benchmark comparison table
| Benchmark / capability | GPT-5.5 | GPT-5.5 Pro | Claude Opus 4.7 | DeepSeek V4 | Kimi K2.6 | Leader in available evidence |
|---|---|---|---|---|---|---|
| GPQA Diamond | 93.6% [ | Insufficient evidence | 94.2% [ | 90.1% for DeepSeek-V4-Pro-Max [ | Insufficient evidence | Claude Opus 4.7 [ |
| Humanity’s Last Exam, no tools | 41.4% [ | 43.1% [ | 46.9% [ | 37.7% for DeepSeek-V4-Pro-Max [ | Insufficient evidence | Claude Opus 4.7 [ |
| Humanity’s Last Exam, with tools | 52.2% [ | 57.2% [ | 54.7% [ | 48.2% for DeepSeek-V4-Pro-Max [ | Insufficient evidence | GPT-5.5 Pro [ |
| Terminal-Bench 2.0 | 82.7% [ | Insufficient evidence | 69.4% [ | 67.9% for DeepSeek-V4-Pro-Max [ | Insufficient evidence | GPT-5.5 [ |
| OSWorld-Verified | 78.7% [ | Insufficient evidence | 78.0% [ | Insufficient evidence | Insufficient evidence | GPT-5.5 [ |
| FrontierMath Tiers 1–3 | 51.7% [ | Insufficient evidence | 43.8% [ | Insufficient evidence | Insufficient evidence | GPT-5.5 [ |
| Vision & Document Arena | Insufficient evidence | Insufficient evidence | Reported #1 overall [ | Insufficient evidence | Insufficient evidence | Claude Opus 4.7 [ |
| Vibe Code Benchmark | Insufficient evidence | Insufficient evidence | Insufficient evidence | Claimed #1 open-weight model [ | Claimed #2 open-weight model [ | DeepSeek V4 among open-weight models, low-confidence evidence [ |
| Context window | Insufficient evidence | Insufficient evidence | 1,000k tokens in one cited comparison [ | 1,000k tokens for DeepSeek V4 Pro in one cited comparison [ | Insufficient evidence | Tie between Claude Opus 4.7 and DeepSeek V4 Pro in available evidence [ |
Model-by-model assessment
GPT-5.5
-
GPT-5.5’s clearest advantage is agentic computing and operational task performance, led by its 82.7% Terminal-Bench 2.0 score [
4][
5].
-
GPT-5.5 also edges Claude Opus 4.7 on OSWorld-Verified, 78.7% versus 78.0% [
5].
-
GPT-5.5 shows a larger advantage over Claude Opus 4.7 on FrontierMath Tiers 1–3, 51.7% versus 43.8% [
5].
-
GPT-5.5 trails Claude Opus 4.7 on GPQA Diamond by 0.6 points, 93.6% versus 94.2% [
4].
-
GPT-5.5 Pro is the best cited model on Humanity’s Last Exam with tools, scoring 57.2% versus Claude Opus 4.7 at 54.7% [
4].
-
Additional GPT-5.5-only domain benchmarks include 91.7% on Harvey BigLaw Bench with 43% perfect scores, 88.5% on an internal investment-banking benchmark, and 80.5% on BixBench bioinformatics [
7]. These results are not directly comparable to the other three models because the provided excerpt does not include their scores on those same benchmarks [
7].
Claude Opus 4.7
-
Claude Opus 4.7 is the strongest cited model on GPQA Diamond, scoring 94.2% [
4].
-
Claude Opus 4.7 is also the strongest cited model on Humanity’s Last Exam without tools, scoring 46.9% [
4].
-
Claude Opus 4.7 ranks below GPT-5.5 Pro on Humanity’s Last Exam with tools, 54.7% versus 57.2% [
4].
-
Claude Opus 4.7 trails GPT-5.5 on Terminal-Bench 2.0 by more than 13 points, 69.4% versus 82.7% [
4][
5].
-
Claude Opus 4.7 is reported #1 in Vision & Document Arena and is said to lead in diagram, homework, and OCR subcategories [
1].
-
Claude Opus 4.7 has a cited 1,000k-token context window in an Artificial Analysis comparison with DeepSeek V4 Pro [
3].
DeepSeek V4
-
DeepSeek-V4-Pro-Max is competitive but trails GPT-5.5 and Claude Opus 4.7 on the cited GPQA Diamond, Humanity’s Last Exam, and Terminal-Bench 2.0 results [
4].
-
DeepSeek-V4-Pro-Max scores 90.1% on GPQA Diamond, 37.7% on Humanity’s Last Exam without tools, 48.2% on Humanity’s Last Exam with tools, and 67.9% on Terminal-Bench 2.0 [
4].
-
DeepSeek V4 is described as delivering near state-of-the-art intelligence at about one-sixth the cost of Opus 4.7 and GPT-5.5, but the excerpt does not provide enough detail to verify cost normalization or workload assumptions [
4].
-
DeepSeek V4 Pro is cited with a 1,000k-token context window in a comparison against Claude Opus 4.7 [
3].
-
A Reddit snippet claims DeepSeek V4 is the #1 open-weight model on a Vibe Code Benchmark and ranks above Kimi K2.6, but this should be treated as low-confidence evidence because the provided excerpt lacks a full methodology or score table [
18].
Kimi K2.6
-
Kimi K2.6 has the weakest quantitative coverage in the available evidence [
1][
18].
-
One source describes Kimi K2.6 as a leading open-model refresh, but the provided excerpt does not expose benchmark scores that can be compared against GPT-5.5, Claude Opus 4.7, or DeepSeek V4 [
1].
-
The only direct Kimi ranking in the available evidence is a Reddit snippet claiming Kimi K2.6 is #2 behind DeepSeek V4 on a Vibe Code Benchmark among open-weight models [
18].
-
Insufficient evidence: the provided material does not support a comprehensive numerical evaluation of Kimi K2.6 across reasoning, math, coding, agentic-computing, multimodal, or long-context benchmarks.
Evidence notes
-
The most usable quantitative cross-model evidence comes from the cited table comparing DeepSeek-V4-Pro-Max, GPT-5.5, GPT-5.5 Pro where available, and Claude Opus 4.7 across GPQA Diamond, Humanity’s Last Exam, and Terminal-Bench 2.0 [
4].
-
GPT-5.5 versus Claude Opus 4.7 is additionally supported by a separate source reporting the same Terminal-Bench 2.0 figures and adding OSWorld-Verified and FrontierMath results [
5].
-
The cited Artificial Analysis comparison provides context-window information for DeepSeek V4 Pro and Claude Opus 4.7, both listed at 1,000k tokens in that comparison [
3].
-
The Vision & Document Arena evidence supports Claude Opus 4.7’s multimodal/document strength, but it does not provide numeric scores for GPT-5.5, DeepSeek V4, or Kimi K2.6 [
1].
-
The Mashable and Design for Online snippets do not provide benchmark values in the supplied evidence, so they cannot support quantitative conclusions here [
2][
6].
Limitations / uncertainty
-
Insufficient evidence: no primary model cards, official benchmark reports, full prompt settings, confidence intervals, or independent reproducibility details are included in the provided evidence.
-
Insufficient evidence: Kimi K2.6 lacks numeric benchmark coverage in the provided excerpts, so any Kimi ranking beyond the Vibe Code claim is unsupported [
1][
18].
-
The benchmark comparisons mix model variants and modes, including GPT-5.5, GPT-5.5 Pro, DeepSeek-V4-Pro-Max, DeepSeek V4 Pro, and Claude Opus 4.7 with differing reasoning or effort settings [
3][
4].
-
The Vibe Code claim for DeepSeek V4 and Kimi K2.6 is low confidence because the available evidence is a Reddit snippet without benchmark scores or methodology [
18].
-
The cost-performance claim for DeepSeek V4 is promising but under-specified because the provided evidence reports “1/6th the cost” without enough details to normalize by token pricing, latency, benchmark workload, or deployment assumptions [
4].
Summary
-
Best cited reasoning/science model: Claude Opus 4.7, based on GPQA Diamond and Humanity’s Last Exam without tools [
4].
-
Best cited tool-augmented exam result: GPT-5.5 Pro, based on Humanity’s Last Exam with tools [
4].
-
Best cited terminal/agentic-computing model: GPT-5.5, based on Terminal-Bench 2.0 [
4][
5].
-
Best cited OS/world-operation and math results between GPT-5.5 and Claude Opus 4.7: GPT-5.5, based on OSWorld-Verified and FrontierMath [
5].
-
Best cited multimodal/document model: Claude Opus 4.7, based on Vision & Document Arena reporting [
1].
-
Best cited open-weight coding claim: DeepSeek V4 over Kimi K2.6 on Vibe Code, but this is low-confidence because the evidence is only a Reddit snippet [
18].
-
Most under-evidenced model: Kimi K2.6, because the provided evidence does not include enough quantitative benchmark results for a comprehensive comparison [
1][
18].
People also ask
What is the short answer to "Research benchmarks for GPT-5.5, Claude Opus 4.7, DeepSeek V4, and Kimi K2.6, and compare them as comprehensively as possible. Create a research report on this."?
Claude Opus 4.7 has the strongest cited results on GPQA Diamond at 94.2% versus GPT-5.5 at 93.6% and DeepSeek-V4-Pro-Max at 90.1%.
What are the key points to validate first?
Claude Opus 4.7 has the strongest cited results on GPQA Diamond at 94.2% versus GPT-5.5 at 93.6% and DeepSeek-V4-Pro-Max at 90.1%. Claude Opus 4.7 also leads the cited Humanity’s Last Exam no-tools result at 46.9%, ahead of GPT-5.5 Pro at 43.1%, GPT-5.5 at 41.4%, and DeepSeek-V4-Pro-Max at 37.7%.
What should I do next in practice?
GPT-5.5 Pro leads the cited Humanity’s Last Exam with-tools result at 57.2%, ahead of Claude Opus 4.7 at 54.7%, GPT-5.5 at 52.2%, and DeepSeek-V4-Pro-Max at 48.2%.
Which related topic should I explore next?
Continue with "Research benchmarks of Claude Opus 4.7, GPT-5.5, DeepSeek V4, Kimi K2.6 and compare as comprehensively as possible" for another angle and extra citations.
Open related pageWhat should I compare this against?
Cross-check this answer against "Research & compare Claude Code vs OpenAI Codex as comprehensively as possible".
Open related pageContinue your research
Sources
- [1] [AINews] Moonshot Kimi K2.6: the world's leading Open Model refreshes to catch up to Opus 4.6 (ahead of DeepSeek v4?)latent.space
Arena results continued to matter for multimodal models. @arena reported Claude Opus 4.7 taking 1 in Vision & Document Arena, with +4 points over Opus 4.6 in Document Arena and a large margin over the next non-Anthropic models. Subcategory wins included dia...
- [2] DeepSeek V4 is here: How it compares to ChatGPT, Claude, Geminimashable.com
A game being played on a smartphone. NYT Connections hints today: Clues, answers for April 25, 2026 Everything you need to solve 'Connections' 1049. By Mashable Team Connections game on a smartphone Connections game on a smartphone OpenAI’s GPT-5.5 vs Claud...
- [3] DeepSeek V4 Pro (Reasoning, Max Effort) vs Claude Opus 4.7 (Non-reasoning, High Effort): Model Comparisonartificialanalysis.ai
Metric DeepSeek logoDeepSeek V4 Pro (Reasoning, Max Effort) Anthropic logoClaude Opus 4.7 (Non-reasoning, High Effort) Analysis --- --- Creator DeepSeek Anthropic Context Window 1000k tokens ( 1500 A4 pages of size 12 Arial font) 1000k tokens ( 1500 A4 page...
- [4] DeepSeek-V4 arrives with near state-of-the-art intelligence at 1/6th ...venturebeat.com
BenchmarkDeepSeek-V4-Pro-MaxGPT-5.5GPT-5.5 Pro, where shownClaude Opus 4.7Best result among these GPQA Diamond90.1%93.6%—94.2%Claude Opus 4.7 Humanity’s Last Exam, no tools37.7%41.4%43.1%46.9%Claude Opus 4.7 Humanity’s Last Exam, with tools48.2%52.2%57.2%54...
- [5] Everything You Need to Know About GPT-5.5vellum.ai
The headline numbers GPT-5.5 achieves state-of-the-art on Terminal-Bench 2.0 at 82.7%, leading Claude Opus 4.7 (69.4%) by over 13 points. On OSWorld-Verified, which tests real computer environment operation, it edges out Claude at 78.7% vs 78.0%. On Frontie...
- [6] GPT-5.5 (high) Review | Pricing, Benchmarks & Capabilities (2026)designforonline.com
5 AI Business Automations You Can Implement Today SEO Pricing UK: A Clear Guide to Our Packages Viral Video Adverts with Google's Veo 3, IKEA, John Lewis, Lego, Dunelm and more. The Best AI Models So Far in 2026 Design for Online Gemini 3.1 Pro, Claude Sonn...
- [7] GPT-5.5: The Complete Guide (2026) - o-mega | AIo-mega.ai
Domain-Specific Benchmarks Benchmark GPT-5.5 Notes --- Harvey BigLaw Bench 91.7% (43% perfect scores) Legal reasoning, audience calibration Internal Investment Banking 88.5% Financial analysis tasks BixBench (bioinformatics) 80.5% (up from 74.0%) +6.5pts ov...
- [8] Introducing GPT-5.5 - OpenAIopenai.com
Abstract reasoning EvalGPT-5.5GPT‑5.4GPT-5.5 ProGPT‑5.4 ProClaude Opus 4.7Gemini 3.1 Pro ARC-AGI-1 (Verified)95.0%93.7%-94.5%93.5%98.0% ARC-AGI-2 (Verified)85.0%73.3%-83.3%75.8%77.1% Evals of GPT were run with reasoning effort set to xhigh and were conducte...
- [9] Kimi K2.6 vs DeepSeek V4 vs GPT-5.5 vs Claude Opus 4.7: Which Should You Test First? | LaoZhang AI Blogblog.laozhang.ai
As of Apr 24, 2026, this comparison should be built around DeepSeek V4, not an older DeepSeek label. Test Kimi K2.6 first when the job is low-cost coding-agent exploration, test DeepSeek V4 Flash or V4 Pro when you need a cheap callable API route today, use...
- [10] GPT-5.5 Benchmarks 2026: Scores, Rankings & Performancebenchlm.ai
benchlm.ai @glevd GPT-5.5 OpenAICurrentReleased Apr 23, 2026 Overall Score 93Prov. 2 of 115Verified 3 of 23 Arena Elo N/A Categories Ranked 2of 8 Price (1M tokens) $5 in / $30 out Speed N/A Context 1M ProprietaryReasoning Confidence base According to BenchL...
- [11] Kimi K2.6 vs DeepSeek-V4 Pro - DocsBot AIdocsbot.ai
Benchmark Kimi K2.6 DeepSeek-V4 Pro --- AIME 2026 American Invitational Mathematics Examination 2026 - Evaluates advanced mathematical problem-solving abilities (contest-level math) 96.4% Thinking mode Source Not available APEX Agents Evaluates long-horizon...
- [12] I reviewed how DeepSeek V4-Pro, Kimi 2.6, Opus 4.6, and Opus 4.7 ...news.ycombinator.com
ozgune 1 day ago parent context favorite on: DeepSeek v4 I reviewed how DeepSeek V4-Pro, Kimi 2.6, Opus 4.6, and Opus 4.7 across the same AI benchmarks. All results are for Max editions, except for Kimi. Summary: Opus 4.6 forms the baseline all three are tr...
- [13] Kimi K2.6 vs Claude Opus 4.6 vs GPT-5.4 - Verdent AIverdent.ai
Benchmark K2.6 Claude Opus 4.6 GPT-5.4 Notes --- --- SWE-Bench Pro 58.60% 53.40% 57.70% Moonshot in-house harness; SEAL mini-swe-agent puts GPT-5.4 at 59.1%, Opus 4.6 at 51.9% SWE-Bench Verified 80.20% 80.80% 80% Tight cluster; Opus 4.7 now leads at 87.6% T...
- [14] Kimi K2.6 vs DeepSeek V2 vs GPT-5.5 vs Claude Opus 4.7: Which Should You Test First? | LaoZhang AI Blogblog.laozhang.ai
Contract item Kimi K2.6 Current DeepSeek API GPT-5.5 Claude Opus 4.7 --- --- Owner route Moonshot / Kimi platform DeepSeek API OpenAI ChatGPT and Codex first Anthropic API and Claude/cloud routes Current deploy label kimi-k2.6 deepseek-v4-flash or deepseek-...
- [15] The Coding Assistant Breakdown: More Tokens Please - SemiAnalysisnewsletter.semianalysis.com
On benchmarks, DeepSeek did not feel that standard benchmarks were good at capturing real-world task capability, so they introduced their own set of agentic benchmarks to measure how V4 compared against other SOTA models: Chinese writing, retrieval augmente...
- [16] Claude Opus 4.7 Isn't a Drop-in Replacement for 4.6blog.dailydoseofds.com
It ended up running around 20% faster than LM Studio on the same hardware. Separately, it refactored an 8-year-old financial matching engine across 13 hours, delivering a 133% peak throughput gain. This is the capability gap that usually separates frontier...
- [17] AI Leaderboard 2026 - Compare Top AI Models & Rankingsllm-stats.com
13 Image 14: OpenAI GPT-5 High OpenAI 1,301 1,067 87.3% — — — — Proprietary 14 Image 15: OpenAI GPT-5.3 Codex OpenAI 1,244 821 — — 400K $1.75 $14.00 Proprietary 15 Image 16: OpenAI GPT-5.1 OpenAI 1,231 1,013 88.1% 76.3% 400K $1.25 $10.00 Proprietary 16 Imag...
- [18] "DeepSeek v4 is now the #1 open-weight model on our Vibe Code Benchmark, and it’s not close. It leaves the #2 (Kimi K2.6) in the dust, and even beats out frontier closed source models like Gemini 3.1 Pro." : r/acceleratereddit.com
Ethical considerations in AI development Latest breakthroughs in machine learning Impact of AI on job markets Public Anyone can view, post, and comment to this community 0 0 Reddit RulesPrivacy PolicyUser AgreementYour Privacy ChoicesAccessibilityReddit, In...
- [19] Deep|DeepSeek V4 vs Claude vs GPT-5.4: A 38-Task ... - FundaAIfundaai.substack.com
Coding (8 tasks): Standard DeepSeek Pro and Flash score about 8.1 avg. DeepSeek Pro (Thinking) scores 8.48 on 4 completed coding tasks and Flash (Thinking) scores 8.44 on 6 completed coding tasks, but hard coding timeouts make the thinking-mode results less...
- [20] I just ran the math on GPT-5.5, Claude Opus 4.7, Kimi K2 ... - Facebookfacebook.com
Vibe Coding is Life I just ran the math on GPT-5.5, Claude Opus 4.7, Kimi K2.6, DeepSeek V4, and Llama 4 Facebook Log In Log In Forgot Account? The exact break-even point where self-hosting beats API pricing Why your biggest self-hosting cost isn't GPUs — i...
- [21] GPT 5.5 is out. Here are the benchmarks. - Facebookfacebook.com
1d 4 Image 3 View all 3 replies []( Robert Eaton Opus 4.7 has been terrible. Getting everything wrong, making same mistake over and over. I went back to 4.6 and everything was fine 1d 4 Image 4Image 5 View all 2 replies []( Patrick Healy Codex $100a month p...