GPT 5.5 vs Claude Ous 4.7, mô hình nào tối ưu cho lập trình
Nếu bạn đang hỏi đúng về GPT 5.5 vs Claude Opus 4.7 , thì câu trả lời ngắn là: chưa đủ bằng chứng để kết luận mô hình nào tối ưu hơn cho lập trình vì bộ chứng cứ hiện có không có benchmark hoặc tài liệu chính thức cho...
Nếu bạn đang hỏi đúng về GPT 5.5 vs Claude Opus 4.7 , thì câu trả lời ngắn là: chưa đủ bằng chứng để kết luận mô hình nào tối ưu hơn cho lập trình vì bộ chứng cứ hiện có không có benchmark hoặc tài liệu chính thức cho GPT 5.5 . Dựa trên tài liệu được cung cấp, Claude Opus 4.7 có tín hiệu mạnh và rõ hơn cho coding , còn
Bài học chính
- Nếu bạn đang hỏi đúng về **GPT-5.5 vs Claude Opus 4.7**, thì câu trả lời ngắn là: **chưa đủ bằng chứng để kết luận mô hình nào tối ưu hơn cho lập trình** vì bộ chứng cứ hiện có **không có benchmark hoặc tài liệu chính thức cho GPT-5.5**. Dựa trên tài liệu được cung cấp, **Claude
- ## Điểm chính
Câu trả lời nghiên cứu
Nếu bạn đang hỏi đúng về GPT-5.5 vs Claude Opus 4.7, thì câu trả lời ngắn là: chưa đủ bằng chứng để kết luận mô hình nào tối ưu hơn cho lập trình vì bộ chứng cứ hiện có không có benchmark hoặc tài liệu chính thức cho GPT-5.5. Dựa trên tài liệu được cung cấp, Claude Opus 4.7 có tín hiệu mạnh và rõ hơn cho coding, còn phía OpenAI trong bộ này chỉ có GPT-5.1-Codex-Max, không phải GPT-5.5.[2][
3]
Điểm chính
-
Claude Opus 4.7 được Anthropic mô tả là mô hình “hybrid reasoning” đẩy mạnh biên năng lực cho coding và AI agents, đồng thời có context window 1M token.[
3]
-
GPT-5.1-Codex-Max được OpenAI mô tả là được huấn luyện trên các tác vụ kỹ nghệ phần mềm thực tế như tạo PR, code review, frontend coding, và Q&A, và “vượt các model trước đó” của OpenAI trên nhiều bài đánh giá coding frontier.[
2]
-
Tuy nhiên, không có tài liệu nào trong bộ chứng cứ này nói về GPT-5.5, nên nếu câu hỏi là so trực tiếp GPT-5.5 với Claude Opus 4.7, thì phải nói thẳng là Insufficient evidence.[
2][
3]
Nếu chỉ xét theo bằng chứng hiện có cho coding
-
Về phía Anthropic, bằng chứng cho Opus 4.7 cụ thể hơn ở cấp sản phẩm: họ công khai định vị đây là model mạnh cho coding/agents và nêu rõ cửa sổ ngữ cảnh 1M token, điều này thường hữu ích cho codebase lớn và tác vụ nhiều file.[
3]
-
Về phía OpenAI, bằng chứng hiện có trong bộ này lại nói về GPT-5.1-Codex-Max, không phải GPT-5.5; OpenAI chỉ khẳng định model này mạnh hơn các model trước của họ trên nhiều đánh giá coding, nhưng không có số liệu đối đầu trực tiếp với Opus 4.7 trong nguồn được cung cấp.[
2]
Về benchmark
-
Một số nguồn bên thứ ba trong bộ chứng cứ nói Claude Opus 4.7 đạt 82.4% trên SWE-bench Verified.[
4]
-
Một nguồn bên thứ ba khác nói Opus 4.7 được so sánh với GPT-5.4, không phải GPT-5.5.[
6]
-
Vì các chi tiết benchmark này đến từ nguồn bên thứ ba chứ không phải tài liệu đối chiếu chính thức giữa hai model bạn hỏi, nên chúng chỉ nên xem là tín hiệu tham khảo, không đủ để chốt kèo tuyệt đối.[
4][
6]
Kết luận thực dụng
-
Nếu bạn cần một kết luận chỉ dựa trên chứng cứ hiện có, thì:
-
Nếu bạn muốn chọn ngay:
Nếu muốn, tôi có thể giúp bạn làm tiếp một bản so sánh theo nhu cầu lập trình cụ thể như:
- codebase lớn / refactor nhiều file,
- competitive coding,
- debug bug production,
- viết test và PR,
- hay agent tự sửa code end-to-end.
Hỗ trợ hình ảnh
















Trao đổi nghiên cứu
Câu hỏi nghiên cứu
GPT 5.5 vs Claude Ous 4.7, mô hình nào tối ưu cho lập trình
Câu trả lời được trích dẫn
Nếu bạn đang hỏi đúng về GPT-5.5 vs Claude Opus 4.7, thì câu trả lời ngắn là: chưa đủ bằng chứng để kết luận mô hình nào tối ưu hơn cho lập trình vì bộ chứng cứ hiện có không có benchmark hoặc tài liệu chính thức cho GPT-5.5. Dựa trên tài liệu được cung cấp, Claude Opus 4.7 có tín hiệu mạnh và rõ hơn cho coding, còn phía OpenAI trong bộ này chỉ có GPT-5.1-Codex-Max, không phải GPT-5.5.[2][
3]
Điểm chính
-
Claude Opus 4.7 được Anthropic mô tả là mô hình “hybrid reasoning” đẩy mạnh biên năng lực cho coding và AI agents, đồng thời có context window 1M token.[
3]
-
GPT-5.1-Codex-Max được OpenAI mô tả là được huấn luyện trên các tác vụ kỹ nghệ phần mềm thực tế như tạo PR, code review, frontend coding, và Q&A, và “vượt các model trước đó” của OpenAI trên nhiều bài đánh giá coding frontier.[
2]
-
Tuy nhiên, không có tài liệu nào trong bộ chứng cứ này nói về GPT-5.5, nên nếu câu hỏi là so trực tiếp GPT-5.5 với Claude Opus 4.7, thì phải nói thẳng là Insufficient evidence.[
2][
3]
Nếu chỉ xét theo bằng chứng hiện có cho coding
-
Về phía Anthropic, bằng chứng cho Opus 4.7 cụ thể hơn ở cấp sản phẩm: họ công khai định vị đây là model mạnh cho coding/agents và nêu rõ cửa sổ ngữ cảnh 1M token, điều này thường hữu ích cho codebase lớn và tác vụ nhiều file.[
3]
-
Về phía OpenAI, bằng chứng hiện có trong bộ này lại nói về GPT-5.1-Codex-Max, không phải GPT-5.5; OpenAI chỉ khẳng định model này mạnh hơn các model trước của họ trên nhiều đánh giá coding, nhưng không có số liệu đối đầu trực tiếp với Opus 4.7 trong nguồn được cung cấp.[
2]
Về benchmark
-
Một số nguồn bên thứ ba trong bộ chứng cứ nói Claude Opus 4.7 đạt 82.4% trên SWE-bench Verified.[
4]
-
Một nguồn bên thứ ba khác nói Opus 4.7 được so sánh với GPT-5.4, không phải GPT-5.5.[
6]
-
Vì các chi tiết benchmark này đến từ nguồn bên thứ ba chứ không phải tài liệu đối chiếu chính thức giữa hai model bạn hỏi, nên chúng chỉ nên xem là tín hiệu tham khảo, không đủ để chốt kèo tuyệt đối.[
4][
6]
Kết luận thực dụng
-
Nếu bạn cần một kết luận chỉ dựa trên chứng cứ hiện có, thì:
-
Nếu bạn muốn chọn ngay:
Nếu muốn, tôi có thể giúp bạn làm tiếp một bản so sánh theo nhu cầu lập trình cụ thể như:
- codebase lớn / refactor nhiều file,
- competitive coding,
- debug bug production,
- viết test và PR,
- hay agent tự sửa code end-to-end.
Người ta cũng hỏi
Câu trả lời ngắn gọn cho "GPT 5.5 vs Claude Ous 4.7, mô hình nào tối ưu cho lập trình" là gì?
Nếu bạn đang hỏi đúng về **GPT-5.5 vs Claude Opus 4.7**, thì câu trả lời ngắn là: **chưa đủ bằng chứng để kết luận mô hình nào tối ưu hơn cho lập trình** vì bộ chứng cứ hiện có **không có benchmark hoặc tài liệu chính thức cho GPT-5.5**. Dựa trên tài liệu được cung cấp, **Claude
Những điểm chính cần xác nhận đầu tiên là gì?
Nếu bạn đang hỏi đúng về **GPT-5.5 vs Claude Opus 4.7**, thì câu trả lời ngắn là: **chưa đủ bằng chứng để kết luận mô hình nào tối ưu hơn cho lập trình** vì bộ chứng cứ hiện có **không có benchmark hoặc tài liệu chính thức cho GPT-5.5**. Dựa trên tài liệu được cung cấp, **Claude ## Điểm chính
Tôi nên khám phá chủ đề liên quan nào tiếp theo?
Tiếp tục với "Tìm kiếm và kiểm chứng thông tin: Làm sao triển khai hoặc tích hợp Kimi K2.6 vào app / production workflow?" để có góc nhìn khác và trích dẫn bổ sung.
Mở trang liên quanTôi nên so sánh điều này với cái gì?
Kiểm tra chéo câu trả lời này với "Show me top 5 trending search question Vietnamese users often ask about Kimi K2.6 now. Show me both Vietnamese language & English version wi".
Mở trang liên quanTiếp tục nghiên cứu của bạn
Nguồn
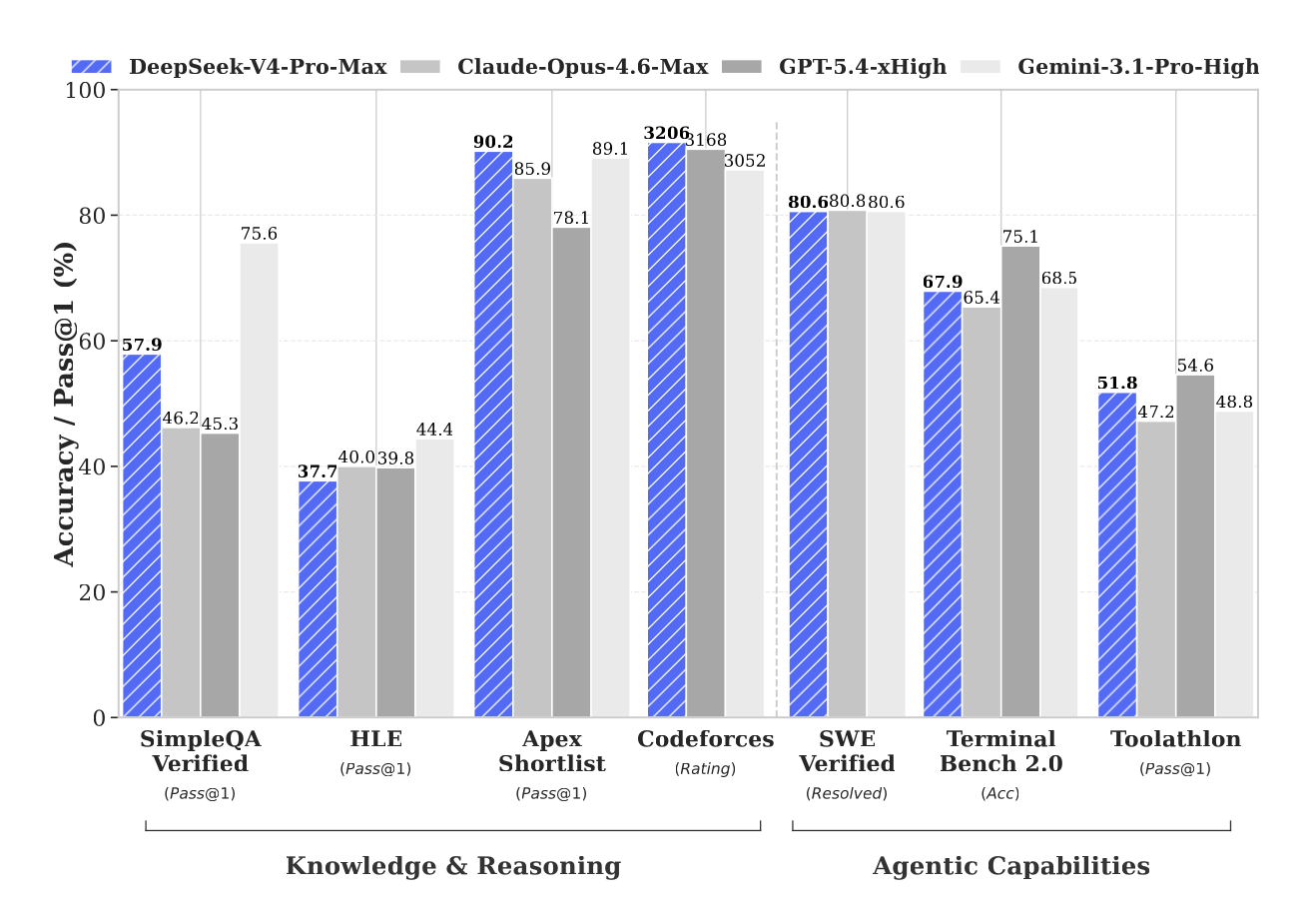
- [1] DeepSeek V4 Released: Everything You Need to Know (April 2026)felloai.com
Long-context retrieval ceiling. Above 128K tokens, retrieval accuracy starts to degrade, dropping to 66% on MRCR at 1M tokens. This is still better than most open models and Gemini 3.1 Pro, but it is not the near-perfect recall some benchmarks have reported for Claude Opus 4.6. Frontier agent tasks. On Terminal Bench 2.0 (67.9) and SWE Pro (55.4), V4-Pro-Max still trails the closed frontier. For pure agentic coding work, GPT-5.5 a Claude Opus 4.7 remain stronger pickers. Multimodal. V4 is text only. DeepSeek says it is “working on incorporating multimodal capabilities to our models” but the c…
- [2] GPT-5.5 Launch: OpenAI Ships Agentic Super-App Engine on April 23theplanettools.ai
What we can compare today: | Dimension | GPT-5.5 | Claude Opus 4.7 | Gemini 3.1 Pro | --- --- | | Launch date | April 23, 2026 | April 2026 (flagship line) | Early 2026 | | Primary positioning | Agentic super-app engine | Coding and long-context frontier | Multimodal agent across Google stack | | Native coding surface | Codex (web, IDE, CLI) | Claude Code (terminal-first) | Gemini Code Assist (IDE) | | Context window | Not disclosed at launch | 1M tokens | 2M tokens | | Enterprise tier availability | Day one (Business, Enterprise) | Claude Enterprise | Gemini Enterprise | | Infrastructure | N…
- [3] GPT-5.5 Review: OpenAI's Smartest Model Yet, the Double Price Tag, and the Honest Benchmark Storyrenovateqr.com
TL;DR What it is: GPT-5.5 is OpenAI's new flagship model, released April 23, 2026, exactly six weeks after GPT-5.4. It leads the Artificial Analysis Intelligence Index with a score of 60, putting it three points ahead of Claude Opus 4.7 and Gemini 3.1 Pro at 57. It is available right now to Plus, Pro, Business, and Enterprise subscribers in ChatGPT and Codex. The biggest improvements: Terminal-Bench 2.0 hits 82.7% (up from GPT-5.4's 75.1%). On long-context evaluations from 512K to 1M tokens, the MRCR v2 score jumps from 36.6% to 74.0%. On FrontierMath Tier 4, it hits 35.4% compared to GPT-…
- [4] GPT-5.5 vs Claude Mythos: How the AI Race Is Reshaping Marketing – Marketing Agent Blogmarketingagent.blog
TechCrunch also confirmed that GPT-5.5 outperforms Google’s Gemini 3.1 Pro and Anthropic’s Claude Opus 4.5 on benchmark testing — not just Mythos Preview on Terminal-Bench alone. The competitive picture across all three major lab families shifted on April 23, 2026. OpenAI also mentioned specific use case domains where GPT-5.5 shows particular strength, including drug discovery and digital defense applications. And per TechCrunch, the release is framed as progress toward OpenAI’s planned “super app” that would combine ChatGPT, Codex, and an AI-powered browser into a single product. That roadma…
- [5] Introducing GPT-5.5 | OpenAIopenai.com
Abstract reasoning EvalGPT-5.5GPT‑5.4GPT-5.5 ProGPT‑5.4 ProClaude Opus 4.7Gemini 3.1 Pro ARC-AGI-1 (Verified)95.0%93.7%-94.5%93.5%98.0% ARC-AGI-2 (Verified)85.0%73.3%-83.3%75.8%77.1% Evals of GPT were run with reasoning effort set to xhigh and were conducted in a research environment, which may provide slightly different output from production ChatGPT in some cases. 2026 ## Author OpenAI ## Keep reading View all Image 10: Making ChatGPT free for clinicians Making ChatGPT better for clinicians Product Apr 22, 2026 Image 11: OAI Blog Agents Hero 1x1 Introducing workspace agents in ChatGPT…
- [6] OpenAI's GPT-5.5 is here, and it's no potato - VentureBeatventurebeat.com
BenchmarkGPT-5.5Claude Opus 4.7Gemini 3.1 ProMythos Preview Terminal-Bench 2.082.769.4 68.5 82.0 Expert-SWE (Internal)73.1——— GDPval (wins or ties)84.980.3 67.3— OSWorld-Verified 78.7 78.0—79.6 Toolathlon55.6—48.8— BrowseComp 84.4 79.3 85.986.9 FrontierMath Tier 1–351.743.8 36.9— FrontierMath Tier 435.422.9 16.7— CyberGym 81.8 73.1—83.1 Tau2-bench Telecom (original prompts)98.0——— OfficeQA Pro54.143.6 18.1— Investment Banking Modeling Tasks (Internal)88.5——— MMMU Pro (no tools)81.2—80.5— MMMU Pro (with tools)83.2——— GeneBench25.0——— BixBench80.5——— Capture-the-Flags challenge tasks (Internal)…
- [7] OpenAI's GPT-5.5 masters agentic coding with 82.7% benchmark ...interestingengineering.com
— OpenAI (@OpenAI) April 23, 2026 OpenAI said the improvements go beyond benchmarks. Early testers reported that GPT-5.5 better understands system architecture and failure points. It can identify where fixes belong and predict downstream impacts across a codebase. The company emphasized efficiency alongside capability. GPT-5.5 matches GPT-5.4’s per-token latency despite higher intelligence. It also uses fewer tokens to complete the same tasks, lowering computational cost. “GPT-5.5 delivers this step up in intelligence without compromising on speed,” OpenAI noted. It added that the model perfo…
- [8] GPT-5.5 vs Claude Opus 4.7: Benchmarks, Pricing & Coding ...lushbinary.com
1Release Context & What Changed The timing tells the story. Anthropic released Claude Opus 4.7 on April 16, 2026 — a focused upgrade that pushed SWE-bench Pro from 53.4% (Opus 4.6) to 64.3%, added high-resolution vision up to 3.75 megapixels, and introduced the
xhigheffort level. All at the same $5/$25 per million token pricing as its predecessor. Exactly one week later, on April 23, OpenAI launched GPT-5.5 — codenamed "Spud." Unlike the incremental GPT-5.1 through 5.4 releases, GPT-5.5 is the first fully retrained base model since GPT-4.5. It's natively omnimodal (text, images, audio,… - [9] GPT-5.5 vs Claude Opus 4.7: Which Model Should You Use First? | LaoZhang AI Blogblog.laozhang.ai
GPT-5.5 vs Claude Opus 4.7: Which Model Should You Use First? AI Free API Team ••12 min read•AI Model Comparison Use GPT-5.5 first for OpenAI-native ChatGPT and Codex testing, use Claude Opus 4.7 first for production API deployment today, and dual-run before replacing a paid workflow. GPT-5.5 vs Claude Opus 4.7: Which Model Should You Use First? GPT-5.5 and Claude Opus 4.7 are not a symmetric API choice yet. As of Apr 24, 2026, GPT-5.5 is available in ChatGPT and Codex with API access coming soon, while Claude Opus 4.7 is already available through Anthropic and major cloud platforms. [...]…
- [10] GPT 5.5 beats Claude Opus 4.7 : r/ArtificialInteligence - Redditreddit.com
Anyone can view, post, and comment to this community 0 0 Reddit RulesPrivacy PolicyUser AgreementYour Privacy ChoicesAccessibilityReddit, Inc. © 2026. All rights reserved. Expand Navigation Collapse Navigation RESOURCES About Reddit Advertise Developer Platform Reddit Pro BETA Help Blog Careers Press Best of Reddit Reddit Rules Privacy Policy User Agreement Your Privacy Choices Accessibility Reddit, Inc. © 2026. All rights reserved. Image 8 [...] # GPT 5.5 beats Claude Opus 4.7 : r/ArtificialInteligence Skip to main contentGPT 5.5 beats Claude Opus 4.7 : r/ArtificialIntel…
- [11] I Tested GPT 5.5 vs Opus 4.7: What You Need to Know OpenAI just ...linkedin.com
in Codex, it's in chat TBT. I'm sure by the time you're watching this video, the API will probably be out. But I saw the announcement and I just jumped on it and wanted to play around. So a quick quote from the president of Opening Eye. It's faster, sharper, and it uses fewer tokens compared to something like GT 5.4. Now let's see where it pulls ahead a little bit. So the terminal bench 2.0, it scored a 82.7, whereas GT 5.4 scored a 75. 21 and Opus 4.7 scored a 69.4 so it is beating Opus here on the terminal bench and it's also beating the previous model. They also ran an expert sweep bench i…
- [12] Model Drop: GPT-5.5handyai.substack.com
Headline benchmarks: Terminal-Bench 2.0 at 82.7% (Opus 4.7: 69.4%, Gemini 3.1 Pro: 68.5%). SWE-Bench Pro at 58.6% (Opus 4.7 still leads at 64.3%). OpenAI’s internal Expert-SWE eval, where tasks have a 20-hour median human completion time, at 73.1% (up from GPT-5.4’s 68.5%). GDPval wins-or-ties at 84.9% (Opus 4.7: 80.3%, Gemini 3.1 Pro: 67.3%). OSWorld-Verified at 78.7% (narrowly edges Opus 4.7’s 78.0%). FrontierMath Tier 4 at 35.4% (Opus 4.7: 22.9%, Gemini 3.1 Pro: 16.7%). CyberGym at 81.8% (Opus 4.7: 73.1%, Anthropic’s Claude Mythos: 83.1%). Tau2-Bench Telecom at 98.0% without prompt tuning.…
- [13] Claude Opus 4.7 - Anthropicanthropic.com
Skip to main contentSkip to footer []( Research Economic Futures Commitments Learn News Try Claude # Claude Opus 4.7 Image 1: Claude Opus 4.7 Image 2: Claude Opus 4.7 Hybrid reasoning model that pushes the frontier for coding and AI agents, featuring a 1M context window Try ClaudeGet API access ## Announcements NEW Claude Opus 4.7 Apr 16, 2026 Claude Opus 4.7 brings stronger performance across coding, vision, and complex multi-step tasks. It's more thorough and consistent on difficult work, with better results across professional knowledge work. Read more Claude Opus 4.6 [...] Read more Claud…
- [14] Claude Opus 4.7 Benchmark Breakdown: Vision, Coding, and ...mindstudio.ai
Claude Opus 4.7 posted 82.4% on SWE-bench Verified, up roughly 11 points from Opus 4.6 — the most meaningful coding benchmark available. Vision improvements were the largest percentage gains: MathVista jumped 9.5 points, enabling reliable visual math reasoning and structured chart interpretation. FinanceBench performance of 82.7% makes Opus 4.7 a strong choice for financial document analysis, handling most standard extraction and calculation tasks accurately. Opus 4.7 leads GPT-5.4 and Gemini 3.1 Pro across all five core benchmarks in this breakdown, with the most meaningful gap on SWE-bench.…
- [15] Claude Opus 4.7 Benchmarks Explainedvellum.ai
Apr 16, 2026•16 min•ByNicolas Zeeb Guides CONTENTS Key observations of reported benchmarks Coding capabilities SWE-bench Verified SWE-bench Pro Terminal-Bench 2.0 Agentic capabilities MCP-Atlas (Scaled tool use) Finance Agent v1.1 OSWorld-Verified (Computer use) BrowseComp (Agentic search) Reasoning capabilities GPQA Diamond (Graduate-level science) Humanity's Last Exam Multimodal and vision capabilities CharXiv Reasoning (Visual reasoning) Multilingual Q&A (MMMLU) Safety and alignment What these benchmarks really mean for your agents When to use Opus 4.6 vs Opus 4.7 Use Opus 4.7 with your Ve…
- [16] Claude Opus 4.7: Anthropic's New Best (Available) Model - DataCampdatacamp.com
Claude Opus 4.7: Anthropic’s New Best (Available) Model Explore what's new in Anthropic's latest flagship: stronger agentic coding, sharper vision, and better memory across sessions. Compare the benchmarks against GPT-5.4, Gemini 3.1 Pro, and the locked-away Mythos Preview. Apr 16, 2026 · 9 min read Anthropic has released Claude Opus 4.7, the latest iteration of its flagship model tier. The headline improvement is autonomy: Anthropic is pitching this as the model you can hand your hardest, longest-running coding and agent work to without close supervision. [...] ## Claude Opus 4.7 Benchmark…
- [17] Claude Opus 4.7: Benchmarks, Pricing, Context & What's ...llm-stats.com
Opus 4.7 · Apr 16, 2026 Effort Levels low → max Opus 4.7 adds xhigh between high and max, giving finer control over reasoning depth without the full latency of max. Anthropic released Claude Opus 4.7 on April 16, 2026. It's a direct upgrade to Opus 4.6 at the same price ($5 / $25 per million input / output tokens), with meaningful gains on the hardest software engineering tasks, a new xhigh effort level, 3.3x higher-resolution vision, and better file-system memory across multi-session agent work. [...] LLM Stats Logo Make AI phone calls with one API call # Claude Opus 4.7: Benchmarks, Pricing…
- [18] Claude Opus 4.7: What Changed for Coding Agents (April 2026)verdent.ai
Image 4: What Is Claude Opus 4.7 Claude Opus 4.7 is Anthropic's most capable generally available model as of April 16, 2026. It's a direct upgrade over Opus 4.6 continuing Anthropic's roughly two-month release cadence. The official Anthropic announcement describes it as "a notable improvement on Opus 4.6 in advanced software engineering, with particular gains on the most difficult tasks." ### API identifier:
claude-opus-4-7Image 5: API identifier: claude-opus-4-7 Available via the Claude API, Amazon Bedrock, Google Cloud Vertex AI, and Microsoft Foundry. Drop-in model ID switch from `claud… - [19] Understand the SWE-Bench Leaderboard 2026 in Depth - CodeAnt AIcodeant.ai
SWE-Bench Verified Leaderboard: April 2026 SWE-bench Verified tests AI models on 500 real GitHub issues from popular Python repositories. Models must submit code patches that fix the bug without breaking existing tests. As of April 2026, Claude Mythos Preview leads at 93.9%, followed by GPT-5.3 Codex at 85% and Claude Opus 4.5 at 80.9%. The average score across all 83 evaluated models is 63.4%. [...] | Rank | Model | SWE-bench Verified | SWE-bench Pro | Notes | --- --- | 1 | Claude Mythos Preview | 93.9% | — | Anthropic | | 2 | GPT-5.3 Codex | 85.0% | 57.0% | OpenAI | | 3 | Claude Opus 4.6…
- [20] 93.9% SWE-bench & Every Record Broken (2026) - NxCodenxcode.io
Claude Opus 4.7 Developer Guide: API Setup, Claude Code & Migration (2026) Developer guide for Claude Opus 4.7: API setup (claude-opus-4-7), new xhigh effort level, /ultrareview command, task budgets, and migration from 4.6. With code examples and cost optimization tips. 2026-04-16Read more →Claude Opus 4.7 vs 4.6 vs Mythos: Which Model Should You Use? (2026) ### Claude Opus 4.7 vs 4.6 vs Mythos: Which Model Should You Use? (2026) Three Claude models, three different use cases. Opus 4.7 (best for everyday coding), Opus 4.6 (proven and stable), Mythos (restricted to cybersecurity). Here's…
- [21] Anthropic Promised Claude Opus 4.7 Would Change ... - Towards AIpub.towardsai.net
Anthropic Promised Claude Opus 4.7 Would Change Everything. Here’s What Actually Happened. | by Adi Insights and Innovations | Apr, 2026 | Towards AI Sitemap Open in app Sign up Sign in []( Get app Write Search Sign up Sign in Image 1 ## Towards AI · Follow publication Image 2: Towards AI We build Enterprise AI. We teach what we learn. Join 100K+ AI practitioners on Towards AI Academy. Free: 6-day Agentic AI Engineering Email Guide: Follow publication Member-only story # Anthropic Promised Claude Opus 4.7 Would Change Everything. Here’s What Actually Happened. ## _The benchmarks say it’s th…
- [22] Anthropic releases Claude Opus 4.7: How to try it, benchmarks, safetymashable.com
Anthropic releases Claude Opus 4.7: How to try it, benchmarks, safety headshot of timothy beck werth, a handsome journalist with great hair The Claude AI logo is displayed on a smartphone screen with a multitude of Anthropic logos in the background Anthropic has been shipping products and making news at a blistering pace in 2026, and on Thursday, the AI company announced the launch of Claude Opus 4.7. Claude Opus 4.7 is Anthropic's most intelligent model available to the general public. Notably, Anthropic said in a press release") that Opus 4.7 is not as powerful as Claude Mythos, which Ant…
- [23] Artificial Intelligencefacebook.com
Anthropic released Claude Opus... - Artificial Intelligence | Facebook Log In Log In Forgot Account? ## Artificial Intelligence's Post []( ### Artificial Intelligence 4d · Let Him Cook · XNIMXS · Anthropic released Claude Opus 4.7 on April 16, 2026. This new AI model is their most powerful public release yet. It’s better at coding, long tasks, and understanding high-resolution images. It’s also safer. Opus 4.7 beats GPT-5.4 and Gemini 3.1 Pro in coding but is not as strong as Anthropic’s private Mythos model. Image 1 Image 2 Image 3 Image 4 Image 5 +3 Image 6 Image 7 All reactions: 33 2 com…
- [24] Claude Opus 4.7 results: early benchmarks, real-world feedback ...boringbot.substack.com
The Claude Opus 4.7 benchmarks on software engineering tasks show the clearest improvement. On SWE-Bench, the industry-standard benchmark for evaluating autonomous code repair across real GitHub issues, Opus 4.7 shows a meaningful step up from Opus 4.6, with early reported scores suggesting improvements in the range of 8–12 percentage points depending on task category (Source: community-reported testing via r/ClaudeAI and independent evaluations). On HumanEval, which tests functional code generation, Opus 4.7 continues to perform competitively. [...] # The Production Gap # Claude Opus 4.7 res…
- [25] [PDF] GeneBench: Assessing AI Agents for Multi-Stage Inference ... - OpenAIcdn.openai.com
Carlos E. Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik R. Narasimhan. SWE-bench: Can Language Models Resolve Real-World GitHub Issues? arXiv preprint arXiv:2310.06770 , 2023. Emily A. King, J. Wade Davis, and Jacob F. Degner. Are drug targets with genetic support twice as likely to be approved? Revised estimates of the impact of genetic support for drug mechanisms on the probability of drug approval. PLoS Genetics , 15:e1008489, 2019. Neil Chowdhury and others. Introducing SWE-bench Verified. Web resource, August 13, 2024; updated February 24, 2025. Sam…
- [26] Building more with GPT-5.1-Codex-Max - OpenAIopenai.com
Frontier coding capabilities GPT‑5.1‑Codex‑Max was trained on real-world software engineering tasks, like PR creation, code review, frontend coding, and Q&A and outperforms our previous models on many frontier coding evaluations. The model’s gains on benchmarks also come with improvements to real-world usage: GPT‑5.1‑Codex‑Max is the first model we have trained to operate in Windows environments, and the model’s training now includes tasks designed to make it a better collaborator in the Codex CLI. SWE-Lancer IC SWE Terminal-Bench 2.0 (n=89) All evals were run with compaction enabled at Extra…
- [27] GPT-5.5 System Card - Deployment Safety Hub - OpenAIdeploymentsafety.openai.com
that tracks the model’s ability to follow user instructions about their CoT. CoT-Control includes over 13,000 tasks built from established benchmarks: GPQA (Rein et al., 2023 ), MMLU-Pro (Hendrycks et al., 2020), HLE (Phan et al., 2025), BFCL (Patil et al., 2025[11: From tool use to agentic evaluation of large language models.” Proceedings of the 42nd international conference on machine learning . Available at: .")]) and SWE-Bench Verified. Each task is created by pairing a benchmark problem with one CoT instruction such as avoiding certain problem-relevant keywords in CoT, using only lowerca…
- [28] GPT-5.5 System Card - OpenAI Deployment Safety Hubdeploymentsafety.openai.com
We measure GPT-5.5’s controllability by running CoT-Control, an evaluation suite described in (Yueh-Han, 2026 ) that tracks the model’s ability to follow user instructions about their CoT. CoT-Control includes over 13,000 tasks built from established benchmarks: GPQA (Rein et al., 2023 ), MMLU-Pro (Hendrycks et al., 2020 ), HLE (Phan et al., 2025 ), BFCL (Patil et al., 2025 [11: From tool use to agentic evaluation of large language models.” Proceedings of the 42nd international conference on machine learning . Available at: .")]) and SWE-Bench Verified. Each task is created by pairing a bench…
- [29] Introducing GPT-5 - OpenAIopenai.com
Coding All SWE-bench evaluation runs use a fixed subset of n=477 verified tasks which have been validated on our internal infrastructure. #### Instruction following and agentic tool use GPT‑5 shows significant gains in benchmarks that test instruction following and agentic tool use, the kinds of capabilities that let it reliably carry out multi-step requests, coordinate across different tools, and adapt to changes in context. In practice, this means it’s better at handling complex, evolving tasks; GPT‑5 can follow your instructions more faithfully and get more of the work done end-to-e…
- [30] Introducing GPT-5.2-Codex - OpenAIopenai.com
GPT‑5.2‑Codex achieves state-of-the-art performance on SWE-Bench Pro and Terminal-Bench 2.0, benchmarks designed to test agentic performance on a wide variety of tasks in realistic terminal environments. It is also much more effective and reliable at agentic coding in native Windows environments, building on capabilities introduced in GPT‑5.1‑Codex‑Max. With these improvements, Codex is more capable at working in large repositories over extended sessions with full context intact. It can more reliably complete complex tasks like large refactors, code migrations, and feature builds — continuing…
- [31] Introducing GPT-5.3-Codexopenai.com
Coding GPT‑5.3‑Codex achieves state-of-the-art performance on SWE-Bench Pro, a rigorous evaluation of real-world software engineering. Where SWE‑bench Verified only tests Python, SWE‑Bench Pro spans four languages and is more contamination‑resistant, challenging, diverse and industry-relevant. It also far exceeds the previous state-of-the-art performance on Terminal-Bench 2.0, which measures the terminal skills a coding agent like Codex needs. Notably, GPT‑5.3‑Codex does so with fewer tokens than any prior model, letting users build more. SWE-Bench Pro (Public) Terminal-Bench 2.0 #### We…
- [32] Introducing GPT-5.4 | OpenAIopenai.com
EvalGPT‑5.4GPT‑5.4 ProGPT‑5.3-CodexGPT‑5.2GPT‑5.2 Pro GDPval 83.0%82.0%70.9%70.9%74.1% FinanceAgent v1.1 56.0%61.5%54.0%59.5%— Investment Banking Modeling Tasks (Internal)87.3%83.6%79.3%68.4%71.7% OfficeQA 68.1%—65.1%63.1%— ##### Coding EvalGPT‑5.4GPT‑5.4 ProGPT‑5.3-CodexGPT‑5.2GPT‑5.2 Pro SWE-Bench Pro (Public)57.7%—56.8%55.6%— Terminal-Bench 2.0 75.1%—77.3%62.2%— ##### Computer use and vision EvalGPT‑5.4GPT‑5.4 ProGPT‑5.3-CodexGPT‑5.2GPT‑5.2 Pro OSWorld-Verified 75.0%—74.0%47.3%— MMMU Pro (no tools)81.2%——79.5%— MMMU Pro (with tools)82.1%——80.4%— ##### Tool use EvalGPT‑5.4GPT‑5.4 ProGPT‑5.3…
- [33] Introducing GPT-5.4 mini and nano - OpenAIopenai.com
Coding | | GPT-5.4 (xhigh) | GPT-5.4 mini (xhigh) | GPT-5.4 nano (xhigh) | GPT-5 mini (high¹) | --- --- | SWE-bench Pro (Public) | 57.7% | 54.4% | 52.4% | 45.7% | | Terminal-Bench 2.0 | 75.1% | 60.0% | 46.3% | 38.2% | ##### Tool-calling | | GPT-5.4 (xhigh) | GPT-5.4 mini (xhigh) | GPT-5.4 nano (xhigh) | GPT-5 mini (high¹) | --- --- | MCP Atlas | 67.2% | 57.7% | 56.1% | 47.6% | | Toolathlon | 54.6% | 42.9% | 35.5% | 26.9% | | τ2-bench (telecom) | 98.9% | 93.4% | 92.5% | 74.1% | ##### Intelligence | | GPT-5.4 (xhigh) | GPT-5.4 mini (xhigh) | GPT-5.4 nano (xhigh) | GPT-5 mini (high¹) | ---…
- [34] Introducing GPT‑5 for developers | OpenAIopenai.com
GPT‑5 is state-of-the-art (SOTA) across key coding benchmarks, scoring 74.9% on SWE-bench Verified and 88% on Aider polyglot. We trained GPT‑5 to be a true coding collaborator. It excels at producing high-quality code and handling tasks such as fixing bugs, editing code, and answering questions about complex codebases. The model is steerable and collaborative—it can follow very detailed instructions with high accuracy and can provide upfront explanations of its actions before and between tool calls. The model also excels at front-end coding, beating OpenAI o3 at frontend web development 70% o…
- [35] GPT-5.5 System Card - Deployment Safety Hub - OpenAIdeploymentsafety.openai.com
that tracks the model’s ability to follow user instructions about their CoT. CoT-Control includes over 13,000 tasks built from established benchmarks: GPQA (Rein et al., 2023 ), MMLU-Pro (Hendrycks et al., 2020), HLE (Phan et al., 2025), BFCL (Patil et al., 2025[11: From tool use to agentic evaluation of large language models.” Proceedings of the 42nd international conference on machine learning . Available at: .")]) and SWE-Bench Verified. Each task is created by pairing a benchmark problem with one CoT instruction such as avoiding certain problem-relevant keywords in CoT, using only lowerca…
- [36] Fact Check: Does GPT-5.5 underperform Claude Opus 4.7 on the ...factcheckradar.com
GPT-5.5 was reported by OpenAI to achieve a 58.6% resolve rate on SWE-Bench Pro. In contrast, Claude Opus 4.7, released one week earlier, achieved a 64.3% resolve rate on the same benchmark. Furthermore, the user's observation regarding OpenAI's reporting style is largely accurate: OpenAI's primary comparison table in their official announcement features an internal benchmark called 'Expert-SWE' (where GPT-5.5 scored 73.1%) rather than the industry-standard SWE-Bench Pro. The SWE-Bench Pro score was mentioned in the body text of the announcement but omitted from the main visual comparison, su…
- [37] GPT-5.5: Pricing, Benchmarks & Performancellm-stats.com
74 79 84 89 878684837978 SWE-bench Pro SWE-Bench Pro is an advanced version of SWE-Bench that evaluates language models on complex, real-world software engineering tasks requiring extended reasoning and multi-step problem solving. agents, code, reasoning 46 58 70 81 7864595854 ARC-AGI v2 [...] 959494949393 HLE 27 41 55 69 655552514037 BrowseComp BrowseComp is a benchmark comprising 1,266 questions that challenge AI agents to persistently navigate the internet in search of hard-to-find, entangled information. The benchmark measures agents' ability to exercise persistence in information gatheri…
- [38] OpenAI GPT-5.5 Benchmark (CodeRabbit)coderabbit.ai
In our early testing with GPT-5.5, the agent reached 79.2% expected issue found on our curated review benchmark versus 58.3%, improved precision from 27.9% to 40.6%, and produced 75 comments versus the baseline's 67. That means it found substantially more useful issues with only a modest increase in comment volume. In testing, GPT-5.5 improved performance across several key metrics on our large-scale, real-world review set. Specifically, the expected issue found rate increased from a 55.0% baseline to 65.0%. Furthermore, precision improved from 11.6% to 13.2%. The agent also became more verbo…
- [39] OpenAI's GPT-5.5 is the new leading AI model - Artificial Analysisartificialanalysis.ai
OpenAI's GPT-5.5 is the new leading AI model Artificial Analysis Log in Artificial Analysis Models Agents Speech, Image, Video Hardware Leaderboards About AI Trends Arenas Log inK leads Terminal-Bench Hard, GDPval-AA and our newly hosted APEX-Agents-AA. The model trails only other OpenAI models in CritPt and AA-LCR, and comes second to Gemini 3.1 Pro Preview on three additional evaluations. The largest gains are on AA-Omniscience (+14 pts), our knowledge and hallucination benchmark, and τ²-Bench Telecom (+7 pts), a customer service agent benchmark. [...] ➤ Number one in GDPval-AA with an El…
- [40] OpenAI releases GPT-5.5 with improved coding and research ...investing.com
The model achieved 82.7% accuracy on Terminal-Bench 2.0, which tests command-line workflows, and 58.6% on SWE-Bench Pro, which evaluates
- [41] GPT-5.5 just dropped (April 23) and it's the strongest agentic leap ...x.com
OpenAI released GPT-5.5 as their “smartest & most intuitive model yet” — built for real computer work with minimal hand-holding. ✓It plans multi
- [42] r/singularity - GPT-5.5 benchmark results have been releasedreddit.com
Mostly only a small jump. They didn't bother including SWE-Bench Pro where it went from 57.6% to 58.6% (Mythos got 77.8%).
- [43] GPT-5.5 - Worth it against Open Models? - YouTubeyoutube.com
GPT-5.5 benchmark performance vs open models · SWE-Bench Pro and Terminal-Bench comparisons · API pricing vs open source alternatives.