ศึกษาค้นคว้าเกณฑ์มาตรฐานการทดสอบของ GPT-5.5, Claude Opus 4.7, DeepSeek V4 และ Kimi K2.6 แล้วเปรียบเทียบให้ครอบคลุมมากที่สุดเท่าที่เป็นไปได้ จัดทำรายงานการวิจัยเกี่ยวกับเรื่องนี้
รายงานนี้พบว่า “มีข้อมูลเปรียบเทียบได้บางส่วน แต่ยังไม่ครบแบบ apples to apples” สำหรับ GPT 5.5, Claude Opus 4.7, DeepSeek V4 และ Kimi K2.6 โดย GPT 5.5 มีข้อมูลคะแนนสาธารณะมากที่สุดในชุดที่ค้นพบ, Claude Opus 4.7 เด่นกว...
รายงานนี้พบว่า “มีข้อมูลเปรียบเทียบได้บางส่วน แต่ยังไม่ครบแบบ apples to apples” สำหรับ GPT 5.5, Claude Opus 4.7, DeepSeek V4 และ Kimi K2.6 โดย GPT 5.5 มีข้อมูลคะแนนสาธารณะมากที่สุดในชุดที่ค้นพบ, Claude Opus 4.7 เด่นกว่า GPT 5.5 ใน SWE Bench Pro ตามแหล่งเปรียบเทียบภายนอก, DeepSeek V4 เด่นเรื่องบริบทยาวระดับ 1,000k token
ประเด็นสำคัญ
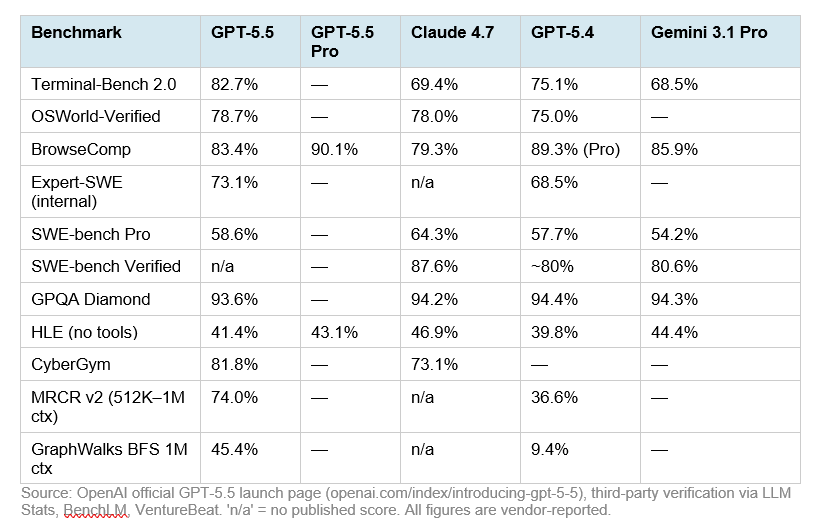
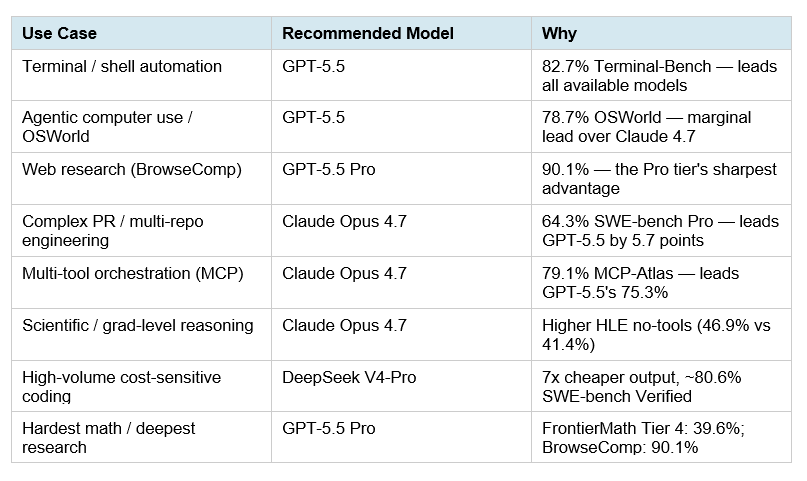
- ข้อมูลที่เทียบได้ตรงที่สุดระหว่าง GPT-5.5 กับ Claude Opus 4.7 คือ Terminal-Bench 2.0, SWE-Bench Pro และ GDPval จากแหล่งวิเคราะห์ภายนอกเดียวกัน
- GPT-5.5 ได้ 82.7% บน Terminal-Bench 2.0 เทียบกับ Claude Opus 4.7 ที่ 69.4% ทำให้ GPT-5.5 นำในงาน terminal/agentic workflow ตามข้อมูลชุดนี้
- Claude Opus 4.7 ได้ 64.3% บน SWE-Bench Pro เทียบกับ GPT-5.5 ที่ 58.6% ทำให้ Claude นำใน benchmark งานแก้ปัญหา software engineering ตามข้อมูลชุดนี้
- GPT-5.5 ได้ 84.9% บน GDPval เทียบกับ Claude Opus 4.7 ที่ 80.3% ทำให้ GPT-5.5 นำใน benchmark งานเชิงเศรษฐกิจ/งานมืออาชีพตามข้อมูลชุดนี้
- รายงานนี้พบว่า “มีข้อมูลเปรียบเทียบได้บางส่วน แต่ยังไม่ครบแบบ apples-to-apples” สำหรับ GPT-5.5, Claude Opus 4.7, DeepSeek V4 และ Kimi K2.6 โดย GPT-5.5 มีข้อมูลคะแนนสาธารณะมากที่สุดในชุดที่ค้นพบ, Claude Opus 4.7 เด่นกว่า GPT-5.5 ใน SWE-Bench Pro ตามแหล่งเปรียบเทียบภายนอก, DeepSeek
- ## Key findings
คำตอบการวิจัย
รายงานนี้พบว่า “มีข้อมูลเปรียบเทียบได้บางส่วน แต่ยังไม่ครบแบบ apples-to-apples” สำหรับ GPT-5.5, Claude Opus 4.7, DeepSeek V4 และ Kimi K2.6 โดย GPT-5.5 มีข้อมูลคะแนนสาธารณะมากที่สุดในชุดที่ค้นพบ, Claude Opus 4.7 เด่นกว่า GPT-5.5 ใน SWE-Bench Pro ตามแหล่งเปรียบเทียบภายนอก, DeepSeek V4 เด่นเรื่องบริบทยาวระดับ 1,000k tokens แต่มีสัญญาณความเสี่ยงด้าน hallucination ในการทดสอบของ Artificial Analysis, ส่วน Kimi K2.6 มีหลักฐานเปรียบเทียบที่พบจำกัด โดยยืนยันได้หลัก ๆ เรื่องบริบท 256k tokens จากแหล่งเปรียบเทียบภายนอก [11][
7][
9]
Key findings
-
ข้อมูลที่เทียบได้ตรงที่สุดระหว่าง GPT-5.5 กับ Claude Opus 4.7 คือ Terminal-Bench 2.0, SWE-Bench Pro และ GDPval จากแหล่งวิเคราะห์ภายนอกเดียวกัน [
11]
-
GPT-5.5 ได้ 82.7% บน Terminal-Bench 2.0 เทียบกับ Claude Opus 4.7 ที่ 69.4% ทำให้ GPT-5.5 นำในงาน terminal/agentic workflow ตามข้อมูลชุดนี้ [
11]
-
Claude Opus 4.7 ได้ 64.3% บน SWE-Bench Pro เทียบกับ GPT-5.5 ที่ 58.6% ทำให้ Claude นำใน benchmark งานแก้ปัญหา software engineering ตามข้อมูลชุดนี้ [
11]
-
GPT-5.5 ได้ 84.9% บน GDPval เทียบกับ Claude Opus 4.7 ที่ 80.3% ทำให้ GPT-5.5 นำใน benchmark งานเชิงเศรษฐกิจ/งานมืออาชีพตามข้อมูลชุดนี้ [
11]
-
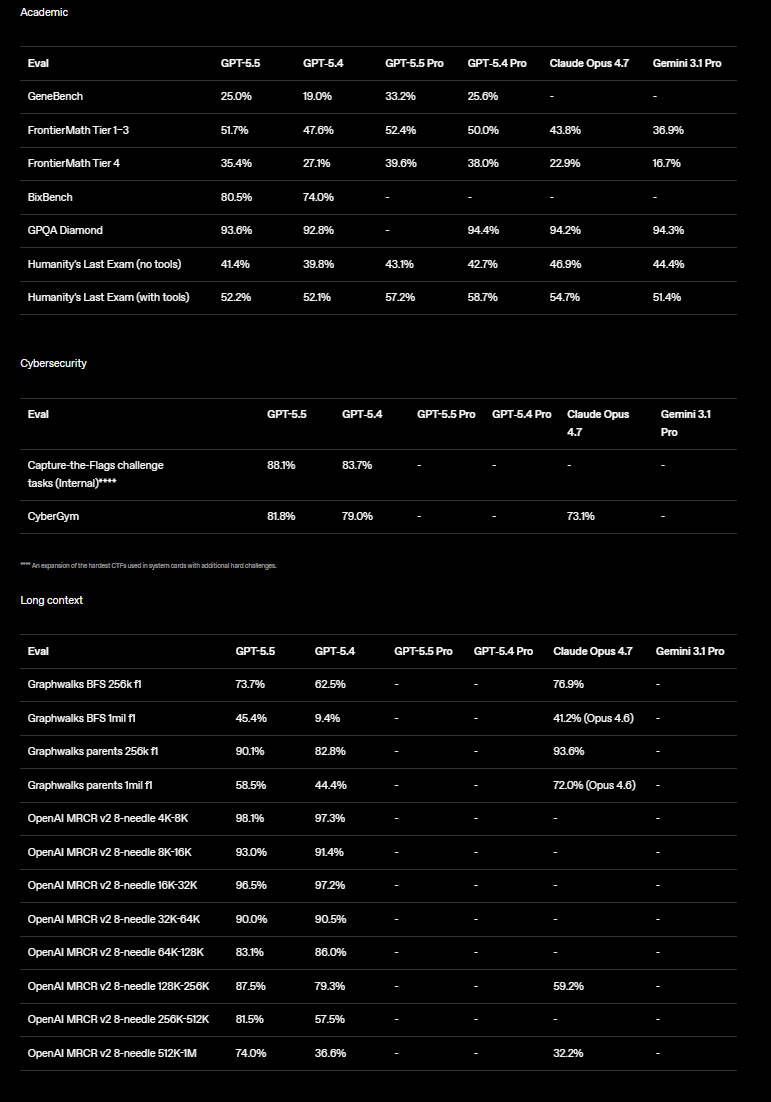
OpenAI มีเอกสาร safety/evaluation สำหรับ GPT-5.5 ที่กล่าวถึง CoT-Control ซึ่งใช้ชุดงานมากกว่า 13,000 งานจาก benchmark ที่มีอยู่ เช่น GPQA และ MMLU-Pro [
14]
-
Anthropic มีบันทึกเอกสาร API ที่ระบุ Claude Opus 4.7 วันที่ 16 เมษายน 2026 แต่ข้อมูลคะแนน benchmark อย่างเป็นทางการที่พบในชุดผลค้นหานี้ยังไม่ครบเท่าข้อมูลของ GPT-5.5 [
2]
-
DeepSeek V4 series ถูกอธิบายในเอกสารเทคนิคว่าเป็นการต่อยอดจาก DeepSeek-V3 โดยยังคง DeepSeekMoE และ Multi-Token Prediction พร้อมเพิ่มกลไกด้านประสิทธิภาพสำหรับ long context [
6]
-
DeepSeek V4 Pro ถูกระบุในแหล่งเปรียบเทียบว่าใช้ context window 1,000k tokens ส่วน Kimi K2.6 ใช้ context window 256k tokens [
9]
-
Artificial Analysis รายงานว่า DeepSeek V4 Pro Max ทำคะแนน AA-Omniscience ที่ -10 ดีขึ้น 11 จุดจาก V3.2 แต่มี hallucination rate สูงถึง 94% ในชุดทดสอบนั้น [
7]
-
หลักฐานสาธารณะที่พบยังไม่เพียงพอสำหรับการสรุปตารางคะแนน benchmark ครบทุกหมวดของทั้ง 4 รุ่นพร้อมกัน; ดังนั้นจุดที่ไม่มีตัวเลขควรถือว่า “Insufficient evidence.”
ขอบเขตและวิธีวิจัย
-
รายงานนี้ใช้หลักฐานจากเอกสารทางการ, เอกสารเทคนิค, แหล่ง benchmark ภายนอก และแหล่งวิชาการที่พบในผลค้นหา ณ วันที่ทำรายงาน [
2][
6][
11][
14][
1]
-
แหล่งที่มีน้ำหนักสูงกว่าในรายงานนี้คือเอกสารทางการหรือเอกสารเทคนิค เช่น release notes ของ Anthropic, เอกสาร safety/evaluation ของ OpenAI และ PDF ทางเทคนิคของ DeepSeek V4 [
2][
14][
6]
-
แหล่งที่ใช้สำหรับคะแนนเปรียบเทียบหลายรุ่นพร้อมกันส่วนใหญ่เป็นแหล่งภายนอก เช่น Vellum, BenchLM, LLM Stats และ Artificial Analysis จึงควรตีความเป็น benchmark จากผู้ประเมินรายนั้น ไม่ใช่ผลรับรองกลางทั้งหมด [
11][
12][
15][
7]
-
งานวิชาการด้าน benchmark การเขียนโค้ดชี้ว่าชุดทดสอบอย่าง HumanEval มีข้อจำกัด และมีความพยายามสร้าง benchmark ที่ใกล้งานจริงมากขึ้น เช่น SWE-Bench และ benchmark fine-grained issue solving [
1]
ภาพรวม benchmark ที่ควรใช้เทียบ
| หมวดทดสอบ | ตัวอย่าง benchmark ที่พบ | ใช้วัดอะไร | หมายเหตุด้านความน่าเชื่อถือ |
|---|---|---|---|
| Reasoning / knowledge | GPQA, MMLU-Pro, ARC-AGI, LongBench v2, MuSR | ความรู้เชิงลึก การให้เหตุผล และการแก้ปัญหาซับซ้อน | OpenAI ระบุว่า CoT-Control ของ GPT-5.5 ใช้ชุดงานจาก GPQA และ MMLU-Pro ร่วมกับ benchmark อื่น ๆ มากกว่า 13,000 งาน [ |
| Coding / software engineering | SWE-Bench Pro, SWE-Bench Verified, LiveCodeBench, Expert-SWE | ความสามารถแก้ issue, เขียน/แก้โค้ด และทำงานวิศวกรรมซอฟต์แวร์ | งานวิชาการระบุว่า benchmark แบบ HumanEval ไม่พอสำหรับงานจริง จึงต้องใช้ benchmark ที่ใกล้ issue จริงมากขึ้น [ |
| Agentic / tool use | Terminal-Bench 2.0, BrowseComp, OSWorld-Verified, GAIA, TAU-bench, WebArena | การใช้เครื่องมือ, terminal, browser, workflow หลายขั้นตอน | BenchLM จัด GPT-5.5 ในหมวด agentic ด้วยชุด benchmark อย่าง Terminal-Bench 2.0, BrowseComp, OSWorld-Verified, GAIA, TAU-bench และ WebArena [ |
| Vision / multimodal | MMMU Pro, image/video input tests | ความเข้าใจภาพ วิดีโอ และเอกสารหลายรูปแบบ | ข้อมูลที่พบสำหรับทั้ง 4 รุ่นยังไม่พอสำหรับสรุปเชิงตัวเลขครบทุกโมเดล; Insufficient evidence. |
| Long context | LongBench v2, MRCRv2, context-window tests | การคงบริบทและดึงข้อมูลจากเอกสารยาว | DeepSeek V4 Pro ถูกระบุว่ามี context window 1,000k tokens และ Kimi K2.6 256k tokens ในแหล่งเปรียบเทียบเดียวกัน [ |
| Safety / reliability | CoT-Control, Petri, hallucination tests, AA-Omniscience | การควบคุมพฤติกรรม, eval-awareness, hallucination, ความน่าเชื่อถือ | OpenAI ใช้ CoT-Control กับงานมากกว่า 13,000 งาน ส่วน Anthropic รายงาน Petri 2.0 และ Artificial Analysis รายงาน hallucination rate ของ DeepSeek V4 Pro Max [ |
ตารางเปรียบเทียบคะแนนที่พบ
| Benchmark / metric | GPT-5.5 | Claude Opus 4.7 | DeepSeek V4 | Kimi K2.6 | ข้อสรุปจากหลักฐาน |
|---|---|---|---|---|---|
| Terminal-Bench 2.0 | 82.7% | 69.4% | Insufficient evidence | Insufficient evidence | GPT-5.5 นำ Claude Opus 4.7 ชัดเจนในงาน terminal/agentic ตามแหล่งนี้ [ |
| SWE-Bench Pro | 58.6% | 64.3% | Insufficient evidence | Insufficient evidence | Claude Opus 4.7 นำ GPT-5.5 ในงาน software engineering ตามแหล่งนี้ [ |
| Expert-SWE internal | 73.1% | Insufficient evidence | Insufficient evidence | Insufficient evidence | ใช้ได้เป็นสัญญาณภายในของ GPT-5.5 แต่ไม่เหมาะสรุปเทียบทุกค่ายเพราะไม่มีคะแนนครบ [ |
| GDPval | 84.9% | 80.3% | Insufficient evidence | Insufficient evidence | GPT-5.5 นำ Claude Opus 4.7 ใน benchmark งานมืออาชีพตามแหล่งนี้ [ |
| BenchLM aggregate: Agentic | #2 / 99.5 จาก 100 | Insufficient evidence | Insufficient evidence | Insufficient evidence | ใช้ดูอันดับรวมของ GPT-5.5 ได้ แต่ยังไม่ใช่ตารางเดียวกันครบ 4 โมเดล [ |
| BenchLM aggregate: Coding | 85.6 จาก 100 | Insufficient evidence | Insufficient evidence | Insufficient evidence | GPT-5.5 ถูกจัดอันดับสูงใน coding aggregate แต่ไม่มีคะแนนคู่เทียบครบในแหล่งเดียวกัน [ |
| BenchLM aggregate: Reasoning | 100.0 จาก 100 | Insufficient evidence | Insufficient evidence | Insufficient evidence | GPT-5.5 ถูกจัดอันดับสูงสุดใน reasoning aggregate ของ BenchLM แต่ยังไม่ใช่ผลเปรียบเทียบครบ 4 รุ่น [ |
| Context window | Insufficient evidence | Insufficient evidence | 1,000k tokens | 256k tokens | DeepSeek V4 Pro เหนือ Kimi K2.6 ด้าน context window ตามแหล่งเปรียบเทียบนี้ [ |
| AA-Omniscience | Insufficient evidence | Insufficient evidence | -10 สำหรับ V4 Pro Max | Insufficient evidence | DeepSeek V4 Pro Max ดีขึ้นจาก V3.2 แต่ยังมี hallucination rate สูงมากในรายงานเดียวกัน [ |
| Hallucination rate | Insufficient evidence | Insufficient evidence | 94% สำหรับ V4 Pro/Flash | Insufficient evidence | เป็นสัญญาณความเสี่ยงสำคัญของ DeepSeek V4 ในชุดทดสอบของ Artificial Analysis [ |
วิเคราะห์รายโมเดล
GPT-5.5
-
GPT-5.5 เป็นโมเดลที่มีข้อมูลคะแนนสาธารณะมากที่สุดในชุดหลักฐานที่พบ โดยมีคะแนน Terminal-Bench 2.0, SWE-Bench Pro, Expert-SWE และ GDPval จากแหล่งเปรียบเทียบภายนอก [
11]
-
จุดแข็งหลักของ GPT-5.5 คือ agentic workflow และงานมืออาชีพ โดยได้ 82.7% บน Terminal-Bench 2.0 และ 84.9% บน GDPval [
11]
-
จุดที่ยังไม่ชนะทุกหมวดคือ software engineering benchmark แบบ SWE-Bench Pro เพราะ GPT-5.5 ได้ 58.6% ต่ำกว่า Claude Opus 4.7 ที่ 64.3% [
11]
-
เอกสาร safety/evaluation ของ OpenAI สำหรับ GPT-5.5 ระบุการใช้ CoT-Control กับงานมากกว่า 13,000 งานจาก benchmark เช่น GPQA และ MMLU-Pro ซึ่งทำให้ข้อมูลด้านการควบคุมพฤติกรรมมีฐานเอกสารทางการมากกว่าโมเดลอื่นในชุดนี้ [
14]
Claude Opus 4.7
-
Claude Opus 4.7 ปรากฏในเอกสาร release notes ของ Anthropic วันที่ 16 เมษายน 2026 ซึ่งช่วยยืนยันสถานะโมเดลในเอกสารทางการ [
2]
-
จุดแข็งที่เด่นที่สุดจากข้อมูลที่พบคือ coding/software engineering เพราะ Claude Opus 4.7 ได้ 64.3% บน SWE-Bench Pro เทียบกับ GPT-5.5 ที่ 58.6% [
11]
-
Claude Opus 4.7 ตามข้อมูลเดียวกันได้ 69.4% บน Terminal-Bench 2.0 และ 80.3% บน GDPval ซึ่งตามหลัง GPT-5.5 ในสองหมวดนี้ [
11]
-
Anthropic มีงานประเมินด้าน safety/eval-awareness ผ่าน Petri 2.0 โดยรายงานว่าการแทรกแซงสองแนวทางร่วมกันทำให้ eval-awareness ลดลงแบบ median relative drop 47.3% ในโมเดล Claude [
4]
DeepSeek V4
-
เอกสาร DeepSeek-V4 ระบุว่า V4 series ยังคง DeepSeekMoE framework และ Multi-Token Prediction strategy จาก DeepSeek-V3 พร้อมเพิ่มนวัตกรรมด้านสถาปัตยกรรมและการปรับประสิทธิภาพ [
6]
-
DeepSeek V4 Pro ถูกระบุในแหล่งเปรียบเทียบว่ามี context window 1,000k tokens ซึ่งสูงกว่า Kimi K2.6 ที่ 256k tokens อย่างมีนัยสำคัญ [
9]
-
Artificial Analysis รายงานว่า DeepSeek V4 Pro Max ได้ AA-Omniscience -10 ซึ่งดีขึ้น 11 จุดจาก DeepSeek V3.2 Reasoning ที่ -21 [
7]
-
ประเด็นเสี่ยงสำคัญคือ Artificial Analysis รายงาน hallucination rate 94% สำหรับ DeepSeek V4 Pro และ V4 Flash ในชุดประเมินของตน [
7]
-
ยังไม่มีหลักฐานเพียงพอในชุดผลค้นหานี้สำหรับการเปรียบเทียบ DeepSeek V4 กับ GPT-5.5 และ Claude Opus 4.7 บน Terminal-Bench 2.0, SWE-Bench Pro หรือ GDPval; Insufficient evidence.
Kimi K2.6
-
หลักฐานเปรียบเทียบที่พบสำหรับ Kimi K2.6 จำกัดกว่ารุ่นอื่น โดยแหล่งที่พบยืนยันได้ว่า Kimi K2.6 มี context window 256k tokens ในตารางเปรียบเทียบกับ DeepSeek V4 Pro [
9]
-
เมื่อเทียบเฉพาะ context window, Kimi K2.6 ต่ำกว่า DeepSeek V4 Pro ที่ 1,000k tokens ตามแหล่งเปรียบเทียบเดียวกัน [
9]
-
ยังไม่มีหลักฐานเพียงพอในชุดผลค้นหานี้สำหรับคะแนน Kimi K2.6 บน Terminal-Bench 2.0, SWE-Bench Pro, GPQA, MMLU-Pro, GDPval หรือ hallucination benchmark แบบเดียวกับ DeepSeek V4; Insufficient evidence.
เปรียบเทียบตามกรณีใช้งาน
-
หากเน้น terminal, agentic workflow และงานหลายขั้นตอน GPT-5.5 เป็นตัวเลือกที่มีหลักฐานคะแนนนำ Claude Opus 4.7 ชัดเจนจาก Terminal-Bench 2.0 ที่ 82.7% เทียบกับ 69.4% [
11]
-
หากเน้นแก้ปัญหา software engineering จาก issue จริง Claude Opus 4.7 น่าพิจารณากว่า GPT-5.5 เพราะได้ SWE-Bench Pro 64.3% เทียบกับ 58.6% [
11]
-
หากเน้นงานมืออาชีพหรือ benchmark แนว GDPval GPT-5.5 มีคะแนน 84.9% สูงกว่า Claude Opus 4.7 ที่ 80.3% [
11]
-
หากเน้น long-context retrieval หรือเอกสารยาวมาก DeepSeek V4 Pro มีจุดเด่นจาก context window 1,000k tokens เทียบกับ Kimi K2.6 ที่ 256k tokens แต่ยังไม่มีข้อมูลครบสำหรับเทียบกับ GPT-5.5 และ Claude Opus 4.7 ในแหล่งเดียวกัน [
9]
-
หากเน้นความน่าเชื่อถือและลด hallucination ควรระวัง DeepSeek V4 เพราะรายงานของ Artificial Analysis ระบุ hallucination rate 94% ในชุดทดสอบของตน [
7]
-
หากต้องการเลือก Kimi K2.6 สำหรับงาน production ควรขอหรือรอ benchmark เพิ่มเติมจากแหล่งทางการหรือผู้ประเมินภายนอกที่ใช้ harness เดียวกับ GPT-5.5, Claude Opus 4.7 และ DeepSeek V4; Insufficient evidence.
Evidence notes
-
แหล่งทางการที่พบสำหรับ GPT-5.5 มีน้ำหนักสูงในส่วน safety/evaluation แต่คะแนนเปรียบเทียบเชิงประสิทธิภาพที่ครบกว่าในรายงานนี้มาจากแหล่งภายนอก [
14][
11]
-
แหล่งทางการของ Anthropic ที่พบยืนยันการมีอยู่ของ Claude Opus 4.7 ใน release notes แต่คะแนนเปรียบเทียบที่ใช้ในตารางมาจากแหล่งภายนอก [
2][
11]
-
แหล่ง DeepSeek V4 ที่มีน้ำหนักสูงสุดคือ PDF เทคนิคบน Hugging Face ของ deepseek-ai ซึ่งอธิบายสถาปัตยกรรมและ long-context direction แต่ไม่ให้ตารางเปรียบเทียบครบทุก benchmark ที่ต้องการในผลค้นหาที่พบ [
6]
-
แหล่งสำหรับ Kimi K2.6 ที่ใช้ได้ในรายงานนี้เป็นแหล่งเปรียบเทียบภายนอก ไม่ใช่เอกสาร benchmark ทางการของ Moonshot/Kimi ในผลค้นหาที่พบ [
9]
-
งานวิชาการสนับสนุนข้อควรระวังว่าการวัด coding capability ต้องใช้ benchmark ที่ใกล้งานจริงกว่า HumanEval และควรพิจารณา benchmark ประเภท SWE-Bench หรือ issue-solving ร่วมด้วย [
1]
Limitations / uncertainty
-
Insufficient evidence สำหรับตารางคะแนนครบทุก benchmark ของทั้ง 4 รุ่นใน harness เดียวกัน
-
คะแนนจากแหล่งต่างกันอาจใช้ prompt, sampling, tool access, reasoning mode, compute budget และ scoring pipeline ต่างกัน จึงไม่ควรนำตัวเลขจากคนละแหล่งมารวมเป็นอันดับเด็ดขาด
-
ข้อมูล DeepSeek V4 และ Kimi K2.6 ในรายงานนี้ยังไม่ครบด้าน coding, reasoning, multimodal, safety และ cost-performance เมื่อเทียบกับข้อมูล GPT-5.5 และ Claude Opus 4.7
-
ผล benchmark ของโมเดลรุ่น frontier เปลี่ยนเร็วมาก และควรตรวจซ้ำกับ model card, system card, technical report และ leaderboard ที่อัปเดตล่าสุดก่อนตัดสินใจใช้งานจริง
Summary
-
GPT-5.5 มีหลักฐานแข็งที่สุดในชุดนี้ด้าน agentic workflow และ GDPval โดยนำ Claude Opus 4.7 บน Terminal-Bench 2.0 และ GDPval [
11]
-
Claude Opus 4.7 เด่นกว่า GPT-5.5 ใน SWE-Bench Pro ซึ่งเป็นสัญญาณสำคัญสำหรับงาน software engineering [
11]
-
DeepSeek V4 Pro เด่นด้าน context window 1,000k tokens และมีเอกสารเทคนิคสนับสนุนเรื่อง long-context architecture แต่มีข้อกังวลจาก hallucination rate สูงในรายงาน Artificial Analysis [
6][
9][
7]
-
Kimi K2.6 ยังมีข้อมูลสาธารณะในชุดหลักฐานนี้น้อยที่สุด โดยยืนยันได้หลัก ๆ ว่ามี context window 256k tokens ในแหล่งเปรียบเทียบกับ DeepSeek V4 Pro [
9]
-
ข้อสรุปเชิงวิจัยคือ GPT-5.5 เหมาะกับ agentic/general professional work, Claude Opus 4.7 เหมาะกับ software engineering, DeepSeek V4 เหมาะกับงาน long-context ที่ยอมรับความเสี่ยงด้าน hallucination ได้, และ Kimi K2.6 ยังต้องการหลักฐาน benchmark เพิ่มเติมก่อนสรุปเชิง production ได้อย่างมั่นใจ.
สนับสนุนภาพ











การสนทนาการวิจัย
คำถามวิจัย
ศึกษาค้นคว้าเกณฑ์มาตรฐานการทดสอบของ GPT-5.5, Claude Opus 4.7, DeepSeek V4 และ Kimi K2.6 แล้วเปรียบเทียบให้ครอบคลุมมากที่สุดเท่าที่เป็นไปได้ จัดทำรายงานการวิจัยเกี่ยวกับเรื่องนี้
อ้างถึงคำตอบ
รายงานนี้พบว่า “มีข้อมูลเปรียบเทียบได้บางส่วน แต่ยังไม่ครบแบบ apples-to-apples” สำหรับ GPT-5.5, Claude Opus 4.7, DeepSeek V4 และ Kimi K2.6 โดย GPT-5.5 มีข้อมูลคะแนนสาธารณะมากที่สุดในชุดที่ค้นพบ, Claude Opus 4.7 เด่นกว่า GPT-5.5 ใน SWE-Bench Pro ตามแหล่งเปรียบเทียบภายนอก, DeepSeek V4 เด่นเรื่องบริบทยาวระดับ 1,000k tokens แต่มีสัญญาณความเสี่ยงด้าน hallucination ในการทดสอบของ Artificial Analysis, ส่วน Kimi K2.6 มีหลักฐานเปรียบเทียบที่พบจำกัด โดยยืนยันได้หลัก ๆ เรื่องบริบท 256k tokens จากแหล่งเปรียบเทียบภายนอก [11][
7][
9]
Key findings
-
ข้อมูลที่เทียบได้ตรงที่สุดระหว่าง GPT-5.5 กับ Claude Opus 4.7 คือ Terminal-Bench 2.0, SWE-Bench Pro และ GDPval จากแหล่งวิเคราะห์ภายนอกเดียวกัน [
11]
-
GPT-5.5 ได้ 82.7% บน Terminal-Bench 2.0 เทียบกับ Claude Opus 4.7 ที่ 69.4% ทำให้ GPT-5.5 นำในงาน terminal/agentic workflow ตามข้อมูลชุดนี้ [
11]
-
Claude Opus 4.7 ได้ 64.3% บน SWE-Bench Pro เทียบกับ GPT-5.5 ที่ 58.6% ทำให้ Claude นำใน benchmark งานแก้ปัญหา software engineering ตามข้อมูลชุดนี้ [
11]
-
GPT-5.5 ได้ 84.9% บน GDPval เทียบกับ Claude Opus 4.7 ที่ 80.3% ทำให้ GPT-5.5 นำใน benchmark งานเชิงเศรษฐกิจ/งานมืออาชีพตามข้อมูลชุดนี้ [
11]
-
OpenAI มีเอกสาร safety/evaluation สำหรับ GPT-5.5 ที่กล่าวถึง CoT-Control ซึ่งใช้ชุดงานมากกว่า 13,000 งานจาก benchmark ที่มีอยู่ เช่น GPQA และ MMLU-Pro [
14]
-
Anthropic มีบันทึกเอกสาร API ที่ระบุ Claude Opus 4.7 วันที่ 16 เมษายน 2026 แต่ข้อมูลคะแนน benchmark อย่างเป็นทางการที่พบในชุดผลค้นหานี้ยังไม่ครบเท่าข้อมูลของ GPT-5.5 [
2]
-
DeepSeek V4 series ถูกอธิบายในเอกสารเทคนิคว่าเป็นการต่อยอดจาก DeepSeek-V3 โดยยังคง DeepSeekMoE และ Multi-Token Prediction พร้อมเพิ่มกลไกด้านประสิทธิภาพสำหรับ long context [
6]
-
DeepSeek V4 Pro ถูกระบุในแหล่งเปรียบเทียบว่าใช้ context window 1,000k tokens ส่วน Kimi K2.6 ใช้ context window 256k tokens [
9]
-
Artificial Analysis รายงานว่า DeepSeek V4 Pro Max ทำคะแนน AA-Omniscience ที่ -10 ดีขึ้น 11 จุดจาก V3.2 แต่มี hallucination rate สูงถึง 94% ในชุดทดสอบนั้น [
7]
-
หลักฐานสาธารณะที่พบยังไม่เพียงพอสำหรับการสรุปตารางคะแนน benchmark ครบทุกหมวดของทั้ง 4 รุ่นพร้อมกัน; ดังนั้นจุดที่ไม่มีตัวเลขควรถือว่า “Insufficient evidence.”
ขอบเขตและวิธีวิจัย
-
รายงานนี้ใช้หลักฐานจากเอกสารทางการ, เอกสารเทคนิค, แหล่ง benchmark ภายนอก และแหล่งวิชาการที่พบในผลค้นหา ณ วันที่ทำรายงาน [
2][
6][
11][
14][
1]
-
แหล่งที่มีน้ำหนักสูงกว่าในรายงานนี้คือเอกสารทางการหรือเอกสารเทคนิค เช่น release notes ของ Anthropic, เอกสาร safety/evaluation ของ OpenAI และ PDF ทางเทคนิคของ DeepSeek V4 [
2][
14][
6]
-
แหล่งที่ใช้สำหรับคะแนนเปรียบเทียบหลายรุ่นพร้อมกันส่วนใหญ่เป็นแหล่งภายนอก เช่น Vellum, BenchLM, LLM Stats และ Artificial Analysis จึงควรตีความเป็น benchmark จากผู้ประเมินรายนั้น ไม่ใช่ผลรับรองกลางทั้งหมด [
11][
12][
15][
7]
-
งานวิชาการด้าน benchmark การเขียนโค้ดชี้ว่าชุดทดสอบอย่าง HumanEval มีข้อจำกัด และมีความพยายามสร้าง benchmark ที่ใกล้งานจริงมากขึ้น เช่น SWE-Bench และ benchmark fine-grained issue solving [
1]
ภาพรวม benchmark ที่ควรใช้เทียบ
| หมวดทดสอบ | ตัวอย่าง benchmark ที่พบ | ใช้วัดอะไร | หมายเหตุด้านความน่าเชื่อถือ |
|---|---|---|---|
| Reasoning / knowledge | GPQA, MMLU-Pro, ARC-AGI, LongBench v2, MuSR | ความรู้เชิงลึก การให้เหตุผล และการแก้ปัญหาซับซ้อน | OpenAI ระบุว่า CoT-Control ของ GPT-5.5 ใช้ชุดงานจาก GPQA และ MMLU-Pro ร่วมกับ benchmark อื่น ๆ มากกว่า 13,000 งาน [ |
| Coding / software engineering | SWE-Bench Pro, SWE-Bench Verified, LiveCodeBench, Expert-SWE | ความสามารถแก้ issue, เขียน/แก้โค้ด และทำงานวิศวกรรมซอฟต์แวร์ | งานวิชาการระบุว่า benchmark แบบ HumanEval ไม่พอสำหรับงานจริง จึงต้องใช้ benchmark ที่ใกล้ issue จริงมากขึ้น [ |
| Agentic / tool use | Terminal-Bench 2.0, BrowseComp, OSWorld-Verified, GAIA, TAU-bench, WebArena | การใช้เครื่องมือ, terminal, browser, workflow หลายขั้นตอน | BenchLM จัด GPT-5.5 ในหมวด agentic ด้วยชุด benchmark อย่าง Terminal-Bench 2.0, BrowseComp, OSWorld-Verified, GAIA, TAU-bench และ WebArena [ |
| Vision / multimodal | MMMU Pro, image/video input tests | ความเข้าใจภาพ วิดีโอ และเอกสารหลายรูปแบบ | ข้อมูลที่พบสำหรับทั้ง 4 รุ่นยังไม่พอสำหรับสรุปเชิงตัวเลขครบทุกโมเดล; Insufficient evidence. |
| Long context | LongBench v2, MRCRv2, context-window tests | การคงบริบทและดึงข้อมูลจากเอกสารยาว | DeepSeek V4 Pro ถูกระบุว่ามี context window 1,000k tokens และ Kimi K2.6 256k tokens ในแหล่งเปรียบเทียบเดียวกัน [ |
| Safety / reliability | CoT-Control, Petri, hallucination tests, AA-Omniscience | การควบคุมพฤติกรรม, eval-awareness, hallucination, ความน่าเชื่อถือ | OpenAI ใช้ CoT-Control กับงานมากกว่า 13,000 งาน ส่วน Anthropic รายงาน Petri 2.0 และ Artificial Analysis รายงาน hallucination rate ของ DeepSeek V4 Pro Max [ |
ตารางเปรียบเทียบคะแนนที่พบ
| Benchmark / metric | GPT-5.5 | Claude Opus 4.7 | DeepSeek V4 | Kimi K2.6 | ข้อสรุปจากหลักฐาน |
|---|---|---|---|---|---|
| Terminal-Bench 2.0 | 82.7% | 69.4% | Insufficient evidence | Insufficient evidence | GPT-5.5 นำ Claude Opus 4.7 ชัดเจนในงาน terminal/agentic ตามแหล่งนี้ [ |
| SWE-Bench Pro | 58.6% | 64.3% | Insufficient evidence | Insufficient evidence | Claude Opus 4.7 นำ GPT-5.5 ในงาน software engineering ตามแหล่งนี้ [ |
| Expert-SWE internal | 73.1% | Insufficient evidence | Insufficient evidence | Insufficient evidence | ใช้ได้เป็นสัญญาณภายในของ GPT-5.5 แต่ไม่เหมาะสรุปเทียบทุกค่ายเพราะไม่มีคะแนนครบ [ |
| GDPval | 84.9% | 80.3% | Insufficient evidence | Insufficient evidence | GPT-5.5 นำ Claude Opus 4.7 ใน benchmark งานมืออาชีพตามแหล่งนี้ [ |
| BenchLM aggregate: Agentic | #2 / 99.5 จาก 100 | Insufficient evidence | Insufficient evidence | Insufficient evidence | ใช้ดูอันดับรวมของ GPT-5.5 ได้ แต่ยังไม่ใช่ตารางเดียวกันครบ 4 โมเดล [ |
| BenchLM aggregate: Coding | 85.6 จาก 100 | Insufficient evidence | Insufficient evidence | Insufficient evidence | GPT-5.5 ถูกจัดอันดับสูงใน coding aggregate แต่ไม่มีคะแนนคู่เทียบครบในแหล่งเดียวกัน [ |
| BenchLM aggregate: Reasoning | 100.0 จาก 100 | Insufficient evidence | Insufficient evidence | Insufficient evidence | GPT-5.5 ถูกจัดอันดับสูงสุดใน reasoning aggregate ของ BenchLM แต่ยังไม่ใช่ผลเปรียบเทียบครบ 4 รุ่น [ |
| Context window | Insufficient evidence | Insufficient evidence | 1,000k tokens | 256k tokens | DeepSeek V4 Pro เหนือ Kimi K2.6 ด้าน context window ตามแหล่งเปรียบเทียบนี้ [ |
| AA-Omniscience | Insufficient evidence | Insufficient evidence | -10 สำหรับ V4 Pro Max | Insufficient evidence | DeepSeek V4 Pro Max ดีขึ้นจาก V3.2 แต่ยังมี hallucination rate สูงมากในรายงานเดียวกัน [ |
| Hallucination rate | Insufficient evidence | Insufficient evidence | 94% สำหรับ V4 Pro/Flash | Insufficient evidence | เป็นสัญญาณความเสี่ยงสำคัญของ DeepSeek V4 ในชุดทดสอบของ Artificial Analysis [ |
วิเคราะห์รายโมเดล
GPT-5.5
-
GPT-5.5 เป็นโมเดลที่มีข้อมูลคะแนนสาธารณะมากที่สุดในชุดหลักฐานที่พบ โดยมีคะแนน Terminal-Bench 2.0, SWE-Bench Pro, Expert-SWE และ GDPval จากแหล่งเปรียบเทียบภายนอก [
11]
-
จุดแข็งหลักของ GPT-5.5 คือ agentic workflow และงานมืออาชีพ โดยได้ 82.7% บน Terminal-Bench 2.0 และ 84.9% บน GDPval [
11]
-
จุดที่ยังไม่ชนะทุกหมวดคือ software engineering benchmark แบบ SWE-Bench Pro เพราะ GPT-5.5 ได้ 58.6% ต่ำกว่า Claude Opus 4.7 ที่ 64.3% [
11]
-
เอกสาร safety/evaluation ของ OpenAI สำหรับ GPT-5.5 ระบุการใช้ CoT-Control กับงานมากกว่า 13,000 งานจาก benchmark เช่น GPQA และ MMLU-Pro ซึ่งทำให้ข้อมูลด้านการควบคุมพฤติกรรมมีฐานเอกสารทางการมากกว่าโมเดลอื่นในชุดนี้ [
14]
Claude Opus 4.7
-
Claude Opus 4.7 ปรากฏในเอกสาร release notes ของ Anthropic วันที่ 16 เมษายน 2026 ซึ่งช่วยยืนยันสถานะโมเดลในเอกสารทางการ [
2]
-
จุดแข็งที่เด่นที่สุดจากข้อมูลที่พบคือ coding/software engineering เพราะ Claude Opus 4.7 ได้ 64.3% บน SWE-Bench Pro เทียบกับ GPT-5.5 ที่ 58.6% [
11]
-
Claude Opus 4.7 ตามข้อมูลเดียวกันได้ 69.4% บน Terminal-Bench 2.0 และ 80.3% บน GDPval ซึ่งตามหลัง GPT-5.5 ในสองหมวดนี้ [
11]
-
Anthropic มีงานประเมินด้าน safety/eval-awareness ผ่าน Petri 2.0 โดยรายงานว่าการแทรกแซงสองแนวทางร่วมกันทำให้ eval-awareness ลดลงแบบ median relative drop 47.3% ในโมเดล Claude [
4]
DeepSeek V4
-
เอกสาร DeepSeek-V4 ระบุว่า V4 series ยังคง DeepSeekMoE framework และ Multi-Token Prediction strategy จาก DeepSeek-V3 พร้อมเพิ่มนวัตกรรมด้านสถาปัตยกรรมและการปรับประสิทธิภาพ [
6]
-
DeepSeek V4 Pro ถูกระบุในแหล่งเปรียบเทียบว่ามี context window 1,000k tokens ซึ่งสูงกว่า Kimi K2.6 ที่ 256k tokens อย่างมีนัยสำคัญ [
9]
-
Artificial Analysis รายงานว่า DeepSeek V4 Pro Max ได้ AA-Omniscience -10 ซึ่งดีขึ้น 11 จุดจาก DeepSeek V3.2 Reasoning ที่ -21 [
7]
-
ประเด็นเสี่ยงสำคัญคือ Artificial Analysis รายงาน hallucination rate 94% สำหรับ DeepSeek V4 Pro และ V4 Flash ในชุดประเมินของตน [
7]
-
ยังไม่มีหลักฐานเพียงพอในชุดผลค้นหานี้สำหรับการเปรียบเทียบ DeepSeek V4 กับ GPT-5.5 และ Claude Opus 4.7 บน Terminal-Bench 2.0, SWE-Bench Pro หรือ GDPval; Insufficient evidence.
Kimi K2.6
-
หลักฐานเปรียบเทียบที่พบสำหรับ Kimi K2.6 จำกัดกว่ารุ่นอื่น โดยแหล่งที่พบยืนยันได้ว่า Kimi K2.6 มี context window 256k tokens ในตารางเปรียบเทียบกับ DeepSeek V4 Pro [
9]
-
เมื่อเทียบเฉพาะ context window, Kimi K2.6 ต่ำกว่า DeepSeek V4 Pro ที่ 1,000k tokens ตามแหล่งเปรียบเทียบเดียวกัน [
9]
-
ยังไม่มีหลักฐานเพียงพอในชุดผลค้นหานี้สำหรับคะแนน Kimi K2.6 บน Terminal-Bench 2.0, SWE-Bench Pro, GPQA, MMLU-Pro, GDPval หรือ hallucination benchmark แบบเดียวกับ DeepSeek V4; Insufficient evidence.
เปรียบเทียบตามกรณีใช้งาน
-
หากเน้น terminal, agentic workflow และงานหลายขั้นตอน GPT-5.5 เป็นตัวเลือกที่มีหลักฐานคะแนนนำ Claude Opus 4.7 ชัดเจนจาก Terminal-Bench 2.0 ที่ 82.7% เทียบกับ 69.4% [
11]
-
หากเน้นแก้ปัญหา software engineering จาก issue จริง Claude Opus 4.7 น่าพิจารณากว่า GPT-5.5 เพราะได้ SWE-Bench Pro 64.3% เทียบกับ 58.6% [
11]
-
หากเน้นงานมืออาชีพหรือ benchmark แนว GDPval GPT-5.5 มีคะแนน 84.9% สูงกว่า Claude Opus 4.7 ที่ 80.3% [
11]
-
หากเน้น long-context retrieval หรือเอกสารยาวมาก DeepSeek V4 Pro มีจุดเด่นจาก context window 1,000k tokens เทียบกับ Kimi K2.6 ที่ 256k tokens แต่ยังไม่มีข้อมูลครบสำหรับเทียบกับ GPT-5.5 และ Claude Opus 4.7 ในแหล่งเดียวกัน [
9]
-
หากเน้นความน่าเชื่อถือและลด hallucination ควรระวัง DeepSeek V4 เพราะรายงานของ Artificial Analysis ระบุ hallucination rate 94% ในชุดทดสอบของตน [
7]
-
หากต้องการเลือก Kimi K2.6 สำหรับงาน production ควรขอหรือรอ benchmark เพิ่มเติมจากแหล่งทางการหรือผู้ประเมินภายนอกที่ใช้ harness เดียวกับ GPT-5.5, Claude Opus 4.7 และ DeepSeek V4; Insufficient evidence.
Evidence notes
-
แหล่งทางการที่พบสำหรับ GPT-5.5 มีน้ำหนักสูงในส่วน safety/evaluation แต่คะแนนเปรียบเทียบเชิงประสิทธิภาพที่ครบกว่าในรายงานนี้มาจากแหล่งภายนอก [
14][
11]
-
แหล่งทางการของ Anthropic ที่พบยืนยันการมีอยู่ของ Claude Opus 4.7 ใน release notes แต่คะแนนเปรียบเทียบที่ใช้ในตารางมาจากแหล่งภายนอก [
2][
11]
-
แหล่ง DeepSeek V4 ที่มีน้ำหนักสูงสุดคือ PDF เทคนิคบน Hugging Face ของ deepseek-ai ซึ่งอธิบายสถาปัตยกรรมและ long-context direction แต่ไม่ให้ตารางเปรียบเทียบครบทุก benchmark ที่ต้องการในผลค้นหาที่พบ [
6]
-
แหล่งสำหรับ Kimi K2.6 ที่ใช้ได้ในรายงานนี้เป็นแหล่งเปรียบเทียบภายนอก ไม่ใช่เอกสาร benchmark ทางการของ Moonshot/Kimi ในผลค้นหาที่พบ [
9]
-
งานวิชาการสนับสนุนข้อควรระวังว่าการวัด coding capability ต้องใช้ benchmark ที่ใกล้งานจริงกว่า HumanEval และควรพิจารณา benchmark ประเภท SWE-Bench หรือ issue-solving ร่วมด้วย [
1]
Limitations / uncertainty
-
Insufficient evidence สำหรับตารางคะแนนครบทุก benchmark ของทั้ง 4 รุ่นใน harness เดียวกัน
-
คะแนนจากแหล่งต่างกันอาจใช้ prompt, sampling, tool access, reasoning mode, compute budget และ scoring pipeline ต่างกัน จึงไม่ควรนำตัวเลขจากคนละแหล่งมารวมเป็นอันดับเด็ดขาด
-
ข้อมูล DeepSeek V4 และ Kimi K2.6 ในรายงานนี้ยังไม่ครบด้าน coding, reasoning, multimodal, safety และ cost-performance เมื่อเทียบกับข้อมูล GPT-5.5 และ Claude Opus 4.7
-
ผล benchmark ของโมเดลรุ่น frontier เปลี่ยนเร็วมาก และควรตรวจซ้ำกับ model card, system card, technical report และ leaderboard ที่อัปเดตล่าสุดก่อนตัดสินใจใช้งานจริง
Summary
คนยังถาม
คำตอบสั้น ๆ สำหรับ "ศึกษาค้นคว้าเกณฑ์มาตรฐานการทดสอบของ GPT-5.5, Claude Opus 4.7, DeepSeek V4 และ Kimi K2.6 แล้วเปรียบเทียบให้ครอบคลุมมากที่สุดเท่าที่เป็นไปได้ จัดทำรายงานการวิจัยเกี่ยวกับเรื่องนี้" คืออะไร
ข้อมูลที่เทียบได้ตรงที่สุดระหว่าง GPT-5.5 กับ Claude Opus 4.7 คือ Terminal-Bench 2.0, SWE-Bench Pro และ GDPval จากแหล่งวิเคราะห์ภายนอกเดียวกัน
ประเด็นสำคัญที่ต้องตรวจสอบก่อนคืออะไร?
ข้อมูลที่เทียบได้ตรงที่สุดระหว่าง GPT-5.5 กับ Claude Opus 4.7 คือ Terminal-Bench 2.0, SWE-Bench Pro และ GDPval จากแหล่งวิเคราะห์ภายนอกเดียวกัน GPT-5.5 ได้ 82.7% บน Terminal-Bench 2.0 เทียบกับ Claude Opus 4.7 ที่ 69.4% ทำให้ GPT-5.5 นำในงาน terminal/agentic workflow ตามข้อมูลชุดนี้
ฉันควรทำอย่างไรต่อไปในทางปฏิบัติ?
Claude Opus 4.7 ได้ 64.3% บน SWE-Bench Pro เทียบกับ GPT-5.5 ที่ 58.6% ทำให้ Claude นำใน benchmark งานแก้ปัญหา software engineering ตามข้อมูลชุดนี้
ฉันควรสำรวจหัวข้อที่เกี่ยวข้องใดต่อไป
ดำเนินการต่อด้วย "Recherchez les benchmarks de GPT-5.5, Claude Opus 4.7, DeepSeek V4 et Kimi K2.6, puis comparez-les de la manière la plus complète possible." เพื่อดูอีกมุมหนึ่งและการอ้างอิงเพิ่มเติม
เปิดหน้าที่เกี่ยวข้องฉันควรเปรียบเทียบสิ่งนี้กับอะไร?
ตรวจสอบคำตอบนี้กับ "Research benchmarks for GPT-5.5, Claude Opus 4.7, DeepSeek V4, and Kimi K2.6, and compare them as comprehensively as possible. Create a rese"
เปิดหน้าที่เกี่ยวข้องทำการวิจัยต่อ
แหล่งที่มา
- [1] [AINews] GPT 5.5 and OpenAI Codex Superapp - Latent.Spacelatent.space
GPT-5.5 is the day’s dominant release: OpenAI launched GPT-5.5, positioned as “a new class of intelligence for real work,” with rollout across ChatGPT and Codex and API access delayed pending additional safeguards. OpenAI and community benchmark posts conve...
- [2] Everything You Need to Know About GPT-5.5vellum.ai
Benchmark GPT-5.5 GPT-5.5 Pro GPT-5.4 Claude Opus 4.7 Gemini 3.1 Pro --- --- --- Terminal-Bench 2.0 82.7% — 75.1% 69.4% 68.5% SWE-Bench Pro 58.6% — 57.7% 64.3% 54.2% Expert-SWE (Internal) 73.1% — 68.5% — — GDPval 84.9% 82.3% 83.0% 80.3% 67.3% OSWorld-Verifi...
- [3] GPT-5.5 Benchmarks 2026: Scores, Rankings & Performancebenchlm.ai
Agentic 2 99.5/ 100 Weight: 22%7 benchmarks Terminal-Bench 2.0BrowseCompOSWorld-VerifiedGAIATAU-benchWebArena Coding 85.6/ 100 Weight: 20%3 benchmarks SWE-bench VerifiedLiveCodeBenchSWE-bench ProSWE-RebenchSciCode Reasoning 100.0/ 100 Weight: 17%3 benchmark...
- [4] GPT-5.5 System Card - OpenAI Deployment Safety Hubdeploymentsafety.openai.com
We measure GPT-5.5’s controllability by running CoT-Control, an evaluation suite described in (Yueh-Han, 2026 ) that tracks the model’s ability to follow user instructions about their CoT. CoT-Control includes over 13,000 tasks built from established benchm...
- [5] GPT-5.5: Pricing, Benchmarks & Performancellm-stats.com
Leaderboard Rankings 2 Coding 2 Reasoning 2 Tool Calling 2 Vision 6 Search 10 Writing 12 Long Context 16 Math 78 Finance GPT-5.5 Performance Across Datasets Scores sourced from the model's scorecard, paper, or official blog posts Image 3: LLM Stats Logollm-...
- [6] GPT-5.5: The Complete Guide (2026) - o-mega | AIo-mega.ai
Reasoning, Math, and Science Benchmark GPT-5.5 GPT-5.5 Pro GPT-5.4 Claude Opus 4.7 Gemini 3.1 Pro --- --- --- MMLU 92.4% - - GPQA Diamond 93.6% 92.8% 94.2% 94.3% ARC-AGI-2 85.0% 73.3% 77.1% ARC-AGI-1 95.0% 93.7% - FrontierMath T1-3 51.7% 52.4% 47.6% 43.8% F...
- [7] Introducing GPT-5.5 - OpenAIopenai.com
Computer use and vision EvalGPT-5.5GPT‑5.4GPT-5.5 ProGPT‑5.4 ProClaudeOpus 4.7Gemini 3.1 Pro OSWorld-Verified 78.7%75.0%--78.0%- MMMU Pro (no tools)81.2%81.2%---80.5% MMMU Pro (with tools)83.2%82.1%---- Tool use EvalGPT-5.5GPT‑5.4GPT-5.5 ProGPT‑5.4 ProClaud...
- [8] OpenAI GPT-5.5 Benchmark (CodeRabbit)coderabbit.ai
2025 was the year of AI speed. 2026 will be the year of AI quality. The year 2025 will be remembered as the moment AI-assisted software development entered its acceleration era. Improvements in the capabilities of coding agents, copilots, and automated work...
- [9] OpenAI's GPT-5.5 is the new leading AI model - Artificial Analysisartificialanalysis.ai
Read the latest Image 7 Kimi K2.6: The new leading open weights model Benchmarks and Analysis of Kimi K2.6 April 21, 2026Image 8 Opus 4.7: Everything you need to know Benchmarks and Analysis of Opus 4.7 April 17, 2026Image 9 Sub-32B Open Weights Benchmark a...
- [10] OpenAI's GPT-5.5 masters agentic coding with 82.7% benchmark ...interestingengineering.com
On SWE-Bench Pro, it reached 58.6%, solving more real-world GitHub issues in a single pass than earlier versions. The model also outperformed its predecessor in long-horizon engineering tasks measured by internal benchmarks. These tasks often take human dev...
- [11] Model Drop: GPT-5.5 - by Jake Handyhandyai.substack.com
Headline benchmarks: Terminal-Bench 2.0 at 82.7% (Opus 4.7: 69.4%, Gemini 3.1 Pro: 68.5%). SWE-Bench Pro at 58.6% (Opus 4.7 still leads at 64.3%). OpenAI’s internal Expert-SWE eval, where tasks have a 20-hour median human completion time, at 73.1% (up from...
- [12] OpenAI Releases GPT-5.5 With State-of-the-Art Scores on Coding, Science, and Computer Uselinkedin.com
On Terminal-Bench 2.0, which measures complex command-line workflows requiring planning and tool coordination, GPT-5.5 reaches 82.7%, up from GPT-5.4's 75.1%. On OSWorld-Verified, which tests whether a model can operate real computer interfaces without huma...
- [13] GPT-5.5 is here: benchmarks, pricing, and what changes ... - Appwriteappwrite.io
Star on GitHub 55.8KGo to Console Start building for free Sign upGo to Console Start building for free Products Docs Pricing Customers Blog Changelog Star on GitHub 55.8K Blog/GPT-5.5 is here: benchmarks, pricing, and what changes for developers Apr 24, 202...
- [14] Unveiling the GPT-5.5 Benchmark Results: A Deep Dive into Agentic ...skywork.ai
.9742C29.3654%2035.1061%2029.1866%2035.1802%2029.0001%2035.1802C28.8136%2035.1802%2028.6348%2035.1061%2028.5029%2034.9742C28.3711%2034.8424%2028.297%2034.6635%2028.297%2034.4771V20.7055L23.1694%2025.8339C23.0375%2025.9658%2022.8586%2026.0399%2022.672%2026.0...
- [15] GPQA Leaderboard 2026 - Compare AI Model Scorespricepertoken.com
Z Z AI GLM 4.7 $0.390 $1.750 66.4 Try AL Alibaba Qwen3 30B A3B Instruct 2507 $0.090 $0.300 65.9 Try Image 89: Anthropic Anthropic Claude 3.7 Sonnet $3.000 $15.000 65.6 Try X Xiaomi MiMo-V2-Flash $0.090 $0.290 65.6 Try Image 90: ByteDance Seed ByteDance Seed...
- [16] GPT 5.5vals.ai
2/17/2026 Anthropic Claude Sonnet 4.6 2/16/2026 Alibaba Qwen 3.5 Plus 2/12/2026 MiniMax MiniMax-M2.5 2/12/2026 MiniMax MiniMax-M2.5 2/11/2026 zAI GLM 5 2/5/2026 Anthropic Claude Opus 4.6 (Nonthinking) 2/5/2026 Anthropic Claude Opus 4.6 (Thinking) 1/26/2026...
- [17] LLM Leaderboard 2026 — Compare Top AI Models - Vellumvellum.ai
93.6% GPT-5.5 92.4% GPT 5.2 91.9% Gemini 3 Pro Best in Reasoning (GPQA Diamond) Model Score --- Claude 3 Opus 95.4% Claude Opus 4.7 94.2% GPT-5.5 93.6% GPT 5.2 92.4% Gemini 3 Pro 91.9% Best in High School Math (AIME 2025) 100%96%93%89%86% 100% Gemini 3 Pro...
- [18] AI Leaderboard 2026 - Compare Top AI Models & Rankingsllm-stats.com
Rank Model Code Arena Chat Arena GPQA SWE-bench Context Input $/M Output $/M License --- --- --- --- --- 1 Image 2: Google Gemini 3.1 Pro Google 2,093 1,222 94.3% 80.6% 1.0M $2.50 $15.00 Proprietary 2 Image 3: Anthropic Claude Opus 4.6 Anthropic 2,005 1,491...
- [19] AI Model Benchmarks Apr 2026 | Compare GPT-5, Claude 4.5 ...lmcouncil.ai
Show More Models (no tools) Score --- 1 Gemini 3.1 Pro Preview 44.7% 2 GPT-5.5 (xhigh) 44.3% 3 GPT-5.5 (high) 43.0% 4 GPT-5.4 (xhigh) 41.6% 5 GPT-5.5 (medium) 40.6% Show all 10 Try Top 4Full Results SimpleBench Asks "trick" questions that require common-sen...
- [20] System Prompts - Claude API Docsdocs.anthropic.com
Claude Opus 4.7. April 16, 2026. Claude Sonnet 4.6. February 17, 2026. Claude Opus 4.6. February 5, 2026. Claude Opus 4.5. January 18, 2026. November 24, 2025 ...
- [21] Introducing Claude 4 - Anthropicanthropic.com
Claude Opus 4 is the world's best coding model, with sustained performance on complex, long-running tasks and agent workflows. Claude Sonnet ... May 22, 2025
- [22] Petri 2.0: New Scenarios, New Model Comparisons, and Improved ...alignment.anthropic.com
The two approaches are complementary: On Claude models, the interventions together lead to a 47.3% median relative drop in eval-awareness ... Jan 22, 2026
- [23] [PDF] Claude Sonnet 4.6 System Card - Anthropicanthropic.com
March 6, 2026. ○ Sonnet 4.6's BrowseComp scores updated due to running an improved cheating detection pipeline. Read more at our blog post ... Feb 17, 2026
- [24] Anthropic's Transparency Hubanthropic.com
View the Claude Opus 4 model report or the Claude Opus 4.1 system card addendum for key updates. Claude 3.7 Sonnet Summary Table. Model ... Feb 20, 2026
- [25] Claude Opus 4.7 - Anthropicanthropic.com
Claude Opus 4.6 is our most capable model to date. Building on the intelligence of Opus 4.5, it brings new levels of reliability and precision to coding, agents ...
- [26] Introducing Claude Opus 4.7 - Anthropicanthropic.com
On our 93-task coding benchmark, Claude Opus 4.7 lifted resolution by 13% over Opus 4.6, including four tasks neither Opus 4.6 nor Sonnet 4.6 ...
- [27] Home \ Anthropicanthropic.com
Claude Opus 4.7. Introducing a smarter, more capable Opus for coding, agents, vision, and complex professional work. Model details. Model details. Model details.
- [28] Research - Anthropicanthropic.com
We tasked Claude with buying, selling and negotiating on our colleagues' behalf. Interpretability Apr 2, 2026. Emotion concepts and their function in a large ...
- [29] Newsroom - Anthropicanthropic.com
Introducing Claude Opus 4.7. Product Apr 16, 2026. Our latest Opus model brings stronger performance ... Product Apr 17, 2026. Introducing Claude Design by ...
- [30] [PDF] DeepSeek-V4: Towards Highly Efficient Million-Token Context ...huggingface.co
Compared with the DeepSeek-V3 architecture (DeepSeek-AI, 2024), DeepSeek-V4 series retain the DeepSeekMoE framework (Dai et al., 2024) and Multi-Token Prediction (MTP) strategy, while introducing several key innovations in architecture and optimization. To...
- [31] DeepSeek is back among the leading open weights models with V4 ...artificialanalysis.ai
Gains in knowledge but an increase in hallucination rate: DeepSeek V4 Pro (Max) scores -10 on AA-Omniscience, an 11 point improvement over V3.2 (Reasoning, -21), driven primarily by higher accuracy. V4 Flash (Max) scores -23, broadly in line with V3.2. V4 P...
- [32] DeepSeek V4 and Kimi K2.6 - Models - NVIDIA Developer Forumsforums.developer.nvidia.com
Deepseek: Extract Reasoning Only NVIDIA Nemotron nim 1 600 February 18, 2025 Hope, dream NVIDIA Nemotron 0 273 February 29, 2024 DeepSeek Models - newbie python programmer - calling the wizards out there (you know who you are) DGX Spark / GB10 Projects deep...
- [33] DeepSeek V4 Pro (Reasoning, High Effort) vs Kimi K2.6: Model Comparisonartificialanalysis.ai
Metric DeepSeek logoDeepSeek V4 Pro (Reasoning, High Effort) Kimi logoKimi K2.6 Analysis --- --- Creator DeepSeek Kimi Context Window 1000k tokens ( 1500 A4 pages of size 12 Arial font) 256k tokens ( 384 A4 pages of size 12 Arial font) DeepSeek V4 Pro (Reas...
- [34] DeepSeek-V4-Pro-Max: Pricing, Benchmarks & Performancellm-stats.com
DeepSeek-V4-Pro-Max: Pricing, Benchmarks & Performance Image 1: LLM Stats LogoLLM Stats Leaderboards Benchmarks Compare Playground Arenas Gateway Services Search⌘K Sign in Toggle theme NEW•NEW•NEW•NEW• Ship an AI phone agent in 7 lines CallingBox Start for...
- [35] Kimi K2.6 - Intelligence, Performance & Price Analysisartificialanalysis.ai
Kimi K2.6 scores 54 on the Artificial Analysis Intelligence Index, placing it well above average among comparable models (averaging 28). When evaluating the Intelligence Index, it generated 160M tokens, which is very verbose in comparison to the average of...
- [36] Kimi K2.6: The new leading open weights model - Artificial Analysisartificialanalysis.ai
➤ Multimodality: Kimi K2.6 supports Image and Video input and text output natively. The model’s max context length remains 256k. Kimi K2.6 has significantly higher token usage than Kimi K2.5. Kimi K2.5 scores 6 on the AA-Omniscience Index, primarily driven...
- [37] DeepSeek V4 Pro (Reasoning, Max Effort) vs Kimi K2.6artificialanalysis.ai
Metric DeepSeek logoDeepSeek V4 Pro (Reasoning, Max Effort) Kimi logoKimi K2.6 Analysis --- --- Creator DeepSeek Kimi Context Window 1000k tokens ( 1500 A4 pages of size 12 Arial font) 256k tokens ( 384 A4 pages of size 12 Arial font) DeepSeek V4 Pro (Reaso...
- [38] I reviewed how DeepSeek V4-Pro, Kimi 2.6, Opus 4.6, and Opus 4.7 ...news.ycombinator.com
ozgune 1 day ago parent context favorite on: DeepSeek v4 I reviewed how DeepSeek V4-Pro, Kimi 2.6, Opus 4.6, and Opus 4.7 across the same AI benchmarks. All results are for Max editions, except for Kimi. Summary: Opus 4.6 forms the baseline all three are tr...
- [39] Artificial Analysis: AI Model & API Providers Analysisartificialanalysis.ai
Speed: Output Tokens per Second; Higher is better 1. gpt-oss-120B (high): 209 2. NVIDIA Nemotron 3 Super: 155 3. Gemini 3.1 Pro Preview: 127 4. Grok 4.20 0309 v2: 108 5. Kimi K2.6: 106 6. GPT-5.4 (xhigh): 80 7. GPT-5.5 (xhigh): 72 8. MiMo-V2.5-Pro: 62 9. Cl...
- [40] DeepSeek V4 Released: Everything You Need to Know (April 2026)felloai.com
Benchmark Opus 4.6 Max GPT-5.4 xHigh Gemini 3.1 Pro High Kimi K2.6 GLM-5.1 DeepSeek V4-Pro-Max --- --- --- MMLU-Pro 89.1 87.5 91.0 87.1 86.0 87.5 SimpleQA-Verified 46.2 45.3 75.6 36.9 38.1 57.9 Chinese-SimpleQA 76.4 76.8 85.9 75.9 75.0 84.4 GPQA Diamond 91....
- [41] DeepSeek V4 finally drops—and gets beaten by a smartphone ...x.com
Kyle Chan on X: "DeepSeek V4 finally drops—and gets beaten by a smartphone company, whose AI team is led by one of DeepSeek’s former top researchers." / X Don’t miss what’s happening People on X are the first to know. Log in Sign up []( Post See new posts C...
- [42] A Real-World Benchmark for Evaluating Fine-Grained Issue Solving Capabilities of Large Language Modelsarxiv.org
… Existing benchmarks such as HumanEval fall short in their ability to … benchmarks like SWE-Bench are designed to evaluate the … on LLM evaluation, there remains a gap in benchmarks … 2024