GPT-5.5, Claude Opus 4.7, DeepSeek V4, Kimi K2.6의 벤치마크를 비교해 주세요.
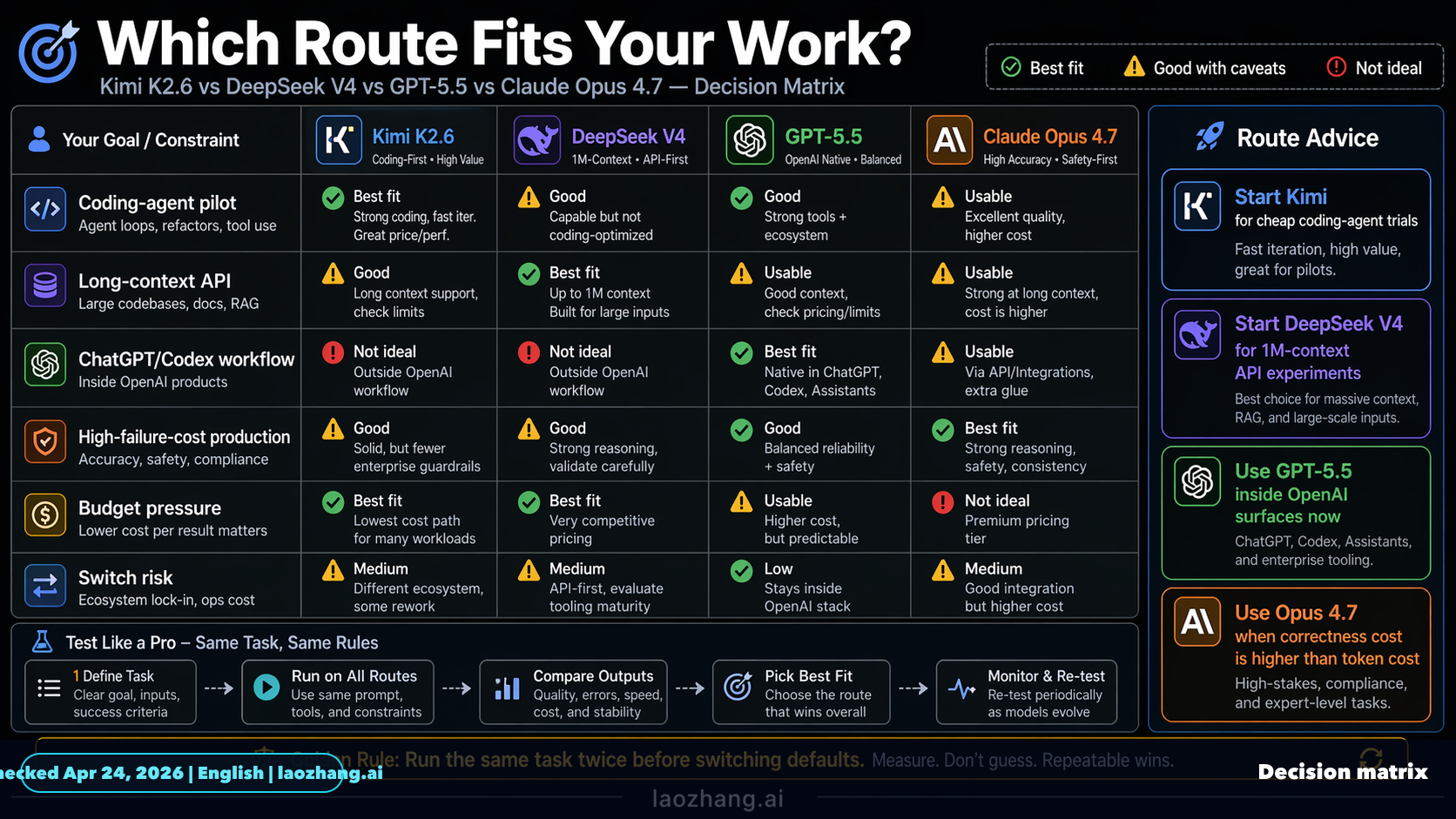
요약하면, 공개적으로 확인 가능한 “동일 조건” 벤치마크만 놓고 보면 GPT 5.5는 터미널/에이전트 코딩, Claude Opus 4.7은 SWE Bench Pro·Verified와 추론 계열에서 강합니다. DeepSeek V4와 Kimi K2.6은 공개 수치가 흩어져 있어 4개 모델을 한 표로 공정하게 순위화하기에는 근거가 부족합니다. | 항목 | GPT 5.5 | Claude Opu...
요약하면, 공개적으로 확인 가능한 “동일 조건” 벤치마크만 놓고 보면 GPT 5.5는 터미널/에이전트 코딩, Claude Opus 4.7은 SWE Bench Pro·Verified와 추론 계열에서 강합니다. DeepSeek V4와 Kimi K2.6은 공개 수치가 흩어져 있어 4개 모델을 한 표로 공정하게 순위화하기에는 근거가 부족합니다. | 항목 | GPT 5.5 | Claude Opus 4.7 | DeepSeek V4 | Kimi K2.6 | | | :| :| :| :| | Terminal Bench 2.0 | 82.7% | 69.4% | 공개 비교 근거 부족 |
주요 시사점
- 요약하면, 공개적으로 확인 가능한 “동일 조건” 벤치마크만 놓고 보면 GPT-5.5는 터미널/에이전트 코딩, Claude Opus 4.7은 SWE-Bench Pro·Verified와 추론 계열에서 강합니다. DeepSeek V4와 Kimi K2.6은 공개 수치가 흩어져 있어 4개 모델을 한 표로 공정하게 순위화하기에는 근거가 부족합니다.
- | 항목 | GPT-5.5 | Claude Opus 4.7 | DeepSeek V4 | Kimi K2.6 |
연구 답변
요약하면, 공개적으로 확인 가능한 “동일 조건” 벤치마크만 놓고 보면 GPT-5.5는 터미널/에이전트 코딩, Claude Opus 4.7은 SWE-Bench Pro·Verified와 추론 계열에서 강합니다. DeepSeek V4와 Kimi K2.6은 공개 수치가 흩어져 있어 4개 모델을 한 표로 공정하게 순위화하기에는 근거가 부족합니다.
| 항목 | GPT-5.5 | Claude Opus 4.7 | DeepSeek V4 | Kimi K2.6 |
|---|---|---|---|---|
| Terminal-Bench 2.0 | 82.7% | 69.4% | 공개 비교 근거 부족 | 약 66%대로 보도됨 |
| SWE-Bench Pro | 58.6% | 64.3% | 공개 비교 근거 부족 | 58.6% |
| SWE-Bench Verified | 공개 수치 확인 부족 | 87.6% | 공개 비교 근거 부족 | 80.2% |
| GPQA Diamond | 0.94/1로 집계된 자료 있음 | 94.2%로 보도됨 | 공개 비교 근거 부족 | 공개 비교 근거 부족 |
| HLE | GPT-5.5와 Opus 4.7 비교 자료에서 항목 존재 | 46.9%로 보도됨 | 공개 비교 근거 부족 | 공개 비교 근거 부족 |
| 기타 | OSWorld, BrowseComp, CyberGym 등에서 GPT-5.5가 앞선다는 비교가 있음 | FinanceAgent, MCP Atlas 등에서 Opus 4.7이 앞선다는 비교가 있음 | Artificial Analysis 기준 AA-Omniscience 개선이 보고됐지만 환각률이 매우 높다는 지적도 있음 | 텍스트·이미지·비디오 입력과 256k 컨텍스트 지원으로 소개됨 |
- GPT-5.5는 OpenAI 발표 기준 Terminal-Bench 2.0에서 82.7%, SWE-Bench Pro에서 58.6%를 기록한 것으로 확인됩니다 [
15].
- Claude Opus 4.7은 여러 비교 자료에서 SWE-Bench Pro 64.3%, SWE-Bench Verified 87.6%, Terminal-Bench 69.4%, GPQA Diamond 94.2%로 제시됩니다 [
3].
- GPT-5.5와 Claude Opus 4.7만 비교하면, 한 집계 자료는 공통 10개 벤치마크 중 Claude Opus 4.7이 6개, GPT-5.5가 4개에서 앞선다고 요약합니다 [
12].
- Kimi K2.6은 SWE-Bench Pro 58.6%, SWE-Bench Verified 80.2%로 소개된 자료가 있지만, GPT-5.5·Claude Opus 4.7·DeepSeek V4와 완전히 같은 하네스에서 비교됐는지는 명확하지 않습니다 [
15][
4].
- DeepSeek V4는 Artificial Analysis에서 V4 Pro와 V4 Flash의 지식·환각 관련 평가가 언급되지만, 위 표의 SWE-Bench Pro, Terminal-Bench, GPQA, HLE와 직접 대응되는 공개 비교 수치는 충분하지 않습니다 [
7].
결론적으로 “벤치마크 승자”를 하나로 고르면 왜곡될 수 있습니다.
시각적 지원
















연구 대화
연구문제
GPT-5.5, Claude Opus 4.7, DeepSeek V4, Kimi K2.6의 벤치마크를 비교해 주세요.
인용 답변
요약하면, 공개적으로 확인 가능한 “동일 조건” 벤치마크만 놓고 보면 GPT-5.5는 터미널/에이전트 코딩, Claude Opus 4.7은 SWE-Bench Pro·Verified와 추론 계열에서 강합니다. DeepSeek V4와 Kimi K2.6은 공개 수치가 흩어져 있어 4개 모델을 한 표로 공정하게 순위화하기에는 근거가 부족합니다.
| 항목 | GPT-5.5 | Claude Opus 4.7 | DeepSeek V4 | Kimi K2.6 |
|---|---|---|---|---|
| Terminal-Bench 2.0 | 82.7% | 69.4% | 공개 비교 근거 부족 | 약 66%대로 보도됨 |
| SWE-Bench Pro | 58.6% | 64.3% | 공개 비교 근거 부족 | 58.6% |
| SWE-Bench Verified | 공개 수치 확인 부족 | 87.6% | 공개 비교 근거 부족 | 80.2% |
| GPQA Diamond | 0.94/1로 집계된 자료 있음 | 94.2%로 보도됨 | 공개 비교 근거 부족 | 공개 비교 근거 부족 |
| HLE | GPT-5.5와 Opus 4.7 비교 자료에서 항목 존재 | 46.9%로 보도됨 | 공개 비교 근거 부족 | 공개 비교 근거 부족 |
| 기타 | OSWorld, BrowseComp, CyberGym 등에서 GPT-5.5가 앞선다는 비교가 있음 | FinanceAgent, MCP Atlas 등에서 Opus 4.7이 앞선다는 비교가 있음 | Artificial Analysis 기준 AA-Omniscience 개선이 보고됐지만 환각률이 매우 높다는 지적도 있음 | 텍스트·이미지·비디오 입력과 256k 컨텍스트 지원으로 소개됨 |
- GPT-5.5는 OpenAI 발표 기준 Terminal-Bench 2.0에서 82.7%, SWE-Bench Pro에서 58.6%를 기록한 것으로 확인됩니다 [
15].
- Claude Opus 4.7은 여러 비교 자료에서 SWE-Bench Pro 64.3%, SWE-Bench Verified 87.6%, Terminal-Bench 69.4%, GPQA Diamond 94.2%로 제시됩니다 [
3].
- GPT-5.5와 Claude Opus 4.7만 비교하면, 한 집계 자료는 공통 10개 벤치마크 중 Claude Opus 4.7이 6개, GPT-5.5가 4개에서 앞선다고 요약합니다 [
12].
- Kimi K2.6은 SWE-Bench Pro 58.6%, SWE-Bench Verified 80.2%로 소개된 자료가 있지만, GPT-5.5·Claude Opus 4.7·DeepSeek V4와 완전히 같은 하네스에서 비교됐는지는 명확하지 않습니다 [
15][
4].
- DeepSeek V4는 Artificial Analysis에서 V4 Pro와 V4 Flash의 지식·환각 관련 평가가 언급되지만, 위 표의 SWE-Bench Pro, Terminal-Bench, GPQA, HLE와 직접 대응되는 공개 비교 수치는 충분하지 않습니다 [
7].
결론적으로 “벤치마크 승자”를 하나로 고르면 왜곡될 수 있습니다.
사람들은 또한 묻습니다.
"GPT-5.5, Claude Opus 4.7, DeepSeek V4, Kimi K2.6의 벤치마크를 비교해 주세요."에 대한 짧은 대답은 무엇입니까?
요약하면, 공개적으로 확인 가능한 “동일 조건” 벤치마크만 놓고 보면 GPT-5.5는 터미널/에이전트 코딩, Claude Opus 4.7은 SWE-Bench Pro·Verified와 추론 계열에서 강합니다. DeepSeek V4와 Kimi K2.6은 공개 수치가 흩어져 있어 4개 모델을 한 표로 공정하게 순위화하기에는 근거가 부족합니다.
먼저 검증할 핵심 포인트는 무엇인가요?
요약하면, 공개적으로 확인 가능한 “동일 조건” 벤치마크만 놓고 보면 GPT-5.5는 터미널/에이전트 코딩, Claude Opus 4.7은 SWE-Bench Pro·Verified와 추론 계열에서 강합니다. DeepSeek V4와 Kimi K2.6은 공개 수치가 흩어져 있어 4개 모델을 한 표로 공정하게 순위화하기에는 근거가 부족합니다. | 항목 | GPT-5.5 | Claude Opus 4.7 | DeepSeek V4 | Kimi K2.6 |
다음에는 어떤 관련 주제를 탐구해야 할까요?
다른 각도와 추가 인용을 보려면 "GPT 5.5와 Claude Opus 4.7의 성능을 비교해 보세요."으로 계속하세요.
관련 페이지 열기이것을 무엇과 비교해야 합니까?
"지금 DeepSeek를 어떻게 사용해 볼 수 있나요?"에 대해 이 답변을 대조 확인하세요.
관련 페이지 열기연구를 계속하세요
출처
- [1] Claude Opus 4.7 vs Kimi K2.6 - Detailed Performance & Feature Comparisondocsbot.ai
| SWE-Bench Verified Evaluates software engineering capabilities through verified code modifications and custom agent setups | Not available | 80.2% SWE-Bench Verified, thinking mode Source | | SWE-Bench Pro Evaluates software engineering on multi-language SWE-Bench Pro benchmark of real-world GitHub issues | 64.3% Public; reported in OpenAI GPT-5.5 comparison table. Source | 58.6% Thinking mode Source | | Toolathon Assesses agentic tool-calling performance across multi-step tasks | 48.8% Source | 50% Thinking mode Source | | Visual Acuity (XBOW) Evaluates high-resolution visual understanding…
- [2] DeepSeek is back among the leading open weights models with V4 Pro ...artificialanalysis.ai
Gains in knowledge but an increase in hallucination rate: DeepSeek V4 Pro (Max) scores -10 on AA-Omniscience, an 11 point improvement over V3.2 (Reasoning, -21), driven primarily by higher accuracy. V4 Flash (Max) scores -23, broadly in line with V3.2. V4 Pro and V4 Flash both have a very high hallucination rate of 94% and 96% respectively meaning when they don’t know the answer they nearly always respond anyway. DeepSeek V4 Pro and V4 Flash individual benchmark results Further benchmarks and analysis on Artificial Analysis of DeepSeek V4 Pro and Flash: ## Read the latest ### OpenAI's GPT-5.5…
- [3] DeepSeek V4 is here: How it compares to ChatGPT, Claude, Geminimashable.com
Here's how the API pricing compares: DeepSeek V4 costs $1.74 per 1 million input tokens and $3.48 per 1 million output tokens (1 million context window) GPT-5.5 costs at $5 per 1 million input tokens and $30 per 1 million output tokens (1 million context window) Claude Opus 4.7 costs at $5 per 1 million input tokens and $25 per 1 million output tokens (1 million context window) Google Gemini 3.1 Pro costs $2 per 1 million input tokens and $12 per 1 million output tokens As you can see, DeepSeek is about one-sixth the cost of the latest U.S. models, which is a huge edge. Even the more affordab…
- [4] DeepSeek V4: Features, Benchmarks, and Comparisons - DataCampdatacamp.com
How large are the DeepSeek V4 models? DeepSeek uses a Mixture of Experts (MoE) architecture. The Pro model contains 1.6 trillion total parameters (49 billion active) and requires an 865GB download. The Flash model contains 284 billion parameters (13 billion active) and requires a 160GB download. ### Does DeepSeek V4 beat GPT-5.5 and Claude Opus 4.7? In pure capability, no. DeepSeek's self-reported data suggests the V4-Pro model trails state-of-the-art closed models by about 3 to 6 months on the hardest coding and reasoning benchmarks. However, it delivers near-frontier performance at roug…
- [5] GPT-5.5 vs Claude Opus 4.7: Pricing, Speed, Benchmarksllm-stats.com
The Verdict On the 10 benchmarks both providers report, Opus 4.7 leads on 6 and GPT-5.5 leads on 4. The leads cluster by category, not by overall quality: Opus 4.7 is ahead on the reasoning-heavy and review-grade tests (GPQA Diamond, HLE with and without tools, SWE-Bench Pro, MCP Atlas, FinanceAgent v1.1). GPT-5.5 is ahead on the long-running tool-use tests (Terminal-Bench 2.0, BrowseComp, OSWorld-Verified, CyberGym). Margins are mostly between 2 and 13 percentage points, and every score is self-reported at each provider's high reasoning tier — comparable in shape, not in methodology. [...…
- [6] Kimi K2.6 vs Claude Opus 4.6 vs GPT-5.4 - Verdent AIverdent.ai
| Benchmark | K2.6 | Claude Opus 4.6 | GPT-5.4 | Notes | --- --- | SWE-Bench Pro | 58.60% | 53.40% | 57.70% | Moonshot in-house harness; SEAL mini-swe-agent puts GPT-5.4 at 59.1%, Opus 4.6 at 51.9% | | SWE-Bench Verified | 80.20% | 80.80% | ~80% | Tight cluster; Opus 4.7 now leads at 87.6% | | Terminal-Bench 2.0 | 66.70% | 65.40% | 65.40% | See note below | | HLE with tools | 54.00% | 53.00% | 52.10% | All three within 2 points | | LiveCodeBench v6 | 89.60% | 88.80% | — | v6 as of April 2026 | Source for all K2.6 numbers: Moonshot AI official model card, April 20, 2026. Claude Opus 4.6 number…
- [7] Kimi K2.6 vs DeepSeek V4 vs GPT-5.5 vs Claude Opus 4.7blog.laozhang.ai
Official Contract Lanes Official rows keep the comparison honest. Kimi's K2.6 pricing page says K2.6 is the latest and smartest Kimi model, supports text, image, and video input, and has a 256k context route. DeepSeek's pricing page lists deepseek-v4-flash and deepseek-v4-pro with a 1M context window, 384K maximum output, OpenAI-format base URL, Anthropic-format base URL, and prices of $0.028 or $0.145 cache-hit input, $0.14 or $1.74 cache-miss input, and $0.28 or $3.48 output per million tokens. OpenAI's current API guide is still titled around GPT-5.4 and states that GPT-5.5 is available…
- [8] OpenAI’s GPT-5.5 vs Claude Opus 4.7: Which is better? | Mashablemashable.com
Thanks for signing up! SWE-Bench Pro: GPT-5.5 scored 58.6; Opus 4.7 scored 64.3 percent Terminal-Bench 2.0: GPT-5.5 scored 82.7 percent; Opus 4.7 scored 69.4 percent Humanity's Last Exam: GPT-5.5 scored 40.6 percent; Opus 4.7 scored 31.2 percent\ Humanity's Last Exam (with tools): GPT-5.5 scored 52.2 percent; Opus 4.7 scored 54.7 percent BrowseComp: GPT-5.5 scored 84.4 percent; Opus 4.7 scored 79.3 percent GPQA Diamond: GPT-5.5 scored 93.6 percent; Opus 4.7 scored 94.2 percent ARC-AGI-1 (Verified): GPT-5.5 (High) scored 94.5 percent; Claude 4.7 (High) scored 92 percent\ ARC-AGI-2 (Verified):…
- [9] Deep|DeepSeek V4 vs Claude vs GPT-5.4: A 38-Task ... - FundaAIfundaai.substack.com
DeepSeek V4 Flash averages 165s per task — faster than all three Claude Opus models (Opus 4.5: 138s, Opus 4.7: 227s, Opus 4.6: 267s). Pro is slower at 256s — comparable to Opus 4.7. Both models produce dense, token-efficient output: Pro averages ~4,200 output tokens and Flash ~3,800, compared to Claude’s ~7,500-8,800 characters. DeepSeek shows competitive quality per token — the content-to-padding ratio is notably higher, with fewer boilerplate disclaimers and more substantive tables, data points, and analysis per word.On cost, DeepSeek V4 shows a notable advantage in this benchmark. Flash at…
- [10] GPT 5.5 Vs Claude Opus 4.7 Proves Benchmarks Need Context : r/AISEOInsiderreddit.com
GPT 5.5 feels like the model you use when you want to get a working version quickly. It can create files, move through steps, fix obvious errors, and keep the project moving without slowing everything down. That is useful for landing pages, prototypes, internal tools, scripts, and automation setups. Claude Opus 4.7 feels better when the work needs more polish. It can be stronger for code review, structure, refactoring, naming, consistency, and improving rough output. That makes Claude useful after the first version already exists. The best workflow is not complicated. Use GPT 5.5 to build the…
- [11] Tech Titans | DeepSeek V4 Pro beats Claude Opus 4.6 and GPT-5.4 on coding benchmarks at a 10th of the price | Facebookfacebook.com
Deep seek sucks and always has 1d 1 Image 5 View 1 reply []( Tsu Li Chuang What is minimum gig requirement for Deepseek V4? 1d 1 Image 6 View 1 reply View more comments 3 of 4 See more on Facebook See more on Facebook Email or phone number Password Log In Forgot password? or Create new account [...] A few people have DMd me asking how to do it... So, I wrote the migration guide really fast (Yes, I did it in Deepseek via Claude Code for reference). 20+ pages covering every major coding agent, every env var, every gotcha. Subscription plan math vs direct API math. Even the benchmarks where V4 s…
- [12] GPT 5.5 is out. Here are the benchmarks. | Facebookfacebook.com
OpenClaw Community | GPT 5.5 is out. Here are the benchmarks | Facebook Log In Log In Forgot Account? 82.0% 53.3% សាដា០ 44.4% 79.3% Scaled 52.2% ขว์๒ป 56.8% astacta 83.7% 51.4% withBoola 77.3% Agentic computer use 64.7% wiatoolls 75.8% 85.9% 78.0% Agentic financial 86.9% 72.7% 73.9% 64.4% 78.7% 60.1% 61.5% 73.1% 79.6% Graduate- level 59.7% 73.8% 81.8% 94.2% 91.3% Visual reasoning 82.1% 83.1% 93.6% 69.1% 94.3% 91.0% withtoeks MultilingualQ&A Q&A 94.6% 84.7% 91.5% 86.1% 91.1% 83.2% 93.2% withtools 92.6%' Image 2 All reactions: 51 36 comments 4 shares Like Comment Share Most relevant []( Andre…
- [13] Everything You Need to Know About GPT-5.5 - Vellumvellum.ai
| Benchmark | GPT-5.5 | GPT-5.5 Pro | GPT-5.4 | Claude Opus 4.7 | Gemini 3.1 Pro | --- --- --- | | Terminal-Bench 2.0 | 82.7% | — | 75.1% | 69.4% | 68.5% | | SWE-Bench Pro | 58.6% | — | 57.7% | 64.3% | 54.2% | | Expert-SWE (Internal) | 73.1% | — | 68.5% | — | — | | GDPval | 84.9% | 82.3% | 83.0% | 80.3% | 67.3% | | OSWorld-Verified | 78.7% | — | 75.0% | 78.0% | — | | BrowseComp | 84.4% | 90.1% | 82.7% | 79.3% | 85.9% | | MCP Atlas | 75.3% | — | 70.6% | 79.1% | 78.2% | | GPQA Diamond | 93.6% | — | 92.8% | 94.2% | 94.3% | | FrontierMath T1–3 | 51.7% | 52.4% | 47.6% | 43.8% | 36.9% | | FrontierM…
- [14] GPT-5.5 System Card - OpenAI Deployment Safety Hubdeploymentsafety.openai.com
We measure GPT-5.5’s controllability by running CoT-Control, an evaluation suite described in (Yueh-Han, 2026 ) that tracks the model’s ability to follow user instructions about their CoT. CoT-Control includes over 13,000 tasks built from established benchmarks: GPQA (Rein et al., 2023 ), MMLU-Pro (Hendrycks et al., 2020 ), HLE (Phan et al., 2025 ), BFCL (Patil et al., 2025 [11: From tool use to agentic evaluation of large language models.” Proceedings of the 42nd international conference on machine learning . Available at: .")]) and SWE-Bench Verified. Each task is created by pairing a bench…
- [15] GPT-5.5: Pricing, Benchmarks & Performance - LLM Statsllm-stats.com
| GPQA A challenging dataset of 448 multiple-choice questions written by domain experts in biology, physics, and chemistry. Questions are Google-proof and extremely difficult, with PhD experts reaching 65% accuracy. More | #4 | 0.94/1 Methodology: GPQA Diamond. Reasoning effort xhigh. | openai.com | [...] ### What is the license for GPT-5.5? GPT-5.5 is released under the Proprietary license. ### Is GPT-5.5 multimodal? Yes, GPT-5.5 is a multimodal model that can process both text and images as input. ### How much does GPT-5.5 cost? GPT-5.5 pricing starts at $5.00 per million input tokens via O…
- [16] GPT-5.5: The Honest Take on OpenAI's Response to Opus 4.7 | Blogalexlavaee.me
One real gap deserves attention: Terminal-Bench 2.0. A 13-point lead over Opus 4.7 is the largest single-benchmark gap between today’s frontier coding models, and this benchmark is newer and harder to pre-train against than the SWE-Bench family. If your agent workload is long-running terminal sessions — sandboxed CI jobs, reproduction scripts, multi-step shell workflows — GPT-5.5 leads it clearly. On MCP Atlas, Opus 4.7 still edges ahead, which matters more for tool-heavy agent workloads than the SWE-Bench Pro delta does. As with the last several releases, the honest framing is that no single…
- [17] OpenAI GPT-5.5 Benchmark (CodeRabbit)coderabbit.ai
In our early testing with GPT-5.5, the agent reached 79.2% expected issue found on our curated review benchmark versus 58.3%, improved precision from 27.9% to 40.6%, and produced 75 comments versus the baseline's 67. That means it found substantially more useful issues with only a modest increase in comment volume. In testing, GPT-5.5 improved performance across several key metrics on our large-scale, real-world review set. Specifically, the expected issue found rate increased from a 55.0% baseline to 65.0%. Furthermore, precision improved from 11.6% to 13.2%. The agent also became more verbo…
- [18] OpenAI's GPT-5.5 masters agentic coding with 82.7% benchmark ...interestingengineering.com
On SWE-Bench Pro, it reached 58.6%, solving more real-world GitHub issues in a single pass than earlier versions. The model also outperformed its predecessor in long-horizon engineering tasks measured by internal benchmarks. These tasks often take human developers up to 20 hours to complete. > Introducing GPT-5.5 > > A new class of intelligence for real work and powering agents, built to understand complex goals, use tools, check its work, and carry more tasks through to completion. It marks a new way of getting computer work done. > > Now available in ChatGPT and Codex. pic.twitter.com/rPLTk…
- [19] Introducing GPT-5.5 - OpenAIopenai.com
Agentic coding GPT‑5.5 is our strongest agentic coding model to date. On Terminal-Bench 2.0, which tests complex command-line workflows requiring planning, iteration, and tool coordination, it achieves a state-of-the-art accuracy of 82.7%. On SWE-Bench Pro, which evaluates real-world GitHub issue resolution, it reaches 58.6%, solving more tasks end-to-end in a single pass than previous models. On Expert-SWE, our internal frontier eval for long-horizon coding tasks with a median estimated human completion time of 20 hours, GPT‑5.5 also outperforms GPT‑5.4. Across all three evals, GPT‑5.5…
- [20] How OpenAI's recently released GPT-5.5 stacks up with Anthropic's ...rdworldonline.com
Opus 4.7 leads GPT-5.5 base on: SWE-bench Pro, HLE with tools. Ties on GPQA and OSWorld. Loses on Terminal-Bench, BrowseComp, CyberGym. [...] Mythos leads: SWE-bench Pro (77.8 vs 58.6 / 64.3), HLE no tools (56.8 vs 41.4 / 46.9), HLE with tools (64.7 vs 52.2 / 54.7), CyberGym (83 vs 81.8 / 73.1), OSWorld-Verified (79.6 vs 78.7 / 78.0), GraphWalks long context (soft comparison but 80 vs 45.4). Effectively tied: GPQA Diamond (94.5 vs 93.6 / 94.2) and Terminal-Bench 2.0 on the headline numbers (82 vs 82.7). Anthropic’s 92.1% Terminal-Bench 2.1 result shows how sensitive the benchmark is to harnes…
- [21] GPT-5.5 Is 'Our Smartest Model Yet,' Says Company With History of ...mediacopilot.ai
The model also shows gains on scientific and technical research workflows. On GeneBench, a new eval focusing on multi-stage scientific data analysis in genetics and quantitative biology, GPT-5.5 outperforms GPT-5.4 on problems that often correspond to multi-day projects for scientific experts. On BixBench, a benchmark designed around real-world bioinformatics and data analysis, it achieved leading performance among models with published scores. [...] By The Copilot OpenAI today released GPT-5.5, what it says is its “smartest and most intuitive to use model yet, and the next step toward a new…
- [22] Model Drop: GPT-5.5 - by Jake Handyhandyai.substack.com
Headline benchmarks: Terminal-Bench 2.0 at 82.7% (Opus 4.7: 69.4%, Gemini 3.1 Pro: 68.5%). SWE-Bench Pro at 58.6% (Opus 4.7 still leads at 64.3%). OpenAI’s internal Expert-SWE eval, where tasks have a 20-hour median human completion time, at 73.1% (up from GPT-5.4’s 68.5%). GDPval wins-or-ties at 84.9% (Opus 4.7: 80.3%, Gemini 3.1 Pro: 67.3%). OSWorld-Verified at 78.7% (narrowly edges Opus 4.7’s 78.0%). FrontierMath Tier 4 at 35.4% (Opus 4.7: 22.9%, Gemini 3.1 Pro: 16.7%). CyberGym at 81.8% (Opus 4.7: 73.1%, Anthropic’s Claude Mythos: 83.1%). Tau2-Bench Telecom at 98.0% without prompt tuning.…
- [23] Perspective helps! GPT-5.5 underperforms Mythos on: - SWE-Bench ...x.com
leo 🐾 on X: "Perspective helps! GPT-5.5 underperforms Mythos on: - SWE-Bench Pro - HLE It is basically on-par on: - GPQA Diamond - BrowseComp - OSWorld-Verified It is better on: - Terminal-Bench 2.0 All while being more token efficient, smaller and cheaper than Mythos (and actually" / X Don’t miss what’s happening People on X are the first to know. Log in Sign up # Quote Image 3 leo Image 4: 🐾 @synthwavedd · Apr 23 GPT-5.5 benchmarks are out Benchmark results are more incremental, but in real world use it feels like a larger jump, especially for 5.5 Pro in my experience. Sort of similar t…
- [24] Claude Opus 4.7vals.ai
Benchmarks Models Comparison Model Guide App Reports News About Benchmarks Models Comparison Model Guide App Reports About Release date Models 4/20/2026 Moonshot AI Kimi K2.6 4/16/2026 Anthropic Claude Opus 4.7 4/8/2026 Meta Muse Spark 4/2/2026 Google Gemma 4 31B IT 4/2/2026 Alibaba Qwen 3.6 Plus 4/1/2026 zAI GLM 5.1 4/1/2026 Arcee AI Trinity Large Thinking 3/17/2026 OpenAI GPT 5.4 Mini 3/17/2026 OpenAI GPT 5.4 Nano 3/17/2026 MiniMax MiniMax-M2.7 3/9/2026 xAI Grok 4.20 (Reasoning) 3/5/2026 OpenAI GPT 5.4 3/3/2026 Google Gemini 3.1 Flash Lite Preview 2/24/2026 OpenAI GPT 5.3 Codex 2/23/2026 Al…
- [25] Claude Opus 4.7 Benchmark Breakdown: Vision, Coding, and ...mindstudio.ai
Claude Opus 4.7 posted 82.4% on SWE-bench Verified, up roughly 11 points from Opus 4.6 — the most meaningful coding benchmark available. Vision improvements were the largest percentage gains: MathVista jumped 9.5 points, enabling reliable visual math reasoning and structured chart interpretation. FinanceBench performance of 82.7% makes Opus 4.7 a strong choice for financial document analysis, handling most standard extraction and calculation tasks accurately. Opus 4.7 leads GPT-5.4 and Gemini 3.1 Pro across all five core benchmarks in this breakdown, with the most meaningful gap on SWE-bench.…
- [26] Claude Opus 4.7 Benchmarks Explainedvellum.ai
Is Claude Opus 4.7 the most powerful Claude model? No. Claude Mythos Preview is Anthropic's most capable model and leads Opus 4.7 on most benchmarks in the comparison table, including SWE-bench Pro (77.8% vs 64.3%), SWE-bench Verified (93.9% vs 87.6%), Terminal-Bench (82.0% vs 69.4%), and GPQA Diamond (94.6% vs 94.2%). Opus 4.7 is the most capable generally available Claude model and is the first to ship with the new cybersecurity safeguards Anthropic is developing ahead of a broader Mythos-class rollout. Where can I access Claude Opus 4.7? [...] What is the xhigh effort level? It's a new eff…
- [27] Claude Opus 4.7: Anthropic's New Best (Available) Model - DataCampdatacamp.com
Claude Opus 4.7 Benchmarks Opus 4.7 was evaluated across 14 benchmarks covering coding, reasoning, tool use, computer use, and visual reasoning. The table below shows the full comparison with Opus 4.6, GPT 5.4, Gemini 3.1 Pro, and the not-yet-published Mythos Preview. ### Agentic coding On SWE-bench Pro, Opus 4.7 scores 64.3%, ahead of GPT-5.4 at 57.7%, Gemini 3.1 Pro at 54.2%, and Opus 4.6 at 53.4%. On SWE-bench Verified, Opus 4.7 reaches 87.6% against Gemini 3.1 Pro's 80.6% and Opus 4.6's 80.8%. GPT-5.4 has no published score on SWE-bench Verified in this comparison. [...] SWE-bench test…
- [28] Claude Opus 4.7: Anthropic’s new flagship, benchmarks, and how it compares to Sonnet & Haiku | explainx.ai Blog | explainx.aiexplainx.ai
\Percentages are as printed on Anthropic’s benchmark figure; leaderboard definitions, prompts, and tool policies can move scores over time—treat this as a snapshot, not a substitute for your eval harness. Reading the table pragmatically Agentic coding (SWE-bench Pro / Verified) is where Opus 4.7 shows a large jump vs 4.6 in this grid. Terminal-Bench still shows GPT-5.4 ahead in this particular column—use both IDE and terminal tasks when you regression-test. Tools materially move HLE and CharXiv scores—if your product gives the model browsers, IDEs, or MCP, mirror that in evals. Mythos Preview…
- [29] Anthropic releases Claude Opus 4.7: How to try it, benchmarks, safetymashable.com
Claude Mythos scored 56.8 percent on HLE Claude Opus 4.7 scored 46.9 percent Gemini 3.1 Pro scored 44.4 percent GPT-5-4 Pro scored 42.7 percent Claude Opus 4.6 scored 40.0 percent With tools, GPT-5-4-Pro scored 58.7 percent compared to Opus 4.7’s 54.7 percent. Mythos beat them both with 64.7 percent. Related Stories 'The AI Doc' director says cynicism is the only wrong answer to AI Anthropic sues Pentagon as Claude downloads soar Anthropic CEO warns that AI could bring slavery, bioterrorism, and unstoppable drone armies. I'm not buying it. Anthropic used mostly AI to build Claude Cowork tool…
- [30] GPT-5.5 vs Claude Opus 4.7: Every Benchmark, One Clear Winner for Agentic Workbeam.ai
| | | | | | --- --- | Category | Benchmark | GPT-5.5 | Opus 4.7 | Winner | | Coding | Terminal-Bench 2.0 | 82.7% | 69.4% | GPT-5.5 | | Coding | SWE-Bench Pro | 58.6% | 64.3% | Opus 4.7 | | Coding | Expert-SWE | 73.1% GPT-5.5 | | Professional | GDPval | 84.9% | 80.3% | GPT-5.5 | | Professional | FinanceAgent v1.1 | 60.0% | 64.4% | Opus 4.7 | | Professional | OfficeQA Pro | 54.1% | 43.6% | GPT-5.5 | | Computer Use | OSWorld-Verified | 78.7% | 78.0% | Tied | | Tool Use | BrowseComp | 84.4% | 79.3% | GPT-5.5 | | Tool Use | MCP Atlas | 75.3% | 79.1% | Opus 4.7 | | Math | FrontierMath T1-3 | 51.7%…
- [31] Introducing Claude Opus 4.7 - Anthropicanthropic.com
For GPT-5.4 and Gemini 3.1 Pro, we compared against the best reported model version available via API in the charts and table. MCP-Atlas: The Opus 4.6 score has been updated to reflect revised grading methodology from Scale AI. SWE-bench Verified, Pro, and Multilingual: Our memorization screens flag a subset of problems in these SWE-bench evals. Excluding any problems that show signs of memorization, Opus 4.7’s margin of improvement over Opus 4.6 holds. Terminal-Bench 2.0: We used the Terminus-2 harness with thinking disabled. All experiments used 1× guaranteed/3× ceiling resource allocation…
- [32] Chris on X: "While we wait for Mythos, Anthropic just dropped a pretty massive .1 upgrade with Opus 4.7. Opus 4.6 -> 4.7 SWE Bench Pro: 53.4% -> 64.3% SWE Bench Verified: 80.8% -> 87.6% Terminal Bench: 65.4% -> 69.4% HLE no tools: 40.0% -> 46.9% GPQA: 91.3% -> 94.2% CharXiv no tools: 69.1%" / Xx.com
Quote Image 2 Claude Image 3 @claudeai · Apr 16 Introducing Claude Opus 4.7, our most capable Opus model yet. It handles long-running tasks with more rigor, follows instructions more precisely, and verifies its own outputs before reporting back. You can hand off your hardest work with less supervision. Image 4: Claude Opus 4.7 Benchmarks read image description ALT 4:07 PM · Apr 16, 2026 · 11.6K Views 9 6 118 5 Read 9 replies ## New to X? Sign up now to get your own personalized timeline! Sign up with Apple Create account By signing up, you agree to the Terms of Service and Privacy Policy, inc…
- [33] Claude Opus 4.7 results: early benchmarks, real-world feedback ...boringbot.substack.com
The Claude Opus 4.7 benchmarks on software engineering tasks show the clearest improvement. On SWE-Bench, the industry-standard benchmark for evaluating autonomous code repair across real GitHub issues, Opus 4.7 shows a meaningful step up from Opus 4.6, with early reported scores suggesting improvements in the range of 8–12 percentage points depending on task category (Source: community-reported testing via r/ClaudeAI and independent evaluations). On HumanEval, which tests functional code generation, Opus 4.7 continues to perform competitively. [...] > Opus 4.7 is an evolution, not a revoluti…
- [34] Lightspeed on X: "Claude Opus 4.7 is here. +11% on SWE-bench Pro. 87.6% on SWE-bench Verified. Agentic coding on tasks that used to need a human in the loop. Vision at 2,576px — 3x prior Claude models. Pricing held flat. A year ago, letting a model code unsupervised was a demo. Today, it's https://tx.com
Image 1: Square profile picture Lightspeed @lightspeedvp Claude Opus 4.7 is here. +11% on SWE-bench Pro. 87.6% on SWE-bench Verified. Agentic coding on tasks that used to need a human in the loop. Vision at 2,576px — 3x prior Claude models. Pricing held flat. A year ago, letting a model code unsupervised was a demo. Today, it's how engineering teams ship. Congrats to the entire @AnthropicAI team. Image 2: Image Quote Image 3 Claude Image 4 @claudeai · Apr 16 Introducing Claude Opus 4.7, our most capable Opus model yet. It handles long-running tasks with more rigor, follows instructions more p…