Deepseek v4 có những cải tiến gì so với Deepseek v3.2?
Theo các thông báo chính thức hiện có, DeepSeek V4 (đang ở bản preview) cải tiến rõ nhất so với V3.2 ở 4 mảng: ngữ cảnh dài 1M token, hiệu quả suy luận/chi phí tốt hơn qua dòng Flash, agentic coding mạnh hơn, và kiến...
Theo các thông báo chính thức hiện có, DeepSeek V4 (đang ở bản preview) cải tiến rõ nhất so với V3.2 ở 4 mảng: ngữ cảnh dài 1M token, hiệu quả suy luận/chi phí tốt hơn qua dòng Flash, agentic coding mạnh hơn, và kiến thức thế giới + reasoning được đẩy lên mức cạnh tranh với các model đóng hàng đầu.[1][4] Tuy vậy, DeepS
Bài học chính
Theo các thông báo chính thức hiện có, DeepSeek V4 (đang ở bản preview) cải tiến rõ nhất so với V3.2 ở 4 mảng: ngữ cảnh dài 1M token, hiệu quả suy luận/chi phí tốt hơn qua dòng Flash, agentic coding mạnh hơn, và kiến thức thế giới + reasoning được đẩy lên mức cạnh tranh với các m
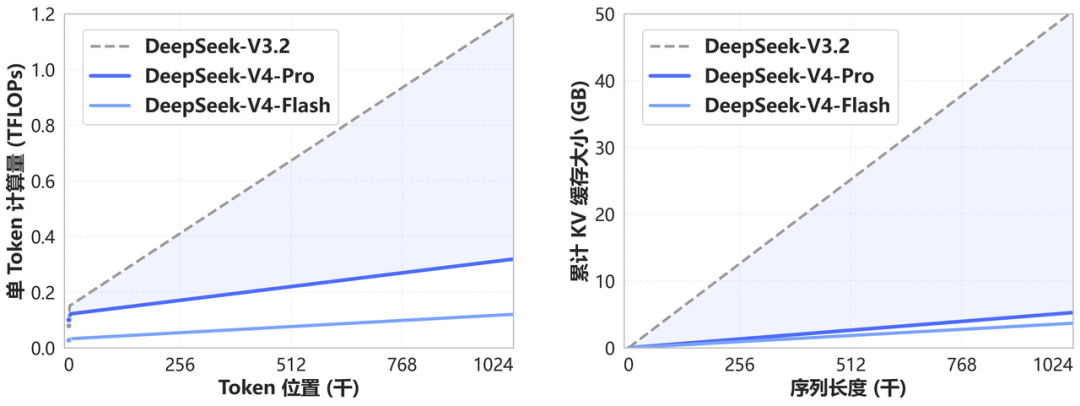
**Ngữ cảnh dài và hiệu quả hệ thống:** V4 giới thiệu attention mới với token-wise compression và DSA (DeepSeek Sparse Attention), đồng thời đưa 1M context thành mặc định trên các dịch vụ chính thức của DeepSeek.[1] Trong khi đó, V3.2 được truyền thông chủ yếu như một bản “reasoni
Câu trả lời nghiên cứu
Theo các thông báo chính thức hiện có, DeepSeek V4 (đang ở bản preview) cải tiến rõ nhất so với V3.2 ở 4 mảng: ngữ cảnh dài 1M token, hiệu quả suy luận/chi phí tốt hơn qua dòng Flash, agentic coding mạnh hơn, và kiến thức thế giới + reasoning được đẩy lên mức cạnh tranh với các model đóng hàng đầu.[1][4] Tuy vậy, DeepSeek chưa công bố trong phần release note ngắn một bảng “delta” V4-vs-V3.2 thật đầy đủ, nên nếu hỏi chênh lệch benchmark định lượng chi tiết thì hiện vẫn còn thiếu bằng chứng công khai trong các nguồn này.[1][4]
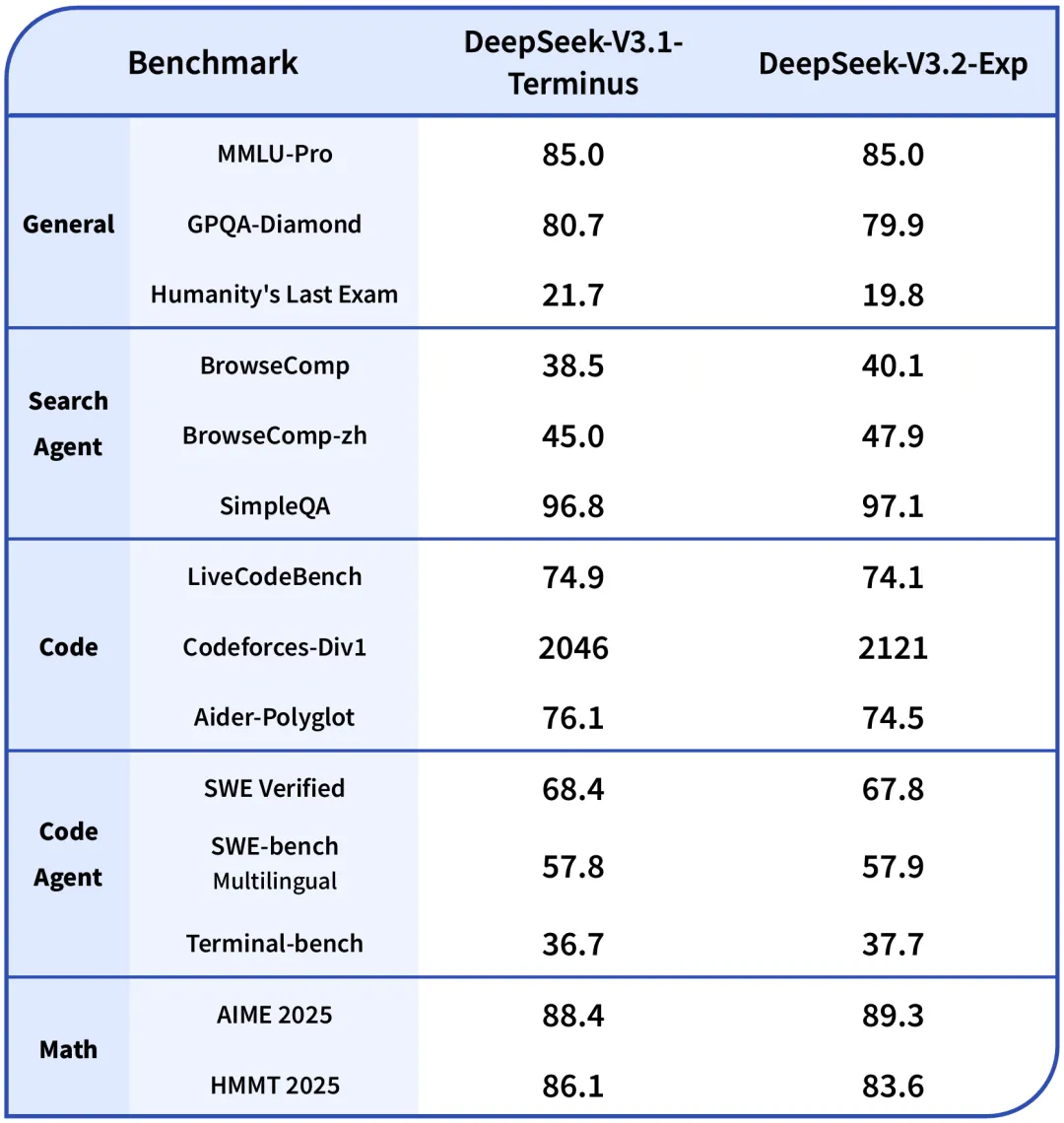
Ngữ cảnh dài và hiệu quả hệ thống: V4 giới thiệu attention mới với token-wise compression và DSA (DeepSeek Sparse Attention), đồng thời đưa 1M context thành mặc định trên các dịch vụ chính thức của DeepSeek.[1] Trong khi đó, V3.2 được truyền thông chủ yếu như một bản “reasoning-first for agents”, không nhấn mạnh dài ngữ cảnh như điểm bán chính.[4]
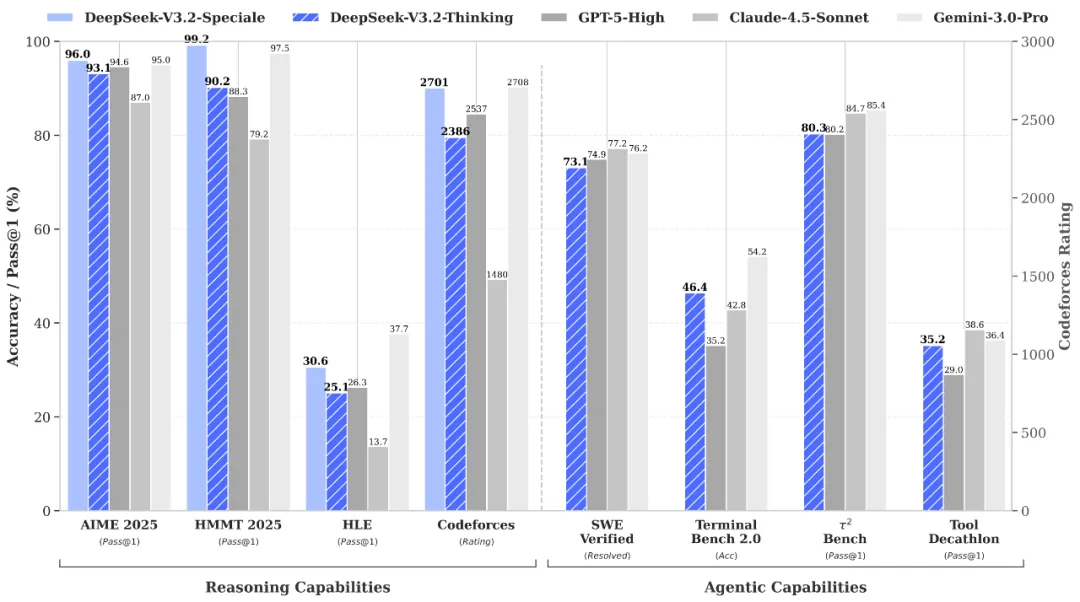
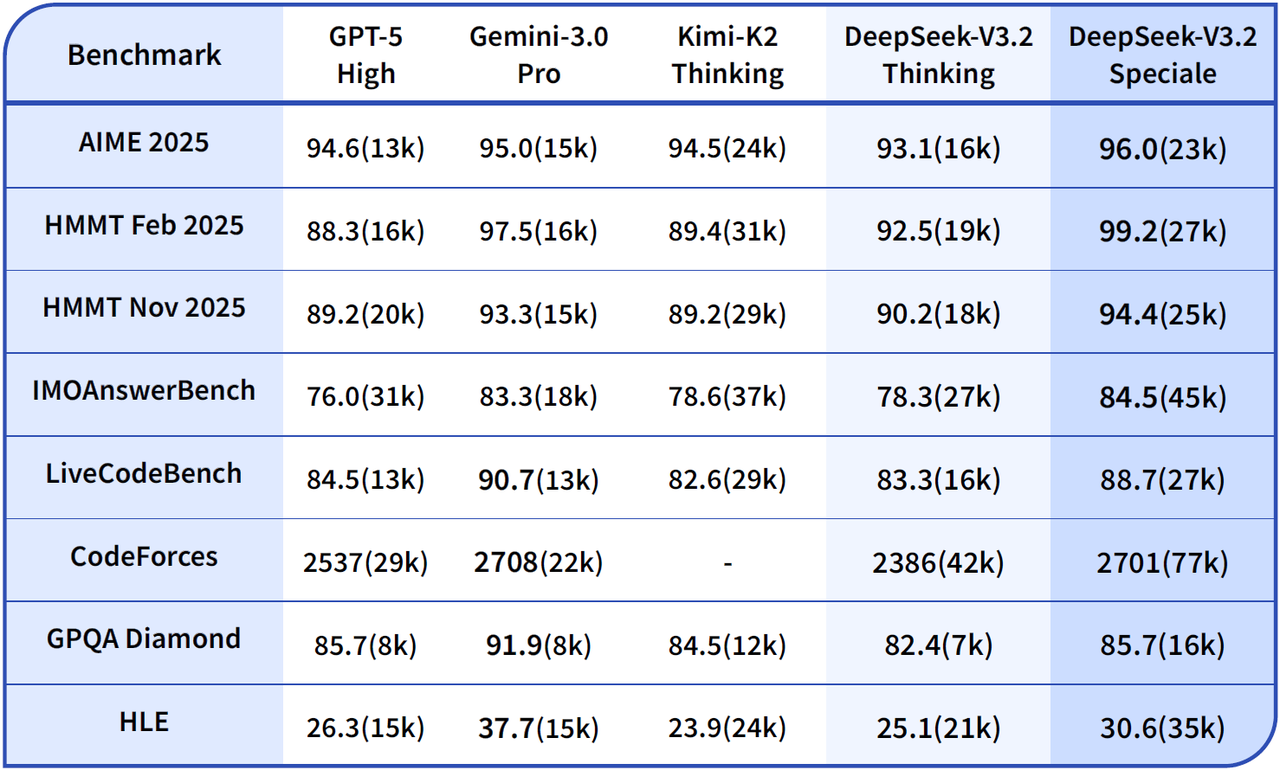
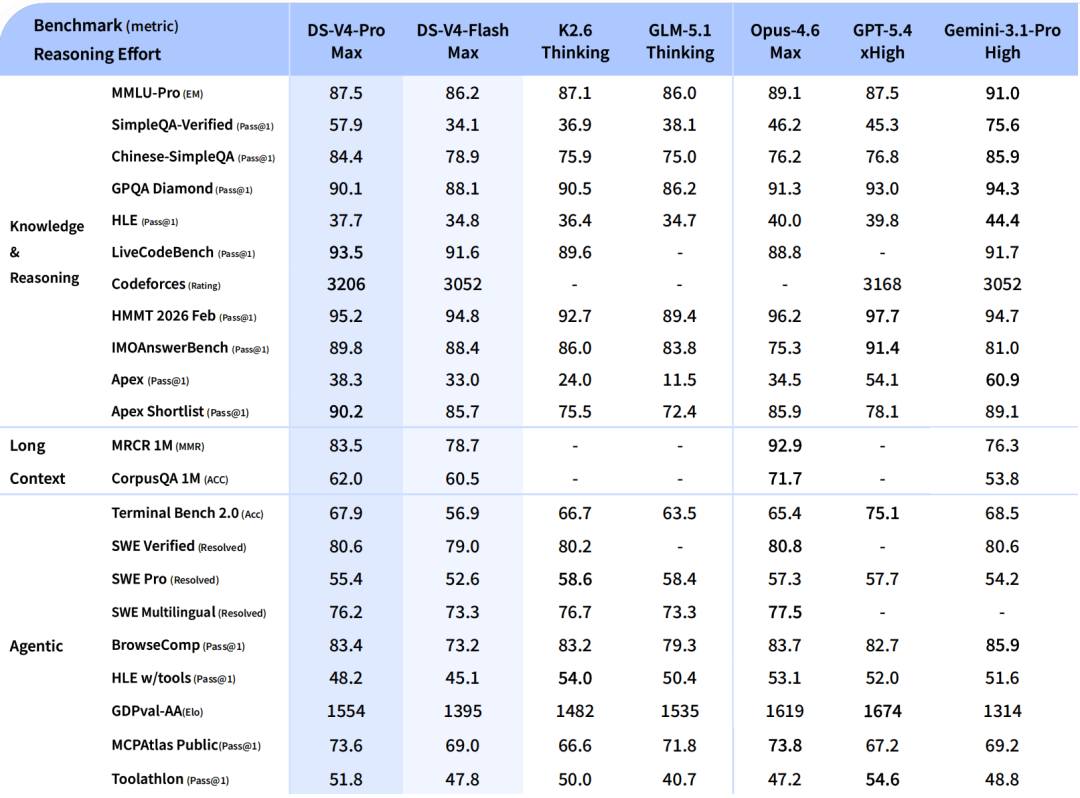
Dòng model mới linh hoạt hơn: V4 có hai biến thể rõ ràng là V4-Pro và V4-Flash; V4-Pro có 1.6T tổng tham số với 49B active params, còn V4-Flash có 284B tổng tham số với 13B active params.[1] DeepSeek nói V4-Flash vẫn tiệm cận V4-Pro về reasoning, ngang V4-Pro ở các agent task đơn giản, nhưng nhanh hơn và kinh tế hơn.[1] Ở V3.2, DeepSeek tách thành V3.2 và V3.2-Speciale; bản Speciale mạnh hơn về reasoning nhưng tốn token hơn, chỉ có API, và chưa hỗ trợ tool-use.[4]
Agentic coding mạnh hơn: V3.2 là bản đầu tiên của DeepSeek đưa “thinking” trực tiếp vào tool-use, dựa trên phương pháp tổng hợp dữ liệu huấn luyện agent mới bao phủ hơn 1.800 môi trường và hơn 85.000 chỉ dẫn phức tạp.[4] Sang V4, DeepSeek nâng định vị lên “open-source SOTA” trên các benchmark agentic coding, đồng thời nói model đã tích hợp mượt với Claude Code, OpenClaw và OpenCode, và đang được dùng cho agentic coding nội bộ của chính DeepSeek.[1]
Kiến thức thế giới và reasoning: Với V3.2, DeepSeek mô tả bản thường là “daily driver” ở mức GPT-5 và bản Speciale cạnh tranh với Gemini-3.0-Pro.[4] Với V4-Pro, DeepSeek công bố model dẫn đầu các open model hiện tại về world knowledge, và vượt các open model hiện tại ở Math/STEM/Coding, đồng thời tiệm cận các model đóng hàng đầu.[1]
Triển khai API thuận hơn: V4 hỗ trợ cả OpenAI ChatCompletions lẫn Anthropic API, và cả V4-Pro lẫn V4-Flash đều có hai chế độ Thinking / Non-Thinking.[1] Theo changelog chính thức, các tên model cũ deepseek-chat và deepseek-reasoner hiện đang trỏ sang non-thinking/thinking của deepseek-v4-flash, và sẽ bị ngừng hẳn vào 24/07/2026.[7]
Nếu cần nói thật ngắn gọn: V3.2 là bước nhảy lớn về reasoning + tool-use cho agent, còn V4 là bước tiếp theo đưa DeepSeek lên ngữ cảnh siêu dài, agentic coding mạnh hơn, và một cấu hình “Pro/Flash” cân bằng tốt hơn giữa chất lượng và chi phí.[1][4]
Nếu muốn, mình có thể làm tiếp một trong hai dạng:
bảng so sánh V3.2 / V3.2-Speciale / V4-Flash / V4-Pro
hoặc tóm tắt riêng các cải tiến của V4 cho lập trình và AI agent.
Hỗ trợ hình ảnh
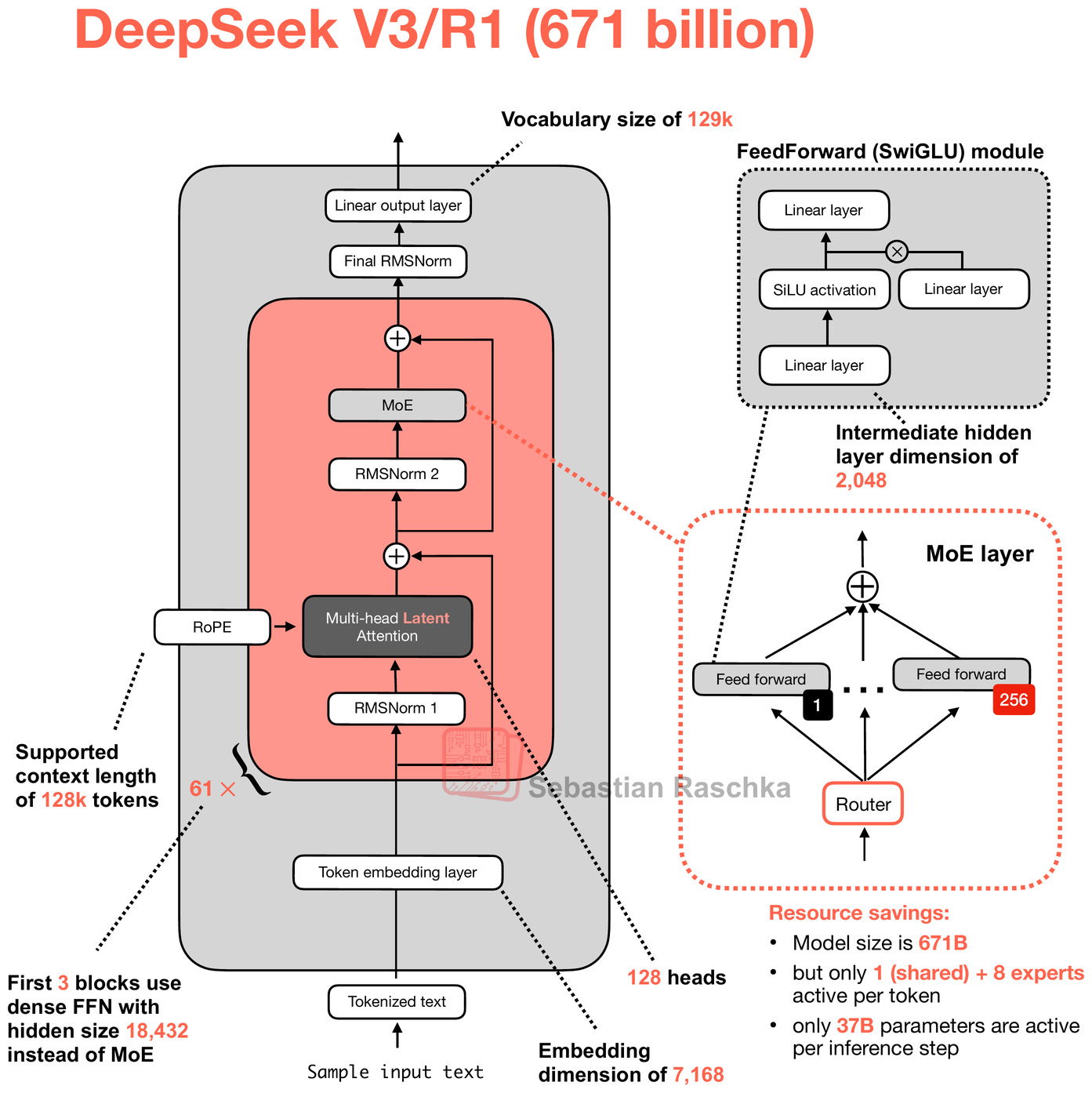
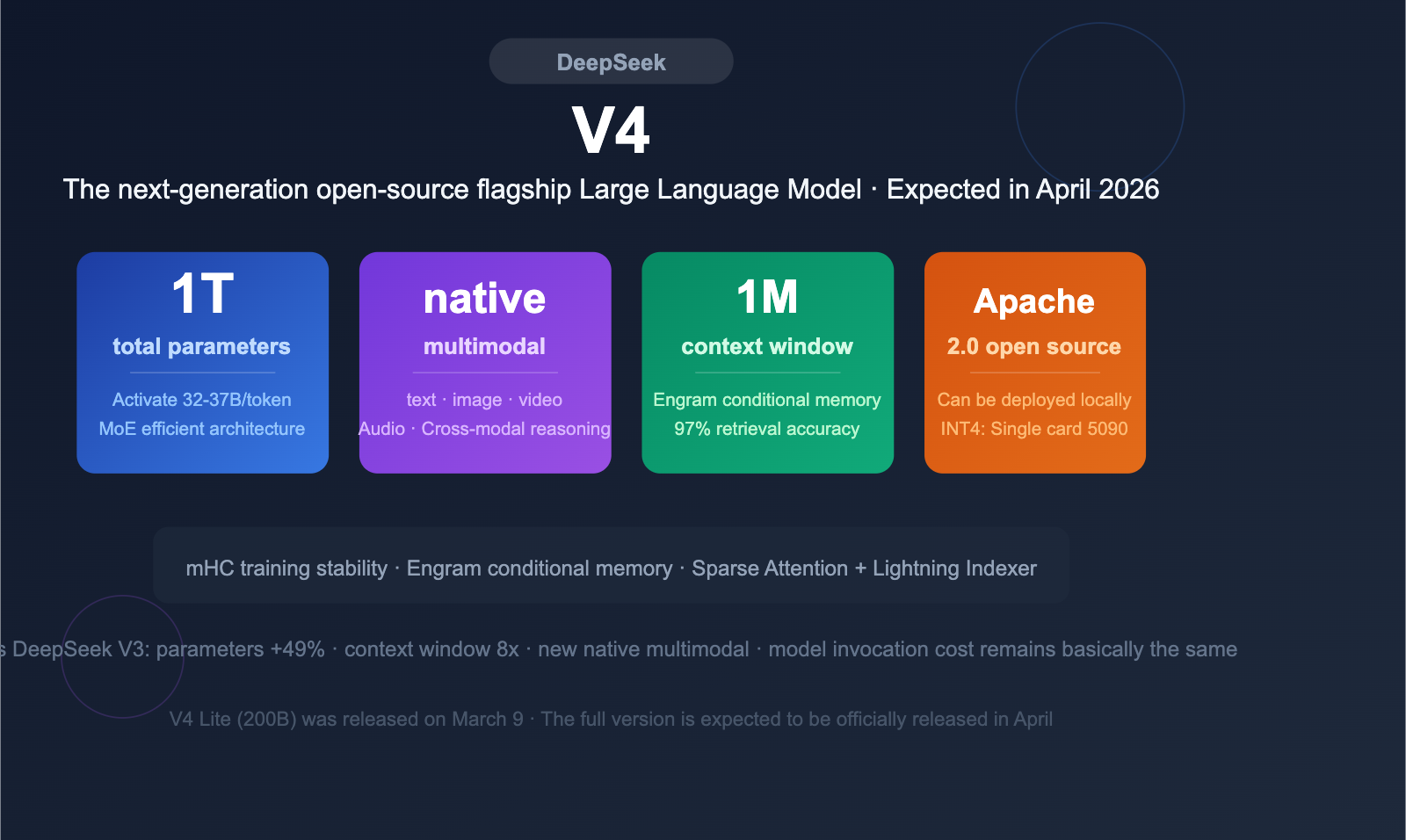
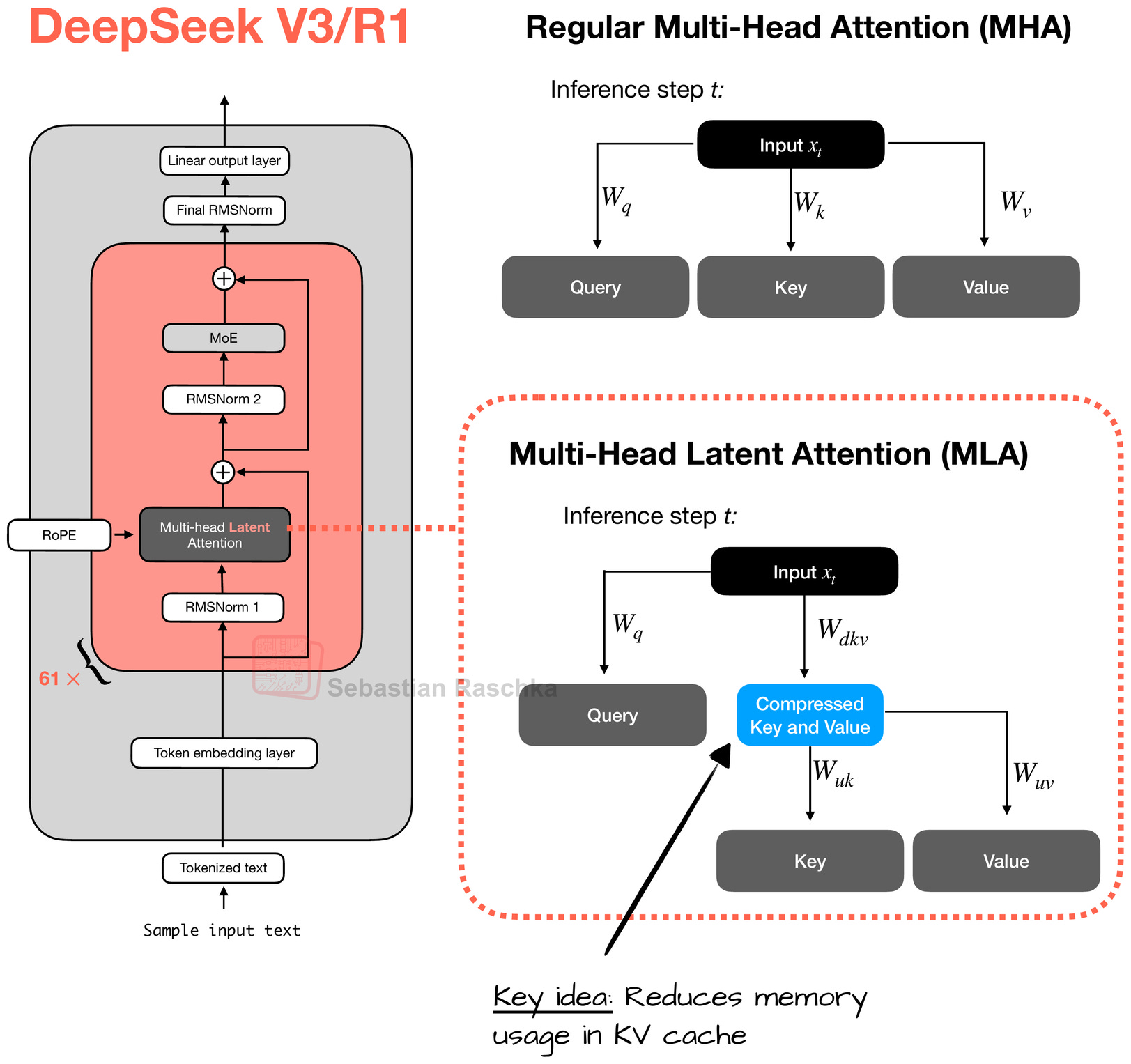
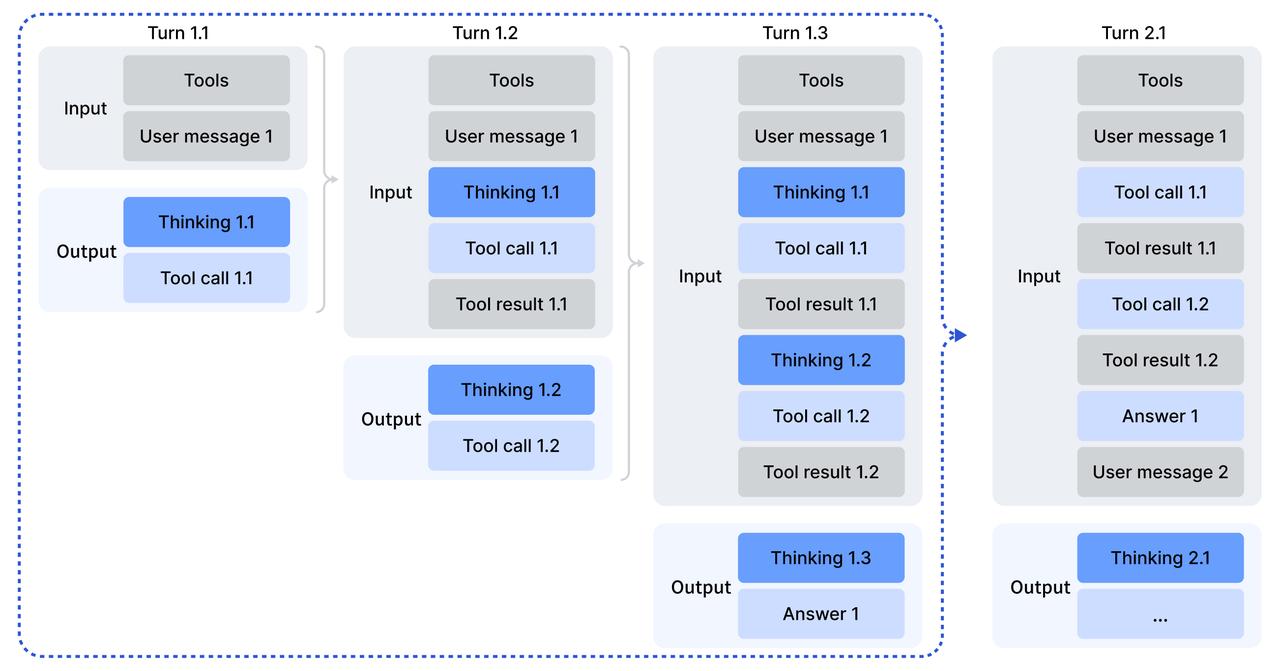
Deepseek V4 Coming Soon: Programming Capabilities May SurpassThe image displays an announcement about DeepSeek's upcoming V4 version, scheduled for mid-February 2026, highlighting features such as a coding breakthrough, surpassing competition with GPT, and a 20% discount on the full V3.2 version, with additional details on parameters, architecture, and release information.A Technical Tour of the DeepSeek Models from V3 to V3.2The image presents a detailed comparison of DeepSeek versions, highlighting improvements from V3/R1 with a model size of 671 billion parameters, increased context length, and resource savings, including specific architectural components like MoE layers, feedforward modules, and token embedding layers.DeepSeek V4 Preview: Comprehensive Analysis of 1T Parameter MoEThe image displays an infographic promoting DeepSeek V4, a next-generation open-source large language model expected in April 2026, highlighting key features such as 1 trillion parameters, native multimodal capabilities, a 1 million context window, and an open-source Apache 2.0 license.DeepSeek V4 Released: What's New in the Latest Model (2026)The image depicts a futuristic, digital illustration of a series of interconnected, glowing circular components labeled from I to VI, forming a curved structure, with technical data and a resolution of 1792 x 2024, representing the release of DeepSeek V4 in 2026.A Technical Tour of the DeepSeek Models from V3 to V3.2The image compares the architecture of DeepSeek V3/R1 with diagrams illustrating the improvements in multi-head latent attention and multi-head attention mechanisms using color-coded flowcharts and diagram labels.The image displays a comparison of performance metrics for DeepSeek V3.2-Exp API, highlighting reduced costs for cache hits, cache misses, aThe image displays a comparison of performance metrics for DeepSeek V3.2-Exp API, highlighting reduced costs for cache hits, cache misses, and total output, with original prices crossed out and new prices emphasized in bold.The diagram illustrates the step-by-step process flow of the DeepSeek V3.2 Release API, highlighting various sub-tasks such as input, thinkiThe diagram illustrates the step-by-step process flow of the DeepSeek V3.2 Release API, highlighting various sub-tasks such as input, thinking, tool calls, and output across multiple turns.The image displays a comparative chart of various language model API performance metrics, including DeepSeek-V3.2-Speciale, DeepSeek-V3.2-ThThe image displays a comparative chart of various language model API performance metrics, including DeepSeek-V3.2-Speciale, DeepSeek-V3.2-Thinking, GPT-5-High, Claude-4.5-Sonnet, and Gemini-3.0-Pro, across different reasoning and agent capabilities, with accuracy/pass rates on the left and codeforces ratings on the rigThe image displays a comparison table of open-source benchmark results for DeepSeek V3.1 and V3.2-Exp, featuring categories like general, seThe image displays a comparison table of open-source benchmark results for DeepSeek V3.1 and V3.2-Exp, featuring categories like general, search agent, code, code agent, and math, with specific performance scores for each benchmark.The image displays a comparison table of benchmark scores for various AI models, highlighting the performance updates of DeepSeek V3.2 in diThe image displays a comparison table of benchmark scores for various AI models, highlighting the performance updates of DeepSeek V3.2 in different evaluation scenarios.DeepSeek V4 Launch 2026: Open Source, 1M Token Context, Rivals GPTThe image displays a promotional graphic for DeepSeek V4, highlighting its 1 million token context, comparison with GPT-5, and showing a cost reduction from ₹420 to ₹25, with a mention of the April 2026 launch.DeepSeek V4 Preview Release | DeepSeek API DocsDeepSeek V4 Preview Release | DeepSeek API DocsDeepSeek V4 Preview Release | DeepSeek API DocsDeepSeek V4 Preview: Official Release, API Models, Open WeightsA promotional graphic showcases DeepSeek V4 with a large 3D whale logo, surrounded by icons representing an API, open weights, and pricing, emphasizing an official release, API models, and transparency.
Trao đổi nghiên cứu
Bạn
Câu hỏi nghiên cứu
Deepseek v4 có những cải tiến gì so với Deepseek v3.2?
Studio Global AI25 nguồn
Câu trả lời được trích dẫn
Theo các thông báo chính thức hiện có, DeepSeek V4 (đang ở bản preview) cải tiến rõ nhất so với V3.2 ở 4 mảng: ngữ cảnh dài 1M token, hiệu quả suy luận/chi phí tốt hơn qua dòng Flash, agentic coding mạnh hơn, và kiến thức thế giới + reasoning được đẩy lên mức cạnh tranh với các model đóng hàng đầu.[1][4] Tuy vậy, DeepSeek chưa công bố trong phần release note ngắn một bảng “delta” V4-vs-V3.2 thật đầy đủ, nên nếu hỏi chênh lệch benchmark định lượng chi tiết thì hiện vẫn còn thiếu bằng chứng công khai trong các nguồn này.[1][4]
Ngữ cảnh dài và hiệu quả hệ thống: V4 giới thiệu attention mới với token-wise compression và DSA (DeepSeek Sparse Attention), đồng thời đưa 1M context thành mặc định trên các dịch vụ chính thức của DeepSeek.[1] Trong khi đó, V3.2 được truyền thông chủ yếu như một bản “reasoning-first for agents”, không nhấn mạnh dài ngữ cảnh như điểm bán chính.[4]
Dòng model mới linh hoạt hơn: V4 có hai biến thể rõ ràng là V4-Pro và V4-Flash; V4-Pro có 1.6T tổng tham số với 49B active params, còn V4-Flash có 284B tổng tham số với 13B active params.[1] DeepSeek nói V4-Flash vẫn tiệm cận V4-Pro về reasoning, ngang V4-Pro ở các agent task đơn giản, nhưng nhanh hơn và kinh tế hơn.[1] Ở V3.2, DeepSeek tách thành V3.2 và V3.2-Speciale; bản Speciale mạnh hơn về reasoning nhưng tốn token hơn, chỉ có API, và chưa hỗ trợ tool-use.[4]
Agentic coding mạnh hơn: V3.2 là bản đầu tiên của DeepSeek đưa “thinking” trực tiếp vào tool-use, dựa trên phương pháp tổng hợp dữ liệu huấn luyện agent mới bao phủ hơn 1.800 môi trường và hơn 85.000 chỉ dẫn phức tạp.[4] Sang V4, DeepSeek nâng định vị lên “open-source SOTA” trên các benchmark agentic coding, đồng thời nói model đã tích hợp mượt với Claude Code, OpenClaw và OpenCode, và đang được dùng cho agentic coding nội bộ của chính DeepSeek.[1]
Kiến thức thế giới và reasoning: Với V3.2, DeepSeek mô tả bản thường là “daily driver” ở mức GPT-5 và bản Speciale cạnh tranh với Gemini-3.0-Pro.[4] Với V4-Pro, DeepSeek công bố model dẫn đầu các open model hiện tại về world knowledge, và vượt các open model hiện tại ở Math/STEM/Coding, đồng thời tiệm cận các model đóng hàng đầu.[1]
Triển khai API thuận hơn: V4 hỗ trợ cả OpenAI ChatCompletions lẫn Anthropic API, và cả V4-Pro lẫn V4-Flash đều có hai chế độ Thinking / Non-Thinking.[1] Theo changelog chính thức, các tên model cũ deepseek-chat và deepseek-reasoner hiện đang trỏ sang non-thinking/thinking của deepseek-v4-flash, và sẽ bị ngừng hẳn vào 24/07/2026.[7]
Nếu cần nói thật ngắn gọn: V3.2 là bước nhảy lớn về reasoning + tool-use cho agent, còn V4 là bước tiếp theo đưa DeepSeek lên ngữ cảnh siêu dài, agentic coding mạnh hơn, và một cấu hình “Pro/Flash” cân bằng tốt hơn giữa chất lượng và chi phí.[1][4]
Nếu muốn, mình có thể làm tiếp một trong hai dạng:
bảng so sánh V3.2 / V3.2-Speciale / V4-Flash / V4-Pro
hoặc tóm tắt riêng các cải tiến của V4 cho lập trình và AI agent.
Người ta cũng hỏi
Câu trả lời ngắn gọn cho "Deepseek v4 có những cải tiến gì so với Deepseek v3.2?" là gì?
Theo các thông báo chính thức hiện có, DeepSeek V4 (đang ở bản preview) cải tiến rõ nhất so với V3.2 ở 4 mảng: ngữ cảnh dài 1M token, hiệu quả suy luận/chi phí tốt hơn qua dòng Flash, agentic coding mạnh hơn, và kiến thức thế giới + reasoning được đẩy lên mức cạnh tranh với các m
Những điểm chính cần xác nhận đầu tiên là gì?
Theo các thông báo chính thức hiện có, DeepSeek V4 (đang ở bản preview) cải tiến rõ nhất so với V3.2 ở 4 mảng: ngữ cảnh dài 1M token, hiệu quả suy luận/chi phí tốt hơn qua dòng Flash, agentic coding mạnh hơn, và kiến thức thế giới + reasoning được đẩy lên mức cạnh tranh với các m **Ngữ cảnh dài và hiệu quả hệ thống:** V4 giới thiệu attention mới với token-wise compression và DSA (DeepSeek Sparse Attention), đồng thời đưa 1M context thành mặc định trên các dịch vụ chính thức của DeepSeek.[1] Trong khi đó, V3.2 được truyền thông chủ yếu như một bản “reasoni
Tôi nên khám phá chủ đề liên quan nào tiếp theo?
Tiếp tục với "Tìm kiếm và kiểm chứng thông tin: Làm sao triển khai hoặc tích hợp Kimi K2.6 vào app / production workflow?" để có góc nhìn khác và trích dẫn bổ sung.
Kiểm tra chéo câu trả lời này với "Show me top 5 trending search question Vietnamese users often ask about Kimi K2.6 now. Show me both Vietnamese language & English version wi".
Sebastian Raschka, PhD Dec 03, 2025 264 13 28 Share Last updated: January 1st, 2026 Similar to DeepSeek V3, the team released their new flagship model over a major US holiday weekend. Given DeepSeek V3.2’s really good performance (on GPT-5 and Gemini 3.0 Pro) level, and the fact that it’s also available as an open-weight model, it’s definitely worth a closer look. Image 5 Figure 1: Benchmark comparison between DeepSeek V3.2 and proprietary flagship models. This is an annotated figure from the DeepSeek V3.2 report. [...] There are several improvements to the training pipeline, for example, GRP…
_Editor's Note (March 2026):__DeepSeek V4 has not been officially released as of publication. While a "V4 Lite" briefly appeared on DeepSeek's platform in early March 2026, the full model remains unreleased. Multiple sources — including Dataconomy (citing Chinese tech outlet Whale Lab) and the Financial Times — have reported imminent launch dates that have since passed. This article analyses three research papers published by DeepSeek between late December 2025 and mid-January 2026 — on Engram conditional memory, manifold-constrained hyper-connections (mHC), and DeepSeek Sparse Attention — th…
⚠️ Note: deepseek-chat & deepseek-reasoner will be fully retired and inaccessible after Jul 24th, 2026, 15:59 (UTC Time). (Currently routing to deepseek-v4-flash non-thinking/thinking). Image 7 🔹 Amid recent attention, a quick reminder: please rely only on our official accounts for DeepSeek news. Statements from other channels do not reflect our views. 🔹 Thank you for your continued trust. We remain committed to longtermism, advancing steadily toward our ultimate goal of AGI. Previous Get User BalanceNext DeepSeek-V3.2 Release DeepSeek-V4-Pro DeepSeek-V4-Flash Structural Innovation & Ultra-…
April 3: Reuters, citing The Information, reported that DeepSeek's V4 model will likely launch in the "next few weeks" and will run on Huawei's newest chips. The report also said DeepSeek has spent the past few months working with Huawei and Cambricon to rewrite parts of the model stack and run testing, while developing two additional V4 variants optimized for different capabilities. Reuters Officially verifiable on April 6: DeepSeek's public API documentation still does not show a V4 model ID, pricing page, or release announcement. The docs explicitly state that deepseek-chat and `deepseek…
What it is: The latest flagship from the DeepSeek team. If DeepSeek v3.2 sets the standard for cost-effective open-source coding models, v4 pushes the boundaries of logic and memory using proprietary Manifold-Constrained Hyper-Connections (mHC) and Engram Memory technologies. Key Benefit: Beyond just generating code snippets, v4 acts like a senior architect, understanding entire repository structures for cross-file reasoning and complex bug fixing. Status: Upcoming Release (Expected mid-February 2026). Why are we confident that DeepSeek v4 is the next game-changer? Because it solves the indus…
March 2026 -- DeepSeek V3 rewrote the rules for open-source AI when it launched in late 2024, proving that a Chinese AI lab could compete head-to-head with OpenAI and Anthropic on reasoning benchmarks while releasing weights for free. Now, DeepSeek V4 is the most anticipated open-source model of 2026 -- and after months of delays, leaks, and a surprise "V4 Lite" appearance, the full release appears imminent. This article compiles everything currently known about DeepSeek V4: its architecture, capabilities, benchmark claims, hardware story, and the long road to launch. Where information comes…
V4 would increase the total expert count while keeping active parameters per forward pass tightly controlled. The model grows, but the fraction engaged during inference stays small. Per-token cost is projected to remain at or below V3 levels even as overall capability scales up, though no pricing data exists yet to confirm this. For teams running high-throughput production workloads, that ratio matters more than raw parameter counts. Editorial note: If the cost-per-token holds at V3 levels while reasoning benchmarks improve meaningfully, V4 becomes a near-automatic upgrade for inference-heavy…
Release Date: When is DeepSeek V4 Coming Out? DeepSeek V4 has experienced a few delays. Initially rumored for mid-February 2026 around the Lunar New Year, the timeline was pushed back due to massive engineering challenges of training on new hardware architectures. ✅ V4 Lite (Sealion-lite): On March 9, 2026, an unannounced "V4 Lite" version (~200B parameters) appeared on the DeepSeek platform, effectively validating the core architecture. 🚀 V4 Flagship: The full 1T-parameter model is now widely predicted for an April 2026 launch. [...] # DeepSeek V4: 1T Parameter AI Model Guide | Independe…
March 3, 2026 · 1 min read ## TL;DR DeepSeek V4 launches this week. It is a 1-trillion-parameter MoE model with a 1M-token context window, three new architectural techniques, and native multimodal support. Pre-release claims put it at 80-85% SWE-bench Verified and 90% HumanEval. API pricing is expected around $0.14/M input tokens, roughly 20-50x cheaper than Western frontier models. The numbers are from internal DeepSeek benchmarks only. Independent evaluations will follow. ### What it is A 1T-parameter mixture-of-experts LLM with native multimodal input (text, image, video), 1M-token context…
DeepSeek-V3 scaled further to 256 experts with 1 shared expert, and increased routing to topk=8. The architecture became more sophisticated in how it managed experts, and introduced a new communication system called DeepEP that makes expert coordination more efficient. Once the network sparsity was well-optimized, attention became the next target for improvement. As the core module of the Transformer architecture, attention is where each token in a sequence analyzes and weights the importance of every other token to understand context and relationships. Attention presents a different challeng…
DeepSeek V4 Update is INSANE! Image 7 Julian Goldie SEO Julian Goldie SEO 378K subscribers Join Subscribe Subscribed 206 Share Save Download Download 12K views 13 days ago 12,425 views • Apr 9, 2026 Want to make money and save time with AI? Get AI Coaching, Support & Courses 👉 Get the video notes + links to the tools → ...more How this was made Altered or synthetic content Sound or visuals were significantly edited or digitally generated. Learn more ## Chapters View all Image 8 #### Intro – Why DeepSeek V4 changes the AI race #### Intro – Why DeepSeek V4 changes the AI race 0:00 #### Intro…
the user should supply the location and date.", "description": "Get weather of a location, the user should supply the location and date.", "parameters": { "parameters": { "type": "object", "type": "object", "properties": { "properties": { "location": { "type": "string", "description": "The city name" }, "location": { "type": "string", "description": "The city name" }, "date": { "type": "string", "description": "The date in format YYYY-mm-dd" }, "date": { "type": "string", "description": "The date in format YYYY-mm-dd" }, }, }, "required": ["location", [...] # The definition of the tools tools…
"name": "get_weather", "description": "Get weather of a location, the user should supply a location first.", "description": "Get weather of a location, the user should supply a location first.", "parameters": { "parameters": { "type": "object", "type": "object", "properties": { "properties": { "location": { "location": { "type": "string", "type": "string", "description": "The city and state, e.g. San Francisco, CA", "description": "The city and state, e.g. San Francisco, CA", } } [...] The execution flow of this example is as follows: 1. User: Asks about the current weather in Hangzhou 2. Mod…
🛠 Open Source Release 🔗 Model: 🔗 Tech report: 🔗 Key GPU kernels in TileLang & CUDA (use TileLang for rapid research prototyping!) ⚡️ Efficiency Gains 🧑💻 API Update 🛠 Open Source Release [...] Skip to main content # Introducing DeepSeek-V3.2-Exp 🚀 Introducing DeepSeek-V3.2-Exp — our latest experimental model! ✨ Built on V3.1-Terminus, it debuts DeepSeek Sparse Attention (DSA) for faster, more efficient training & inference on long context. 👉 Now live on App, Web, and API 💰 API prices cut by 50%+! ## ⚡️ Efficiency Gains 🤖 DSA achieves fine-grained sparse attention with minimal…
DeepSeek API Docs Logo DeepSeek API Docs Logo # Your First API Call The DeepSeek API uses an API format compatible with OpenAI. By modifying the configuration, you can use the OpenAI SDK or softwares compatible with the OpenAI API to access the DeepSeek API. | PARAM | VALUE | --- | | base_url \ |
| | api\_key | apply for an API key |
\ To be compatible with OpenAI, you can also use
as the
base_url
. But note that the
v1
here has NO relationship with the model's version.
base_urlv1 \ The deepseek-chat and deepseek-reasoner correspond to the model version DeepSeek-V3.2 (128…
DeepSeek API Docs Logo DeepSeek API Docs Logo # DeepSeek-R1 Release ⚡ Performance on par with OpenAI-o1 📖 Fully open-source model & technical report 🏆 Code and models are released under the MIT License: Distill & commercialize freely! 🌐 Website & API are live now! Try DeepThink at chat.deepseek.com today! 🔥 Bonus: Open-Source Distilled Models! 🔬 Distilled from DeepSeek-R1, 6 small models fully open-sourced 📏 32B & 70B models on par with OpenAI-o1-mini 🤝 Empowering the open-source community 🌍 Pushing the boundaries of open AI! 📜 License Update! 🔄 DeepSeek-R1 is now MIT licensed for c…
Still the best value in the market! 🔥 🌌 Open-source spirit + Longtermism to inclusive AGI 🌟 DeepSeek’s mission is unwavering. We’re thrilled to share our progress with the community and see the gap between open and closed models narrowing. 🚀 This is just the beginning! Look forward to multimodal support and other cutting-edge features in the DeepSeek ecosystem. 💡 Together, let’s push the boundaries of innovation! Biggest leap forward yet 🎉 What’s new in V3 💰 API Pricing Update Still the best value in the market! 🔥 [...] Skip to main content # 🚀 Introducing DeepSeek-V3 ## Biggest…
Câu trả lờiURL công khai24 thg 4, 202625 nguồn
Deepseek v4 có những cải tiến gì so với Deepseek v3.2?
Theo các thông báo chính thức hiện có, DeepSeek V4 (đang ở bản preview) cải tiến rõ nhất so với V3.2 ở 4 mảng: ngữ cảnh dài 1M token, hiệu quả suy luận/chi phí tốt hơn qua dòng Flash, agentic coding mạnh hơn, và kiến...
Theo các thông báo chính thức hiện có, DeepSeek V4 (đang ở bản preview) cải tiến rõ nhất so với V3.2 ở 4 mảng: ngữ cảnh dài 1M token, hiệu quả suy luận/chi phí tốt hơn qua dòng Flash, agentic coding mạnh hơn, và kiến thức thế giới + reasoning được đẩy lên mức cạnh tranh với các model đóng hàng đầu.[1][4] Tuy vậy, DeepS
Bài học chính
Theo các thông báo chính thức hiện có, DeepSeek V4 (đang ở bản preview) cải tiến rõ nhất so với V3.2 ở 4 mảng: ngữ cảnh dài 1M token, hiệu quả suy luận/chi phí tốt hơn qua dòng Flash, agentic coding mạnh hơn, và kiến thức thế giới + reasoning được đẩy lên mức cạnh tranh với các m
**Ngữ cảnh dài và hiệu quả hệ thống:** V4 giới thiệu attention mới với token-wise compression và DSA (DeepSeek Sparse Attention), đồng thời đưa 1M context thành mặc định trên các dịch vụ chính thức của DeepSeek.[1] Trong khi đó, V3.2 được truyền thông chủ yếu như một bản “reasoni
Câu trả lời nghiên cứu
Theo các thông báo chính thức hiện có, DeepSeek V4 (đang ở bản preview) cải tiến rõ nhất so với V3.2 ở 4 mảng: ngữ cảnh dài 1M token, hiệu quả suy luận/chi phí tốt hơn qua dòng Flash, agentic coding mạnh hơn, và kiến thức thế giới + reasoning được đẩy lên mức cạnh tranh với các model đóng hàng đầu.[1][4] Tuy vậy, DeepSeek chưa công bố trong phần release note ngắn một bảng “delta” V4-vs-V3.2 thật đầy đủ, nên nếu hỏi chênh lệch benchmark định lượng chi tiết thì hiện vẫn còn thiếu bằng chứng công khai trong các nguồn này.[1][4]
Ngữ cảnh dài và hiệu quả hệ thống: V4 giới thiệu attention mới với token-wise compression và DSA (DeepSeek Sparse Attention), đồng thời đưa 1M context thành mặc định trên các dịch vụ chính thức của DeepSeek.[1] Trong khi đó, V3.2 được truyền thông chủ yếu như một bản “reasoning-first for agents”, không nhấn mạnh dài ngữ cảnh như điểm bán chính.[4]
Dòng model mới linh hoạt hơn: V4 có hai biến thể rõ ràng là V4-Pro và V4-Flash; V4-Pro có 1.6T tổng tham số với 49B active params, còn V4-Flash có 284B tổng tham số với 13B active params.[1] DeepSeek nói V4-Flash vẫn tiệm cận V4-Pro về reasoning, ngang V4-Pro ở các agent task đơn giản, nhưng nhanh hơn và kinh tế hơn.[1] Ở V3.2, DeepSeek tách thành V3.2 và V3.2-Speciale; bản Speciale mạnh hơn về reasoning nhưng tốn token hơn, chỉ có API, và chưa hỗ trợ tool-use.[4]
Agentic coding mạnh hơn: V3.2 là bản đầu tiên của DeepSeek đưa “thinking” trực tiếp vào tool-use, dựa trên phương pháp tổng hợp dữ liệu huấn luyện agent mới bao phủ hơn 1.800 môi trường và hơn 85.000 chỉ dẫn phức tạp.[4] Sang V4, DeepSeek nâng định vị lên “open-source SOTA” trên các benchmark agentic coding, đồng thời nói model đã tích hợp mượt với Claude Code, OpenClaw và OpenCode, và đang được dùng cho agentic coding nội bộ của chính DeepSeek.[1]
Kiến thức thế giới và reasoning: Với V3.2, DeepSeek mô tả bản thường là “daily driver” ở mức GPT-5 và bản Speciale cạnh tranh với Gemini-3.0-Pro.[4] Với V4-Pro, DeepSeek công bố model dẫn đầu các open model hiện tại về world knowledge, và vượt các open model hiện tại ở Math/STEM/Coding, đồng thời tiệm cận các model đóng hàng đầu.[1]
Triển khai API thuận hơn: V4 hỗ trợ cả OpenAI ChatCompletions lẫn Anthropic API, và cả V4-Pro lẫn V4-Flash đều có hai chế độ Thinking / Non-Thinking.[1] Theo changelog chính thức, các tên model cũ deepseek-chat và deepseek-reasoner hiện đang trỏ sang non-thinking/thinking của deepseek-v4-flash, và sẽ bị ngừng hẳn vào 24/07/2026.[7]
Nếu cần nói thật ngắn gọn: V3.2 là bước nhảy lớn về reasoning + tool-use cho agent, còn V4 là bước tiếp theo đưa DeepSeek lên ngữ cảnh siêu dài, agentic coding mạnh hơn, và một cấu hình “Pro/Flash” cân bằng tốt hơn giữa chất lượng và chi phí.[1][4]
Nếu muốn, mình có thể làm tiếp một trong hai dạng:
bảng so sánh V3.2 / V3.2-Speciale / V4-Flash / V4-Pro
hoặc tóm tắt riêng các cải tiến của V4 cho lập trình và AI agent.
Hỗ trợ hình ảnh
Deepseek V4 Coming Soon: Programming Capabilities May SurpassThe image displays an announcement about DeepSeek's upcoming V4 version, scheduled for mid-February 2026, highlighting features such as a coding breakthrough, surpassing competition with GPT, and a 20% discount on the full V3.2 version, with additional details on parameters, architecture, and release information.A Technical Tour of the DeepSeek Models from V3 to V3.2The image presents a detailed comparison of DeepSeek versions, highlighting improvements from V3/R1 with a model size of 671 billion parameters, increased context length, and resource savings, including specific architectural components like MoE layers, feedforward modules, and token embedding layers.DeepSeek V4 Preview: Comprehensive Analysis of 1T Parameter MoEThe image displays an infographic promoting DeepSeek V4, a next-generation open-source large language model expected in April 2026, highlighting key features such as 1 trillion parameters, native multimodal capabilities, a 1 million context window, and an open-source Apache 2.0 license.DeepSeek V4 Released: What's New in the Latest Model (2026)The image depicts a futuristic, digital illustration of a series of interconnected, glowing circular components labeled from I to VI, forming a curved structure, with technical data and a resolution of 1792 x 2024, representing the release of DeepSeek V4 in 2026.A Technical Tour of the DeepSeek Models from V3 to V3.2The image compares the architecture of DeepSeek V3/R1 with diagrams illustrating the improvements in multi-head latent attention and multi-head attention mechanisms using color-coded flowcharts and diagram labels.The image displays a comparison of performance metrics for DeepSeek V3.2-Exp API, highlighting reduced costs for cache hits, cache misses, aThe image displays a comparison of performance metrics for DeepSeek V3.2-Exp API, highlighting reduced costs for cache hits, cache misses, and total output, with original prices crossed out and new prices emphasized in bold.The diagram illustrates the step-by-step process flow of the DeepSeek V3.2 Release API, highlighting various sub-tasks such as input, thinkiThe diagram illustrates the step-by-step process flow of the DeepSeek V3.2 Release API, highlighting various sub-tasks such as input, thinking, tool calls, and output across multiple turns.The image displays a comparative chart of various language model API performance metrics, including DeepSeek-V3.2-Speciale, DeepSeek-V3.2-ThThe image displays a comparative chart of various language model API performance metrics, including DeepSeek-V3.2-Speciale, DeepSeek-V3.2-Thinking, GPT-5-High, Claude-4.5-Sonnet, and Gemini-3.0-Pro, across different reasoning and agent capabilities, with accuracy/pass rates on the left and codeforces ratings on the rigThe image displays a comparison table of open-source benchmark results for DeepSeek V3.1 and V3.2-Exp, featuring categories like general, seThe image displays a comparison table of open-source benchmark results for DeepSeek V3.1 and V3.2-Exp, featuring categories like general, search agent, code, code agent, and math, with specific performance scores for each benchmark.The image displays a comparison table of benchmark scores for various AI models, highlighting the performance updates of DeepSeek V3.2 in diThe image displays a comparison table of benchmark scores for various AI models, highlighting the performance updates of DeepSeek V3.2 in different evaluation scenarios.DeepSeek V4 Launch 2026: Open Source, 1M Token Context, Rivals GPTThe image displays a promotional graphic for DeepSeek V4, highlighting its 1 million token context, comparison with GPT-5, and showing a cost reduction from ₹420 to ₹25, with a mention of the April 2026 launch.DeepSeek V4 Preview Release | DeepSeek API DocsDeepSeek V4 Preview Release | DeepSeek API DocsDeepSeek V4 Preview Release | DeepSeek API DocsDeepSeek V4 Preview: Official Release, API Models, Open WeightsA promotional graphic showcases DeepSeek V4 with a large 3D whale logo, surrounded by icons representing an API, open weights, and pricing, emphasizing an official release, API models, and transparency.
Trao đổi nghiên cứu
Bạn
Câu hỏi nghiên cứu
Deepseek v4 có những cải tiến gì so với Deepseek v3.2?
Studio Global AI25 nguồn
Câu trả lời được trích dẫn
Theo các thông báo chính thức hiện có, DeepSeek V4 (đang ở bản preview) cải tiến rõ nhất so với V3.2 ở 4 mảng: ngữ cảnh dài 1M token, hiệu quả suy luận/chi phí tốt hơn qua dòng Flash, agentic coding mạnh hơn, và kiến thức thế giới + reasoning được đẩy lên mức cạnh tranh với các model đóng hàng đầu.[1][4] Tuy vậy, DeepSeek chưa công bố trong phần release note ngắn một bảng “delta” V4-vs-V3.2 thật đầy đủ, nên nếu hỏi chênh lệch benchmark định lượng chi tiết thì hiện vẫn còn thiếu bằng chứng công khai trong các nguồn này.[1][4]
Ngữ cảnh dài và hiệu quả hệ thống: V4 giới thiệu attention mới với token-wise compression và DSA (DeepSeek Sparse Attention), đồng thời đưa 1M context thành mặc định trên các dịch vụ chính thức của DeepSeek.[1] Trong khi đó, V3.2 được truyền thông chủ yếu như một bản “reasoning-first for agents”, không nhấn mạnh dài ngữ cảnh như điểm bán chính.[4]
Dòng model mới linh hoạt hơn: V4 có hai biến thể rõ ràng là V4-Pro và V4-Flash; V4-Pro có 1.6T tổng tham số với 49B active params, còn V4-Flash có 284B tổng tham số với 13B active params.[1] DeepSeek nói V4-Flash vẫn tiệm cận V4-Pro về reasoning, ngang V4-Pro ở các agent task đơn giản, nhưng nhanh hơn và kinh tế hơn.[1] Ở V3.2, DeepSeek tách thành V3.2 và V3.2-Speciale; bản Speciale mạnh hơn về reasoning nhưng tốn token hơn, chỉ có API, và chưa hỗ trợ tool-use.[4]
Agentic coding mạnh hơn: V3.2 là bản đầu tiên của DeepSeek đưa “thinking” trực tiếp vào tool-use, dựa trên phương pháp tổng hợp dữ liệu huấn luyện agent mới bao phủ hơn 1.800 môi trường và hơn 85.000 chỉ dẫn phức tạp.[4] Sang V4, DeepSeek nâng định vị lên “open-source SOTA” trên các benchmark agentic coding, đồng thời nói model đã tích hợp mượt với Claude Code, OpenClaw và OpenCode, và đang được dùng cho agentic coding nội bộ của chính DeepSeek.[1]
Kiến thức thế giới và reasoning: Với V3.2, DeepSeek mô tả bản thường là “daily driver” ở mức GPT-5 và bản Speciale cạnh tranh với Gemini-3.0-Pro.[4] Với V4-Pro, DeepSeek công bố model dẫn đầu các open model hiện tại về world knowledge, và vượt các open model hiện tại ở Math/STEM/Coding, đồng thời tiệm cận các model đóng hàng đầu.[1]
Triển khai API thuận hơn: V4 hỗ trợ cả OpenAI ChatCompletions lẫn Anthropic API, và cả V4-Pro lẫn V4-Flash đều có hai chế độ Thinking / Non-Thinking.[1] Theo changelog chính thức, các tên model cũ deepseek-chat và deepseek-reasoner hiện đang trỏ sang non-thinking/thinking của deepseek-v4-flash, và sẽ bị ngừng hẳn vào 24/07/2026.[7]
Nếu cần nói thật ngắn gọn: V3.2 là bước nhảy lớn về reasoning + tool-use cho agent, còn V4 là bước tiếp theo đưa DeepSeek lên ngữ cảnh siêu dài, agentic coding mạnh hơn, và một cấu hình “Pro/Flash” cân bằng tốt hơn giữa chất lượng và chi phí.[1][4]
Nếu muốn, mình có thể làm tiếp một trong hai dạng:
bảng so sánh V3.2 / V3.2-Speciale / V4-Flash / V4-Pro
hoặc tóm tắt riêng các cải tiến của V4 cho lập trình và AI agent.
Người ta cũng hỏi
Câu trả lời ngắn gọn cho "Deepseek v4 có những cải tiến gì so với Deepseek v3.2?" là gì?
Theo các thông báo chính thức hiện có, DeepSeek V4 (đang ở bản preview) cải tiến rõ nhất so với V3.2 ở 4 mảng: ngữ cảnh dài 1M token, hiệu quả suy luận/chi phí tốt hơn qua dòng Flash, agentic coding mạnh hơn, và kiến thức thế giới + reasoning được đẩy lên mức cạnh tranh với các m
Những điểm chính cần xác nhận đầu tiên là gì?
Theo các thông báo chính thức hiện có, DeepSeek V4 (đang ở bản preview) cải tiến rõ nhất so với V3.2 ở 4 mảng: ngữ cảnh dài 1M token, hiệu quả suy luận/chi phí tốt hơn qua dòng Flash, agentic coding mạnh hơn, và kiến thức thế giới + reasoning được đẩy lên mức cạnh tranh với các m **Ngữ cảnh dài và hiệu quả hệ thống:** V4 giới thiệu attention mới với token-wise compression và DSA (DeepSeek Sparse Attention), đồng thời đưa 1M context thành mặc định trên các dịch vụ chính thức của DeepSeek.[1] Trong khi đó, V3.2 được truyền thông chủ yếu như một bản “reasoni
Tôi nên khám phá chủ đề liên quan nào tiếp theo?
Tiếp tục với "Tìm kiếm và kiểm chứng thông tin: Làm sao triển khai hoặc tích hợp Kimi K2.6 vào app / production workflow?" để có góc nhìn khác và trích dẫn bổ sung.
Kiểm tra chéo câu trả lời này với "Show me top 5 trending search question Vietnamese users often ask about Kimi K2.6 now. Show me both Vietnamese language & English version wi".
Sebastian Raschka, PhD Dec 03, 2025 264 13 28 Share Last updated: January 1st, 2026 Similar to DeepSeek V3, the team released their new flagship model over a major US holiday weekend. Given DeepSeek V3.2’s really good performance (on GPT-5 and Gemini 3.0 Pro) level, and the fact that it’s also available as an open-weight model, it’s definitely worth a closer look. Image 5 Figure 1: Benchmark comparison between DeepSeek V3.2 and proprietary flagship models. This is an annotated figure from the DeepSeek V3.2 report. [...] There are several improvements to the training pipeline, for example, GRP…
_Editor's Note (March 2026):__DeepSeek V4 has not been officially released as of publication. While a "V4 Lite" briefly appeared on DeepSeek's platform in early March 2026, the full model remains unreleased. Multiple sources — including Dataconomy (citing Chinese tech outlet Whale Lab) and the Financial Times — have reported imminent launch dates that have since passed. This article analyses three research papers published by DeepSeek between late December 2025 and mid-January 2026 — on Engram conditional memory, manifold-constrained hyper-connections (mHC), and DeepSeek Sparse Attention — th…
⚠️ Note: deepseek-chat & deepseek-reasoner will be fully retired and inaccessible after Jul 24th, 2026, 15:59 (UTC Time). (Currently routing to deepseek-v4-flash non-thinking/thinking). Image 7 🔹 Amid recent attention, a quick reminder: please rely only on our official accounts for DeepSeek news. Statements from other channels do not reflect our views. 🔹 Thank you for your continued trust. We remain committed to longtermism, advancing steadily toward our ultimate goal of AGI. Previous Get User BalanceNext DeepSeek-V3.2 Release DeepSeek-V4-Pro DeepSeek-V4-Flash Structural Innovation & Ultra-…
April 3: Reuters, citing The Information, reported that DeepSeek's V4 model will likely launch in the "next few weeks" and will run on Huawei's newest chips. The report also said DeepSeek has spent the past few months working with Huawei and Cambricon to rewrite parts of the model stack and run testing, while developing two additional V4 variants optimized for different capabilities. Reuters Officially verifiable on April 6: DeepSeek's public API documentation still does not show a V4 model ID, pricing page, or release announcement. The docs explicitly state that deepseek-chat and `deepseek…
What it is: The latest flagship from the DeepSeek team. If DeepSeek v3.2 sets the standard for cost-effective open-source coding models, v4 pushes the boundaries of logic and memory using proprietary Manifold-Constrained Hyper-Connections (mHC) and Engram Memory technologies. Key Benefit: Beyond just generating code snippets, v4 acts like a senior architect, understanding entire repository structures for cross-file reasoning and complex bug fixing. Status: Upcoming Release (Expected mid-February 2026). Why are we confident that DeepSeek v4 is the next game-changer? Because it solves the indus…
March 2026 -- DeepSeek V3 rewrote the rules for open-source AI when it launched in late 2024, proving that a Chinese AI lab could compete head-to-head with OpenAI and Anthropic on reasoning benchmarks while releasing weights for free. Now, DeepSeek V4 is the most anticipated open-source model of 2026 -- and after months of delays, leaks, and a surprise "V4 Lite" appearance, the full release appears imminent. This article compiles everything currently known about DeepSeek V4: its architecture, capabilities, benchmark claims, hardware story, and the long road to launch. Where information comes…
V4 would increase the total expert count while keeping active parameters per forward pass tightly controlled. The model grows, but the fraction engaged during inference stays small. Per-token cost is projected to remain at or below V3 levels even as overall capability scales up, though no pricing data exists yet to confirm this. For teams running high-throughput production workloads, that ratio matters more than raw parameter counts. Editorial note: If the cost-per-token holds at V3 levels while reasoning benchmarks improve meaningfully, V4 becomes a near-automatic upgrade for inference-heavy…
Release Date: When is DeepSeek V4 Coming Out? DeepSeek V4 has experienced a few delays. Initially rumored for mid-February 2026 around the Lunar New Year, the timeline was pushed back due to massive engineering challenges of training on new hardware architectures. ✅ V4 Lite (Sealion-lite): On March 9, 2026, an unannounced "V4 Lite" version (~200B parameters) appeared on the DeepSeek platform, effectively validating the core architecture. 🚀 V4 Flagship: The full 1T-parameter model is now widely predicted for an April 2026 launch. [...] # DeepSeek V4: 1T Parameter AI Model Guide | Independe…
March 3, 2026 · 1 min read ## TL;DR DeepSeek V4 launches this week. It is a 1-trillion-parameter MoE model with a 1M-token context window, three new architectural techniques, and native multimodal support. Pre-release claims put it at 80-85% SWE-bench Verified and 90% HumanEval. API pricing is expected around $0.14/M input tokens, roughly 20-50x cheaper than Western frontier models. The numbers are from internal DeepSeek benchmarks only. Independent evaluations will follow. ### What it is A 1T-parameter mixture-of-experts LLM with native multimodal input (text, image, video), 1M-token context…
DeepSeek-V3 scaled further to 256 experts with 1 shared expert, and increased routing to topk=8. The architecture became more sophisticated in how it managed experts, and introduced a new communication system called DeepEP that makes expert coordination more efficient. Once the network sparsity was well-optimized, attention became the next target for improvement. As the core module of the Transformer architecture, attention is where each token in a sequence analyzes and weights the importance of every other token to understand context and relationships. Attention presents a different challeng…
DeepSeek V4 Update is INSANE! Image 7 Julian Goldie SEO Julian Goldie SEO 378K subscribers Join Subscribe Subscribed 206 Share Save Download Download 12K views 13 days ago 12,425 views • Apr 9, 2026 Want to make money and save time with AI? Get AI Coaching, Support & Courses 👉 Get the video notes + links to the tools → ...more How this was made Altered or synthetic content Sound or visuals were significantly edited or digitally generated. Learn more ## Chapters View all Image 8 #### Intro – Why DeepSeek V4 changes the AI race #### Intro – Why DeepSeek V4 changes the AI race 0:00 #### Intro…
the user should supply the location and date.", "description": "Get weather of a location, the user should supply the location and date.", "parameters": { "parameters": { "type": "object", "type": "object", "properties": { "properties": { "location": { "type": "string", "description": "The city name" }, "location": { "type": "string", "description": "The city name" }, "date": { "type": "string", "description": "The date in format YYYY-mm-dd" }, "date": { "type": "string", "description": "The date in format YYYY-mm-dd" }, }, }, "required": ["location", [...] # The definition of the tools tools…
"name": "get_weather", "description": "Get weather of a location, the user should supply a location first.", "description": "Get weather of a location, the user should supply a location first.", "parameters": { "parameters": { "type": "object", "type": "object", "properties": { "properties": { "location": { "location": { "type": "string", "type": "string", "description": "The city and state, e.g. San Francisco, CA", "description": "The city and state, e.g. San Francisco, CA", } } [...] The execution flow of this example is as follows: 1. User: Asks about the current weather in Hangzhou 2. Mod…
🛠 Open Source Release 🔗 Model: 🔗 Tech report: 🔗 Key GPU kernels in TileLang & CUDA (use TileLang for rapid research prototyping!) ⚡️ Efficiency Gains 🧑💻 API Update 🛠 Open Source Release [...] Skip to main content # Introducing DeepSeek-V3.2-Exp 🚀 Introducing DeepSeek-V3.2-Exp — our latest experimental model! ✨ Built on V3.1-Terminus, it debuts DeepSeek Sparse Attention (DSA) for faster, more efficient training & inference on long context. 👉 Now live on App, Web, and API 💰 API prices cut by 50%+! ## ⚡️ Efficiency Gains 🤖 DSA achieves fine-grained sparse attention with minimal…
DeepSeek API Docs Logo DeepSeek API Docs Logo # Your First API Call The DeepSeek API uses an API format compatible with OpenAI. By modifying the configuration, you can use the OpenAI SDK or softwares compatible with the OpenAI API to access the DeepSeek API. | PARAM | VALUE | --- | | base_url \ |
| | api\_key | apply for an API key |
\ To be compatible with OpenAI, you can also use
as the
base_url
. But note that the
v1
here has NO relationship with the model's version.
base_urlv1 \ The deepseek-chat and deepseek-reasoner correspond to the model version DeepSeek-V3.2 (128…
DeepSeek API Docs Logo DeepSeek API Docs Logo # DeepSeek-R1 Release ⚡ Performance on par with OpenAI-o1 📖 Fully open-source model & technical report 🏆 Code and models are released under the MIT License: Distill & commercialize freely! 🌐 Website & API are live now! Try DeepThink at chat.deepseek.com today! 🔥 Bonus: Open-Source Distilled Models! 🔬 Distilled from DeepSeek-R1, 6 small models fully open-sourced 📏 32B & 70B models on par with OpenAI-o1-mini 🤝 Empowering the open-source community 🌍 Pushing the boundaries of open AI! 📜 License Update! 🔄 DeepSeek-R1 is now MIT licensed for c…
Still the best value in the market! 🔥 🌌 Open-source spirit + Longtermism to inclusive AGI 🌟 DeepSeek’s mission is unwavering. We’re thrilled to share our progress with the community and see the gap between open and closed models narrowing. 🚀 This is just the beginning! Look forward to multimodal support and other cutting-edge features in the DeepSeek ecosystem. 💡 Together, let’s push the boundaries of innovation! Biggest leap forward yet 🎉 What’s new in V3 💰 API Pricing Update Still the best value in the market! 🔥 [...] Skip to main content # 🚀 Introducing DeepSeek-V3 ## Biggest…