Research benchmarks of Claude Opus 4.7, GPT-5.5, DeepSeek V4, Kimi K2.6 and compare as comprehensively as possible
Using only the supplied evidence, the strongest benchmark signal is that GPT 5.5 leads the available aggregate Intelligence Index, with GPT 5.5 xhigh at 60 and GPT 5.5 high at 59, while Claude Opus 4.7 Adaptive Reason...
Using only the supplied evidence, the strongest benchmark signal is that GPT 5.5 leads the available aggregate Intelligence Index, with GPT 5.5 xhigh at 60 and GPT 5.5 high at 59, while Claude Opus 4.7 Adaptive Reasoning Max Effort scores 57.[5] DeepSeek V4 Pro has the richest disclosed task level benchmark data in the
Key takeaways
- GPT-5.5 is the best-supported leader on the only cross-model aggregate benchmark available here: GPT-5.5 xhigh ranks first with an Intelligence Index of 60, and GPT-5.5 high ranks second with 59.
- Claude Opus 4.7 is close behind on that same aggregate measure: Claude Opus 4.7 Adaptive Reasoning Max Effort ranks third with an Intelligence Index of 57.
- DeepSeek V4 Pro has the clearest disclosed coding/SWE benchmark profile in the supplied evidence: 93.5% LiveCodeBench, Codeforces 3206, 80.6% SWE-Bench Verified, and 76.2% SWE-Bench Multilingual.
- Kimi K2.6 is described as an “open-source flagship” agent-coding model in the launch/news evidence, but the supplied evidence does not provide numeric benchmark scores for Kimi K2.6.
- Using only the supplied evidence, the strongest benchmark signal is that GPT-5.5 leads the available aggregate Intelligence Index, with GPT-5.5 xhigh at 60 and GPT-5.5 high at 59, while Claude Opus 4.7 Adaptive Reasoning Max Effort scores 57.[5] DeepSeek V4 Pro has the richest di
- ## Key findings
Research answer
Using only the supplied evidence, the strongest benchmark signal is that GPT-5.5 leads the available aggregate Intelligence Index, with GPT-5.5 xhigh at 60 and GPT-5.5 high at 59, while Claude Opus 4.7 Adaptive Reasoning Max Effort scores 57.[5] DeepSeek V4 Pro has the richest disclosed task-level benchmark data in the evidence, including 93.5% LiveCodeBench, Codeforces 3206, 80.6% SWE-Bench Verified, and 76.2% SWE-Bench Multilingual.[
6] For Kimi K2.6, the supplied evidence contains positioning and pricing but no comparable numeric benchmark scores, so a full apples-to-apples benchmark ranking is not supported.[
1][
3]
Key findings
-
GPT-5.5 is the best-supported leader on the only cross-model aggregate benchmark available here: GPT-5.5 xhigh ranks first with an Intelligence Index of 60, and GPT-5.5 high ranks second with 59.[
5]
-
Claude Opus 4.7 is close behind on that same aggregate measure: Claude Opus 4.7 Adaptive Reasoning Max Effort ranks third with an Intelligence Index of 57.[
5]
-
DeepSeek V4 Pro has the clearest disclosed coding/SWE benchmark profile in the supplied evidence: 93.5% LiveCodeBench, Codeforces 3206, 80.6% SWE-Bench Verified, and 76.2% SWE-Bench Multilingual.[
6]
-
Kimi K2.6 is described as an “open-source flagship” agent-coding model in the launch/news evidence, but the supplied evidence does not provide numeric benchmark scores for Kimi K2.6.[
1]
-
DeepSeek V4 is materially cheaper than GPT-5.5 in the pricing evidence: DeepSeek V4 is listed at $1.74 per 1M input tokens and $3.48 per 1M output tokens, while GPT-5.5 is listed at $5 per 1M input tokens and $30 per 1M output tokens, with both shown as 1M-context models.[
4]
-
DeepSeek V4 Flash is far cheaper than Kimi K2.6 in the direct pricing comparison: DeepSeek V4 Flash is listed at $0.14 per 1M input tokens, $0.28 per 1M output tokens, and $0.18 blended, while Kimi K2.6 is listed at $0.95 per 1M input tokens, $4.00 per 1M output tokens, and $1.71 blended.[
3]
-
The supplied evidence treats DeepSeek V4 as a family with multiple variants, including V4 Flash and V4 Pro, so comparisons depend on which variant is meant.[
2][
3][
6]
Benchmark and capability comparison
| Area | GPT-5.5 | Claude Opus 4.7 | DeepSeek V4 | Kimi K2.6 |
|---|---|---|---|---|
| Aggregate Intelligence Index | 60 for GPT-5.5 xhigh; 59 for GPT-5.5 high.[ | 57 for Claude Opus 4.7 Adaptive Reasoning Max Effort.[ | No numeric Intelligence Index for DeepSeek V4 is provided in the supplied evidence. | No numeric Intelligence Index for Kimi K2.6 is provided in the supplied evidence. |
| Coding / SWE benchmarks | No exact coding benchmark scores are provided in the supplied evidence. | The launch evidence says Claude Opus 4.7 has improved programming and a threefold vision upgrade, but no exact benchmark numbers are provided.[ | DeepSeek V4 Pro is listed with 93.5% LiveCodeBench, Codeforces 3206, 80.6% SWE-Bench Verified, and 76.2% SWE-Bench Multilingual.[ | Kimi K2.6 is positioned as an open-source flagship agent-coding model, but no exact benchmark numbers are provided.[ |
| Context window evidence | GPT-5.5 is listed with a 1M context window in the pricing comparison.[ | The supplied pricing snippet does not clearly provide Claude Opus 4.7’s context window. | DeepSeek V4 is listed with a 1M context window in one comparison, and DeepSeek V4 Flash / Pro are also described as 1M-context options in enterprise guidance.[ | No context-window figure for Kimi K2.6 is provided in the supplied evidence. |
| Pricing evidence | $5 per 1M input tokens and $30 per 1M output tokens.[ | $5 per 1M input tokens is visible in the supplied snippet, but the output price is truncated.[ | DeepSeek V4 is listed at $1.74 per 1M input tokens and $3.48 per 1M output tokens; DeepSeek V4 Flash is listed at $0.14 input, $0.28 output, and $0.18 blended.[ | Kimi K2.6 is listed at $0.95 per 1M input tokens, $4.00 per 1M output tokens, and $1.71 blended.[ |
| Best-supported use case from evidence | Highest aggregate intelligence among the four where evidence is available.[ | High-end reasoning close to GPT-5.5 on the available Intelligence Index.[ | Strongest supplied coding/SWE evidence and strong cost positioning, especially for Flash and Pro variants.[ | Potentially strong open-source agent-coding positioning, but benchmark evidence is insufficient.[ |
Pricing and value takeaways
-
On the available aggregate benchmark, GPT-5.5 leads Claude Opus 4.7 by 3 points at the xhigh setting and by 2 points at the high setting.[
5]
-
On the available API pricing comparison, GPT-5.5 costs about 2.9x DeepSeek V4 for input tokens and about 8.6x DeepSeek V4 for output tokens.[
4]
-
In the DeepSeek V4 Flash vs Kimi K2.6 pricing comparison, Kimi K2.6’s blended price of $1.71 per 1M tokens is about 9.5x DeepSeek V4 Flash’s $0.18 blended price.[
3]
-
One enterprise-oriented comparison recommends DeepSeek V4 Flash for high-volume text summarization, customer-service classification, and internal knowledge-base Q&A because of low cost and 1M context.[
2]
-
The same enterprise-oriented comparison recommends DeepSeek V4 Pro for complex document analysis, cross-department workflows, and automated agents because it is described as lower-cost than closed flagship models while offering high-end open-weight capability and 1M context.[
2]
Evidence notes
-
The strongest single benchmark source in the supplied evidence is the Intelligence Index listing, which ranks GPT-5.5 xhigh first at 60, GPT-5.5 high second at 59, and Claude Opus 4.7 Adaptive Reasoning Max Effort third at 57.[
5]
-
The strongest task-level benchmark evidence is for DeepSeek V4 Pro, because it includes exact coding and software-engineering metrics rather than only positioning language.[
6]
-
The Kimi K2.6 evidence is mostly launch positioning and pricing, not benchmark results.[
1][
3]
-
A user post describes four one-shot head-to-head experiments comparing Codex on GPT-5.5 with Claude Code on Opus 4.7, but the supplied snippet does not provide the outcomes or benchmark scores.[
31]
-
There is conflicting or variant-specific DeepSeek context/pricing evidence: one comparison lists DeepSeek V4 with a 1M context window, while another provider listing for DeepSeek V4 Pro shows 256K max tokens and 66K max output tokens.[
4][
7]
Limitations / uncertainty
-
Insufficient evidence for a full, comprehensive benchmark comparison across Claude Opus 4.7, GPT-5.5, DeepSeek V4, and Kimi K2.6.
-
Insufficient evidence to rank DeepSeek V4 or Kimi K2.6 against GPT-5.5 and Claude Opus 4.7 on the same aggregate Intelligence Index, because the supplied excerpt only provides numeric Intelligence Index scores for GPT-5.5 and Claude Opus 4.7 among the requested models.[
5]
-
Insufficient evidence to compare all four models on the same coding benchmarks, because only DeepSeek V4 Pro has detailed numeric coding/SWE benchmark scores in the supplied evidence.[
6]
-
Insufficient evidence to compare multimodal performance across all four models, because the supplied evidence only includes a launch-positioning claim that Claude Opus 4.7 has a threefold vision upgrade and does not provide comparable multimodal benchmark numbers for the others.[
1]
Summary
GPT-5.5 has the strongest supplied aggregate benchmark result, with Intelligence Index scores of 60 and 59 depending on reasoning setting.[5] Claude Opus 4.7 is close behind at 57 and is the only other requested model with a numeric aggregate score in the supplied evidence.[
5] DeepSeek V4 Pro has the best-supported coding/SWE benchmark profile, while DeepSeek V4 Flash and V4 Pro appear especially strong on cost and long-context enterprise use cases.[
2][
3][
6] Kimi K2.6 may be competitively positioned as an open-source agent-coding model, but the supplied evidence does not include enough numeric benchmark data to verify how it compares against GPT-5.5, Claude Opus 4.7, or DeepSeek V4.[
1][
3]
Supporting visuals



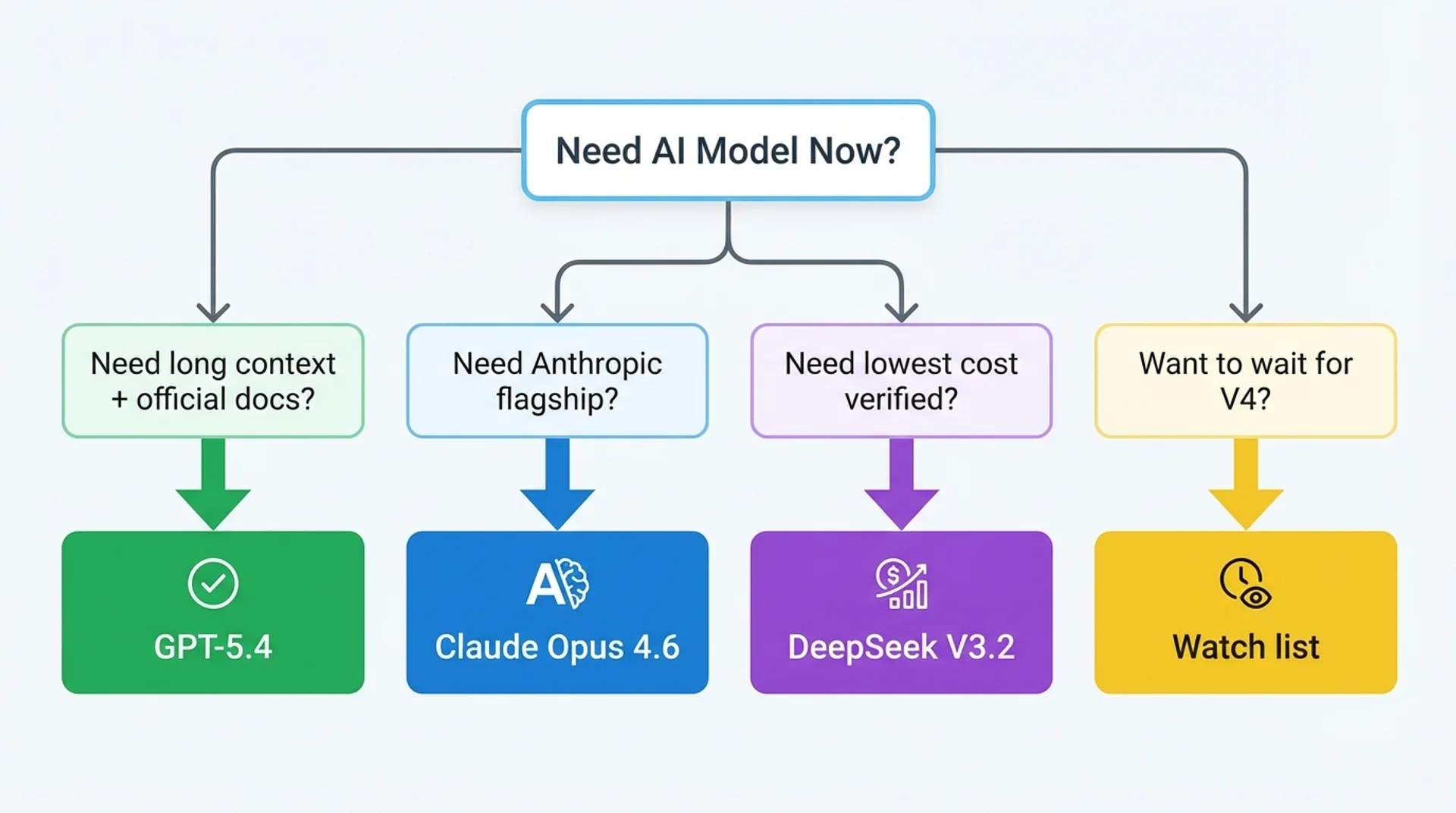








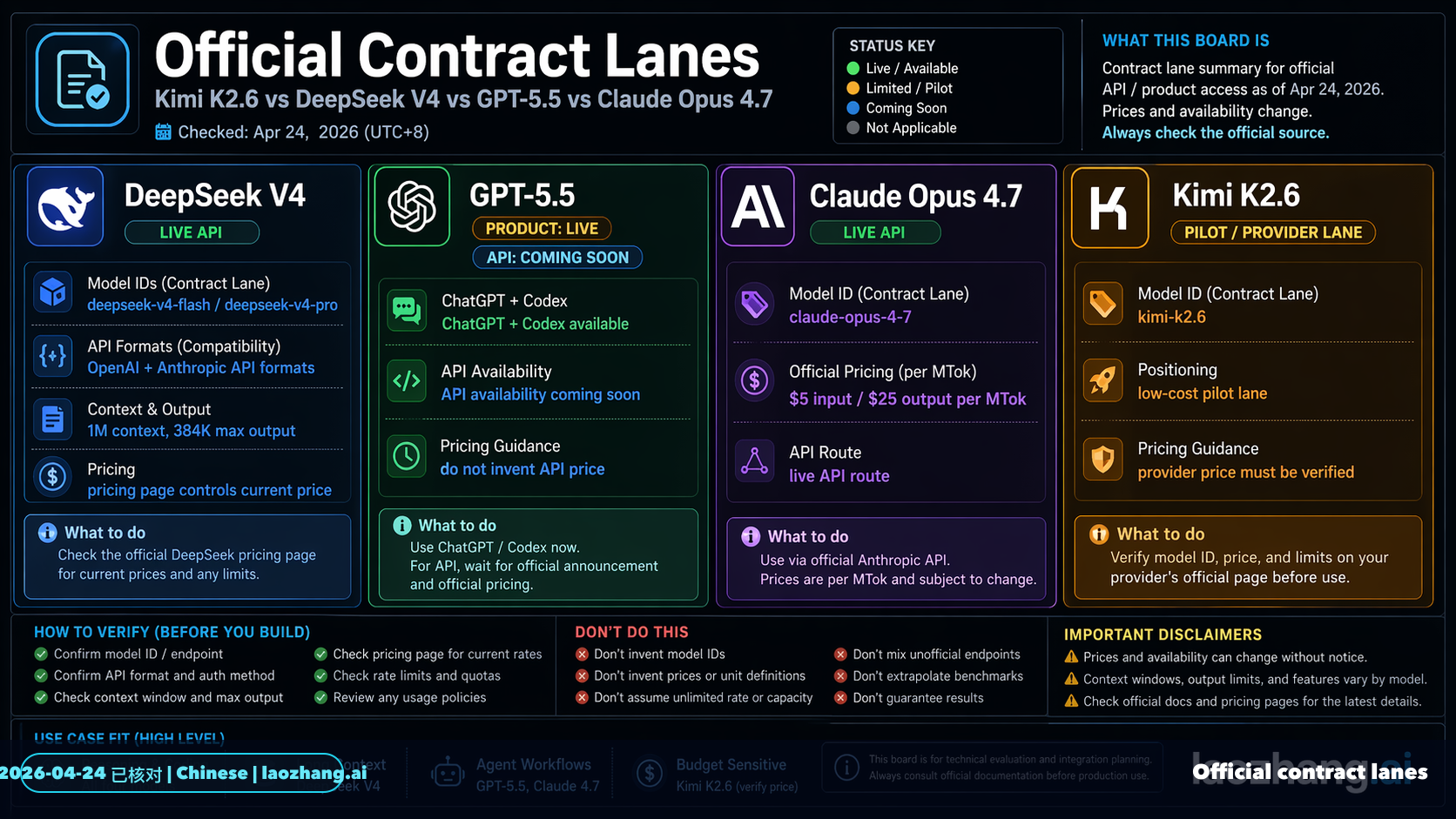


Research conversation
Research question
Research benchmarks of Claude Opus 4.7, GPT-5.5, DeepSeek V4, Kimi K2.6 and compare as comprehensively as possible
Cited answer
Using only the supplied evidence, the strongest benchmark signal is that GPT-5.5 leads the available aggregate Intelligence Index, with GPT-5.5 xhigh at 60 and GPT-5.5 high at 59, while Claude Opus 4.7 Adaptive Reasoning Max Effort scores 57.[5] DeepSeek V4 Pro has the richest disclosed task-level benchmark data in the evidence, including 93.5% LiveCodeBench, Codeforces 3206, 80.6% SWE-Bench Verified, and 76.2% SWE-Bench Multilingual.[
6] For Kimi K2.6, the supplied evidence contains positioning and pricing but no comparable numeric benchmark scores, so a full apples-to-apples benchmark ranking is not supported.[
1][
3]
Key findings
-
GPT-5.5 is the best-supported leader on the only cross-model aggregate benchmark available here: GPT-5.5 xhigh ranks first with an Intelligence Index of 60, and GPT-5.5 high ranks second with 59.[
5]
-
Claude Opus 4.7 is close behind on that same aggregate measure: Claude Opus 4.7 Adaptive Reasoning Max Effort ranks third with an Intelligence Index of 57.[
5]
-
DeepSeek V4 Pro has the clearest disclosed coding/SWE benchmark profile in the supplied evidence: 93.5% LiveCodeBench, Codeforces 3206, 80.6% SWE-Bench Verified, and 76.2% SWE-Bench Multilingual.[
6]
-
Kimi K2.6 is described as an “open-source flagship” agent-coding model in the launch/news evidence, but the supplied evidence does not provide numeric benchmark scores for Kimi K2.6.[
1]
-
DeepSeek V4 is materially cheaper than GPT-5.5 in the pricing evidence: DeepSeek V4 is listed at $1.74 per 1M input tokens and $3.48 per 1M output tokens, while GPT-5.5 is listed at $5 per 1M input tokens and $30 per 1M output tokens, with both shown as 1M-context models.[
4]
-
DeepSeek V4 Flash is far cheaper than Kimi K2.6 in the direct pricing comparison: DeepSeek V4 Flash is listed at $0.14 per 1M input tokens, $0.28 per 1M output tokens, and $0.18 blended, while Kimi K2.6 is listed at $0.95 per 1M input tokens, $4.00 per 1M output tokens, and $1.71 blended.[
3]
-
The supplied evidence treats DeepSeek V4 as a family with multiple variants, including V4 Flash and V4 Pro, so comparisons depend on which variant is meant.[
2][
3][
6]
Benchmark and capability comparison
| Area | GPT-5.5 | Claude Opus 4.7 | DeepSeek V4 | Kimi K2.6 |
|---|---|---|---|---|
| Aggregate Intelligence Index | 60 for GPT-5.5 xhigh; 59 for GPT-5.5 high.[ | 57 for Claude Opus 4.7 Adaptive Reasoning Max Effort.[ | No numeric Intelligence Index for DeepSeek V4 is provided in the supplied evidence. | No numeric Intelligence Index for Kimi K2.6 is provided in the supplied evidence. |
| Coding / SWE benchmarks | No exact coding benchmark scores are provided in the supplied evidence. | The launch evidence says Claude Opus 4.7 has improved programming and a threefold vision upgrade, but no exact benchmark numbers are provided.[ | DeepSeek V4 Pro is listed with 93.5% LiveCodeBench, Codeforces 3206, 80.6% SWE-Bench Verified, and 76.2% SWE-Bench Multilingual.[ | Kimi K2.6 is positioned as an open-source flagship agent-coding model, but no exact benchmark numbers are provided.[ |
| Context window evidence | GPT-5.5 is listed with a 1M context window in the pricing comparison.[ | The supplied pricing snippet does not clearly provide Claude Opus 4.7’s context window. | DeepSeek V4 is listed with a 1M context window in one comparison, and DeepSeek V4 Flash / Pro are also described as 1M-context options in enterprise guidance.[ | No context-window figure for Kimi K2.6 is provided in the supplied evidence. |
| Pricing evidence | $5 per 1M input tokens and $30 per 1M output tokens.[ | $5 per 1M input tokens is visible in the supplied snippet, but the output price is truncated.[ | DeepSeek V4 is listed at $1.74 per 1M input tokens and $3.48 per 1M output tokens; DeepSeek V4 Flash is listed at $0.14 input, $0.28 output, and $0.18 blended.[ | Kimi K2.6 is listed at $0.95 per 1M input tokens, $4.00 per 1M output tokens, and $1.71 blended.[ |
| Best-supported use case from evidence | Highest aggregate intelligence among the four where evidence is available.[ | High-end reasoning close to GPT-5.5 on the available Intelligence Index.[ | Strongest supplied coding/SWE evidence and strong cost positioning, especially for Flash and Pro variants.[ | Potentially strong open-source agent-coding positioning, but benchmark evidence is insufficient.[ |
Pricing and value takeaways
-
On the available aggregate benchmark, GPT-5.5 leads Claude Opus 4.7 by 3 points at the xhigh setting and by 2 points at the high setting.[
5]
-
On the available API pricing comparison, GPT-5.5 costs about 2.9x DeepSeek V4 for input tokens and about 8.6x DeepSeek V4 for output tokens.[
4]
-
In the DeepSeek V4 Flash vs Kimi K2.6 pricing comparison, Kimi K2.6’s blended price of $1.71 per 1M tokens is about 9.5x DeepSeek V4 Flash’s $0.18 blended price.[
3]
-
One enterprise-oriented comparison recommends DeepSeek V4 Flash for high-volume text summarization, customer-service classification, and internal knowledge-base Q&A because of low cost and 1M context.[
2]
-
The same enterprise-oriented comparison recommends DeepSeek V4 Pro for complex document analysis, cross-department workflows, and automated agents because it is described as lower-cost than closed flagship models while offering high-end open-weight capability and 1M context.[
2]
Evidence notes
-
The strongest single benchmark source in the supplied evidence is the Intelligence Index listing, which ranks GPT-5.5 xhigh first at 60, GPT-5.5 high second at 59, and Claude Opus 4.7 Adaptive Reasoning Max Effort third at 57.[
5]
-
The strongest task-level benchmark evidence is for DeepSeek V4 Pro, because it includes exact coding and software-engineering metrics rather than only positioning language.[
6]
-
The Kimi K2.6 evidence is mostly launch positioning and pricing, not benchmark results.[
1][
3]
-
A user post describes four one-shot head-to-head experiments comparing Codex on GPT-5.5 with Claude Code on Opus 4.7, but the supplied snippet does not provide the outcomes or benchmark scores.[
31]
-
There is conflicting or variant-specific DeepSeek context/pricing evidence: one comparison lists DeepSeek V4 with a 1M context window, while another provider listing for DeepSeek V4 Pro shows 256K max tokens and 66K max output tokens.[
4][
7]
Limitations / uncertainty
-
Insufficient evidence for a full, comprehensive benchmark comparison across Claude Opus 4.7, GPT-5.5, DeepSeek V4, and Kimi K2.6.
-
Insufficient evidence to rank DeepSeek V4 or Kimi K2.6 against GPT-5.5 and Claude Opus 4.7 on the same aggregate Intelligence Index, because the supplied excerpt only provides numeric Intelligence Index scores for GPT-5.5 and Claude Opus 4.7 among the requested models.[
5]
-
Insufficient evidence to compare all four models on the same coding benchmarks, because only DeepSeek V4 Pro has detailed numeric coding/SWE benchmark scores in the supplied evidence.[
6]
-
Insufficient evidence to compare multimodal performance across all four models, because the supplied evidence only includes a launch-positioning claim that Claude Opus 4.7 has a threefold vision upgrade and does not provide comparable multimodal benchmark numbers for the others.[
1]
Summary
GPT-5.5 has the strongest supplied aggregate benchmark result, with Intelligence Index scores of 60 and 59 depending on reasoning setting.[5] Claude Opus 4.7 is close behind at 57 and is the only other requested model with a numeric aggregate score in the supplied evidence.[
5] DeepSeek V4 Pro has the best-supported coding/SWE benchmark profile, while DeepSeek V4 Flash and V4 Pro appear especially strong on cost and long-context enterprise use cases.[
2][
3][
6] Kimi K2.6 may be competitively positioned as an open-source agent-coding model, but the supplied evidence does not include enough numeric benchmark data to verify how it compares against GPT-5.5, Claude Opus 4.7, or DeepSeek V4.[
1][
3]
People also ask
What is the short answer to "Research benchmarks of Claude Opus 4.7, GPT-5.5, DeepSeek V4, Kimi K2.6 and compare as comprehensively as possible"?
GPT-5.5 is the best-supported leader on the only cross-model aggregate benchmark available here: GPT-5.5 xhigh ranks first with an Intelligence Index of 60, and GPT-5.5 high ranks second with 59.
What are the key points to validate first?
GPT-5.5 is the best-supported leader on the only cross-model aggregate benchmark available here: GPT-5.5 xhigh ranks first with an Intelligence Index of 60, and GPT-5.5 high ranks second with 59. Claude Opus 4.7 is close behind on that same aggregate measure: Claude Opus 4.7 Adaptive Reasoning Max Effort ranks third with an Intelligence Index of 57.
What should I do next in practice?
DeepSeek V4 Pro has the clearest disclosed coding/SWE benchmark profile in the supplied evidence: 93.5% LiveCodeBench, Codeforces 3206, 80.6% SWE-Bench Verified, and 76.2% SWE-Bench Multilingual.
Which related topic should I explore next?
Continue with "Research & compare Claude Code vs OpenAI Codex as comprehensively as possible" for another angle and extra citations.
Open related pageWhat should I compare this against?
Cross-check this answer against "Deep research & compare GPT-5.5, Claude Opus 4.7, Kimi K2.6, DeepSeek V4".
Open related pageContinue your research
Sources
- [1] Compare DeepSeek V4 Flash (Reasoning, High Effort) vs Kimi K2.6 | AI Model Comparisonllmbase.ai
Metric DeepSeek logo De DeepSeek V4 Flash (Reasoning, High Effort) DeepSeek Kimi logo Ki Kimi K2.6 Kimi --- Pricing per 1M tokens Input Cost $0.14/1M $0.95/1M Output Cost $0.28/1M $4.00/1M Blended (3:1) $0.18/1M $1.71/1M Specifications Organization DeepSeek...
- [2] DeepSeek V4 Pro (Reasoning, High Effort) vs Kimi K2.6: Model Comparisonartificialanalysis.ai
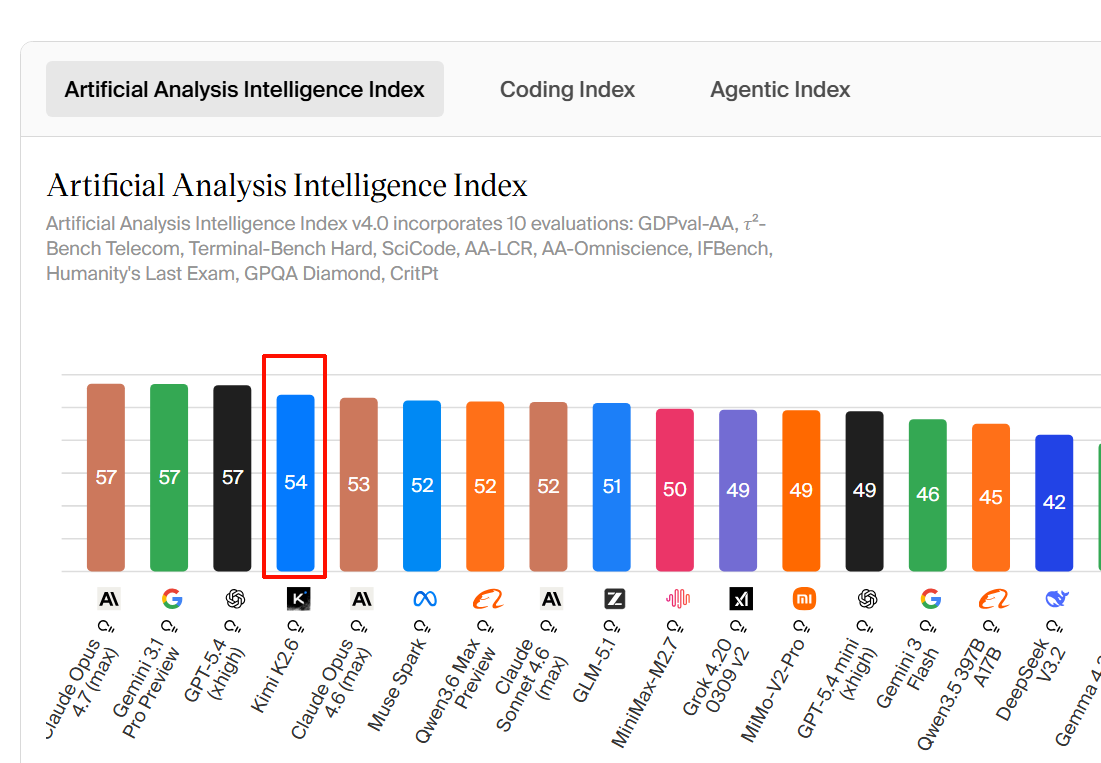
What are the top AI models? The top AI models by Intelligence Index are: 1. GPT-5.5 (xhigh) (60), 2. GPT-5.5 (high) (59), 3. Claude Opus 4.7 (Adaptive Reasoning, Max Effort) (57), 4. Gemini 3.1 Pro Preview (57), 5. GPT-5.4 (xhigh) (57). Which is the fastest...
- [3] DeepSeek V4 Pro vs Kimi K2.6 - AI Model Comparison | OpenRouteropenrouter.ai
Ready Output will appear here... Pricing Input$0.7448 / M tokens Output$4.655 / M tokens Images– – Features Input Modalities text, image Output Modalities text Quantization int4 Max Tokens (input + output)256K Max Output Tokens 66K Stream cancellation Suppo...
- [4] DeepSeek V4 vs Claude Opus 4.6 vs GPT-5.4: Compararea modelelor AI pentru programare (2026) | NxCodenxcode.io
Diferență de cost de 50x: Prețul API pentru DeepSeek V4 ( $0.28/M input) este de aproximativ 50x mai ieftin dect Claude Opus 4.6 ($15/M input), ceea ce îl face cștigătorul clar pentru echipele sensibile la costuri. Claude Opus conduce în benchmark-urile ver...
- [5] DeepSeek V4 vs Claude Opus 4.6 vs GPT-5.4: השוואת מודלי AI לתכנות (2026) | NxCodenxcode.io
השוואת תמחור כאן ההשוואה הופכת לדרמטית. מודל התמחור של DeepSeek שונה מהותית מזה של ספקי המודלים הסגורים. קטגוריית עלות DeepSeek V4 Claude Opus 4.6 GPT-5.4 --- --- קלט (לכל 1M tokens) $0.28 $15.00 $10.00 פלט (לכל 1M tokens) $1.10 $75.00 $30.00 תוספת תשלום על...
- [6] DeepSeek V4 vs Claude Opus 4.6 vs GPT-5.4: השוואת מודלי AI לתכנות (2026) | NxCodenxcode.io
Perbedaan biaya 50x: DeepSeek V4 API pricing ( $0.28/M input) sekitar 50x lebih murah daripada Claude Opus 4.6 ($15/M input), menjadikannya pemenang yang jelas bagi tim yang sensitif terhadap biaya. Claude Opus memimpin pada verified benchmarks: 80.8% SWE-b...
- [7] GPT-5.5 vs Claude Opus 4.7: Pricing, Speed, Benchmarks - LLM Statsllm-stats.com
Reasoning & knowledge Benchmark GPT-5.5 Opus 4.7 Lead --- --- GPQA Diamond 93.6% 94.2% Opus +0.6 HLE (no tools) 41.4% 46.9% Opus +5.5 HLE (with tools) 52.2% 54.7% Opus +2.5 The HLE no-tools margin (+5.5pp) is the most informative entry in the table because...
- [8] GPT-5.5 vs Claude Opus 4.7: Real-World Coding Performance ...mindstudio.ai
SWE-Bench and Coding Tasks On SWE-Bench Verified — the standard benchmark for evaluating real GitHub issue resolution — both models score competitively at the top of the 2026 leaderboard. GPT-5.5 holds a slight edge on problems requiring precise tool use an...
- [9] OpenAI's GPT-5.5 vs Claude Opus 4.7: Which is better? | Mashablemashable.com
Thanks for signing up! SWE-Bench Pro: GPT-5.5 scored 58.6; Opus 4.7 scored 64.3 percent Terminal-Bench 2.0: GPT-5.5 scored 82.7 percent; Opus 4.7 scored 69.4 percent Humanity's Last Exam: GPT-5.5 scored 40.6 percent; Opus 4.7 scored 31.2 percent\ Humanity's...
- [10] DeepSeek V4 vs GPT-5.4 vs Claude Opus 4.6 (April 2026)evolink.ai
Max output 384K 384K 128K 128K Thinking mode Supported Supported Supported via reasoning effort Supported via adaptive / extended thinking Tool calls Supported Supported Supported Supported Practical status Best low-cost V4 route Best higher-intelligence V4...
- [11] I reviewed how DeepSeek V4-Pro, Kimi 2.6, Opus 4.6, and Opus 4.7 ...news.ycombinator.com
ozgune 1 day ago parent context favorite on: DeepSeek v4 I reviewed how DeepSeek V4-Pro, Kimi 2.6, Opus 4.6, and Opus 4.7 across the same AI benchmarks. All results are for Max editions, except for Kimi. Summary: Opus 4.6 forms the baseline all three are tr...
- [12] I Tested GPT 5.5 vs Opus 4.7: What You Need to Know OpenAI just ...linkedin.com
I Tested GPT 5.5 vs Opus 4.7: What You Need to Know OpenAI just dropped GPT 5.5. The benchmarks look strong against Opus 4.7. But benchmarks only tell part of the story. So I ran 4 head-to-head experiments. Codex on GPT 5.5. Claude Code on Opus 4.7. Same pr...
- [13] Kimi K2.6 上线:开源旗舰 Agent 编程登顶 - API易文档中心docs.apiyi.com
Kimi K2.6 上线:开源旗舰 Agent 编程登顶 DeepSeek V4-Pro / V4-Flash 上线:百万上下文 + 开源 SOTA OpenAI gpt-image-2 正式上线:原生 4K + 降价 30% gpt-image-2-all 上线:$0.03/张 GPT 官逆图像模型 Claude Opus 4.7 重磅上线:编程再进化,视觉能力三倍升级 GLM-5.1 上线:智谱开源最强编程 Agent 模型 Qwen3.6-Plus 上线:阿里千问最强编程 Agent 模型 Gemini...
- [14] 【收費比拼】DeepSeek V4 發布後 企業如何挑選 LLM ? 一文比較 GPT、Claude、Gemini 與開源 LLM 收費、智力、應用場景unwire.pro
企業需求 建議模型 原因 --- 大量文字摘要、客服分類、內部知識庫問答 DeepSeek V4 Flash 成本最低,1M context,適合大量低風險文字任務 大量多模態任務,例如圖片、PDF、影片、搜尋 grounding Gemini 3.1 Flash-Lite / Gemini 3 Flash 成本仍低,但比純文字低價模型更適合 Google 多模態與搜尋生態 複雜文件分析、跨部門流程、自動化 agent DeepSeek V4 Pro 成本低於閉源旗艦,但具備高階開源權重能力與 1M cont...
- [15] DeepSeek V4 is here: How it compares to ChatGPT, Claude, Geminimashable.com
Here's how the API pricing compares: DeepSeek V4 costs $1.74 per 1 million input tokens and $3.48 per 1 million output tokens (1 million context window) GPT-5.5 costs at $5 per 1 million input tokens and $30 per 1 million output tokens (1 million context wi...
- [16] DeepSeek-V4 arrives with near state-of-the-art intelligence at 1/6th ...venturebeat.com
BenchmarkDeepSeek-V4-Pro-MaxGPT-5.5GPT-5.5 Pro, where shownClaude Opus 4.7Best result among these GPQA Diamond90.1%93.6%—94.2%Claude Opus 4.7 Humanity’s Last Exam, no tools37.7%41.4%43.1%46.9%Claude Opus 4.7 Humanity’s Last Exam, with tools48.2%52.2%57.2%54...
- [17] Introducing Claude Opus 4.7 - Anthropicanthropic.com
Image 7: logo Based on our internal research-agent benchmark, Claude Opus 4.7 has the strongest efficiency baseline we’ve seen for multi-step work. It tied for the top overall score across our six modules at 0.715 and delivered the most consistent long-cont...
- [18] Kimi K2.6 Tested: Does It Beat Claude and GPT-5? | Lorka AIlorka.ai
Benchmark What it tests Kimi K2.6 GPT-5.4 Opus 4.6 Gemini 3.1 Pro --- --- --- HLE-Full (with tools) Agentic reasoning with tool use 54.0% 52.1% 53.0% 51.4% DeepSearchQA (F1) Research retrieval and synthesis 92.5% 78.6% 91.3% 81.9% SWE-Bench Pro Multi-file c...
- [19] Kimi K2.6 vs Claude Opus 4.6 vs GPT-5.4 - Verdent AIverdent.ai
Benchmark K2.6 Claude Opus 4.6 GPT-5.4 Notes --- --- SWE-Bench Pro 58.60% 53.40% 57.70% Moonshot in-house harness; SEAL mini-swe-agent puts GPT-5.4 at 59.1%, Opus 4.6 at 51.9% SWE-Bench Verified 80.20% 80.80% 80% Tight cluster; Opus 4.7 now leads at 87.6% T...
- [20] 是夯爆了还是拉完了?Deepseek V4第一波测评来了(附排行榜)-36氪36kr.com
模型评测平台Arena.ai在V4发布当日宣布,DeepSeek V4 Pro(思考模式)在其代码竞技场中排名开源模型第3位,综合排名第14位,并将此次发布定性为"相较DeepSeek V3.2的重大飞跃"。Arena.ai同时测试了V4 Flash,两款模型均支持100万token上下文。 Vals AI的评测结果更具看点。该平台表示,DeepSeek V4在其Vibe Code Benchmark中"以压倒性优势"成为开源权重模型第一,不仅超越第2名Kimi K2.6,更击败Gemini 3.1 Pro等...
- [21] AI Arms Race Accelerates With New Models from OpenAI ... - CNETcnet.com
Fullscreen This is a modal window. Beginning of dialog window. Escape will cancel and close the window. Text Color Opacity Text Background Color Opacity Caption Area Background Color Opacity Font Size Text Edge Style Font Family Reset Done Close Modal Dialo...
- [22] We Gave Claude Opus 4.7 and Kimi K2.6 the Same Workflow ...blog.kilo.ai
Where Open-Weight Models Stand Right Now This test sits inside a pattern we’ve been tracking for a while. MiniMax M2.7 matched Claude Opus 4.6’s detection rate on our last three-part benchmark. GLM-5.1 scored five points behind Claude Opus 4.6 on our job qu...
- [23] Changelog | Artificial Analysisartificialanalysis.ai
Intelligence Index: 34 AA-Omniscience: -51 Qwen3.6 27B (Reasoning) Qwen3.6 27B (Reasoning) Intelligence Index: 46 AA-Omniscience: -20 DeepSeek V4 Flash (Reasoning, Max Effort) on DeepSeek DeepSeek V4 Flash (Reasoning, Max Effort) on DeepSeek DeepSeek V4 Fla...
- [24] DeepSeek V4 vs Claude vs GPT-5.4: A 38-Task Benchmark ... - FundaAIfundaai.substack.com
As of time of publication, GPT-5.5 has not yet officially released its API. Testing solely through Codex 5.5 may not fully reflect the complete performance of the API. We have currently only conducted urgent testing on DeepSeek V4, and will include GPT-5.5...
- [25] DeepSeek V4 Pro API - Together AItogether.ai
Coding & Software Engineering: • 93.5% LiveCodeBench and Codeforces 3206 for competitive and production code generation • 80.6% SWE-Bench Verified for autonomous software engineering across repositories • 76.2% SWE-Bench Multilingual for cross-language soft...
- [26] deepseek-ai/DeepSeek-V4-Pro - Hugging Facehuggingface.co
Opus-4.6 Max GPT-5.4 xHigh Gemini-3.1-Pro High K2.6 Thinking GLM-5.1 Thinking DS-V4-Pro Max :---: :---: :---: Knowledge & Reasoning MMLU-Pro (EM) 89.1 87.5 91.0 87.1 86.0 87.5 SimpleQA-Verified (Pass@1) 46.2 45.3 75.6 36.9 38.1 57.9 Chinese-SimpleQA (Pass@1...
- [27] DeepSeek-V4 Pro - DocsBot AIdocsbot.ai
SWE-Bench Multilingual Multilingual version of SWE-Bench evaluating software engineering performance across languages 76.2% Resolved, Think Max Source MCP-Atlas Tool-use benchmark focused on MCP (Model Context Protocol) tasks; typically reported on a public...
- [28] DeepSeek-V4-Pro - DeepInfradeepinfra.com
Benchmark (Metric) Opus-4.6 Max GPT-5.4 xHigh Gemini-3.1-Pro High K2.6 Thinking GLM-5.1 Thinking DS-V4-Pro Max --- --- --- Knowledge & Reasoning MMLU-Pro (EM) 89.1 87.5 91.0 87.1 86.0 87.5 SimpleQA-Verified (Pass@1) 46.2 45.3 75.6 36.9 38.1 57.9 Chinese-Sim...
- [29] DeepSeek-V4-Pro-Max: Pricing, Benchmarks & Performancellm-stats.com
SWE-Bench ProView → 11 of 11 Image 35: LLM Stats Logo SWE-Bench Pro is an advanced version of SWE-Bench that evaluates language models on complex, real-world software engineering tasks requiring extended reasoning and multi-step problem solving. More 1Image...
- [30] DeepSeek V4: Features, Benchmarks, and Comparisonsdatacamp.com
DeepSeek V4 vs Competitors Over the last week, we’ve seen the release of OpenAI's GPT-5.5 and Anthropic's Claude Opus 4.7. While those models boast top-tier capabilities, especially in long-context reasoning and agentic coding, DeepSeek V4 competes heavily...
- [31] deepseek-v4-pro Model by Deepseek-ai | NVIDIA NIM - NVIDIA Buildbuild.nvidia.com
Benchmark (Metric) V4-Flash Non-Think V4-Flash High V4-Flash Max V4-Pro Non-Think V4-Pro High V4-Pro Max --- --- --- Knowledge & Reasoning MMLU-Pro (EM) 83.0 86.4 86.2 82.9 87.1 87.5 SimpleQA-Verified (Pass@1) 23.1 28.9 34.1 45.0 46.2 57.9 Chinese-SimpleQA...
- [32] Model Drop: DeepSeek V4 - by Jake Handyhandyai.substack.com
+ V4-Pro Max: 80.6% + Opus 4.7: 87.6% + OpenAI didn’t report a GPT-5.5 number on this one Terminal-Bench 2.0 + V4-Pro Max: 67.9% + Opus 4.7: 69.4% + GPT-5.5: 82.7% GPQA Diamond + V4-Pro Max: 90.1% + Opus 4.7: 94.2% BrowseComp + V4-Pro Max: 83.4% + GPT-5.5:...