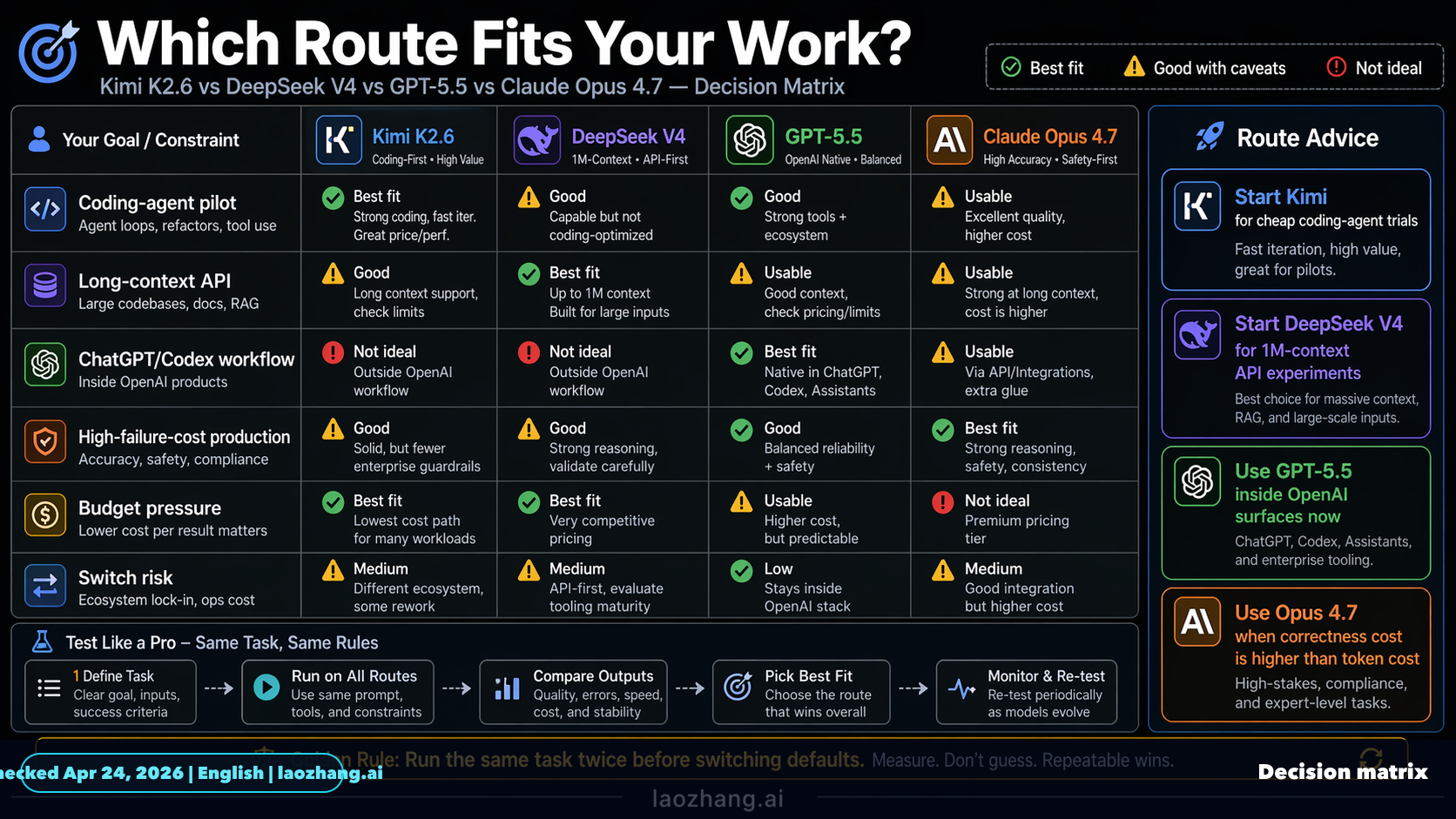
Recherchieren Sie die Benchmarks von Claude Opus 4.7, GPT-5.5, DeepSeek V4 und Kimi K2.6 und vergleichen Sie sie so umfassend wie möglich im Format eines Forschungsberichts, damit alle sie leicht verstehen können.
Auf Basis der vorliegenden Belege wirkt GPT 5.5 insgesamt am stärksten belegt: Es führt im genannten „Intelligence Index“ und liegt auch bei BrowseComp vor Claude Opus 4.7 und knapp vor DeepSeek V4 [6][7]. DeepSeek V4...
Auf Basis der vorliegenden Belege wirkt GPT 5.5 insgesamt am stärksten belegt: Es führt im genannten „Intelligence Index“ und liegt auch bei BrowseComp vor Claude Opus 4.7 und knapp vor DeepSeek V4 [6][7]. DeepSeek V4 ist besonders auffällig, weil es bei BrowseComp Claude Opus 4.7 schlägt und GPT 5.5 fast erreicht, abe
Wichtige Erkenntnisse
- Auf Basis der vorliegenden Belege wirkt GPT-5.5 insgesamt am stärksten belegt: Es führt im genannten „Intelligence Index“ und liegt auch bei BrowseComp vor Claude Opus 4.7 und knapp vor DeepSeek V4 [6][7]. DeepSeek V4 ist besonders auffällig, weil es bei BrowseComp Claude Opus 4.7 schlägt und GPT-5.
- GPT-5.5 wird im verfügbaren Artificial-Analysis-Ausschnitt als Nummer 1 und 2 des „Intelligence Index“ geführt: GPT-5.5 „xhigh“ mit 60 Punkten und GPT-5.5 „high“ mit 59 Punkten.
- Claude Opus 4.7 wird im selben Ausschnitt mit „Adaptive Reasoning, Max Effort“ bei 57 Punkten genannt und damit hinter GPT-5.5 xhigh und GPT-5.5 high eingeordnet.
- Bei BrowseComp erreicht DeepSeek V4 laut verfügbarem Bericht 83,4 %, Claude Opus 4.7 79,3 % und GPT-5.5 84,4 %; GPT-5.5 Pro liegt mit 90,1 % deutlich höher.
- DeepSeek V4 schlägt Claude Opus 4.7 in BrowseComp, liegt dort aber knapp hinter GPT-5.5 und klar hinter GPT-5.5 Pro.
- Auf Basis der vorliegenden Belege wirkt GPT-5.5 insgesamt am stärksten belegt: Es führt im genannten „Intelligence Index“ und liegt auch bei BrowseComp vor Claude Opus 4.7 und knapp vor DeepSeek V4 [6][7]. DeepSeek V4 ist besonders auffällig, weil es bei BrowseComp Claude Opus 4.
- ## Key findings
Forschungsantwort
Auf Basis der vorliegenden Belege wirkt GPT-5.5 insgesamt am stärksten belegt: Es führt im genannten „Intelligence Index“ und liegt auch bei BrowseComp vor Claude Opus 4.7 und knapp vor DeepSeek V4 [6][
7]. DeepSeek V4 ist besonders auffällig, weil es bei BrowseComp Claude Opus 4.7 schlägt und GPT-5.5 fast erreicht, aber die verfügbaren Belege reichen nicht, um es insgesamt vor GPT-5.5 oder Claude Opus 4.7 einzuordnen [
7]. Für Kimi K2.6 fehlen belastbare Zahlenwerte; hier ist die Evidenz deutlich schwächer [
21].
Key findings
-
GPT-5.5 wird im verfügbaren Artificial-Analysis-Ausschnitt als Nummer 1 und 2 des „Intelligence Index“ geführt: GPT-5.5 „xhigh“ mit 60 Punkten und GPT-5.5 „high“ mit 59 Punkten [
6].
-
Claude Opus 4.7 wird im selben Ausschnitt mit „Adaptive Reasoning, Max Effort“ bei 57 Punkten genannt und damit hinter GPT-5.5 xhigh und GPT-5.5 high eingeordnet [
6].
-
Bei BrowseComp erreicht DeepSeek V4 laut verfügbarem Bericht 83,4 %, Claude Opus 4.7 79,3 % und GPT-5.5 84,4 %; GPT-5.5 Pro liegt mit 90,1 % deutlich höher [
7].
-
DeepSeek V4 schlägt Claude Opus 4.7 in BrowseComp, liegt dort aber knapp hinter GPT-5.5 und klar hinter GPT-5.5 Pro [
7].
-
Trotz des starken BrowseComp-Werts heißt es im verfügbaren Bericht, DeepSeek-V4-Pro-Max entthrone GPT-5.5 oder Claude Opus 4.7 auf den direkt vergleichbaren Benchmarks insgesamt nicht [
7].
-
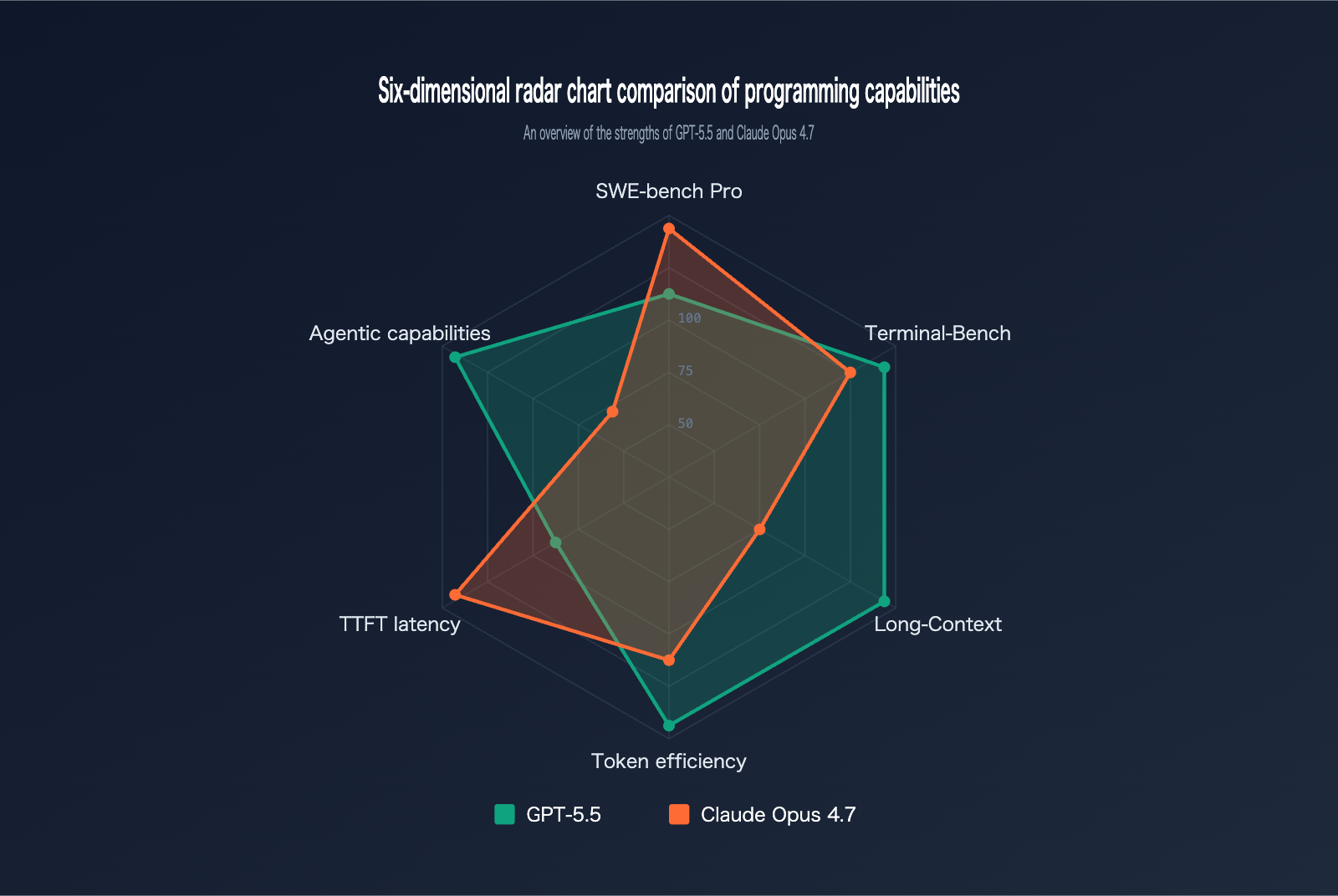
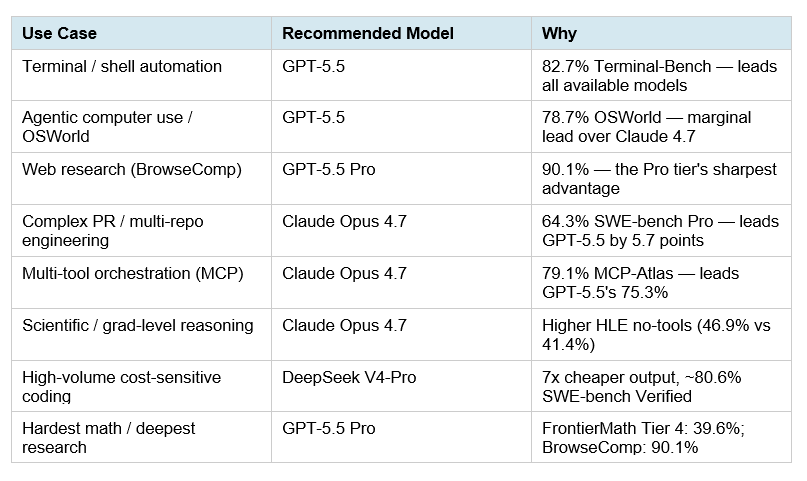
Für Claude Opus 4.7 liegen mehrere konkrete Benchmarkwerte vor: SWE-bench Pro 64,3 %, SWE-bench Verified 87,6 %, Terminal-Bench 69,4 % und GPQA Diamond 94,2 % [
3].
-
Ein weiterer verfügbarer Benchmarkhinweis nennt Claude Opus 4.7 mit 82,7 % auf FinanceBench, allerdings stammt dieser Wert aus einem sekundären Blogkontext und sollte vorsichtig interpretiert werden [
2].
-
Für Kimi K2.6 enthält die verfügbare Evidenz keine belastbaren numerischen Benchmarkwerte; ein Reddit-Beitrag behauptet lediglich, DeepSeek V4 sei im „Vibe Code Benchmark“ das führende Open-Weight-Modell und Kimi K2.6 liege dort auf Platz 2 [
21].
Vergleichstabelle
| Modell | Beste verfügbare Evidenz | Genannte Benchmarkwerte | Einordnung |
|---|---|---|---|
| GPT-5.5 | Führt den „Intelligence Index“ in zwei Varianten [ | Intelligence Index: 60 xhigh, 59 high; BrowseComp: 84,4 %; GPT-5.5 Pro BrowseComp: 90,1 % [ | Stärkster belegt unter den vier Modellen, vor allem im Intelligence Index und bei BrowseComp [ |
| Claude Opus 4.7 | Platz 3 im genannten Intelligence Index-Ausschnitt [ | Intelligence Index: 57; BrowseComp: 79,3 %; SWE-bench Pro: 64,3 %; SWE-bench Verified: 87,6 %; Terminal-Bench: 69,4 %; GPQA Diamond: 94,2 %; FinanceBench: 82,7 % [ | Sehr stark belegt, aber in den verfügbaren Vergleichsdaten hinter GPT-5.5 und bei BrowseComp hinter DeepSeek V4 [ |
| DeepSeek V4 | Sehr stark bei BrowseComp [ | BrowseComp: 83,4 %; API-Preis: $1.74 pro 1 Mio. Input-Tokens und $3.48 pro 1 Mio. Output-Tokens [ | Nahe an GPT-5.5 bei BrowseComp und besser als Claude Opus 4.7 in diesem Benchmark, aber nicht klarer Gesamtsieger [ |
| Kimi K2.6 | Nur schwacher Rankinghinweis aus Reddit [ | Keine belastbaren Zahlenwerte in der bereitgestellten Evidenz [ | Insufficient evidence: Keine solide numerische Einordnung möglich [ |
Benchmark-für-Benchmark-Vergleich
Intelligence Index
-
GPT-5.5 liegt im verfügbaren Ausschnitt des „Intelligence Index“ auf Platz 1 mit 60 Punkten in der xhigh-Konfiguration und auf Platz 2 mit 59 Punkten in der high-Konfiguration [
6].
-
Claude Opus 4.7 liegt in der Konfiguration „Adaptive Reasoning, Max Effort“ bei 57 Punkten und wird damit hinter beiden GPT-5.5-Varianten genannt [
6].
-
Für DeepSeek V4 und Kimi K2.6 werden im verfügbaren Ausschnitt keine konkreten Intelligence-Index-Werte genannt [
6].
BrowseComp
-
GPT-5.5 erreicht bei BrowseComp 84,4 %, während GPT-5.5 Pro 90,1 % erreicht [
7].
-
DeepSeek V4 erreicht bei BrowseComp 83,4 % und liegt damit sehr knapp hinter GPT-5.5, aber deutlich hinter GPT-5.5 Pro [
7].
-
Claude Opus 4.7 erreicht bei BrowseComp 79,3 % und liegt damit hinter DeepSeek V4 und GPT-5.5 [
7].
-
Kimi K2.6 hat in der bereitgestellten Evidenz keinen BrowseComp-Wert [
7][
21].
Coding- und Software-Benchmarks
-
Claude Opus 4.7 wird mit 64,3 % auf SWE-bench Pro und 87,6 % auf SWE-bench Verified angegeben [
3].
-
Claude Opus 4.7 wird außerdem mit etwa 70 % auf CursorBench genannt, aber dieser Vergleich stammt aus einem Kontext zu GPT-5.4, nicht GPT-5.5 [
4].
-
Für GPT-5.5, DeepSeek V4 und Kimi K2.6 liegen in der bereitgestellten Evidenz keine direkt vergleichbaren SWE-bench-Pro- oder SWE-bench-Verified-Werte vor [
3][
4][
7][
21].
-
Ein Reddit-Beitrag behauptet, DeepSeek V4 sei im „Vibe Code Benchmark“ das führende Open-Weight-Modell und Kimi K2.6 liege dahinter auf Platz 2, aber dieser Beleg ist schwächer als die übrigen Quellen und enthält im Ausschnitt keine konkreten Prozentwerte [
21].
Reasoning- und Wissens-Benchmarks
-
Claude Opus 4.7 wird mit 94,2 % auf GPQA Diamond angegeben [
3].
-
Für GPT-5.5, DeepSeek V4 und Kimi K2.6 liegen in der bereitgestellten Evidenz keine direkt vergleichbaren GPQA-Diamond-Werte vor [
3][
6][
7][
21].
FinanceBench
-
Claude Opus 4.7 wird in einem verfügbaren Blogausschnitt mit 82,7 % auf FinanceBench erwähnt [
2].
-
Für GPT-5.5, DeepSeek V4 und Kimi K2.6 liegen in der bereitgestellten Evidenz keine FinanceBench-Werte vor [
2][
5][
7][
21].
Preis- und Kontextvergleich
-
DeepSeek V4 wird mit $1.74 pro 1 Million Input-Tokens und $3.48 pro 1 Million Output-Tokens bei einem Kontextfenster von 1 Million Tokens angegeben [
5].
-
GPT-5.5 wird mit $5 pro 1 Million Input-Tokens und $30 pro 1 Million Output-Tokens bei einem Kontextfenster von 1 Million Tokens angegeben [
5].
-
Für Claude Opus 4.7 ist im verfügbaren Ausschnitt nur der Beginn einer Preisangabe erkennbar, aber kein vollständiger Output-Preis, daher reicht die Evidenz für einen vollständigen Kostenvergleich nicht aus [
5].
-
Für Kimi K2.6 enthält die bereitgestellte Evidenz keinen Preiswert [
5][
21].
Verständliche Einordnung
-
Wenn man nur die verfügbaren Zahlen betrachtet, ist GPT-5.5 der sicherste Kandidat für die stärkste Gesamtleistung, weil es den genannten Intelligence Index anführt und bei BrowseComp vor DeepSeek V4 und Claude Opus 4.7 liegt [
6][
7].
-
DeepSeek V4 ist der stärkste Herausforderer in den verfügbaren Zahlen, weil es bei BrowseComp mit 83,4 % fast GPT-5.5 erreicht und Claude Opus 4.7 übertrifft [
7].
-
Claude Opus 4.7 ist am breitesten mit konkreten Einzelbenchmarks belegt, vor allem in SWE-bench, Terminal-Bench, GPQA Diamond und FinanceBench [
2][
3].
-
Kimi K2.6 kann anhand der bereitgestellten Evidenz nicht fair numerisch mit den anderen drei Modellen verglichen werden, weil die einzige konkrete Aussage nur ein schwacher Reddit-Rankinghinweis ohne Zahlenwerte ist [
21].
Evidence notes
-
Die stärksten quantitativen Vergleichsdaten in der bereitgestellten Evidenz sind der Intelligence-Index-Ausschnitt und der BrowseComp-Vergleich, weil sie mehrere der angefragten Modelle direkt nebeneinander nennen [
6][
7].
-
Die Claude-Opus-4.7-Werte zu SWE-bench Pro, SWE-bench Verified, Terminal-Bench und GPQA Diamond sind nützlich, aber sie erlauben keinen vollständigen Vier-Modell-Vergleich, weil entsprechende Werte für GPT-5.5, DeepSeek V4 und Kimi K2.6 in der Evidenz fehlen [
3].
-
Der Kimi-K2.6-Hinweis ist deutlich schwächer, weil er aus einem Reddit-Beitrag stammt und im verfügbaren Ausschnitt keine numerischen Ergebnisse enthält [
21].
-
Ein Vergleich mit GPT-5.4 ist nur indirekt relevant, weil die Nutzerfrage GPT-5.5 betrifft; die verfügbare Quelle nennt dort außerdem, dass Benchmarkwerte teils vendor-reported sind und unterschiedliche Harness-Konfigurationen nutzen [
4].
Limitations / uncertainty
-
Insufficient evidence: Für Kimi K2.6 fehlen belastbare Benchmarkzahlen in der bereitgestellten Evidenz [
21].
-
Insufficient evidence: Für GPT-5.5 fehlen in der bereitgestellten Evidenz konkrete Werte zu SWE-bench, GPQA Diamond, Terminal-Bench, FinanceBench und Vibe Code [
6][
7].
-
Insufficient evidence: Für DeepSeek V4 fehlen in der bereitgestellten Evidenz konkrete Werte zu SWE-bench, GPQA Diamond, Terminal-Bench und FinanceBench [
5][
7][
21].
-
Die Modelle werden teils in unterschiedlichen Varianten oder Testmodi genannt, etwa GPT-5.5 xhigh, GPT-5.5 high, Claude Opus 4.7 „Adaptive Reasoning, Max Effort“ und DeepSeek-V4-Pro-Max, wodurch ein 1:1-Vergleich nur eingeschränkt möglich ist [
6][
7].
-
Die bereitgestellte Evidenz enthält keine vollständigen offiziellen Modellkarten oder Primärquellen mit einheitlichem Benchmark-Setup für alle vier Modelle [
1][
3][
6][
7].
Summary
-
GPT-5.5: Beste belegte Gesamtposition, führt den Intelligence Index und liegt bei BrowseComp vor DeepSeek V4 und Claude Opus 4.7 [
6][
7].
-
DeepSeek V4: Sehr stark bei BrowseComp, knapp hinter GPT-5.5 und vor Claude Opus 4.7; außerdem deutlich günstiger als GPT-5.5 in der verfügbaren Preisangabe [
5][
7].
-
Claude Opus 4.7: Sehr gut dokumentiert mit vielen Einzelbenchmarks, aber in den direkt verfügbaren Vergleichszahlen hinter GPT-5.5 und bei BrowseComp hinter DeepSeek V4 [
2][
3][
6][
7].
-
Kimi K2.6: Nicht seriös numerisch bewertbar, weil die bereitgestellte Evidenz nur einen schwachen Rankinghinweis ohne konkrete Zahlen enthält [
21].
Unterstützende Visuals













Forschungsgespräch
Forschungsfrage
Recherchieren Sie die Benchmarks von Claude Opus 4.7, GPT-5.5, DeepSeek V4 und Kimi K2.6 und vergleichen Sie sie so umfassend wie möglich im Format eines Forschungsberichts, damit alle sie leicht verstehen können.
Zitierte Antwort
Auf Basis der vorliegenden Belege wirkt GPT-5.5 insgesamt am stärksten belegt: Es führt im genannten „Intelligence Index“ und liegt auch bei BrowseComp vor Claude Opus 4.7 und knapp vor DeepSeek V4 [6][
7]. DeepSeek V4 ist besonders auffällig, weil es bei BrowseComp Claude Opus 4.7 schlägt und GPT-5.5 fast erreicht, aber die verfügbaren Belege reichen nicht, um es insgesamt vor GPT-5.5 oder Claude Opus 4.7 einzuordnen [
7]. Für Kimi K2.6 fehlen belastbare Zahlenwerte; hier ist die Evidenz deutlich schwächer [
21].
Key findings
-
GPT-5.5 wird im verfügbaren Artificial-Analysis-Ausschnitt als Nummer 1 und 2 des „Intelligence Index“ geführt: GPT-5.5 „xhigh“ mit 60 Punkten und GPT-5.5 „high“ mit 59 Punkten [
6].
-
Claude Opus 4.7 wird im selben Ausschnitt mit „Adaptive Reasoning, Max Effort“ bei 57 Punkten genannt und damit hinter GPT-5.5 xhigh und GPT-5.5 high eingeordnet [
6].
-
Bei BrowseComp erreicht DeepSeek V4 laut verfügbarem Bericht 83,4 %, Claude Opus 4.7 79,3 % und GPT-5.5 84,4 %; GPT-5.5 Pro liegt mit 90,1 % deutlich höher [
7].
-
DeepSeek V4 schlägt Claude Opus 4.7 in BrowseComp, liegt dort aber knapp hinter GPT-5.5 und klar hinter GPT-5.5 Pro [
7].
-
Trotz des starken BrowseComp-Werts heißt es im verfügbaren Bericht, DeepSeek-V4-Pro-Max entthrone GPT-5.5 oder Claude Opus 4.7 auf den direkt vergleichbaren Benchmarks insgesamt nicht [
7].
-
Für Claude Opus 4.7 liegen mehrere konkrete Benchmarkwerte vor: SWE-bench Pro 64,3 %, SWE-bench Verified 87,6 %, Terminal-Bench 69,4 % und GPQA Diamond 94,2 % [
3].
-
Ein weiterer verfügbarer Benchmarkhinweis nennt Claude Opus 4.7 mit 82,7 % auf FinanceBench, allerdings stammt dieser Wert aus einem sekundären Blogkontext und sollte vorsichtig interpretiert werden [
2].
-
Für Kimi K2.6 enthält die verfügbare Evidenz keine belastbaren numerischen Benchmarkwerte; ein Reddit-Beitrag behauptet lediglich, DeepSeek V4 sei im „Vibe Code Benchmark“ das führende Open-Weight-Modell und Kimi K2.6 liege dort auf Platz 2 [
21].
Vergleichstabelle
| Modell | Beste verfügbare Evidenz | Genannte Benchmarkwerte | Einordnung |
|---|---|---|---|
| GPT-5.5 | Führt den „Intelligence Index“ in zwei Varianten [ | Intelligence Index: 60 xhigh, 59 high; BrowseComp: 84,4 %; GPT-5.5 Pro BrowseComp: 90,1 % [ | Stärkster belegt unter den vier Modellen, vor allem im Intelligence Index und bei BrowseComp [ |
| Claude Opus 4.7 | Platz 3 im genannten Intelligence Index-Ausschnitt [ | Intelligence Index: 57; BrowseComp: 79,3 %; SWE-bench Pro: 64,3 %; SWE-bench Verified: 87,6 %; Terminal-Bench: 69,4 %; GPQA Diamond: 94,2 %; FinanceBench: 82,7 % [ | Sehr stark belegt, aber in den verfügbaren Vergleichsdaten hinter GPT-5.5 und bei BrowseComp hinter DeepSeek V4 [ |
| DeepSeek V4 | Sehr stark bei BrowseComp [ | BrowseComp: 83,4 %; API-Preis: $1.74 pro 1 Mio. Input-Tokens und $3.48 pro 1 Mio. Output-Tokens [ | Nahe an GPT-5.5 bei BrowseComp und besser als Claude Opus 4.7 in diesem Benchmark, aber nicht klarer Gesamtsieger [ |
| Kimi K2.6 | Nur schwacher Rankinghinweis aus Reddit [ | Keine belastbaren Zahlenwerte in der bereitgestellten Evidenz [ | Insufficient evidence: Keine solide numerische Einordnung möglich [ |
Benchmark-für-Benchmark-Vergleich
Intelligence Index
-
GPT-5.5 liegt im verfügbaren Ausschnitt des „Intelligence Index“ auf Platz 1 mit 60 Punkten in der xhigh-Konfiguration und auf Platz 2 mit 59 Punkten in der high-Konfiguration [
6].
-
Claude Opus 4.7 liegt in der Konfiguration „Adaptive Reasoning, Max Effort“ bei 57 Punkten und wird damit hinter beiden GPT-5.5-Varianten genannt [
6].
-
Für DeepSeek V4 und Kimi K2.6 werden im verfügbaren Ausschnitt keine konkreten Intelligence-Index-Werte genannt [
6].
BrowseComp
-
GPT-5.5 erreicht bei BrowseComp 84,4 %, während GPT-5.5 Pro 90,1 % erreicht [
7].
-
DeepSeek V4 erreicht bei BrowseComp 83,4 % und liegt damit sehr knapp hinter GPT-5.5, aber deutlich hinter GPT-5.5 Pro [
7].
-
Claude Opus 4.7 erreicht bei BrowseComp 79,3 % und liegt damit hinter DeepSeek V4 und GPT-5.5 [
7].
-
Kimi K2.6 hat in der bereitgestellten Evidenz keinen BrowseComp-Wert [
7][
21].
Coding- und Software-Benchmarks
-
Claude Opus 4.7 wird mit 64,3 % auf SWE-bench Pro und 87,6 % auf SWE-bench Verified angegeben [
3].
-
Claude Opus 4.7 wird außerdem mit etwa 70 % auf CursorBench genannt, aber dieser Vergleich stammt aus einem Kontext zu GPT-5.4, nicht GPT-5.5 [
4].
-
Für GPT-5.5, DeepSeek V4 und Kimi K2.6 liegen in der bereitgestellten Evidenz keine direkt vergleichbaren SWE-bench-Pro- oder SWE-bench-Verified-Werte vor [
3][
4][
7][
21].
-
Ein Reddit-Beitrag behauptet, DeepSeek V4 sei im „Vibe Code Benchmark“ das führende Open-Weight-Modell und Kimi K2.6 liege dahinter auf Platz 2, aber dieser Beleg ist schwächer als die übrigen Quellen und enthält im Ausschnitt keine konkreten Prozentwerte [
21].
Reasoning- und Wissens-Benchmarks
-
Claude Opus 4.7 wird mit 94,2 % auf GPQA Diamond angegeben [
3].
-
Für GPT-5.5, DeepSeek V4 und Kimi K2.6 liegen in der bereitgestellten Evidenz keine direkt vergleichbaren GPQA-Diamond-Werte vor [
3][
6][
7][
21].
FinanceBench
-
Claude Opus 4.7 wird in einem verfügbaren Blogausschnitt mit 82,7 % auf FinanceBench erwähnt [
2].
-
Für GPT-5.5, DeepSeek V4 und Kimi K2.6 liegen in der bereitgestellten Evidenz keine FinanceBench-Werte vor [
2][
5][
7][
21].
Preis- und Kontextvergleich
-
DeepSeek V4 wird mit $1.74 pro 1 Million Input-Tokens und $3.48 pro 1 Million Output-Tokens bei einem Kontextfenster von 1 Million Tokens angegeben [
5].
-
GPT-5.5 wird mit $5 pro 1 Million Input-Tokens und $30 pro 1 Million Output-Tokens bei einem Kontextfenster von 1 Million Tokens angegeben [
5].
-
Für Claude Opus 4.7 ist im verfügbaren Ausschnitt nur der Beginn einer Preisangabe erkennbar, aber kein vollständiger Output-Preis, daher reicht die Evidenz für einen vollständigen Kostenvergleich nicht aus [
5].
-
Für Kimi K2.6 enthält die bereitgestellte Evidenz keinen Preiswert [
5][
21].
Verständliche Einordnung
-
Wenn man nur die verfügbaren Zahlen betrachtet, ist GPT-5.5 der sicherste Kandidat für die stärkste Gesamtleistung, weil es den genannten Intelligence Index anführt und bei BrowseComp vor DeepSeek V4 und Claude Opus 4.7 liegt [
6][
7].
-
DeepSeek V4 ist der stärkste Herausforderer in den verfügbaren Zahlen, weil es bei BrowseComp mit 83,4 % fast GPT-5.5 erreicht und Claude Opus 4.7 übertrifft [
7].
-
Claude Opus 4.7 ist am breitesten mit konkreten Einzelbenchmarks belegt, vor allem in SWE-bench, Terminal-Bench, GPQA Diamond und FinanceBench [
2][
3].
-
Kimi K2.6 kann anhand der bereitgestellten Evidenz nicht fair numerisch mit den anderen drei Modellen verglichen werden, weil die einzige konkrete Aussage nur ein schwacher Reddit-Rankinghinweis ohne Zahlenwerte ist [
21].
Evidence notes
-
Die stärksten quantitativen Vergleichsdaten in der bereitgestellten Evidenz sind der Intelligence-Index-Ausschnitt und der BrowseComp-Vergleich, weil sie mehrere der angefragten Modelle direkt nebeneinander nennen [
6][
7].
-
Die Claude-Opus-4.7-Werte zu SWE-bench Pro, SWE-bench Verified, Terminal-Bench und GPQA Diamond sind nützlich, aber sie erlauben keinen vollständigen Vier-Modell-Vergleich, weil entsprechende Werte für GPT-5.5, DeepSeek V4 und Kimi K2.6 in der Evidenz fehlen [
3].
-
Der Kimi-K2.6-Hinweis ist deutlich schwächer, weil er aus einem Reddit-Beitrag stammt und im verfügbaren Ausschnitt keine numerischen Ergebnisse enthält [
21].
-
Ein Vergleich mit GPT-5.4 ist nur indirekt relevant, weil die Nutzerfrage GPT-5.5 betrifft; die verfügbare Quelle nennt dort außerdem, dass Benchmarkwerte teils vendor-reported sind und unterschiedliche Harness-Konfigurationen nutzen [
4].
Limitations / uncertainty
-
Insufficient evidence: Für Kimi K2.6 fehlen belastbare Benchmarkzahlen in der bereitgestellten Evidenz [
21].
-
Insufficient evidence: Für GPT-5.5 fehlen in der bereitgestellten Evidenz konkrete Werte zu SWE-bench, GPQA Diamond, Terminal-Bench, FinanceBench und Vibe Code [
6][
7].
-
Insufficient evidence: Für DeepSeek V4 fehlen in der bereitgestellten Evidenz konkrete Werte zu SWE-bench, GPQA Diamond, Terminal-Bench und FinanceBench [
5][
7][
21].
-
Die Modelle werden teils in unterschiedlichen Varianten oder Testmodi genannt, etwa GPT-5.5 xhigh, GPT-5.5 high, Claude Opus 4.7 „Adaptive Reasoning, Max Effort“ und DeepSeek-V4-Pro-Max, wodurch ein 1:1-Vergleich nur eingeschränkt möglich ist [
6][
7].
-
Die bereitgestellte Evidenz enthält keine vollständigen offiziellen Modellkarten oder Primärquellen mit einheitlichem Benchmark-Setup für alle vier Modelle [
1][
3][
6][
7].
Summary
-
GPT-5.5: Beste belegte Gesamtposition, führt den Intelligence Index und liegt bei BrowseComp vor DeepSeek V4 und Claude Opus 4.7 [
6][
7].
-
DeepSeek V4: Sehr stark bei BrowseComp, knapp hinter GPT-5.5 und vor Claude Opus 4.7; außerdem deutlich günstiger als GPT-5.5 in der verfügbaren Preisangabe [
5][
7].
-
Claude Opus 4.7: Sehr gut dokumentiert mit vielen Einzelbenchmarks, aber in den direkt verfügbaren Vergleichszahlen hinter GPT-5.5 und bei BrowseComp hinter DeepSeek V4 [
2][
3][
6][
7].
-
Kimi K2.6: Nicht seriös numerisch bewertbar, weil die bereitgestellte Evidenz nur einen schwachen Rankinghinweis ohne konkrete Zahlen enthält [
21].
Die Leute fragen auch
Wie lautet die kurze Antwort auf „Recherchieren Sie die Benchmarks von Claude Opus 4.7, GPT-5.5, DeepSeek V4 und Kimi K2.6 und vergleichen Sie sie so umfassend wie möglich im Format eines Forschungsberichts, damit alle sie leicht verstehen können.“?
Auf Basis der vorliegenden Belege wirkt GPT-5.5 insgesamt am stärksten belegt: Es führt im genannten „Intelligence Index“ und liegt auch bei BrowseComp vor Claude Opus 4.7 und knapp vor DeepSeek V4 [6][7]. DeepSeek V4 ist besonders auffällig, weil es bei BrowseComp Claude Opus 4.7 schlägt und GPT-5.
Was sind die wichtigsten Punkte, die zuerst validiert werden müssen?
Auf Basis der vorliegenden Belege wirkt GPT-5.5 insgesamt am stärksten belegt: Es führt im genannten „Intelligence Index“ und liegt auch bei BrowseComp vor Claude Opus 4.7 und knapp vor DeepSeek V4 [6][7]. DeepSeek V4 ist besonders auffällig, weil es bei BrowseComp Claude Opus 4.7 schlägt und GPT-5. GPT-5.5 wird im verfügbaren Artificial-Analysis-Ausschnitt als Nummer 1 und 2 des „Intelligence Index“ geführt: GPT-5.5 „xhigh“ mit 60 Punkten und GPT-5.5 „high“ mit 59 Punkten.
Was soll ich als nächstes in der Praxis tun?
Claude Opus 4.7 wird im selben Ausschnitt mit „Adaptive Reasoning, Max Effort“ bei 57 Punkten genannt und damit hinter GPT-5.5 xhigh und GPT-5.5 high eingeordnet.
Welches verwandte Thema sollte ich als nächstes untersuchen?
Fahren Sie mit „Suche & Faktencheck: Wie schütze ich mich vor Fehlern, Missbrauch und Betrug durch KI?“ für einen anderen Blickwinkel und zusätzliche Zitate fort.
Zugehörige Seite öffnenWomit soll ich das vergleichen?
Vergleichen Sie diese Antwort mit „Suche & Faktencheck: Kann KI mir bei der Steuer helfen?“.
Zugehörige Seite öffnenSetzen Sie Ihre Recherche fort
Quellen
- [1] DeepSeek V4 is here: How it compares to ChatGPT, Claude, Geminimashable.com
Here's how the API pricing compares: DeepSeek V4 costs $1.74 per 1 million input tokens and $3.48 per 1 million output tokens (1 million context window) GPT-5.5 costs at $5 per 1 million input tokens and $30 per 1 million output tokens (1 million context wi...
- [2] DeepSeek V4 Pro (Reasoning, High Effort) vs Kimi K2.6artificialanalysis.ai
What are the top AI models? The top AI models by Intelligence Index are: 1. GPT-5.5 (xhigh) (60), 2. GPT-5.5 (high) (59), 3. Claude Opus 4.7 (Adaptive Reasoning, Max Effort) (57), 4. Gemini 3.1 Pro Preview (57), 5. GPT-5.4 (xhigh) (57). Which is the fastest...
- [3] DeepSeek-V4 arrives with near state-of-the-art intelligence at 1/6th ...venturebeat.com
BrowseComp is the standout: DeepSeek’s 83.4% beats Claude Opus 4.7’s 79.3% and nearly matches GPT-5.5’s 84.4%, though GPT-5.5 Pro’s 90.1% remains well ahead. So ultimately, DeepSeek-V4-Pro-Max does not appear to dethrone GPT-5.5 or Claude Opus 4.7 on the be...
- [4] GPT-5.5 vs Claude Opus 4.7: Pricing, Speed, Benchmarks - LLM Statsllm-stats.com
Vision: 3.75 MP vs Standard Opus 4.7 reads images at roughly 3.3× the resolution of any comparable model. Up to 2,576 pixels on the long edge ( 3.75 megapixels), versus 1,568 px ( 1.15 MP) on prior Claude models. Scores align: Opus 4.7 reports 91.0% on Char...
- [5] GPT-5.5 vs Claude Opus 4.7: Real-World Coding Performance ...mindstudio.ai
SWE-Bench and Coding Tasks On SWE-Bench Verified — the standard benchmark for evaluating real GitHub issue resolution — both models score competitively at the top of the 2026 leaderboard. GPT-5.5 holds a slight edge on problems requiring precise tool use an...
- [6] Introducing Claude Opus 4.7 - Anthropicanthropic.com
Image 7: logo Based on our internal research-agent benchmark, Claude Opus 4.7 has the strongest efficiency baseline we’ve seen for multi-step work. It tied for the top overall score across our six modules at 0.715 and delivered the most consistent long-cont...
- [7] Kimi K2.6 vs DeepSeek-V4 Pro - DocsBot AIdocsbot.ai
Kimi K2.6 Kimi K2.6 is Moonshot AI's latest open-source native multimodal agentic model, advancing long-horizon coding, coding-driven design, proactive autonomous execution, and swarm-based task orchestration. It keeps the Kimi K2.5 1T parameter MoE archite...
- [8] OpenAI's GPT-5.5 vs Claude Opus 4.7: Which is better? | Mashablemashable.com
Thanks for signing up! SWE-Bench Pro: GPT-5.5 scored 58.6; Opus 4.7 scored 64.3 percent Terminal-Bench 2.0: GPT-5.5 scored 82.7 percent; Opus 4.7 scored 69.4 percent Humanity's Last Exam: GPT-5.5 scored 40.6 percent; Opus 4.7 scored 31.2 percent\ Humanity's...
- [9] Deepseek v4 Performance Analysis: Does It Beat Kimi K2.6 and Qwen 3.6 Plus? - Geeky Gadgetsgeeky-gadgets.com
Deepseek v4 has officially undergone comprehensive testing, revealing both its potential and its limitations. Developed as an open source AI model, it is available in two versions: the high-performance Deepseek v4 Pro and the cost-efficient Deepseek v4 Flas...
- [10] I reviewed how DeepSeek V4-Pro, Kimi 2.6, Opus 4.6, and Opus 4.7 ...news.ycombinator.com
ozgune 1 day ago parent context favorite on: DeepSeek v4 I reviewed how DeepSeek V4-Pro, Kimi 2.6, Opus 4.6, and Opus 4.7 across the same AI benchmarks. All results are for Max editions, except for Kimi. Summary: Opus 4.6 forms the baseline all three are tr...
- [11] GPT 5.5 Vs Claude Opus 4.7 Proves Benchmarks Need Contextreddit.com
That difference matters because most people use AI too broadly. They ask one model to do every task, then get annoyed when it performs unevenly. A better approach is to treat each model like a different role inside your workflow. GPT 5.5 can be the operator...
- [12] I Tested GPT 5.5 vs Opus 4.7: What You Need to Know OpenAI just ...linkedin.com
I Tested GPT 5.5 vs Opus 4.7: What You Need to Know OpenAI just dropped GPT 5.5. The benchmarks look strong against Opus 4.7. But benchmarks only tell part of the story. So I ran 4 head-to-head experiments. Codex on GPT 5.5. Claude Code on Opus 4.7. Same pr...
- [13] Documentation - Claude API Docsplatform.claude.com
Cookie settings We use cookies to deliver and improve our services, analyze site usage, and if you agree, to customize or personalize your experience and market our services to you. You can read our Cookie Policy here. Solutions Partners Learn Company Learn...
- [14] The Coding Assistant Breakdown: More Tokens Please - SemiAnalysisnewsletter.semianalysis.com
On benchmarks, DeepSeek did not feel that standard benchmarks were good at capturing real-world task capability, so they introduced their own set of agentic benchmarks to measure how V4 compared against other SOTA models: Chinese writing, retrieval augmente...
- [15] "DeepSeek v4 is now the #1 open-weight model on our Vibe Code ...reddit.com
"DeepSeek v4 is now the 1 open-weight model on our Vibe Code Benchmark, and it’s not close. It leaves the 2 (Kimi K2.6) in the dust, and even beats out frontier closed source models like Gemini 3.1 Pro." : r/accelerate Skip to main content"DeepSeek v4 is no...
- [16] AI Week in Review 26.04.25 - by Patrick McGuinnesspatmcguinness.substack.com
Also impressively, GPT-5.5 achieves high-level performance with significantly fewer output tokens than GPT-5.4, somewhat making up for its higher per-token cost. GPT-5.5 comes with a 1 million-token context window and advanced compaction for long-horizon ta...
- [17] Bad Opus 4.7, Good Kimi K2.6, and Growing Codexaicodingdaily.substack.com
Simon Willison on X: “Opus 4.7 appears to use 1.46x times the tokens for text and up to 3x the tokens for images than Opus 4.6” x.com I upgraded my Claude token counter tool to compare different models and Opus 4.7 does appear to use 1.46x times the tokens...
- [18] GPT 5.5 beats Claude Opus 4.7 : r/ArtificialInteligence - Redditreddit.com
Anyone can view, post, and comment to this community 0 0 Reddit RulesPrivacy PolicyUser AgreementYour Privacy ChoicesAccessibilityReddit, Inc. © 2026. All rights reserved. Expand Navigation Collapse Navigation RESOURCES About Reddit Adv...
- [19] Claude Opus 4.7 Benchmark Breakdown: Vision, Coding, ...mindstudio.ai
This matters for teams evaluating Opus 4.7 for production use because the model’s capability gains are only useful if they’re integrated into something that works end-to-end. The gap between “this model scores 82.7% on FinanceBench” and “we have a deployed...
- [20] Claude Opus 4.7 Benchmarks Explained - Vellumvellum.ai
Is Claude Opus 4.7 the most powerful Claude model? No. Claude Mythos Preview is Anthropic's most capable model and leads Opus 4.7 on most benchmarks in the comparison table, including SWE-bench Pro (77.8% vs 64.3%), SWE-bench Verified (93.9% vs 87.6%), Term...
- [21] Claude Opus 4.7 vs. GPT-5.4: Which Frontier Model Should You Use?datacamp.com
--- --- Benchmark Claude Opus 4.7 GPT-5.4 Notes SWE-bench Pro 64.3% 57.7% Vendor-reported; different harness configurations SWE-bench Verified 87.6% Not published OpenAI has not released an official score on this variant CursorBench 70% Not published Cursor...
- [22] Everything You Need to Know About GPT-5.5 - Vellumvellum.ai
Benchmark GPT-5.5 GPT-5.5 Pro GPT-5.4 Claude Opus 4.7 Gemini 3.1 Pro --- --- --- Terminal-Bench 2.0 82.7% — 75.1% 69.4% 68.5% SWE-Bench Pro 58.6% — 57.7% 64.3% 54.2% Expert-SWE (Internal) 73.1% — 68.5% — — GDPval 84.9% 82.3% 83.0% 80.3% 67.3% OSWorld-Verifi...
- [23] GPT-5.5: The Honest Take on OpenAI's Response to Opus ...alexlavaee.me
OpenAI released GPT-5.5 today, exactly one week after Anthropic shipped Claude Opus 4.7( ref-5). The timing is not subtle. Opus 4.7 took the SWE-Bench Verified crown at 87.6% and put Anthropic at the top of most third-party coding leaderboards; GPT-5.5 is t...
- [24] Introducing GPT-5.5 - OpenAIopenai.com
Evaluations Coding EvalGPT-5.5GPT‑5.4GPT-5.5 ProGPT‑5.4 ProClaude Opus 4.7Gemini 3.1 Pro SWE-Bench Pro (Public) 58.6%57.7%--64.3%54.2% Terminal-Bench 2.0 82.7%75.1%--69.4%68.5% Expert-SWE (Internal)73.1%68.5%---- Labs have noted evidence of memorization(op...
- [25] OpenAI's GPT-5.5 masters agentic coding with 82.7% benchmark ...interestingengineering.com
About UsAdvertise ContactFAQ Follow Us On LinkedInXInstagramFlipboardFacebookYouTubeTikTok All Rights Reserved, IE Media, Inc. AI and Robotics GPT-5.5 crushes Claude Opus 4.7 in agentic coding with 82.7% terminal-bench score GPT-5.5 introduces smarter task...
- [26] Mythos 5.5 SWE-bench Pro 77.8%* 58.6% Terminal ... - Hacker Newsnews.ycombinator.com
6thbit 1 day ago parent context favorite on: GPT-5.5 Still far from Mythos on SWE-bench but quite comparable otherwise. Source for mythos values: --- aliljet 1 day ago next (javascript:void(0)) Mythos is only real when it's actually available. If you're usi...