बेंचमार्क रिपोर्ट के आधार पर GPT-5.5 और Claude Opus 4.7 की तुलना करें।
GPT 5.5 कुल मिलाकर reasoning, terminal/agent execution और कई academic benchmarks में आगे दिखता है, जबकि Claude Opus 4.7 कठिन software engineering और multi tool orchestration में मजबूत है। इसलिए “बेहतर” मॉडल use case प...
GPT 5.5 कुल मिलाकर reasoning, terminal/agent execution और कई academic benchmarks में आगे दिखता है, जबकि Claude Opus 4.7 कठिन software engineering और multi tool orchestration में मजबूत है। इसलिए “बेहतर” मॉडल use case पर निर्भर है: general reasoning/terminal tasks के लिए GPT 5.5, और complex coding/agentic tool workflows
मुख्य निष्कर्ष
- GPT-5.5 कुल मिलाकर reasoning, terminal/agent execution और कई academic benchmarks में आगे दिखता है, जबकि Claude Opus 4.7 कठिन software-engineering और multi-tool orchestration में मजबूत है। इसलिए “बेहतर” मॉडल use case पर निर्भर है: general reasoning/terminal tasks के लिए GPT-5.5, औ
- **Coding: मिश्रित नतीजा**
शोध उत्तर
GPT-5.5 कुल मिलाकर reasoning, terminal/agent execution और कई academic benchmarks में आगे दिखता है, जबकि Claude Opus 4.7 कठिन software-engineering और multi-tool orchestration में मजबूत है। इसलिए “बेहतर” मॉडल use case पर निर्भर है: general reasoning/terminal tasks के लिए GPT-5.5, और complex coding/agentic tool workflows के लिए Opus 4.7 बेहतर विकल्प दिखता है।
-
Coding: मिश्रित नतीजा
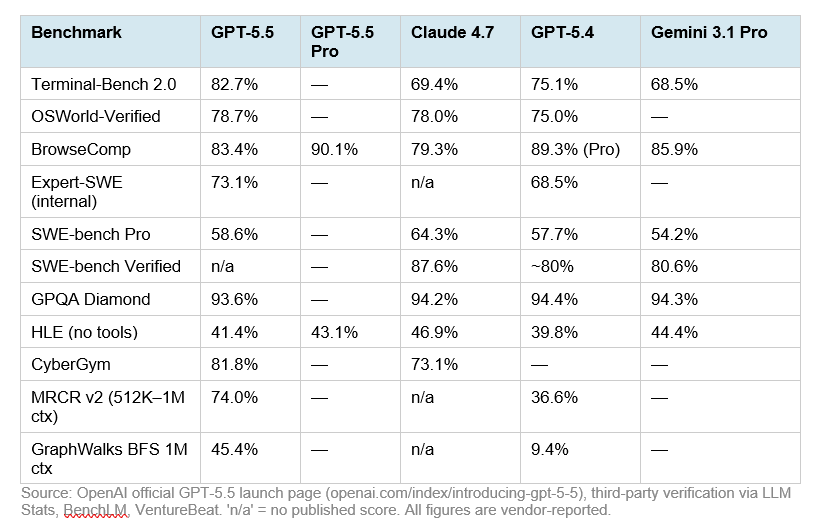
- SWE-Bench Verified में GPT-5.5 को मामूली बढ़त दी गई है: 88.7% बनाम Claude Opus 4.7 का 87.6% [
7].
- SWE-Bench Pro में Claude Opus 4.7 स्पष्ट रूप से आगे है: 64.3% बनाम GPT-5.5 का 58.6% [
7][
6].
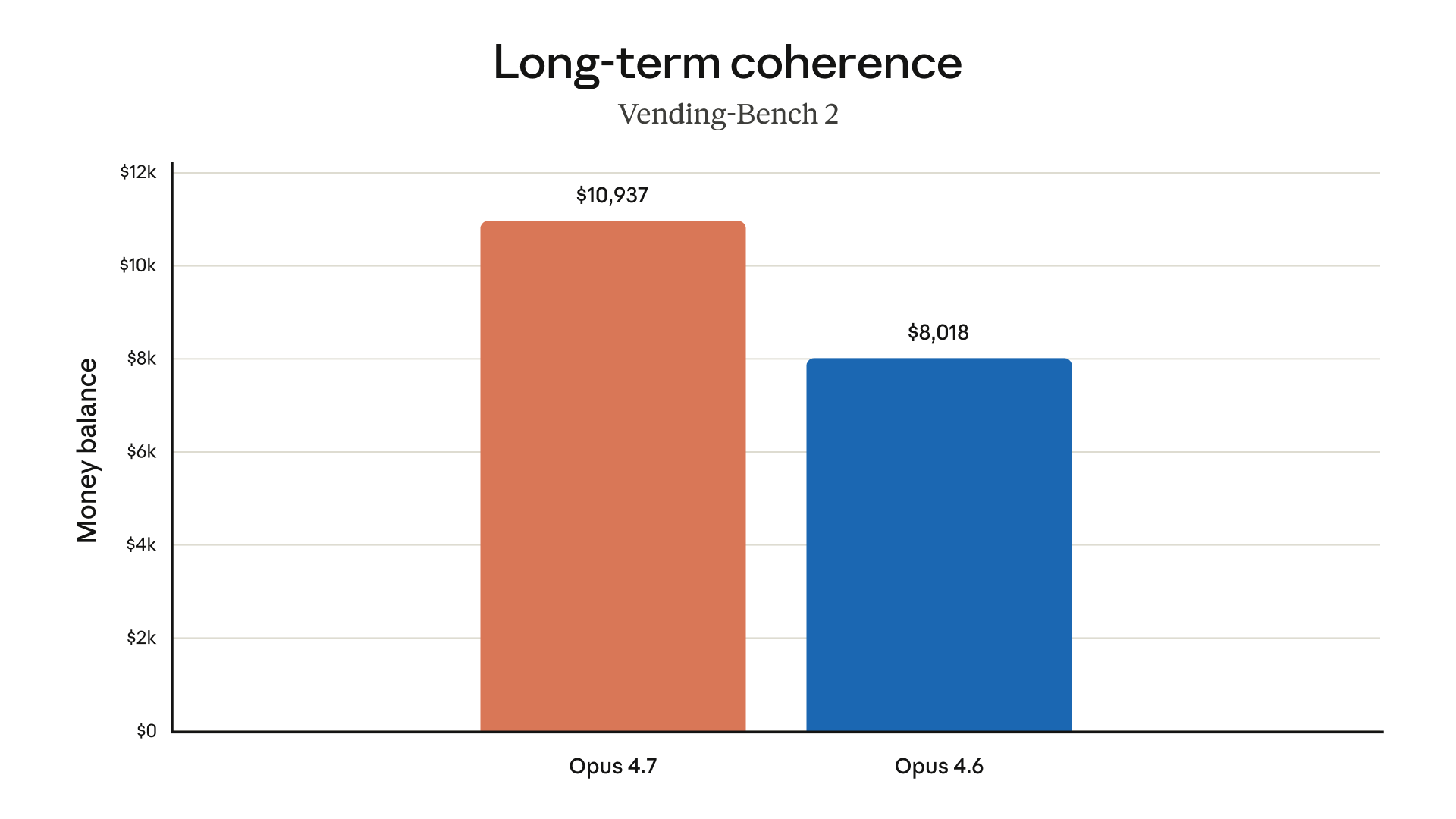
- Opus 4.7 के लिए रिपोर्टों में SWE-bench Pro पर Opus 4.6 से 53.4% से 64.3% तक सुधार बताया गया है, यानी कठिन real-world coding tasks में बड़ा लाभ [
3][
6].
- SWE-Bench Verified में GPT-5.5 को मामूली बढ़त दी गई है: 88.7% बनाम Claude Opus 4.7 का 87.6% [
-
Terminal / agent execution
- Terminal-Bench 2.0 में GPT-5.5 को 82.7% और Opus 4.7 को 69.4% बताया गया है, इसलिए shell/terminal-style execution tasks में GPT-5.5 मजबूत दिखता है [
12][
7].
- कुछ रिपोर्टों में GPT-5.5 के लिए Terminal-Bench 2.0 score 82.7% है, लेकिन Opus के public number को लेकर स्रोतों में असंगति है; इसलिए इस benchmark को थोड़ी सावधानी से पढ़ना चाहिए [
7][
12].
- Terminal-Bench 2.0 में GPT-5.5 को 82.7% और Opus 4.7 को 69.4% बताया गया है, इसलिए shell/terminal-style execution tasks में GPT-5.5 मजबूत दिखता है [
-
Tool use और orchestration
-
Academic / reasoning
- OpenAI की GPT-5.5 रिपोर्ट में FrontierMath Tier 1–3 पर GPT-5.5 को 51.7% और Claude Opus 4.7 को 43.8% बताया गया है [
15][
7].
- उसी रिपोर्ट में FrontierMath Tier 4 पर GPT-5.5 को 35.4% और Claude Opus 4.7 को 22.9% बताया गया है [
15][
7].
- GPQA Diamond में दोनों बहुत करीब हैं: GPT-5.5 93.6% और Claude Opus 4.7 94.2% [
15][
7].
- OpenAI की GPT-5.5 रिपोर्ट में FrontierMath Tier 1–3 पर GPT-5.5 को 51.7% और Claude Opus 4.7 को 43.8% बताया गया है [
-
निष्कर्ष
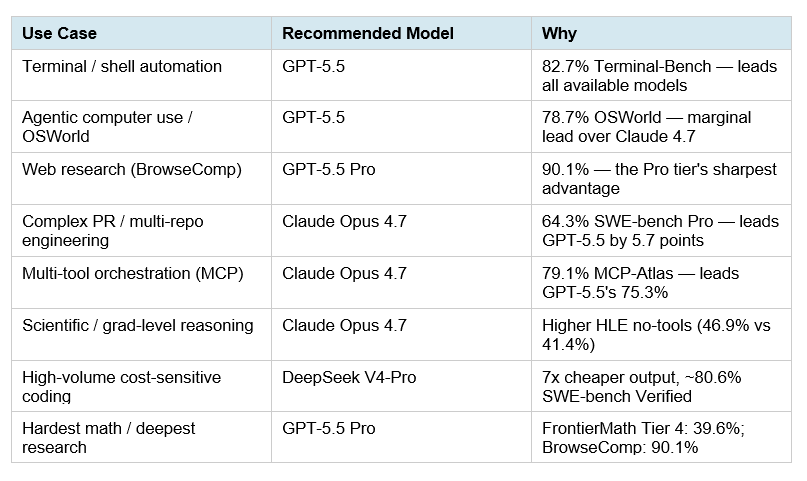
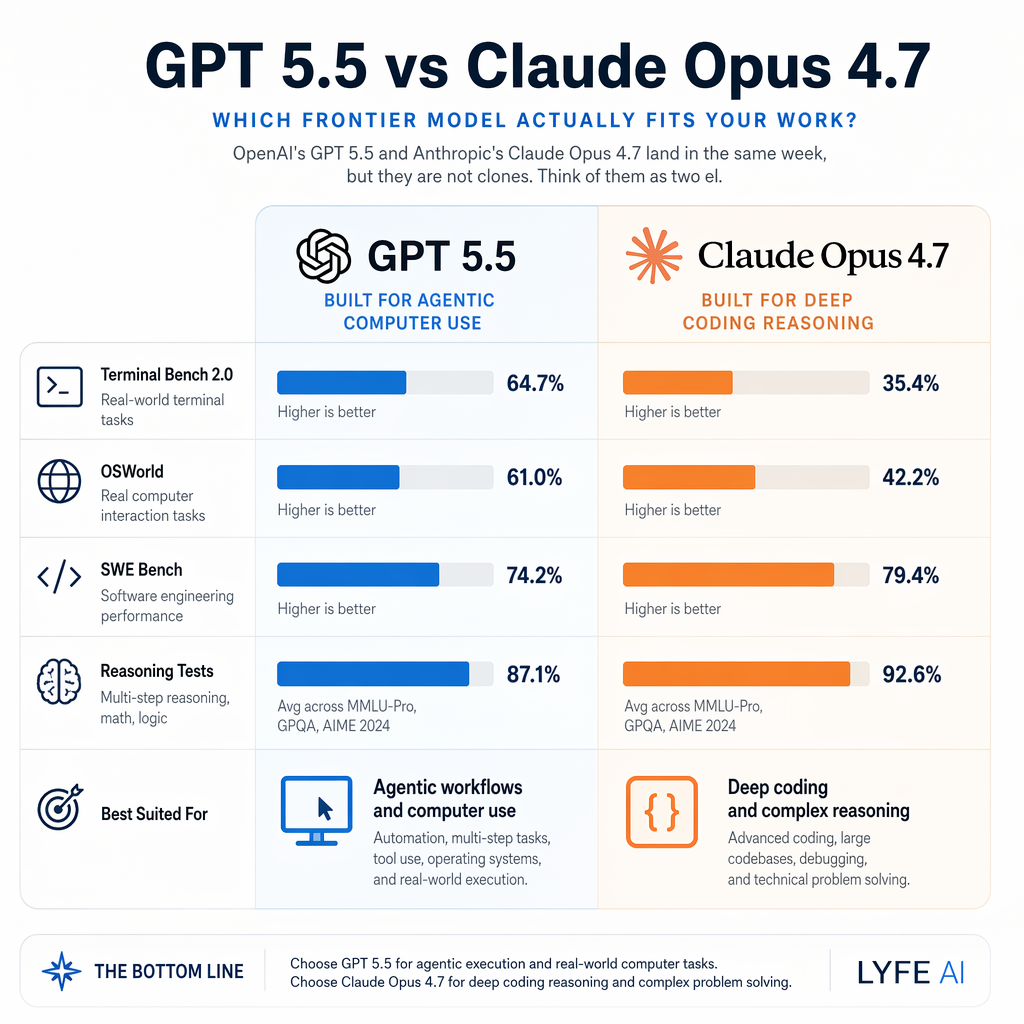
- GPT-5.5 चुनें अगर आपको broad reasoning, math-heavy tasks, terminal automation, या general-purpose high-performance assistant चाहिए।
- Claude Opus 4.7 चुनें अगर आपका मुख्य काम complex codebase changes, SWE-Bench Pro जैसे कठिन coding tasks, या multi-tool enterprise agents हैं।
- स्वतंत्र, समान harness पर चले benchmarks कम उपलब्ध हैं; official lab numbers और third-party summaries को सीधे “अंतिम सत्य” न मानकर workload-specific testing से validate करना बेहतर होगा।
सहायक दृश्य










अनुसंधान वार्तालाप
शोध प्रश्न
बेंचमार्क रिपोर्ट के आधार पर GPT-5.5 और Claude Opus 4.7 की तुलना करें।
उद्धृत उत्तर
GPT-5.5 कुल मिलाकर reasoning, terminal/agent execution और कई academic benchmarks में आगे दिखता है, जबकि Claude Opus 4.7 कठिन software-engineering और multi-tool orchestration में मजबूत है। इसलिए “बेहतर” मॉडल use case पर निर्भर है: general reasoning/terminal tasks के लिए GPT-5.5, और complex coding/agentic tool workflows के लिए Opus 4.7 बेहतर विकल्प दिखता है।
-
Coding: मिश्रित नतीजा
- SWE-Bench Verified में GPT-5.5 को मामूली बढ़त दी गई है: 88.7% बनाम Claude Opus 4.7 का 87.6% [
7].
- SWE-Bench Pro में Claude Opus 4.7 स्पष्ट रूप से आगे है: 64.3% बनाम GPT-5.5 का 58.6% [
7][
6].
- Opus 4.7 के लिए रिपोर्टों में SWE-bench Pro पर Opus 4.6 से 53.4% से 64.3% तक सुधार बताया गया है, यानी कठिन real-world coding tasks में बड़ा लाभ [
3][
6].
- SWE-Bench Verified में GPT-5.5 को मामूली बढ़त दी गई है: 88.7% बनाम Claude Opus 4.7 का 87.6% [
-
Terminal / agent execution
- Terminal-Bench 2.0 में GPT-5.5 को 82.7% और Opus 4.7 को 69.4% बताया गया है, इसलिए shell/terminal-style execution tasks में GPT-5.5 मजबूत दिखता है [
12][
7].
- कुछ रिपोर्टों में GPT-5.5 के लिए Terminal-Bench 2.0 score 82.7% है, लेकिन Opus के public number को लेकर स्रोतों में असंगति है; इसलिए इस benchmark को थोड़ी सावधानी से पढ़ना चाहिए [
7][
12].
- Terminal-Bench 2.0 में GPT-5.5 को 82.7% और Opus 4.7 को 69.4% बताया गया है, इसलिए shell/terminal-style execution tasks में GPT-5.5 मजबूत दिखता है [
-
Tool use और orchestration
-
Academic / reasoning
- OpenAI की GPT-5.5 रिपोर्ट में FrontierMath Tier 1–3 पर GPT-5.5 को 51.7% और Claude Opus 4.7 को 43.8% बताया गया है [
15][
7].
- उसी रिपोर्ट में FrontierMath Tier 4 पर GPT-5.5 को 35.4% और Claude Opus 4.7 को 22.9% बताया गया है [
15][
7].
- GPQA Diamond में दोनों बहुत करीब हैं: GPT-5.5 93.6% और Claude Opus 4.7 94.2% [
15][
7].
- OpenAI की GPT-5.5 रिपोर्ट में FrontierMath Tier 1–3 पर GPT-5.5 को 51.7% और Claude Opus 4.7 को 43.8% बताया गया है [
-
निष्कर्ष
- GPT-5.5 चुनें अगर आपको broad reasoning, math-heavy tasks, terminal automation, या general-purpose high-performance assistant चाहिए।
- Claude Opus 4.7 चुनें अगर आपका मुख्य काम complex codebase changes, SWE-Bench Pro जैसे कठिन coding tasks, या multi-tool enterprise agents हैं।
- स्वतंत्र, समान harness पर चले benchmarks कम उपलब्ध हैं; official lab numbers और third-party summaries को सीधे “अंतिम सत्य” न मानकर workload-specific testing से validate करना बेहतर होगा।
लोग पूछते भी हैं
"बेंचमार्क रिपोर्ट के आधार पर GPT-5.5 और Claude Opus 4.7 की तुलना करें।" का संक्षिप्त उत्तर क्या है?
GPT-5.5 कुल मिलाकर reasoning, terminal/agent execution और कई academic benchmarks में आगे दिखता है, जबकि Claude Opus 4.7 कठिन software-engineering और multi-tool orchestration में मजबूत है। इसलिए “बेहतर” मॉडल use case पर निर्भर है: general reasoning/terminal tasks के लिए GPT-5.5, औ
सबसे पहले सत्यापित करने योग्य मुख्य बिंदु क्या हैं?
GPT-5.5 कुल मिलाकर reasoning, terminal/agent execution और कई academic benchmarks में आगे दिखता है, जबकि Claude Opus 4.7 कठिन software-engineering और multi-tool orchestration में मजबूत है। इसलिए “बेहतर” मॉडल use case पर निर्भर है: general reasoning/terminal tasks के लिए GPT-5.5, औ **Coding: मिश्रित नतीजा**
मुझे आगे किस संबंधित विषय का पता लगाना चाहिए?
अन्य कोण और अतिरिक्त उद्धरणों के लिए "Codex बनाम Claude Code: कौन बेहतर है?" के साथ जारी रखें।
संबंधित पृष्ठ खोलेंमुझे इसकी तुलना किससे करनी चाहिए?
इस उत्तर को "So sánh một cách toàn diện benchmarks của DeepSeek V4 vs Claude Opus 4.7" के सामने क्रॉस-चेक करें।
संबंधित पृष्ठ खोलेंअपना शोध जारी रखें
सूत्र
- [1] GPT-5.5 vs Claude Opus 4.7: 2026 Frontier Showdown (Benchmarks)tokenmix.ai
Head-to-Head: The Numbers That Matter Benchmark GPT-5.5 Claude Opus 4.7 Winner --- --- SWE-Bench Verified 88.7% 87.6% GPT-5.5 by 1.1 SWE-Bench Pro 58.6% 64.3% Opus 4.7 by 5.7 MMLU 92.4% 91% GPT-5.5 Terminal-Bench 2.0 82.7% — GPT-5.5 (no public Opus number)...
- [2] GPT-5.5 vs Claude Opus 4.7: Pricing, Speed, Benchmarks - LLM Statsllm-stats.com
Within seven days, I had two new frontier models to compare against the workloads I run for LLM Stats:Claude Opus 4.7shipped on April 16, 2026, andGPT-5.5 on April 23. Both land at the same input price. Both ship 1M-token context. Both pitch significantly b...
- [3] GPT-5.5 vs Claude Opus 4.7: Real-World Coding Performance ...mindstudio.ai
SWE-Bench and Coding Tasks On SWE-Bench Verified — the standard benchmark for evaluating real GitHub issue resolution — both models score competitively at the top of the 2026 leaderboard. GPT-5.5 holds a slight edge on problems requiring precise tool use an...
- [4] GPT-5.5 vs Claude Opus 4.7: Which Model Wins for Agentic Work?beam.ai
Tool integration. On MCP Atlas (Scale AI's April 2026 update), Claude Opus 4.7 scores 79.1% versus GPT-5.5's 75.3%. For multi-model orchestration systems where agents need to call external tools, APIs, and services reliably, Opus 4.7 remains the stronger ch...
- [5] OpenAI's GPT-5.5 vs Claude Opus 4.7: Which is better? | Mashablemashable.com
Thanks for signing up! SWE-Bench Pro: GPT-5.5 scored 58.6; Opus 4.7 scored 64.3 percent Terminal-Bench 2.0: GPT-5.5 scored 82.7 percent; Opus 4.7 scored 69.4 percent Humanity's Last Exam: GPT-5.5 scored 40.6 percent; Opus 4.7 scored 31.2 percent\ Humanity's...
- [6] Claude Opus 4.7 vs GPT-5.5 - Detailed Performance & Feature Comparisondocsbot.ai
Claude Opus 4.7 Claude Opus 4.7 is Anthropic's most capable generally available Opus model (released April 16, 2026), focused on advanced software engineering, long-horizon autonomy, instruction following, and high-resolution multimodal understanding. It su...
- [7] GPT-5.5 vs Claude Opus 4.7: Benchmarks, Pricing & Coding ...lushbinary.com
1Release Context & What Changed The timing tells the story. Anthropic released Claude Opus 4.7 on April 16, 2026 — a focused upgrade that pushed SWE-bench Pro from 53.4% (Opus 4.6) to 64.3%, added high-resolution vision up to 3.75 megapixels, and introduced...
- [8] GPT 5.5 beats Claude Opus 4.7 : r/ArtificialInteligence - Redditreddit.com
Anyone can view, post, and comment to this community 0 0 Reddit RulesPrivacy PolicyUser AgreementYour Privacy ChoicesAccessibilityReddit, Inc. © 2026. All rights reserved. Expand Navigation Collapse Navigation RESOURCES About Reddit Adv...
- [9] GPT 5.5 Vs Claude Opus 4.7 Proves Benchmarks Need Context : r/AISEOInsiderreddit.com
GPT 5.5 feels like the model you use when you want to get a working version quickly. It can create files, move through steps, fix obvious errors, and keep the project moving without slowing everything down. That is useful for landing pages, prototypes, inte...
- [10] GPT-5.5 Is Here — I Tested It (And It Beats Claude Opus 4.7)medium.com
GPT-5.5 Is Here — I Tested It (And It Beats Claude Opus 4.7) by Joe Njenga AI Software Engineer Apr, 2026 Medium Sitemap Open in app Sign up Sign in Image 3: Joe Njenga Joe Njenga Follow 9 min read · 1 day ago Press enter or click to view image in full size...
- [11] I Tested GPT 5.5 vs Opus 4.7: What You Need to Know OpenAI just dropped GPT 5.5. The benchmarks look strong against Opus 4.7. But benchmarks only tell part of the story. So I ran 4 head-to-head… | Nate Herkelman | 39 commentslinkedin.com
LinkedIn© 2026 About Accessibility User Agreement Privacy Policy Your California Privacy Choices Cookie Policy Copyright Policy Brand Policy Guest Controls Community Guidelines العربية (Arabic) বাংলা (Bangla) Čeština (Czech) Dansk (Danish) Deutsch (German)...
- [12] It happened. ChatGPT 5.5 is out. We tested it for financefinstoryai.substack.com
AI In Finance It happened. ChatGPT 5.5 is out. We tested it for finance ChatGPT 5.5 beats Opus 4.7 in almost every benchmark. It's the best in class for knowledge work tasks. Every document, spreadsheet, presentation you create should go through 5.5 AI In F...
- [13] Best AI Model for MCP Tool Calling in 2026: Claude, GPT-5.4, Gemini 3.1 Pro, GLM-5.1 & More | MCP Playgroundmcpplaygroundonline.com
GPT-5.4 replaced GPT-4.1 as OpenAI's frontier — stronger agentic training, 89.3 weighted score on BenchLM's agentic leaderboard (highest among all models tested). Gemini 3.1 Pro replaced Gemini 2.5 Pro — Google's new frontier leads cross-server MCP coordina...
- [14] Claude Opus 4.7 Benchmark Full Analysis: Empirical Data Leading ...help.apiyi.com
Q2: Which is better, Claude Opus 4.7 or GPT-5.4? It depends on your use case. Opus 4.7 clearly leads in programming (SWE-bench Pro 64.3% vs 57.7%), tool invocation (MCP-Atlas +9.2 points), and Computer Use (78.0% vs 75.0%). However, GPT-5.4 holds the advant...
- [15] Claude Opus 4.7 Benchmarks Explained - Vellumvellum.ai
The strongest results are in the places that break production agents. SWE-bench Pro jumping from 53.4% to 64.3% means Opus 4.7 can handle the harder multi-language engineering tasks that Opus 4.6 regularly stumbled on. MCP-Atlas at 77.3%, best-in-class, mea...
- [16] Claude Opus 4.7 Is Here — Head-to-Head Benchmark Comparison with GPT 5.4, Gemini 3.1 Pro, and Mythos | Enersys Insightsenersys.co.th
Conclusion Opus 4.7 doesn't win everything — but it wins where it matters most for software development and enterprise AI. The ranking: 1 for coding (SWE-bench Pro, CursorBench) — leads all publicly available models 1 for agentic tasks (MCP-Atlas, Finance A...
- [17] Claude Opus 4.7: Anthropic's New Best (Available) Modeldatacamp.com
SWE-bench tests a model's ability to resolve real GitHub issues in open-source Python repositories. Pro is a harder variant with more complex issues. The 10.9-point gain over Opus 4.6 on SWE-bench Pro is the largest improvement in this release (percentage p...
- [18] Claude Opus 4.7: Benchmarks, Pricing, Context & What's Newllm-stats.com
Benchmarks Agentic coding Benchmark Opus 4.7 Opus 4.6 Delta --- --- SWE-bench Verified 87.6% 80.8% +6.8 SWE-bench Pro 64.3% 53.4% +10.9 Terminal-Bench 2.0 69.4% 65.4% +4.0 The jump on SWE-bench Pro (+10.9 points) is larger than on SWE-bench Verified, sugges...
- [19] Introducing Claude Opus 4.7 - Anthropicanthropic.com
CyberGym: Opus 4.6’s score has been updated from the originally reported 66.6 to 73.8, as we updated our harness parameters to better elicit cyber capability. SWE-bench Multimodal: We used an internal implementation for both Opus 4.7 and Opus 4.6. Scores ar...
- [20] Claude Opus 4.7 leads on SWE-bench and agentic ... - TNWthenextweb.com
What it means Opus 4.7 is not a paradigm shift. It is a meaningful improvement across every dimension that matters to the people who pay for Claude: better coding, better agentic reasoning, better vision, better instruction-following, and better resilience...
- [21] MCP Atlas Benchmark 2026: 13 model averages | BenchLM.aibenchlm.ai
Core Rankings Specialized Use Cases Dashboards Directories Guides & Lists Tools MCP Atlas A benchmark for tool-calling over Model Context Protocol integrations and external tools. Benchmark score on MCP Atlas — April 23, 2026 BenchLM mirrors the published s...
- [22] SWE-Bench Pro Leaderboard (2026): Why 46% Beats 81%morphllm.com
Dimension SWE-Bench Verified SWE-Bench Pro --- Tasks 500 1,865 Repositories 12 (all Python) 41 (Python, Go, TS, JS) Avg lines changed 11 (median: 4) 107.4 Avg files changed 1 4.1 Top score (Mar 2026) 80.9% (Claude Opus 4.5) 59% (agent systems) Contamination...
- [23] Claude Opus 4.7 Just Dropped — The Benchmarks Are Real - Mediummedium.com
5 min read · 3 days ago []( -- []( Listen Share Anthropic shipped Claude Opus 4.7 today. The benchmark numbers are the kind that make you reach for the update button without reading further: 87.6% on SWE-bench Verified, triple the production task completion...
- [24] Claude Opus 4.7 results: early benchmarks, real-world feedback ...boringbot.substack.com
The Claude Opus 4.7 benchmarks on software engineering tasks show the clearest improvement. On SWE-Bench, the industry-standard benchmark for evaluating autonomous code repair across real GitHub issues, Opus 4.7 shows a meaningful step up from Opus 4.6, wit...
- [25] GPT-5.5 Benchmarks Revealed: The 9 Numbers That ... - Kingy AIkingy.ai
Three items deserve flagging: Academic and Reasoning Eval GPT-5.5 GPT-5.4 GPT-5.5 Pro GPT-5.4 Pro Claude Opus 4.7 Gemini 3.1 Pro --- --- --- GPQA Diamond 93.6% 92.8% — 94.4% 94.2% 94.3% Humanity’s Last Exam (no tools) 41.4% 39.8% 43.1% 42.7% 46.9% 44.4% Hum...
- [26] GPT-5.5 is here: benchmarks, pricing, and what changes ... - Appwriteappwrite.io
Star on GitHub 55.8KGo to Console Start building for free Sign upGo to Console Start building for free Products Docs Pricing Customers Blog Changelog Star on GitHub 55.8K Blog/GPT-5.5 is here: benchmarks, pricing, and what changes for developers Apr 24, 202...
- [27] GPT-5.5: The Honest Take on OpenAI's Response to Opus ...alexlavaee.me
Benchmark GPT-5.5 GPT-5.4 Opus 4.7 Gemini 3.1 Pro --- --- Terminal-Bench 2.0 82.7% 75.1% 69.4% 68.5% SWE-Bench Pro (public)\ 58.6% 57.7% 64.3% 54.2% Expert-SWE (OpenAI internal) 73.1% 68.5% — — OSWorld-Verified 78.7% 75.0% 78.0% — MCP Atlas (tool use) 75.3%...
- [28] Introducing GPT-5.5 - OpenAIopenai.com
Academic EvalGPT-5.5GPT‑5.4GPT-5.5 ProGPT‑5.4 ProClaudeOpus 4.7Gemini 3.1 Pro GeneBench 25.0%19.0%33.2%25.6%-- FrontierMath Tier 1–3 51.7%47.6%52.4%50.0%43.8%36.9% FrontierMath Tier 4 35.4%27.1%39.6%38.0%22.9%16.7% BixBench 80.5%74.0%---- GPQA Diamond 93.6%...
- [29] OpenAI's GPT-5.5 Launches With 91.7% Benchmark Scoremexc.com
Timothy Morano Apr 23, 2026 18:49 OpenAI’s GPT-5.5 debuts with enhanced legal AI capabilities, scoring 91.7% on benchmarks. Available now for ChatGPT Plus and Pro users. OpenAI has officially unveiled GPT-5.5, its latest AI model, on April 23, 2026, pushing...
- [30] OpenAI's GPT-5.5 masters agentic coding with 82.7% benchmark ...interestingengineering.com
On SWE-Bench Pro, it reached 58.6%, solving more real-world GitHub issues in a single pass than earlier versions. The model also outperformed its predecessor in long-horizon engineering tasks measured by internal benchmarks. These tasks often take human dev...
- [31] What Is GPT-5.5 for Builders in 2026? | WaveSpeedAI Blogwavespeed.ai
Item Status --- Release date: April 23, 2026 Confirmed — OpenAI official Live in ChatGPT (Plus/Pro/Business/Enterprise) Confirmed — OpenAI official Live in Codex (Plus/Pro/Business/Enterprise/Edu/Go) Confirmed — OpenAI official 400K context in Codex Confirm...
- [32] Everything You Need to Know About GPT-5.5 - Vellumvellum.ai
SWE-bench Pro: the coding crown stays with Anthropic Claude Opus 4.7 scores 64.3% versus GPT-5.5's 58.6% — a 5.7-point gap on real GitHub issue resolution. OpenAI's system card includes an asterisk noting "evidence of memorization" from other labs on this e...
- [33] GPT-5.5: The Complete Guide (2026) - o-mega | AIo-mega.ai
On the five benchmarks where both GPT-5.5 and Mythos have published scores, Mythos wins four: SWE-bench Pro (77.8% vs 58.6%, a staggering 19-point gap), HLE no tools (56.8% vs 41.4%), HLE with tools (64.7% vs 52.2%), and OSWorld-Verified (79.6% vs 78.7%). G...
- [34] GPT-5.5 lands as OpenAI accelerates its model release cadence to ...startupfortune.com
Logo GPT-5.5 lands as OpenAI accelerates its model release cadence to near-monthly GPT-5.5 lands as OpenAI accelerates its model release cadence to near-monthly OpenAI released GPT-5.5 on April 23, 2026, just six weeks after GPT-5.4, and the model’s perform...
- [35] How OpenAI's recently released GPT-5.5 stacks up with Anthropic's ...rdworldonline.com
Research & Development World How OpenAI’s recently released GPT-5.5 stacks up with Anthropic’s gated Claude Mythos By Brian Buntz [Adobe Stock] TL;DR: Claude Mythos Preview appears to lead cleanly on six of nine overlapping rows, especially SWE-bench Pro an...
- [36] Model Drop: GPT-5.5handyai.substack.com
Headline benchmarks: Terminal-Bench 2.0 at 82.7% (Opus 4.7: 69.4%, Gemini 3.1 Pro: 68.5%). SWE-Bench Pro at 58.6% (Opus 4.7 still leads at 64.3%). OpenAI’s internal Expert-SWE eval, where tasks have a 20-hour median human completion time, at 73.1% (up from...