So sánh một cách toàn diện benchmarks của DeepSeek V4 vs Claude Opus 4.7
Claude Opus 4.7 hiện có lợi thế rõ hơn ở benchmark “software engineering thật” và tác vụ agent dài hơi; DeepSeek V4 mạnh hơn về chi phí/hiệu năng, competitive coding và khả năng mở/triển khai linh hoạt. Tuy nhiên, so...
Claude Opus 4.7 hiện có lợi thế rõ hơn ở benchmark “software engineering thật” và tác vụ agent dài hơi; DeepSeek V4 mạnh hơn về chi phí/hiệu năng, competitive coding và khả năng mở/triển khai linh hoạt. Tuy nhiên, so sánh này chưa thể coi là tuyệt đối vì DeepSeek V4 mới ở dạng preview, nhiều số benchmark đến từ leaderb
Bài học chính
- Claude Opus 4.7 hiện có lợi thế rõ hơn ở benchmark “software engineering thật” và tác vụ agent dài hơi; DeepSeek V4 mạnh hơn về chi phí/hiệu năng, competitive coding và khả năng mở/triển khai linh hoạt. Tuy nhiên, so sánh này chưa thể coi là tuyệt đối vì DeepSeek V4 mới ở dạng preview, nhiều số benc
- Claude Opus 4.7 hiện có lợi thế rõ hơn ở benchmark “software engineering thật” và tác vụ agent dài hơi; DeepSeek V4 mạnh hơn về chi phí/hiệu năng, competitive coding và khả năng mở/triển khai linh hoạt. Tuy nhiên, so sánh này chưa thể coi là tuyệt đối vì DeepSeek V4 mới ở dạng pr
- ## Tóm tắt nhanh
Câu trả lời nghiên cứu
Claude Opus 4.7 hiện có lợi thế rõ hơn ở benchmark “software engineering thật” và tác vụ agent dài hơi; DeepSeek V4 mạnh hơn về chi phí/hiệu năng, competitive coding và khả năng mở/triển khai linh hoạt. Tuy nhiên, so sánh này chưa thể coi là tuyệt đối vì DeepSeek V4 mới ở dạng preview, nhiều số benchmark đến từ leaderboard/bên thứ ba chứ chưa có bộ đánh giá độc lập, đồng nhất và ổn định.
Tóm tắt nhanh
| Hạng mục | DeepSeek V4 / V4-Pro | Claude Opus 4.7 | Nhận định |
|---|---|---|---|
| Trạng thái phát hành | DeepSeek công bố V4 Preview và cho biết deepseek-chat/deepseek-reasoner hiện đang route sang deepseek-v4-flash trước khi bị retire sau 24/7/2026 [ | Anthropic có tài liệu chính thức cho Claude Opus 4.7 và giới thiệu “task budgets” cho vòng lặp agentic [ | Claude có tài liệu sản phẩm trưởng thành hơn; DeepSeek V4 còn mang tính preview |
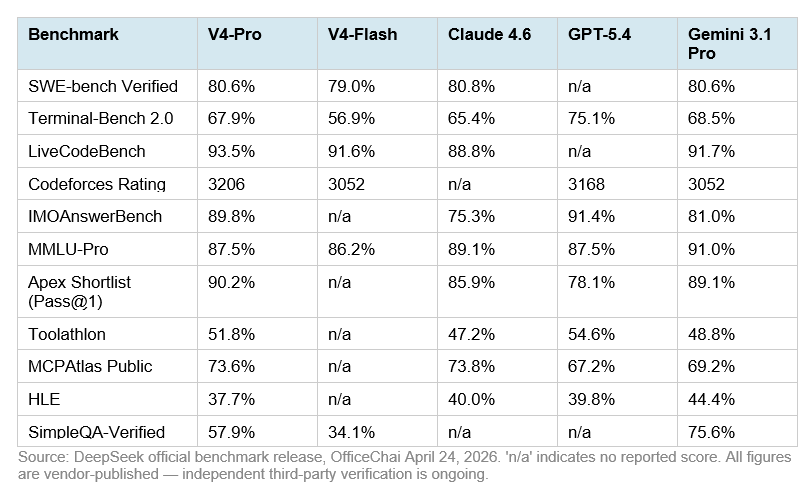
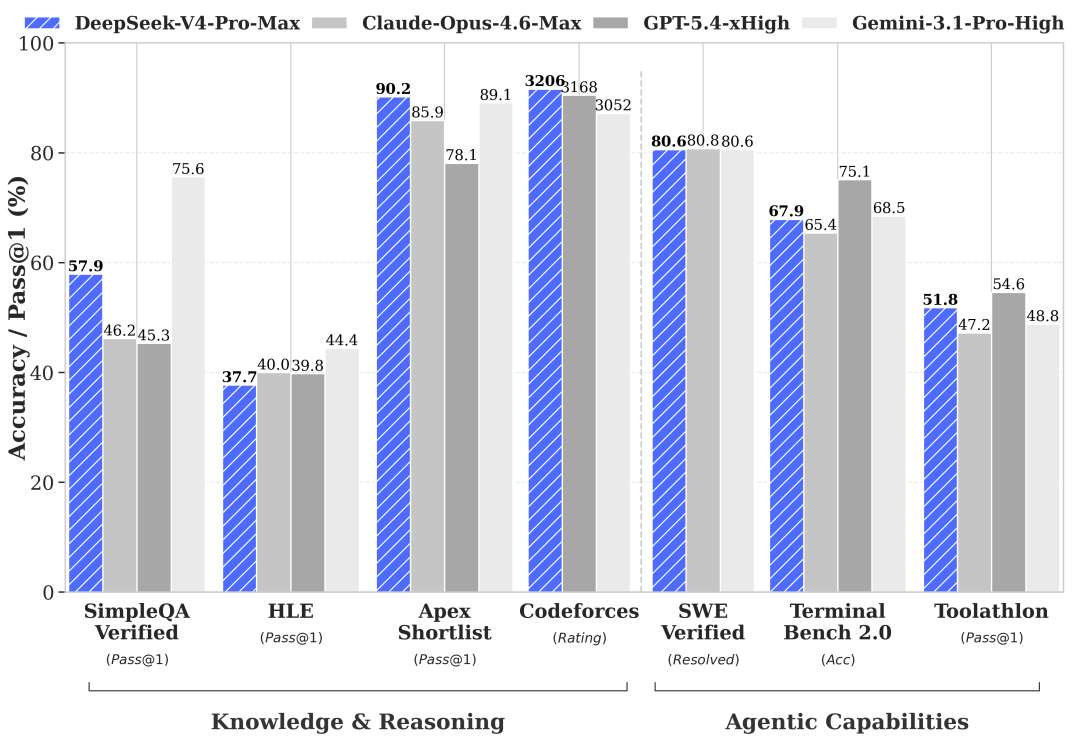
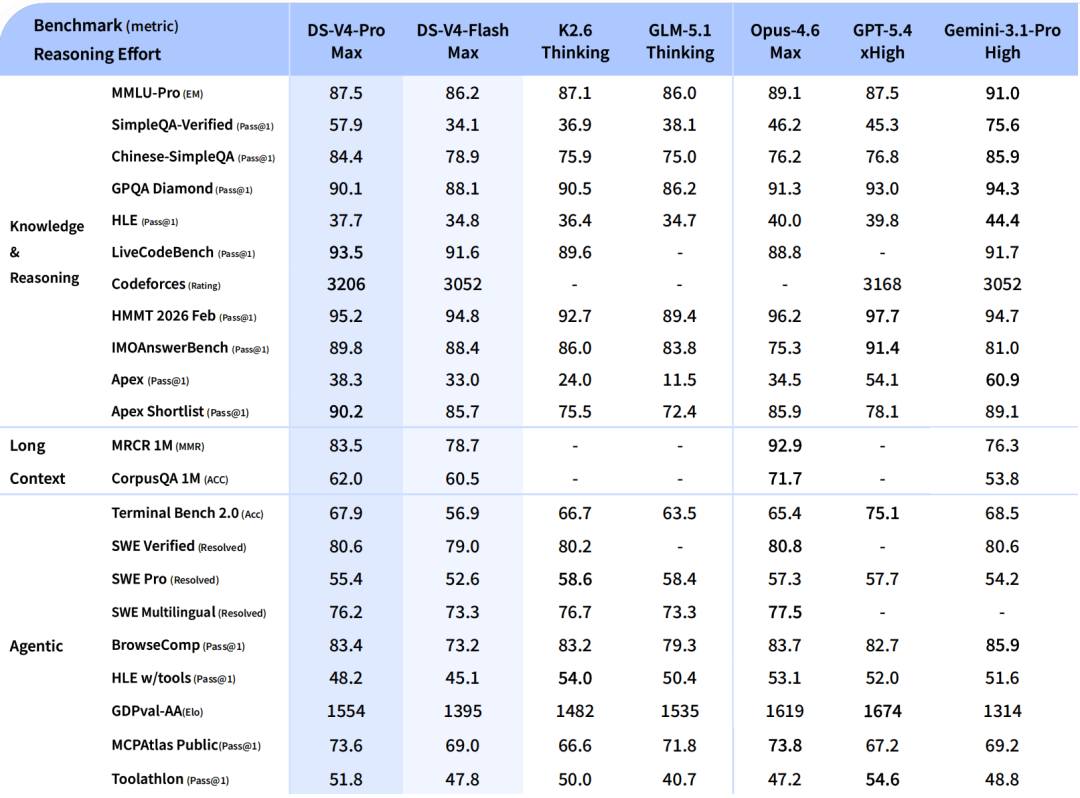
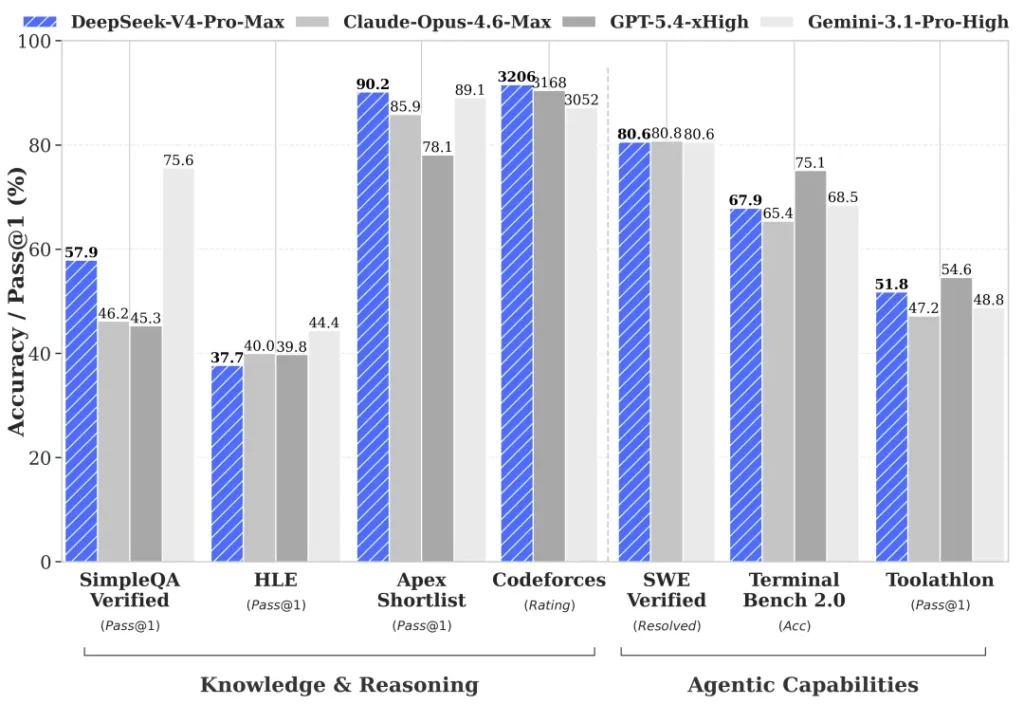
| Software engineering | Theo một so sánh bên thứ ba, V4-Pro đạt 80.6% SWE-bench Verified và 55.4% SWE-bench Pro [ | Cùng nguồn cho Claude Opus 4.7 là 87.6% SWE-bench Verified và 64.3% SWE-bench Pro [ | Opus 4.7 thắng rõ ở sửa lỗi / PR / repo thật |
| Competitive coding | V4-Pro được báo cáo dẫn trên LiveCodeBench 93.5 và Codeforces 3206 [ | Claude Opus 4.7 được báo cáo LiveCodeBench 88.8 trong cùng so sánh [ | DeepSeek V4 mạnh hơn ở coding kiểu contest |
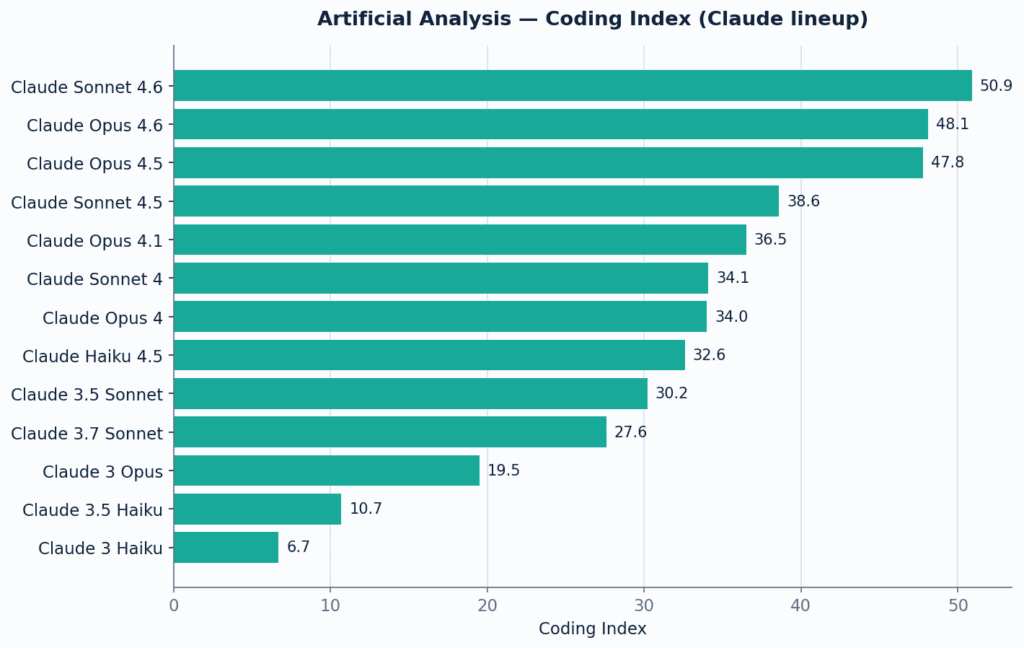
| Benchmark coding nội bộ | Chưa thấy số chính thức đủ rộng từ DeepSeek trong kết quả tìm kiếm; nguồn chính thức chỉ xác nhận preview/routing [ | Anthropic nói Opus 4.7 cải thiện 13% so với Opus 4.6 trên benchmark coding 93 tác vụ của họ [ | Opus có claim chính thức mạnh hơn, nhưng là benchmark nội bộ |
| Lập luận khoa học / GPQA | Một nguồn bên thứ ba ghi V4-Pro đạt GPQA Diamond 90.1% [ | Chưa có số GPQA chính thức rõ trong kết quả tìm kiếm này cho Opus 4.7 | Insufficient evidence để kết luận chắc bên nào thắng GPQA |
| Agentic / tool use | DeepSeek V4 được mô tả là có “excellent agent capability at significantly lower cost” theo phân tích được CNBC trích dẫn [ | Opus 4.7 có “task budgets” để quản lý vòng lặp agent gồm thinking, tool calls, tool results và final output [ | Claude có thiết kế sản phẩm agent rõ hơn; DeepSeek có lợi thế chi phí nếu claim đúng |
| Context | OpenRouter mô tả DeepSeek V4 Pro hỗ trợ context 1M token và là MoE 1.6T tham số, 49B active [ | Một nguồn so sánh cho biết Claude Opus 4.7 có context 1M token [ | Tương đương về context theo nguồn bên thứ ba, nhưng cần kiểm chứng bằng docs pricing/model card chính thức |
| Giá | Một nguồn so sánh nêu Claude Opus 4.7 giá $5 / 1M input token và $25 / 1M output token [ | DeepSeek V4 được nhiều nguồn mô tả là cạnh tranh nhờ chi phí thấp hơn, nhưng số giá cụ thể đáng tin cậy chưa đủ trong kết quả này [ | DeepSeek nhiều khả năng rẻ hơn; chưa đủ số chính thức để tính TCO chuẩn |
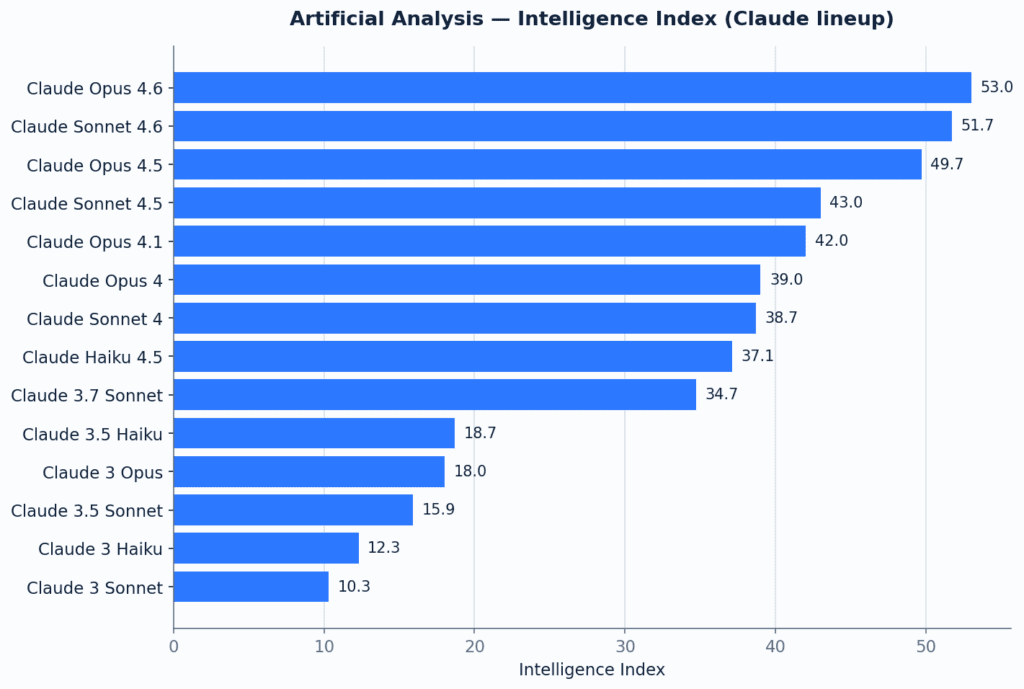
| Leaderboard tổng hợp | BenchLM ghi DeepSeek V4 Pro High có overall score 83 và xếp #15 provisional [ | BenchLM ghi Claude Opus 4.7 overall score 97/100, xếp #2 provisional và #2 verified [ | Theo leaderboard này, Opus 4.7 vượt xa tổng thể |
| Model openness | OpenRouter mô tả DeepSeek V4 Pro là MoE quy mô lớn của DeepSeek [ | Artificial Analysis ghi Anthropic không công bố kích thước/parameter count của Claude Opus 4.7 [ | DeepSeek minh bạch kiến trúc hơn theo nguồn bên thứ ba; Claude đóng hơn |
Kết luận theo từng nhu cầu
-
Chọn Claude Opus 4.7 nếu ưu tiên:
-
Chọn DeepSeek V4 nếu ưu tiên:
-
Điểm chưa chắc chắn:
- Insufficient evidence để kết luận toàn diện về GPQA, multimodal, safety, hallucination, multilingual tiếng Việt và long-context retrieval giữa hai model vì các nguồn hiện có không dùng cùng harness đánh giá.
- Các con số từ BenchLM, OpenRouter, Vellum, o-mega và blog so sánh là nguồn bên thứ ba; đáng dùng để tham khảo xu hướng, nhưng không mạnh bằng benchmark độc lập có mã nguồn, prompt set và cấu hình inference công khai.
Đánh giá cuối
Nếu lấy benchmark kỹ thuật phần mềm làm trọng tâm, Claude Opus 4.7 đang nhỉnh hơn DeepSeek V4. Nếu lấy hiệu năng/giá, competitive coding và khả năng scale chi phí làm trọng tâm, DeepSeek V4 là lựa chọn hấp dẫn hơn. Với production, nên A/B test trên bộ tác vụ thật của bạn thay vì chỉ dựa vào benchmark công khai.
Hỗ trợ hình ảnh









Trao đổi nghiên cứu
Câu hỏi nghiên cứu
So sánh một cách toàn diện benchmarks của DeepSeek V4 vs Claude Opus 4.7
Câu trả lời được trích dẫn
Claude Opus 4.7 hiện có lợi thế rõ hơn ở benchmark “software engineering thật” và tác vụ agent dài hơi; DeepSeek V4 mạnh hơn về chi phí/hiệu năng, competitive coding và khả năng mở/triển khai linh hoạt. Tuy nhiên, so sánh này chưa thể coi là tuyệt đối vì DeepSeek V4 mới ở dạng preview, nhiều số benchmark đến từ leaderboard/bên thứ ba chứ chưa có bộ đánh giá độc lập, đồng nhất và ổn định.
Tóm tắt nhanh
| Hạng mục | DeepSeek V4 / V4-Pro | Claude Opus 4.7 | Nhận định |
|---|---|---|---|
| Trạng thái phát hành | DeepSeek công bố V4 Preview và cho biết deepseek-chat/deepseek-reasoner hiện đang route sang deepseek-v4-flash trước khi bị retire sau 24/7/2026 [ | Anthropic có tài liệu chính thức cho Claude Opus 4.7 và giới thiệu “task budgets” cho vòng lặp agentic [ | Claude có tài liệu sản phẩm trưởng thành hơn; DeepSeek V4 còn mang tính preview |
| Software engineering | Theo một so sánh bên thứ ba, V4-Pro đạt 80.6% SWE-bench Verified và 55.4% SWE-bench Pro [ | Cùng nguồn cho Claude Opus 4.7 là 87.6% SWE-bench Verified và 64.3% SWE-bench Pro [ | Opus 4.7 thắng rõ ở sửa lỗi / PR / repo thật |
| Competitive coding | V4-Pro được báo cáo dẫn trên LiveCodeBench 93.5 và Codeforces 3206 [ | Claude Opus 4.7 được báo cáo LiveCodeBench 88.8 trong cùng so sánh [ | DeepSeek V4 mạnh hơn ở coding kiểu contest |
| Benchmark coding nội bộ | Chưa thấy số chính thức đủ rộng từ DeepSeek trong kết quả tìm kiếm; nguồn chính thức chỉ xác nhận preview/routing [ | Anthropic nói Opus 4.7 cải thiện 13% so với Opus 4.6 trên benchmark coding 93 tác vụ của họ [ | Opus có claim chính thức mạnh hơn, nhưng là benchmark nội bộ |
| Lập luận khoa học / GPQA | Một nguồn bên thứ ba ghi V4-Pro đạt GPQA Diamond 90.1% [ | Chưa có số GPQA chính thức rõ trong kết quả tìm kiếm này cho Opus 4.7 | Insufficient evidence để kết luận chắc bên nào thắng GPQA |
| Agentic / tool use | DeepSeek V4 được mô tả là có “excellent agent capability at significantly lower cost” theo phân tích được CNBC trích dẫn [ | Opus 4.7 có “task budgets” để quản lý vòng lặp agent gồm thinking, tool calls, tool results và final output [ | Claude có thiết kế sản phẩm agent rõ hơn; DeepSeek có lợi thế chi phí nếu claim đúng |
| Context | OpenRouter mô tả DeepSeek V4 Pro hỗ trợ context 1M token và là MoE 1.6T tham số, 49B active [ | Một nguồn so sánh cho biết Claude Opus 4.7 có context 1M token [ | Tương đương về context theo nguồn bên thứ ba, nhưng cần kiểm chứng bằng docs pricing/model card chính thức |
| Giá | Một nguồn so sánh nêu Claude Opus 4.7 giá $5 / 1M input token và $25 / 1M output token [ | DeepSeek V4 được nhiều nguồn mô tả là cạnh tranh nhờ chi phí thấp hơn, nhưng số giá cụ thể đáng tin cậy chưa đủ trong kết quả này [ | DeepSeek nhiều khả năng rẻ hơn; chưa đủ số chính thức để tính TCO chuẩn |
| Leaderboard tổng hợp | BenchLM ghi DeepSeek V4 Pro High có overall score 83 và xếp #15 provisional [ | BenchLM ghi Claude Opus 4.7 overall score 97/100, xếp #2 provisional và #2 verified [ | Theo leaderboard này, Opus 4.7 vượt xa tổng thể |
| Model openness | OpenRouter mô tả DeepSeek V4 Pro là MoE quy mô lớn của DeepSeek [ | Artificial Analysis ghi Anthropic không công bố kích thước/parameter count của Claude Opus 4.7 [ | DeepSeek minh bạch kiến trúc hơn theo nguồn bên thứ ba; Claude đóng hơn |
Kết luận theo từng nhu cầu
-
Chọn Claude Opus 4.7 nếu ưu tiên:
-
Chọn DeepSeek V4 nếu ưu tiên:
-
Điểm chưa chắc chắn:
- Insufficient evidence để kết luận toàn diện về GPQA, multimodal, safety, hallucination, multilingual tiếng Việt và long-context retrieval giữa hai model vì các nguồn hiện có không dùng cùng harness đánh giá.
- Các con số từ BenchLM, OpenRouter, Vellum, o-mega và blog so sánh là nguồn bên thứ ba; đáng dùng để tham khảo xu hướng, nhưng không mạnh bằng benchmark độc lập có mã nguồn, prompt set và cấu hình inference công khai.
Đánh giá cuối
Nếu lấy benchmark kỹ thuật phần mềm làm trọng tâm, Claude Opus 4.7 đang nhỉnh hơn DeepSeek V4. Nếu lấy hiệu năng/giá, competitive coding và khả năng scale chi phí làm trọng tâm, DeepSeek V4 là lựa chọn hấp dẫn hơn. Với production, nên A/B test trên bộ tác vụ thật của bạn thay vì chỉ dựa vào benchmark công khai.
Người ta cũng hỏi
Câu trả lời ngắn gọn cho "So sánh một cách toàn diện benchmarks của DeepSeek V4 vs Claude Opus 4.7" là gì?
Claude Opus 4.7 hiện có lợi thế rõ hơn ở benchmark “software engineering thật” và tác vụ agent dài hơi; DeepSeek V4 mạnh hơn về chi phí/hiệu năng, competitive coding và khả năng mở/triển khai linh hoạt. Tuy nhiên, so sánh này chưa thể coi là tuyệt đối vì DeepSeek V4 mới ở dạng preview, nhiều số benc
Những điểm chính cần xác nhận đầu tiên là gì?
Claude Opus 4.7 hiện có lợi thế rõ hơn ở benchmark “software engineering thật” và tác vụ agent dài hơi; DeepSeek V4 mạnh hơn về chi phí/hiệu năng, competitive coding và khả năng mở/triển khai linh hoạt. Tuy nhiên, so sánh này chưa thể coi là tuyệt đối vì DeepSeek V4 mới ở dạng preview, nhiều số benc Claude Opus 4.7 hiện có lợi thế rõ hơn ở benchmark “software engineering thật” và tác vụ agent dài hơi; DeepSeek V4 mạnh hơn về chi phí/hiệu năng, competitive coding và khả năng mở/triển khai linh hoạt. Tuy nhiên, so sánh này chưa thể coi là tuyệt đối vì DeepSeek V4 mới ở dạng pr
Tôi nên làm gì tiếp theo trong thực tế?
## Tóm tắt nhanh
Tôi nên khám phá chủ đề liên quan nào tiếp theo?
Tiếp tục với "So sánh một cách toàn diện benchmarks của DeepSeek V4 vs GPT-5.5" để có góc nhìn khác và trích dẫn bổ sung.
Mở trang liên quanTôi nên so sánh điều này với cái gì?
Kiểm tra chéo câu trả lời này với "So sánh một cách toàn diện benchmarks của GPT-5.5 vs Claude Opus 4.7".
Mở trang liên quanTiếp tục nghiên cứu của bạn
Nguồn
- [1] China's DeepSeek releases preview of long-awaited V4 model as AI ...cnbc.com
According to Counterpoint’s principal AI analyst, Wei Sun, V4′s benchmark profile suggests it could offer “excellent agent capability at significantly lower cost.” Opt-Out IconYour Privacy Choices CA Notice Terms of Service © 2026 Versant Media, LLC. All Ri...
- [2] DeepSeek V4 AI Model Launch Guide 2026: What You Need to Knowvertu.com
10. What You Need to Know for 2026 As DeepSeek V4 launches in 2026, understanding its capabilities is crucial. Developers, businesses, and researchers must grasp its architecture, features, and competitive edge. This knowledge is key to navigating the evolv...
- [3] DeepSeek V4 Preview Releaseapi-docs.deepseek.com
⚠️ Note: deepseek-chat & deepseek-reasoner will be fully retired and inaccessible after Jul 24th, 2026, 15:59 (UTC Time). (Currently routing to deepseek-v4-flash non-thinking/thinking). Image 7 🔹 Amid recent attention, a quick reminder: please rely only on...
- [4] DeepSeek V4 Preview: The Complete 2026 Guide - o-mega | AIo-mega.ai
On GPQA Diamond, Gemini 3.1 Pro leads at 94.3% versus V4-Pro's 90.1%. On ARC-AGI-2 (a test of genuine novel reasoning), Gemini 3.1 Pro leads at 77.1% versus DeepSeek's comparable scores. These gaps suggest that Google's model maintains an edge on deep scien...
- [5] DeepSeek V4 Pro (High) Benchmarks 2026 - BenchLM.aibenchlm.ai
Tools Tools Alternative FinderLLM Selector QuizCost CalculatorSelf-host vs APIToken CounterData & Embed BlogAdvertise Search⌘K Search BenchLM Search models, benchmarks, rankings, comparisons, providers, and blog posts. @glevd DeepSeek V4 Pro (High) DeepSeek...
- [6] DeepSeek V4 Targets Coding Dominance with Mid-February Launchintrol.com
TL;DR DeepSeek plans to release V4 around February 17, 2026, coinciding with Lunar New Year. The model integrates Engram conditional memory technology published January 13, enabling efficient retrieval from contexts exceeding one million tokens. Internal be...
- [7] DeepSeek V4: Release Date, Announcement, and What to Expect in ...atlascloud.ai
Final Perspective DeepSeek V4 is expected to be a significant step forward—but its real impact will be felt by teams that are operationally ready, not those chasing day-one hype. If current industry expectations hold, developers should plan for: Release win...
- [8] Mapping the DeepSeek V4 Evaluation Suite: A Field Guide to 2026 ...redreamality.com
Mapping the DeepSeek V4 Evaluation Suite: A Field Guide to 2026 LLM Benchmarks Published on April 24, 2026 by Remy When DeepSeek dropped V4-Pro on April 24, 2026, the technical report packed in roughly sixteen distinct benchmarks across coding, reasoning, k...
- [9] DeepSeek-V4-Pro-Max: Pricing, Benchmarks & Performancellm-stats.com
7Image 54DeepSeek-V4-Pro-Max 0.83 8Image 55GPT-5.4 0.83 9Image 56Claude Opus 4.7 0.79 10Image 57GLM-5.1 0.79 Show 16 more Notice missing or incorrect data?Let us know→ Specifications Parameters 1.6T License MIT Training data 32.0T tokens Released Apr 2026 O...
- [10] DeepSeek V4: Architecture, Benchmarks, and API Guide (2026)morphllm.com
Frequently Asked Questions When is DeepSeek V4 releasing? The first week of March 2026, per Financial Times reporting on February 27. The release is timed to China's Two Sessions parliamentary meetings beginning March 4. Prior windows (mid-February, late Fe...
- [11] Deepseek v4 models are out and here are benchmarks !( 4 ...reddit.com
Local hosting needs planning but pays off for privacy and removing token limits. Start by testing a compact quantized model on the target hardware, pick a backend that matches your team needs (easy UX vs deep control), and design predictable latency and mod...
- [12] Deepseek v4: Best Opensource Model Ever? (Fully Tested) - YouTubeyoutube.com
Benchmark Maxxing 0:53 Image 10 Cost Efficiency Cost Efficiency 1:29 Cost Efficiency 1:29 Image 11 Benchmarks Benchmarks 2:09 Benchmarks 2:09 Image 12 MacOS Demo MacOS Demo 2:23 MacOS Demo 2:23 Image 13 DeepSeek Lying... DeepSeek Lying... 3:16 DeepSeek Lyin...
- [13] What's new in Claude Opus 4.7platform.claude.com
Task budgets (beta) Claude Opus 4.7 introduces task budgets. A task budget gives Claude a rough estimate of how many tokens to target for a full agentic loop, including thinking, tool calls, tool results, and final output. The model sees a running countdown...
- [14] Claude Opus 4.7 (max) - Intelligence, Performance & Price Analysisartificialanalysis.ai
Claude Opus 4.7 (Adaptive Reasoning, Max Effort) is a proprietary model and Anthropic has not disclosed the model size or parameter count. How does Claude Opus 4.7 (Adaptive Reasoning, Max Effort) perform on benchmarks? Claude Opus 4.7 (Adaptive Reasoning,...
- [15] Claude Opus 4.7 Benchmark Full Analysis: Empirical Data Leading ...help.apiyi.com
Anthropic officially released Claude Opus 4.7 on April 16, 2026, taking the lead in 7 out of 10 core benchmarks. In this article, we’ll take a deep dive into the core data from the Claude Opus 4.7 benchmark and explore its practical use cases from a real-wo...
- [16] Claude Opus 4.7 Benchmarks 2026: Scores, Rankings & Performancebenchlm.ai
Core Rankings Specialized Use Cases Dashboards Directories Guides & Lists Tools Claude Opus 4.7 According to BenchLM.ai, Claude Opus 4.7 ranks 2 out of 110 models on the provisional leaderboard with an overall score of 97/100. It also ranks 2 out of 14 on t...
- [17] Claude Opus 4.7 Benchmarks Explained - Vellumvellum.ai
Where can I access Claude Opus 4.7? Opus 4.7 is available through the Anthropic API (model name: claude-opus-4-7), Amazon Bedrock, Google Cloud Vertex AI, and Microsoft Foundry. It's also available directly in Vellum, either by plugging in your Anthropic AP...
- [18] Claude Opus 4.7 Review: What's New, What Regressed, and Who ...mindstudio.ai
Image 10 April 23, 2026 Claude Opus 4.7 vs Claude Opus 4.6: What Actually Changed? Claude Opus 4.7 improves software engineering benchmarks by 10% and visual reasoning by 13%, but regresses on agentic search. Here's the full breakdown. Claude Comparisons LL...
- [19] Introducing Claude Opus 4.7 - Anthropicanthropic.com
Image 6: logo On our 93-task coding benchmark, Claude Opus 4.7 lifted resolution by 13% over Opus 4.6, including four tasks neither Opus 4.6 nor Sonnet 4.6 could solve. Combined with faster median latency and strict instruction following, it’s particularly...
- [20] Opus 4.7 Review: Features, Performance & How to Use It (2026 ...aimlapi.com
Try For Free Sign Up Opus 4.7 Review: Features, Performance & How to Use It (2026 Guide) What Is Opus 4.7? Opus 4.7 is Anthropic's latest flagship large language model, released on April 16, 2026, as a direct upgrade to Claude Opus 4.6. It is designed for d...
- [21] Claude Opus 4.7 - Anthropicanthropic.com
Skip to main contentSkip to footer []( Research Economic Futures Commitments Learn News Try Claude Claude Opus 4.7 Image 1: Claude Opus 4.7 Image 2: Claude Opus 4.7 Hybrid reasoning model that pushes the frontier for coding and AI agents, featuring a 1M con...
- [22] Anthropic Promised Claude Opus 4.7 Would Change ... - Towards AIpub.towardsai.net
Anthropic Promised Claude Opus 4.7 Would Change Everything. Here’s What Actually Happened. by Adi Insights and Innovations Apr, 2026 Towards AI Sitemap Open in app Sign up Sign in []( Get app Write Search Sign up Sign in Image 1 Towards AI · Follow publicat...
- [23] Claude Opus 4.7 and Every Anthropic Model Reviewed - Web Wallahwebwallah.in
Claude Opus 4.7 is the best generally available model Anthropic has ever built. But the more interesting story sits just above it – a model so capable that Anthropic has chosen, deliberately and publicly, not to release it to the world. That decision will d...
- [24] Claude Opus 4.7 results: early benchmarks, real-world feedback ...boringbot.substack.com
The Production Gap Claude Opus 4.7 results: early benchmarks, real-world feedback, and is it worth upgrading? Yet another release from Anthropic Hamza Farooq Apr 21, 2026 👋 Hi everyone, I am Hamza. I have 18 years of building large scale ecosystems and I t...
- [25] DeepSeek V4 is here: How it compares to ChatGPT, Claude, Geminimashable.com
Credit: Long Wei/VCG via Getty Images Anything you can do I can do better... That may as well be the motto for the AI arms race, which is unfolding across multiple dimensions in 2026. There's the competition between Silicon Valley AI labs like Anthropic, Op...
- [26] DeepSeek V4 is here: How it compares to ChatGPT, Claude, Geminitech.yahoo.com
DeepSeek V4 is here: How it compares to ChatGPT, Claude, Gemini GPT-5.5 costs at $5 per 1 million input tokens and $30 per 1 million output tokens (1 million context window) Claude Opus 4.7costs at $5 per 1 million input tokens and $25 per 1 million output...
- [27] DeepSeek V4 Pro vs Claude Opus 4.7 - AI Model Comparison | OpenRouteropenrouter.ai
deepseek Context Length 1.05M Reasoning Providers 2 DeepSeek V4 Pro is a large-scale Mixture-of-Experts model from DeepSeek with 1.6T total parameters and 49B activated parameters, supporting a 1M-token context window. It is designed for advanced reasoning,...
- [28] DeepSeek V4 vs Claude Opus 4.7 vs GPT-5.5: Benchmarks & Pricinglushbinary.com
Opus 4.7 leads on SWE-bench Pro (64.3% vs 55.4%) and SWE-bench Verified (87.6% vs 80.6%). V4-Pro leads on LiveCodeBench (93.5 vs 88.8) and Codeforces (3206). Opus is stronger for real-world software engineering; V4-Pro excels at competitive programming. Is...
- [29] DeepSeek-V4 Pro vs Claude Opus 4.7 - DocsBot AIdocsbot.ai
Claude Opus 4.7 Claude Opus 4.7 is Anthropic's most capable generally available Opus model (released April 16, 2026), focused on advanced software engineering, long-horizon autonomy, instruction following, and high-resolution multimodal understanding. It su...
- [30] DeepSeek V4 - Vals AIvals.ai
Benchmarks Models Comparison Model Guide App Reports News About Benchmarks Models Comparison Model Guide App Reports About Release date Models 4/23/2026 DeepSeek DeepSeek V4 4/23/2026 OpenAI GPT 5.5 4/20/2026 Moonshot AI Kimi K2.6 4/16/2026 Anthropic Claude...
- [31] DeepSeek V4 Pro (Reasoning, High Effort) vs Claude Opus 4.7 (Non-reasoning, High Effort): Model Comparisonartificialanalysis.ai
Metric DeepSeek logoDeepSeek V4 Pro (Reasoning, High Effort) Anthropic logoClaude Opus 4.7 (Non-reasoning, High Effort) Analysis --- --- Creator DeepSeek Anthropic Context Window 1000k tokens ( 1500 A4 pages of size 12 Arial font) 1000k tokens ( 1500 A4 pag...
- [32] DeepSeek V4: Features, Benchmarks, and Comparisonsdatacamp.com
DeepSeek V4 vs Competitors Over the last week, we’ve seen the release of OpenAI's GPT-5.5 and Anthropic's Claude Opus 4.7. While those models boast top-tier capabilities, especially in long-context reasoning and agentic coding, DeepSeek V4 competes heavily...
- [33] DeepSeek V4 vs Claude vs GPT-5.4: A 38-Task Benchmark ... - FundaAIfundaai.substack.com
DeepSeek V4 is DeepSeek’s next-generation foundation model, shipped as two variants through the Pandora API: Pro (deeper, slower — optimized for thoroughness) and Flash (faster, more concise — optimized for production throughput). Both support multi-turn co...