So sánh một cách toàn diện benchmarks của DeepSeek V4 vs GPT-5.5
Hiện chưa có đủ bằng chứng công khai, độc lập và đầy đủ để “so sánh toàn diện” benchmark DeepSeek V4 vs GPT 5.5 theo từng bài test chuẩn như MMLU, GPQA, SWE bench, AIME, LiveCodeBench với số liệu ngang hàng. Những gì...
Hiện chưa có đủ bằng chứng công khai, độc lập và đầy đủ để “so sánh toàn diện” benchmark DeepSeek V4 vs GPT 5.5 theo từng bài test chuẩn như MMLU, GPQA, SWE bench, AIME, LiveCodeBench với số liệu ngang hàng. Những gì có thể kết luận chắc hơn là: GPT 5.5 có tài liệu chính thức rõ hơn về API/cấu hình, còn DeepSeek V4 mới
Bài học chính
- Hiện chưa có đủ bằng chứng công khai, độc lập và đầy đủ để “so sánh toàn diện” benchmark DeepSeek V4 vs GPT-5.5 theo từng bài test chuẩn như MMLU, GPQA, SWE-bench, AIME, LiveCodeBench với số liệu ngang hàng. Những gì có thể kết luận chắc hơn là: GPT-5.5 có tài liệu chính thức rõ hơn về API/cấu hình,
- Hiện chưa có đủ bằng chứng công khai, độc lập và đầy đủ để “so sánh toàn diện” benchmark DeepSeek V4 vs GPT-5.5 theo từng bài test chuẩn như MMLU, GPQA, SWE-bench, AIME, LiveCodeBench với số liệu ngang hàng. Những gì có thể kết luận chắc hơn là: GPT-5.5 có tài liệu chính thức rõ
- ## Điểm chắc chắn từ nguồn hiện có
Câu trả lời nghiên cứu
Hiện chưa có đủ bằng chứng công khai, độc lập và đầy đủ để “so sánh toàn diện” benchmark DeepSeek V4 vs GPT-5.5 theo từng bài test chuẩn như MMLU, GPQA, SWE-bench, AIME, LiveCodeBench với số liệu ngang hàng. Những gì có thể kết luận chắc hơn là: GPT-5.5 có tài liệu chính thức rõ hơn về API/cấu hình, còn DeepSeek V4 mới ở dạng preview và các so sánh bên thứ ba hiện chủ yếu từ Artificial Analysis hoặc bài tổng hợp, chưa đủ để coi là bảng benchmark cuối cùng.
Điểm chắc chắn từ nguồn hiện có
-
DeepSeek có trang “DeepSeek-V4 Preview Release” ngày 2026/04/24 trong tài liệu API chính thức, nhưng kết quả tìm kiếm không hiển thị bảng benchmark chi tiết đầy đủ ngay trong snippet [
6].
-
OpenAI API docs liệt kê GPT-5.5 với model ID
gpt-5.5, context window 1M tokens, max output 128K tokens, input price $5/1M tokens và output price $30/1M tokens [1].
-
GPT-5.5 được OpenAI mô tả là “a new class of intelligence for coding and professional work” trong tài liệu API [
1].
-
Artificial Analysis có các trang so sánh DeepSeek V4 Pro/Flash với GPT-5.5 ở nhiều mức reasoning như low, medium, xhigh, nhưng snippet công khai chủ yếu cho thấy thông tin cấu hình như context window thay vì toàn bộ điểm số benchmark [
4][
10][
11].
-
Artificial Analysis ghi nhận DeepSeek V4 Pro là mô hình “open weights” phát hành tháng 4/2026 [
8].
-
DeepSeek V4 Pro và V4 Flash được Artificial Analysis mô tả là có cải thiện về kiến thức nhưng cũng có hallucination rate rất cao trong AA-Omniscience; snippet nêu V4 Pro Max đạt -10, cải thiện 11 điểm so với V3.2 Reasoning, còn V4 Flash Max đạt -23 [
3].
So sánh nhanh theo trục quan trọng
| Trục so sánh | DeepSeek V4 | GPT-5.5 | Nhận định |
|---|---|---|---|
| Trạng thái công khai | Preview chính thức từ DeepSeek [ | Có trong OpenAI API docs [ | GPT-5.5 có thông tin API rõ hơn |
| Mô hình mở | Artificial Analysis gọi V4 Pro là open weights [ | Proprietary/đóng theo hệ sinh thái OpenAI [ | DeepSeek lợi thế nếu cần tự host/tùy biến |
| Context window | Các trang so sánh AA nêu DeepSeek V4 khoảng 1,000k tokens [ | OpenAI docs nêu GPT-5.5 context 1M tokens [ | Gần tương đương về ngữ cảnh |
| Max output | Insufficient evidence từ nguồn chính thức trong kết quả tìm kiếm | 128K tokens theo OpenAI API docs [ | GPT-5.5 có số chính thức rõ hơn |
| Coding/pro work | Insufficient evidence để kết luận thắng-thua benchmark | OpenAI định vị GPT-5.5 cho coding và professional work [ | Chưa đủ số liệu độc lập để xếp hạng chắc chắn |
| Hallucination/knowledge | AA nêu V4 Pro cải thiện knowledge nhưng hallucination rate rất cao [ | Insufficient evidence trong kết quả tìm kiếm để so trực tiếp cùng metric | Cần xem bảng AA đầy đủ hoặc eval độc lập |
| Giá API | Một số bài/press-release nêu giá DeepSeek thấp, nhưng chưa đủ tin cậy để lấy làm kết luận chuẩn [ | $5 input / $30 output mỗi 1M tokens theo OpenAI API docs [ | GPT-5.5 có giá chính thức; DeepSeek cần xác nhận từ bảng giá DeepSeek |
Kết luận thực dụng
-
Nếu bạn cần benchmark “đẹp, ổn định, có hệ sinh thái API, tool calling, file/web/computer use”: GPT-5.5 có lợi thế về tài liệu chính thức và tích hợp API [
1].
-
Nếu bạn cần mô hình open-weight, chi phí có khả năng thấp hơn, hoặc triển khai/tùy biến nội bộ: DeepSeek V4 Pro đáng chú ý hơn, nhưng số liệu benchmark công khai hiện chưa đủ để khẳng định vượt GPT-5.5 toàn diện [
6][
8].
-
Nếu chỉ hỏi “model nào mạnh hơn?”: Insufficient evidence. Các nguồn hiện có chưa cung cấp một bảng benchmark độc lập, đầy đủ, cùng điều kiện chạy cho DeepSeek V4 Pro/Flash và GPT-5.5 trên toàn bộ các bài test quan trọng.
-
Để so sánh nghiêm túc, nên chờ hoặc tự chạy bộ test gồm: GPQA Diamond, MMLU-Pro, AIME 2025/2026, LiveCodeBench, SWE-bench Verified, MMMU, long-context retrieval, tool-use/agentic tasks, multilingual Vietnamese eval, hallucination/factuality và latency/cost trên cùng prompt + cùng mức reasoning.
Hỗ trợ hình ảnh











Trao đổi nghiên cứu
Câu hỏi nghiên cứu
So sánh một cách toàn diện benchmarks của DeepSeek V4 vs GPT-5.5
Câu trả lời được trích dẫn
Hiện chưa có đủ bằng chứng công khai, độc lập và đầy đủ để “so sánh toàn diện” benchmark DeepSeek V4 vs GPT-5.5 theo từng bài test chuẩn như MMLU, GPQA, SWE-bench, AIME, LiveCodeBench với số liệu ngang hàng. Những gì có thể kết luận chắc hơn là: GPT-5.5 có tài liệu chính thức rõ hơn về API/cấu hình, còn DeepSeek V4 mới ở dạng preview và các so sánh bên thứ ba hiện chủ yếu từ Artificial Analysis hoặc bài tổng hợp, chưa đủ để coi là bảng benchmark cuối cùng.
Điểm chắc chắn từ nguồn hiện có
-
DeepSeek có trang “DeepSeek-V4 Preview Release” ngày 2026/04/24 trong tài liệu API chính thức, nhưng kết quả tìm kiếm không hiển thị bảng benchmark chi tiết đầy đủ ngay trong snippet [
6].
-
OpenAI API docs liệt kê GPT-5.5 với model ID
gpt-5.5, context window 1M tokens, max output 128K tokens, input price $5/1M tokens và output price $30/1M tokens [1].
-
GPT-5.5 được OpenAI mô tả là “a new class of intelligence for coding and professional work” trong tài liệu API [
1].
-
Artificial Analysis có các trang so sánh DeepSeek V4 Pro/Flash với GPT-5.5 ở nhiều mức reasoning như low, medium, xhigh, nhưng snippet công khai chủ yếu cho thấy thông tin cấu hình như context window thay vì toàn bộ điểm số benchmark [
4][
10][
11].
-
Artificial Analysis ghi nhận DeepSeek V4 Pro là mô hình “open weights” phát hành tháng 4/2026 [
8].
-
DeepSeek V4 Pro và V4 Flash được Artificial Analysis mô tả là có cải thiện về kiến thức nhưng cũng có hallucination rate rất cao trong AA-Omniscience; snippet nêu V4 Pro Max đạt -10, cải thiện 11 điểm so với V3.2 Reasoning, còn V4 Flash Max đạt -23 [
3].
So sánh nhanh theo trục quan trọng
| Trục so sánh | DeepSeek V4 | GPT-5.5 | Nhận định |
|---|---|---|---|
| Trạng thái công khai | Preview chính thức từ DeepSeek [ | Có trong OpenAI API docs [ | GPT-5.5 có thông tin API rõ hơn |
| Mô hình mở | Artificial Analysis gọi V4 Pro là open weights [ | Proprietary/đóng theo hệ sinh thái OpenAI [ | DeepSeek lợi thế nếu cần tự host/tùy biến |
| Context window | Các trang so sánh AA nêu DeepSeek V4 khoảng 1,000k tokens [ | OpenAI docs nêu GPT-5.5 context 1M tokens [ | Gần tương đương về ngữ cảnh |
| Max output | Insufficient evidence từ nguồn chính thức trong kết quả tìm kiếm | 128K tokens theo OpenAI API docs [ | GPT-5.5 có số chính thức rõ hơn |
| Coding/pro work | Insufficient evidence để kết luận thắng-thua benchmark | OpenAI định vị GPT-5.5 cho coding và professional work [ | Chưa đủ số liệu độc lập để xếp hạng chắc chắn |
| Hallucination/knowledge | AA nêu V4 Pro cải thiện knowledge nhưng hallucination rate rất cao [ | Insufficient evidence trong kết quả tìm kiếm để so trực tiếp cùng metric | Cần xem bảng AA đầy đủ hoặc eval độc lập |
| Giá API | Một số bài/press-release nêu giá DeepSeek thấp, nhưng chưa đủ tin cậy để lấy làm kết luận chuẩn [ | $5 input / $30 output mỗi 1M tokens theo OpenAI API docs [ | GPT-5.5 có giá chính thức; DeepSeek cần xác nhận từ bảng giá DeepSeek |
Kết luận thực dụng
-
Nếu bạn cần benchmark “đẹp, ổn định, có hệ sinh thái API, tool calling, file/web/computer use”: GPT-5.5 có lợi thế về tài liệu chính thức và tích hợp API [
1].
-
Nếu bạn cần mô hình open-weight, chi phí có khả năng thấp hơn, hoặc triển khai/tùy biến nội bộ: DeepSeek V4 Pro đáng chú ý hơn, nhưng số liệu benchmark công khai hiện chưa đủ để khẳng định vượt GPT-5.5 toàn diện [
6][
8].
-
Nếu chỉ hỏi “model nào mạnh hơn?”: Insufficient evidence. Các nguồn hiện có chưa cung cấp một bảng benchmark độc lập, đầy đủ, cùng điều kiện chạy cho DeepSeek V4 Pro/Flash và GPT-5.5 trên toàn bộ các bài test quan trọng.
-
Để so sánh nghiêm túc, nên chờ hoặc tự chạy bộ test gồm: GPQA Diamond, MMLU-Pro, AIME 2025/2026, LiveCodeBench, SWE-bench Verified, MMMU, long-context retrieval, tool-use/agentic tasks, multilingual Vietnamese eval, hallucination/factuality và latency/cost trên cùng prompt + cùng mức reasoning.
Người ta cũng hỏi
Câu trả lời ngắn gọn cho "So sánh một cách toàn diện benchmarks của DeepSeek V4 vs GPT-5.5" là gì?
Hiện chưa có đủ bằng chứng công khai, độc lập và đầy đủ để “so sánh toàn diện” benchmark DeepSeek V4 vs GPT-5.5 theo từng bài test chuẩn như MMLU, GPQA, SWE-bench, AIME, LiveCodeBench với số liệu ngang hàng. Những gì có thể kết luận chắc hơn là: GPT-5.5 có tài liệu chính thức rõ hơn về API/cấu hình,
Những điểm chính cần xác nhận đầu tiên là gì?
Hiện chưa có đủ bằng chứng công khai, độc lập và đầy đủ để “so sánh toàn diện” benchmark DeepSeek V4 vs GPT-5.5 theo từng bài test chuẩn như MMLU, GPQA, SWE-bench, AIME, LiveCodeBench với số liệu ngang hàng. Những gì có thể kết luận chắc hơn là: GPT-5.5 có tài liệu chính thức rõ hơn về API/cấu hình, Hiện chưa có đủ bằng chứng công khai, độc lập và đầy đủ để “so sánh toàn diện” benchmark DeepSeek V4 vs GPT-5.5 theo từng bài test chuẩn như MMLU, GPQA, SWE-bench, AIME, LiveCodeBench với số liệu ngang hàng. Những gì có thể kết luận chắc hơn là: GPT-5.5 có tài liệu chính thức rõ
Tôi nên làm gì tiếp theo trong thực tế?
## Điểm chắc chắn từ nguồn hiện có
Tôi nên khám phá chủ đề liên quan nào tiếp theo?
Tiếp tục với "So sánh một cách toàn diện benchmarks của DeepSeek V4 vs Claude Opus 4.7" để có góc nhìn khác và trích dẫn bổ sung.
Mở trang liên quanTôi nên so sánh điều này với cái gì?
Kiểm tra chéo câu trả lời này với "So sánh một cách toàn diện benchmarks của GPT-5.5 vs Claude Opus 4.7".
Mở trang liên quanTiếp tục nghiên cứu của bạn
Nguồn
- [1] DeepSeek V4 is here: How it compares to ChatGPT, Claude, Geminimashable.com
Credit: Long Wei/VCG via Getty Images Anything you can do I can do better... That may as well be the motto for the AI arms race, which is unfolding across multiple dimensions in 2026. There's the competition between Silicon Valley AI labs like Anthropic, Op...
- [2] DeepSeek V4 Preview: The Complete 2026 Guide - o-mega | AIo-mega.ai
6. Head-to-Head: DeepSeek V4 vs GPT-5.5 The comparison between DeepSeek V4-Pro and GPT-5.5 is the headline matchup, and the nuances matter more than the top-line numbers suggest. GPT-5.5 holds clear advantages in certain areas, DeepSeek V4-Pro leads in othe...
- [3] DeepSeek V4 Pro (Reasoning, High Effort) vs GPT-5.5 (low): Model Comparisonartificialanalysis.ai
Highlights Model Comparison Metric DeepSeek logoDeepSeek V4 Pro (Reasoning, High Effort) OpenAI logoGPT-5.5 (low) Analysis --- --- Creator DeepSeek OpenAI Context Window 1000k tokens ( 1500 A4 pages of size 12 Arial font) 922k tokens ( 1383 A4 pages of size...
- [4] DeepSeek-V4-Pro-Max: Pricing, Benchmarks & Performancellm-stats.com
DeepSeek-V4-Pro-Max: Pricing, Benchmarks & Performance Image 1: LLM Stats LogoLLM Stats Leaderboards Benchmarks Compare Playground Arenas Gateway Services Search⌘K Sign in Toggle theme NEW•NEW•NEW•NEW• What if your agent could make phone calls? CallingBox S...
- [5] From GPT-5.5 to DeepSeek V4: How Developers Are ...cincinnati.com
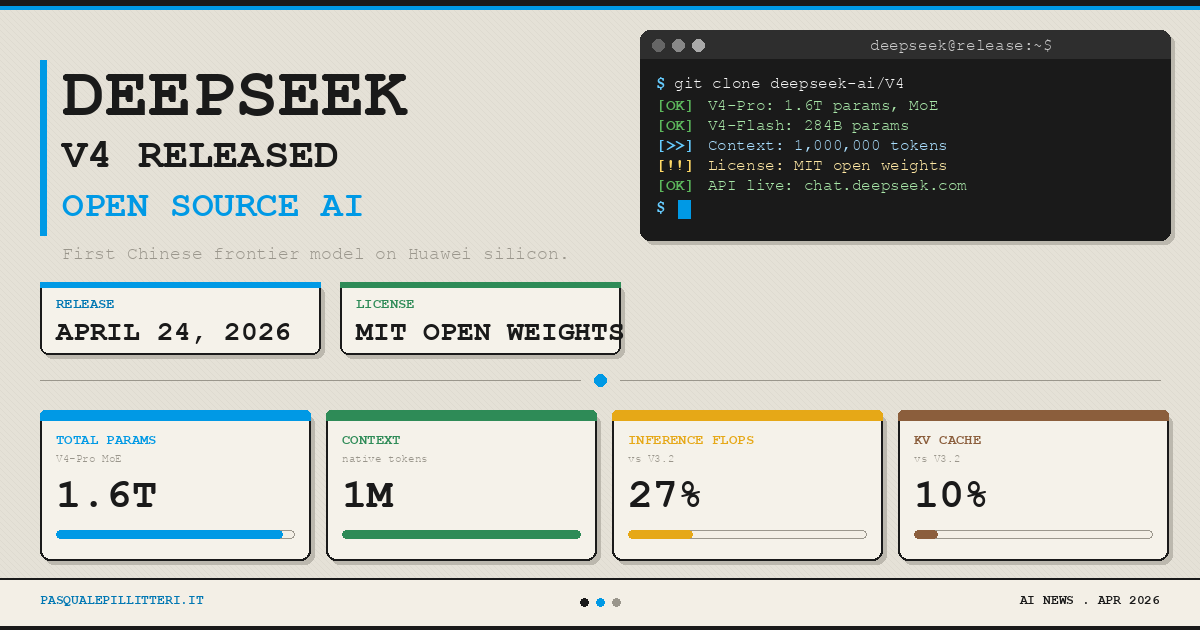
DeepSeek V4 Preview (DeepSeek, April 24, 2026) is the release that may define Q2 2026. The model ships in two variants: V4-Pro (1.6 trillion parameters, 49 billion active, MIT license) and V4-Flash (284 billion parameters, 13 billion active). Priced at $0.1...
- [6] GPT-5.5 (high) - Intelligence, Performance & Price Analysisartificialanalysis.ai
Artificial Analysis GPT-5.5 (high) logo • Proprietarymodel • Released April 2026 GPT-5.5 (high)Intelligence, Performance & Price Analysis Model summary Intelligence Artificial Analysis Intelligence Index 4 out of 4 units for Intelligence. Output tokens per...
- [7] GPT-5.5 (high) Review | Pricing, Benchmarks & Capabilities (2026)designforonline.com
Transform your business & boost efficiency with AI automation, utilising the very latest in LLMs, seamless no code automation options & MCPs Home AI Models GPT-5.5 (high) GPT-5.5 (high) OpenAI GPT-5.5 (high) Analysis Summary GPT-5.5 (high) sits in the Front...
- [8] GPT-5.5 System Card - OpenAI Deployment Safety Hubdeploymentsafety.openai.com
We measure GPT-5.5’s controllability by running CoT-Control, an evaluation suite described in (Yueh-Han, 2026 ) that tracks the model’s ability to follow user instructions about their CoT. CoT-Control includes over 13,000 tasks built from established benchm...
- [9] GPT-5.5 vs DeepSeek-V4 Pro - Detailed Performance & Feature Comparisondocsbot.ai
Feature GPT-5.5 DeepSeek-V4 Pro --- Input Context Window The number of tokens supported by the input context window. 1M API / 400K Codex tokens 1M tokens Maximum Output Tokens The number of tokens that can be generated by the model in a single request. 128K...
- [10] GPT-5.5: Pricing, Benchmarks & Performance - LLM Statsllm-stats.com
GPT-5.5: Pricing, Benchmarks & Performance Image 1: LLM Stats LogoLLM Stats Leaderboards Benchmarks Compare Playground Arenas Gateway Services Search⌘K Sign in Toggle theme NEW•NEW•NEW•NEW• Make AI phone calls with one API call CallingBox Start for free 1....
- [11] China's DeepSeek releases preview of long-awaited V4 model as AI ...cnbc.com
According to Counterpoint’s principal AI analyst, Wei Sun, V4′s benchmark profile suggests it could offer “excellent agent capability at significantly lower cost.” Opt-Out IconYour Privacy Choices CA Notice Terms of Service © 2026 Versant Media, LLC. All Ri...
- [12] DeepSeek V4: Architecture, Benchmarks, and API Guide (2026)morphllm.com
For Coding: How Good Is It? DeepSeek V4 was built with coding as a primary target. According to Reuters and The Information, internal benchmarks show V4 outperforming both Claude and GPT series specifically on extremely long code prompts, which is where the...
- [13] DeepSeek V4 Preview Releaseapi-docs.deepseek.com
Image 8: WeChat QRcode Community Email Discord Twitter More GitHub Copyright © 2026 DeepSeek, Inc. [...] API Reference News DeepSeek-V4 Preview Release 2026/04/24 DeepSeek-V3.2 Release 2025/12/01 DeepSeek-V3.2-Exp Release 2025/09/29 DeepSeek V3.1 Update 202...
- [14] DeepSeek-R1 Release | DeepSeek API Docsapi-docs.deepseek.com
API Reference News DeepSeek-V4 Preview Release 2026/04/24 DeepSeek-V3.2 Release 2025/12/01 DeepSeek-V3.2-Exp Release 2025/09/29 DeepSeek V3.1 Update 2025/09/22 DeepSeek V3.1 Release 2025/08/21 DeepSeek-R1-0528 Release 2025/05/28 DeepSeek-V3-0324 Release 202...
- [15] DeepSeek-R1-0528 Releaseapi-docs.deepseek.com
DeepSeek-R1-0528 Release 🚀 DeepSeek-R1-0528 is here! 🔹 Improved benchmark performance 🔹 Enhanced front-end capabilities 🔹 Reduced hallucinations 🔹 Supports JSON output & function calling ✅ Try it now: 🔌 No change to API usage — docs here: 🔗 Open-sour...
- [16] DeepSeek-V2.5: A New Open-Source Model Combining General ...api-docs.deepseek.com
General Capabilities General Capability Evaluation We assessed DeepSeek-V2.5 using industry-standard test sets. DeepSeek-V2.5 outperforms both DeepSeek-V2-0628 and DeepSeek-Coder-V2-0724 on most benchmarks. In our internal Chinese evaluations, DeepSeek-V2....
- [17] DeepSeek-V3.1-Terminusapi-docs.deepseek.com
API Reference News DeepSeek-V4 Preview Release 2026/04/24 DeepSeek-V3.2 Release 2025/12/01 DeepSeek-V3.2-Exp Release 2025/09/29 DeepSeek V3.1 Update 2025/09/22 DeepSeek V3.1 Release 2025/08/21 DeepSeek-R1-0528 Release 2025/05/28 DeepSeek-V3-0324 Release 202...
- [18] DeepSeek-V3.2 Releaseapi-docs.deepseek.com
API Reference News DeepSeek-V4 Preview Release 2026/04/24 DeepSeek-V3.2 Release 2025/12/01 DeepSeek-V3.2-Exp Release 2025/09/29 DeepSeek V3.1 Update 2025/09/22 DeepSeek V3.1 Release 2025/08/21 DeepSeek-R1-0528 Release 2025/05/28 DeepSeek-V3-0324 Release 202...
- [19] Introducing DeepSeek-V3.2-Expapi-docs.deepseek.com
🛠 Open Source Release 🔗 Model: 🔗 Tech report: 🔗 Key GPU kernels in TileLang & CUDA (use TileLang for rapid research prototyping!) ⚡️ Efficiency Gains 🧑💻 API Update 🛠 Open Source Release [...] Skip to main content Introducing DeepSeek-V3.2-Exp 🚀 In...
- [20] Change Log | DeepSeek API Docsapi-docs.deepseek.com
Previous FAQ Date: 2026-04-24 DeepSeek-V4 Date: 2025-12-01 DeepSeek-V3.2 DeepSeek-V3.2-Speciale Date: 2025-09-29 DeepSeek-V3.2-Exp Date: 2025-09-22 DeepSeek-V3.1-Terminus Date: 2025-08-21 DeepSeek-V3.1 Date: 2025-05-28 deepseek-reasoner Date: 2025-03-24 dee...
- [21] DeepSeek | 深度求索deepseek.com
DeepSeek 深度求索 Image 1: DeepSeek Logo 🎉 DeepSeek-V4 预览版本发布,具备世界顶级推理性能,Agent 能力大幅提高,已在网页端、APP 和 API 上线,点击查看详情。 探索未至之境 开始对话 与 DeepSeek 免费对话 体验全新旗舰模型API 开放平台 调用 DeepSeek 最新模型 快速集成、流畅体验 获取手机 AppEnglish Image 2: DeepSeek Logo © 2026 杭州深度求索人工智能基础技术研究有限公司 版权所有 浙IC...
- [22] Models | OpenAI APIdevelopers.openai.com
GPT-5.5 New A new class of intelligence for coding and professional work. Model ID gpt-5.5 [Reasoning none low medium high xhigh Input price $5 / Input MTok Output price $30 / Output MTok Latency Fast Max output 128K tokens Context window 1M Tools Functions...
- [23] [PDF] HealthBench Professional: Evaluating Large Language Models on Real ...cdn.openai.com
Here we describe the systems evaluated in Section 5. We distinguish between AI systems and models. AI systems include models and harnesses used to exercise them. Harnesses may include tools, prompts, agentic loops, rich environments, storage containers, or...
- [24] GPT-5.5 System Card - Deployment Safety Hub - OpenAIdeploymentsafety.openai.com
We measure GPT-5.5’s controllability by running CoT-Control, an evaluation suite described in (Yueh-Han, 2026 ) that tracks the model’s ability to follow user instructions about their CoT. CoT-Control includes over 13,000 tasks built from established benchm...
- [25] GPT-5.5 System Card - OpenAIopenai.com
We generally treat GPT‑5.5’s safety results as strong proxies for GPT‑5.5 Pro, which is the same underlying model using a setting that makes use of parallel test time compute. As noted below, we separately evaluate GPT‑5.5 Pro in certain cases because we ju...
- [26] Introducing GPT-5 - OpenAIopenai.com
Keep reading View all Image 3: Hero Art Card SEO 1x1 Introducing GPT-5.5 Product Apr 23, 2026 Image 4: Making ChatGPT free for clinicians Making ChatGPT better for clinicians Product Apr 22, 2026 Image 5: OAI Blog Agents Hero 1x1 Introducing workspace agent...
- [27] Introducing GPT-5.5 - OpenAIopenai.com
Introducing GPT-5.5 OpenAI Skip to main content Log inTry ChatGPT(opens in a new window) Research Products Business Developers Company Foundation(opens in a new window) Introducing GPT-5.5 OpenAI Table of contents Model capabilities Next-generation inferenc...
- [28] Making ChatGPT better for clinicians - OpenAIopenai.com
Keep reading View all Image 2: Hero Art Card SEO 1x1 Introducing GPT-5.5 Product Apr 23, 2026 Image 3: OAI Blog Agents Hero 1x1 Introducing workspace agents in ChatGPT Product Apr 22, 2026 Image 4: Images 2.0 blog art card Introducing ChatGPT Images 2.0 Pro...
- [29] [PDF] GeneBench: Assessing AI Agents for Multi-Stage Inference ... - OpenAIcdn.openai.com
OpenAI. GPT-5.2 Model. OpenAI API documentation, 2026. models/gpt-5.2 OpenAI. GPT-5.4 Model. OpenAI API documentation, 2026. docs/models/gpt-5.4 OpenAI. GPT-5.4 pro Model. OpenAI API documentation, 2026. docs/models/gpt-5.4-pro OpenAI. GPT-5 pro Model. Open...
- [30] GPT-5 System Card | OpenAIopenai.com
Similarly to ChatGPT agent, we have decided to treat gpt-5-thinking as High capability in the Biological and Chemical domain under our Preparedness Framework, activating the associated safeguards. While we do not have definitive evidence that this model cou...
- [31] GPT-5.5 is here! Available in the API, Codex and ChatGPT todaycommunity.openai.com
It is now available in the API! OpenAI Developers OpenAI Developers @OpenAIDevs I think I need to phone my bank manager … Fingers crossed for your bank account: Looking at the price per million tokens, GPT-5.5 appears to be twice as expensive, but efficienc...
- [32] OpenAI Deployment Safety Hub: System cards & other updatesdeploymentsafety.openai.com
Skip to content Deployment Safety Hub Deployment safety Sharing the technical work we do to make our systems safe, including how deployed models perform in evaluations, the risks we measure, and the steps we take to improve over time. Abstract gradient back...
- [33] DeepSeek is back among the leading open weights models with V4 ...artificialanalysis.ai
Gains in knowledge but an increase in hallucination rate: DeepSeek V4 Pro (Max) scores -10 on AA-Omniscience, an 11 point improvement over V3.2 (Reasoning, -21), driven primarily by higher accuracy. V4 Flash (Max) scores -23, broadly in line with V3.2. V4 P...
- [34] DeepSeek V4 Flash (Reasoning, High Effort) vs GPT-5.5 (xhigh): Model Comparisonartificialanalysis.ai
Model Comparison Metric DeepSeek logoDeepSeek V4 Flash (Reasoning, High Effort) OpenAI logoGPT-5.5 (xhigh) Analysis --- --- Creator DeepSeek OpenAI Context Window 1000k tokens ( 1500 A4 pages of size 12 Arial font) 922k tokens ( 1383 A4 pages of size 12 Ari...
- [35] DeepSeek V4 Pro (Max) - Intelligence, Performance & Price Analysisartificialanalysis.ai
DeepSeek V4 Pro (Reasoning, Max Effort) logo Open weights model Released April 2026 DeepSeek V4 Pro (Reasoning, Max Effort) Intelligence, Performance & Price Analysis Model summary Intelligence Artificial Analysis Intelligence Index Speed Output tokens per...
- [36] DeepSeek V4 Pro (Reasoning, High Effort) vs ... - Artificial Analysisartificialanalysis.ai
Metric DeepSeek logoDeepSeek V4 Pro (Reasoning, High Effort) DeepSeek logoDeepSeek V4 Pro (Reasoning, Max Effort) Analysis --- --- Creator DeepSeek DeepSeek Context Window 1000k tokens ( 1500 A4 pages of size 12 Arial font) 1000k tokens ( 1500 A4 pages of s...
- [37] DeepSeek V4 Pro (Reasoning, High Effort) vs GPT-5.5 (medium)artificialanalysis.ai
Highlights Model Comparison Metric DeepSeek logoDeepSeek V4 Pro (Reasoning, High Effort) OpenAI logoGPT-5.5 (medium) Analysis --- --- Creator DeepSeek OpenAI Context Window 1000k tokens ( 1500 A4 pages of size 12 Arial font) 922k tokens ( 1383 A4 pages of s...
- [38] DeepSeek V4: Features, Benchmarks, and Comparisonsdatacamp.com
What is DeepSeek V4? DeepSeek V4 is the highly anticipated new series of open-weight large language models from Chinese AI lab DeepSeek. Released on April 24, 2026, the V4 series comes in two versions: DeepSeek-V4-Pro and DeepSeek-V4-Flash. Both models util...
- [39] From GPT-5.5 to DeepSeek V4: How Developers Are Building ...desmoinesregister.com
DeepSeek V4 Preview (DeepSeek, April 24, 2026) is the release that may define Q2 2026. The model ships in two variants: V4-Pro (1.6 trillion parameters, 49 billion active, MIT license) and V4-Flash (284 billion parameters, 13 billion active). Priced at $0.1...
- [40] OpenAI's GPT-5.5 is the new leading AI model - Artificial Analysisartificialanalysis.ai
Read the latest Image 7 Kimi K2.6: The new leading open weights model Benchmarks and Analysis of Kimi K2.6 April 21, 2026Image 8 Opus 4.7: Everything you need to know Benchmarks and Analysis of Opus 4.7 April 17, 2026Image 9 Sub-32B Open Weights Benchmark a...
- [41] DeepSeek V4 Pro (Reasoning, High Effort) vs GPT-5.5 (high): Model Comparisonartificialanalysis.ai
Highlights Model Comparison Metric DeepSeek logoDeepSeek V4 Pro (Reasoning, High Effort) OpenAI logoGPT-5.5 (high) Analysis --- --- Creator DeepSeek OpenAI Context Window 1000k tokens ( 1500 A4 pages of size 12 Arial font) 922k tokens ( 1383 A4 pages of siz...
- [42] LLM Leaderboard 2026 — Compare Top AI Models - Vellumvellum.ai
93.6% GPT-5.5 92.4% GPT 5.2 91.9% Gemini 3 Pro Best in Reasoning (GPQA Diamond) Model Score --- Claude 3 Opus 95.4% Claude Opus 4.7 94.2% GPT-5.5 93.6% GPT 5.2 92.4% Gemini 3 Pro 91.9% Best in High School Math (AIME 2025) 100%96%93%89%86% 100% Gemini 3 Pro...