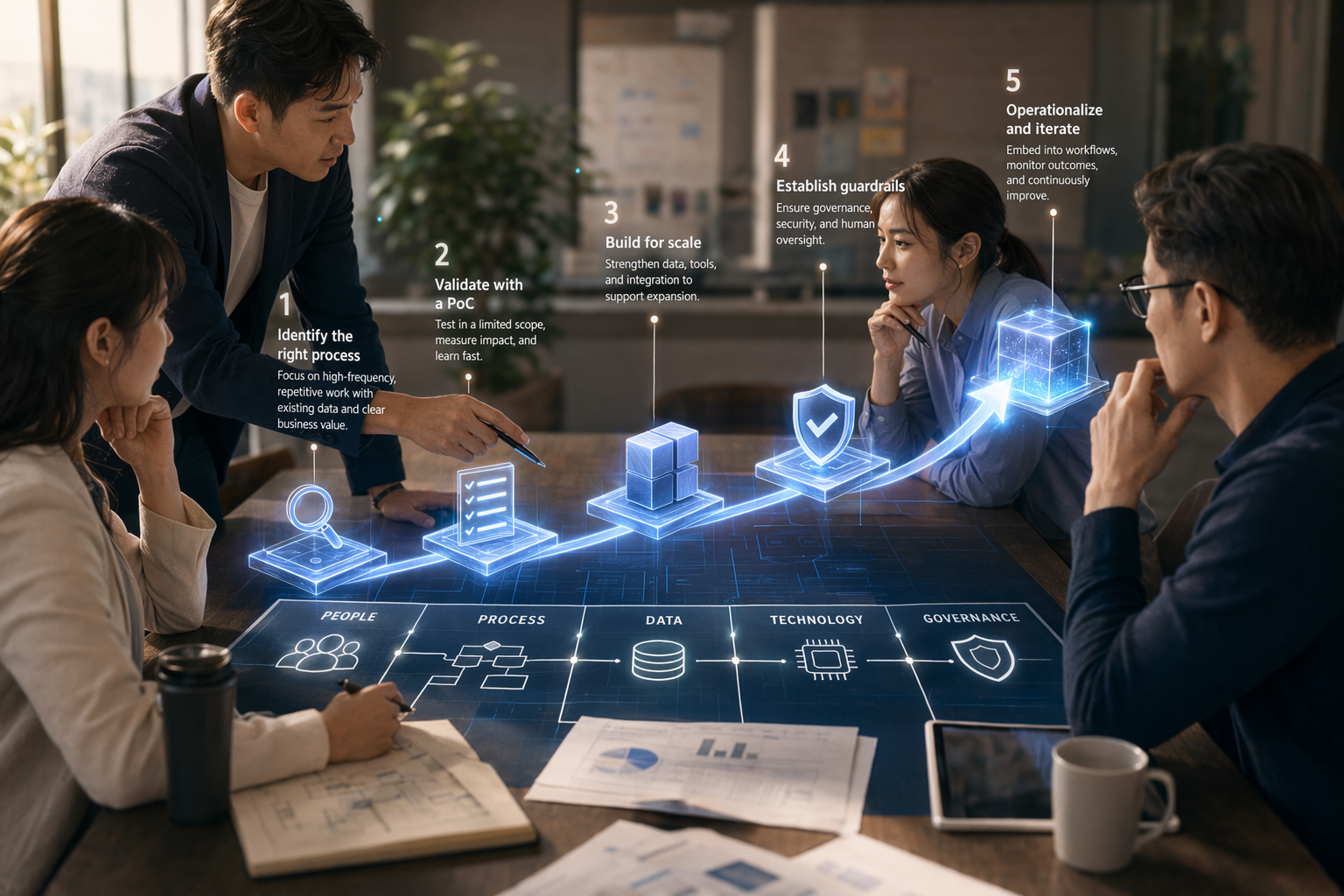
기업 AI 도입의 핵심은 먼저 모델을 사는 것이 아니라, 반복 빈도가 높고 측정 가능하며 사람이 검토할 수 있는 업무 흐름을 실제 데이터와 KPI에 연결하는 것이다. 실행 순서는 ① 비즈니스 문제와 오너 정의 ② 1–3개 우선 과제 선정 ③ 데이터·권한·시스템 연동 점검 ④ 실제 업무 흐름에 붙인 PoC 운영 ⑤ 거버넌스 통과 후 확대가 바람직하다.
企業 AI 導入指南:5 步把 PoC 變成可落地流程企業 AI 落地的重點,是把 PoC 接入真實流程、資料、權限與治理,而不只是展示模型能力。
AI 프롬프트
Create a landscape editorial hero image for this Studio Global article: 企業 AI 導入指南:5 步把 PoC 變成可落地流程. Article summary: 企業導入 AI 應從高頻、重複、資料已存在且可人工覆核的流程開始,而不是先買模型;The Consulting Report 整理 McKinsey 調查指出,88% 組織已在至少一個業務功能使用 AI,但近三分之二仍停在實驗或早期 pilot。[5]. Topic tags: ai, enterprise ai, ai adoption, ai governance, agents. Reference image context from search candidates: Reference image 1: visual subject "## 洞察觀點. ## 企業如何導入AI才能見效?多數專案失敗關鍵藏在第一步. 你可能也聽過這樣的故事:公司投入大筆預算導入AI,卻在半年後發現「用不起來」。工具買了、資料也蒐集了,但成果遲遲沒有顯現。這時大家開始懷疑:「是不是AI不適合我們?」. 其實,多數導入失敗的企業問題都不在技術,而在方向一開始就沒對準。AI不是萬能解方,它更像一面鏡子——會放大企業" source context "企業如何導入AI才能見效?多數專案失敗關鍵藏在第一步 | 先行智庫|企業培訓與數位轉型領導品牌" Reference image 2: visual subject "在全面導入前,應先透過概念驗證(POC)進行小範圍測試,例如針對單一部門或流程進行試跑,觀察實際效果與數據回饋。這個階段的重點不是做到完美,而是快速驗證" source context "企業 AI 導入怎麼做?從 0 開始建立完整流程與 4 大盲點一次看 - Growth Strategy—你的成長績效策略部門" Style: premium digital editorial illustration, source-backed re
openai.com
기업이 AI를 도입할 때 가장 자주 막히는 지점은 모델 성능만이 아니다. 더 큰 문제는 AI가 실제 업무 방식을 바꿀 수 있느냐다. 필요한 데이터에 안전하게 접근할 수 있는지, 결과물이 CRM·ERP·문서 시스템·업무 포털 같은 기존 시스템으로 돌아가는지, KPI는 누가 책임지는지, 권한과 리스크는 통제되는지가 관건이다.
McKinsey 글로벌 조사를 정리한 한 보도에 따르면, 조직의 88%가 최소 1개 업무 기능에서 AI를 사용하고 있지만 거의 3분의 2는 여전히 실험 또는 초기 파일럿 단계에 머물러 있다. 다시 말해 많은 기업에 AI 시도는 이미 있다. 부족한 것은 시범사업을 안정적인 운영 역량으로 바꾸는 방법이다.
먼저 모델이 아니라 업무 흐름을 고른다
기업 AI의 출발점은 ‘어떤 모델을 쓸까’가 아니라 ‘어떤 업무를 다시 설계할 가치가 있는가’다. 첫 과제는 꼭 가장 크고 화려할 필요가 없다. 오히려 자주 발생하고, 데이터 출처가 분명하며, 결과를 측정할 수 있고, 오류가 생겼을 때 사람이 검토할 수 있는 업무가 좋다.
우선 검토할 만한 업무는 보통 다음 조건을 갖춘다.
부서가 매일 또는 매주 비슷한 일을 반복한다.
필요한 자료가 문서 저장소, CRM, ERP, 고객 문의·티켓 시스템, 데이터웨어하우스, 내부 지식베이스 등에 이미 있다.
현재 업무에 뚜렷한 병목이 있다. 예를 들어 검색 시간이 길거나, 복사·붙여넣기가 많거나, 답변이 담당자마다 다르거나, 재작업이 잦다.
AI 결과를 사람이 검토·샘플링·수정할 수 있고, 필요하면 수동 처리로 넘길 수 있다.
현업 오너가 프로세스를 바꿀 의지가 있고 성과에 책임질 수 있다.
이 조건이 없는 상태에서 도구나 모델부터 구매하면 멋진 데모는 만들 수 있어도 지속 가능한 운영 성과로 이어지기 어렵다.
PoC를 운영 역량으로 바꾸는 5단계
1. 요구사항을 측정 가능한 비즈니스 문제로 쓴다
프로젝트명을 ‘AI 도입’으로 잡으면 성공 여부를 판단하기 어렵다. 더 좋은 방식은 특정 업무에서 어떤 사용자가 어떤 반복 작업을 하고 있으며, 현재 어디서 막히고, AI 개입 후 어떤 지표를 얼마나 개선할 것인지부터 쓰는 것이다.
다음 문장으로 시작해볼 수 있다.
업무 A에서 역할 B는 매주 작업 C에 많은 시간을 쓴다. AI를 활용해 지표 D를 현재 기준값에서 목표값까지 개선하고, 현업 오너 E가 프로세스 조정과 성과 검증을 책임진다.
착수 전에 최소한 다음 질문에 답해야 한다.
이 AI 기능을 매일 사용할 사람은 누구인가?
AI는 독립된 챗봇인가, 아니면 기존 업무의 어느 단계에 들어가는가?
현재 기준값은 얼마인가? 예: 처리 시간, 오류율, 전환율, 고객 불만, 투입 인력 시간.
성공 KPI는 효율, 품질, 매출, 비용, 리스크, 직원 경험 중 무엇인가?
프로세스 변경을 결정하고 결과를 책임질 사람은 누구인가?
현업 오너와 기준값이 없으면 PoC, 즉 개념검증이 성공했는지 판단하기 어렵고 조직 내 확산도 설득하기 어렵다.
2. 고빈도·반복·기존 데이터가 있는 1–3개 과제를 고른다
첫 과제는 범위를 크게 잡기보다 빈도가 높고 반복적이며 데이터 출처가 명확하고 오류 비용을 통제할 수 있는 업무가 적합하다.
후보 과제
먼저 시도하기 좋은 이유
첫 KPI 예시
고객지원 지식 검색
답변 근거가 FAQ, 제품 문서, 문의 이력, 내부 지식베이스에 있는 경우가 많다
평균 처리 시간, 1차 해결률, 샘플 정답률, 고객 불만 건수
Studio Global AI
Search, cite, and publish your own answer
Use this topic as a starting point for a fresh source-backed answer, then compare citations before you share it.
"기업 AI 도입 가이드: PoC에서 현업 적용까지 5단계와 KPI"에 대한 짧은 대답은 무엇입니까?
기업 AI 도입의 핵심은 먼저 모델을 사는 것이 아니라, 반복 빈도가 높고 측정 가능하며 사람이 검토할 수 있는 업무 흐름을 실제 데이터와 KPI에 연결하는 것이다.
먼저 검증할 핵심 포인트는 무엇인가요?
기업 AI 도입의 핵심은 먼저 모델을 사는 것이 아니라, 반복 빈도가 높고 측정 가능하며 사람이 검토할 수 있는 업무 흐름을 실제 데이터와 KPI에 연결하는 것이다. 실행 순서는 ① 비즈니스 문제와 오너 정의 ② 1–3개 우선 과제 선정 ③ 데이터·권한·시스템 연동 점검 ④ 실제 업무 흐름에 붙인 PoC 운영 ⑤ 거버넌스 통과 후 확대가 바람직하다.
실무에서는 다음으로 무엇을 해야 합니까?
AI 에이전트는 더 신중하게 확장해야 한다. McKinsey 2025년 조사 요약에 따르면 어떤 단일 기능에서도 AI 에이전트를 규모 있게 적용했다고 답한 응답자는 10%를 넘지 않았고, 보안과 리스크는 agentic AI 확장의 주요 장벽으로 지목됐다.[2][8]
처음부터 가장 위험하고 복잡하며 책임 경계가 모호한 과제를 고르는 것은 피하는 편이 낫다. 데이터가 흩어져 있거나 업무가 표준화되지 않았거나, 규제·준법 요구가 높은데 거버넌스가 없다면 먼저 데이터와 프로세스부터 정비해야 한다.
3. PoC 전에 데이터·권한·시스템 연동을 점검한다
AI 도입의 난점은 종종 모델 자체보다 데이터 접근에 있다. 필요한 데이터를 안전하고 정확하게, 가능한 한 최신 상태로 가져올 수 있어야 한다.
Talyx가 RAND Corporation의 2024년 연구를 정리한 내용에 따르면, 이 연구는 숙련된 데이터 과학자와 엔지니어 65명을 인터뷰해 AI 프로젝트 실패의 주요 원인으로 문제 정의에 대한 오해, 불충분한 학습 데이터, 문제보다 기술을 앞세우는 접근, 부족한 인프라, 애초에 너무 어려운 문제 설정을 제시했다.
PoC 전에 최소한 다음 항목을 확인해야 한다.
데이터는 어디에 있는가? 문서 저장소, CRM, ERP, 티켓 시스템, 데이터웨어하우스, 또는 개인 PC와 파일에 흩어져 있는가?
데이터 품질은 어떤가? 오래됐거나 중복됐거나 필드가 비었거나 형식이 제각각인가?
권한은 어떻게 관리되는가? 부서, 직급, 지역에 따라 볼 수 있는 정보가 다른가?
업데이트 주기는 어떤가? AI가 최신 자료를 바탕으로 답하는가, 몇 달 전 자료를 보고 답하는가?
시스템 연동이 가능한가? AI 결과가 티켓, CRM, 보고서, 승인, 문서 업무 흐름으로 다시 들어갈 수 있는가?
감사 추적이 가능한가? 누가 무엇을 물었고, AI가 무엇을 답했으며, 누가 채택하거나 수정했는지 기록할 수 있는가?
데이터가 쓸 수 없는 상태라면 강력한 모델도 시연용에 그친다. 권한 설계가 불명확하면 정보보안, 개인정보, 법무, 감사 검토 단계에서 프로젝트가 멈출 가능성이 크다.
4. PoC는 작게 하되 실제 업무 흐름에 붙인다
PoC는 회의실에서 보여주는 데모가 아니라 1차 제품에 가깝게 설계해야 한다. 실제 사용자, 실제 데이터, 실제 업무 흐름을 연결하고 성공·확대·중단 기준을 미리 정해야 한다.
운영으로 이어질 수 있는 PoC는 다음 질문에 답할 수 있어야 한다.
사용자는 어디서 AI를 호출하는가? 고객지원 콘솔, Slack, Teams, CRM, 내부 포털, 기존 업무 시스템 중 어디인가?
AI가 만든 결과는 누가 검토하는가? 어떤 상황에서는 반드시 사람에게 넘겨야 하는가?
오류는 어떻게 신고하는가? 신고 후 누가 데이터를 고치고, 규칙이나 프롬프트를 조정하는가?
어떤 작업은 보조만 가능하고 자동 완료는 금지해야 하는가?
어떤 KPI 기준을 넘으면 확대하고, 어떤 기준을 넘지 못하면 중단할 것인가?
이 단계의 핵심은 AI가 답변을 생성할 수 있음을 증명하는 데 있지 않다. 기존 업무 안에서 안정적으로 쓰이고, 특정 지표를 실제로 개선한다는 것을 증명해야 한다.
5. 거버넌스를 통과한 뒤 두 번째 부서나 더 높은 자동화로 넓힌다
AI 확장은 계정 수를 늘리는 일이 아니다. 한 부서에서 다른 부서로 넘어갈 때마다 새로운 데이터 출처, 권한 규칙, 업무 차이, 법무·보안 요구, KPI가 등장한다.
특히 AI가 검색, 요약, 초안 작성 수준을 넘어 더 자율적으로 행동하는 AI 에이전트로 갈수록 단계적 접근이 필요하다. McKinsey 2025년 조사 요약에 따르면 어떤 단일 기능에서도 AI 에이전트를 규모 있게 적용했다고 답한 응답자는 10%를 넘지 않았다. McKinsey는 또한 보안과 리스크가 agentic AI 확장의 최우선 장벽이며, 부정확성과 사이버보안이 가장 자주 언급되는 AI 리스크라고 지적했다.
더 안전한 확장 순서는 다음과 같다.
먼저 AI가 검색, 정리, 요약, 초안 작성을 돕게 한다.
human-in-the-loop, 즉 사람이 검토하는 단계를 유지하며 오류·예외·사용 기록을 쌓는다.
정확도, 프로세스 안정성, 권한, 감사 체계가 성숙하면 낮은 리스크의 단계부터 자동화한다.
새 부서로 확장할 때마다 데이터, 권한, 법무, 보안, 개인정보, 감사 요구를 다시 검토한다.
KPI는 모델 정확도만 보지 않는다
AI 프로젝트에서 모델 정확도만 보면 실제 운영 가치가 빠지기 쉽다. 먼저 현재 기준값을 측정하고, 여러 층위의 KPI로 확대 여부를 판단하는 편이 좋다.
KPI 유형
지표 예시
적합한 과제
효율
평균 처리 시간, 리드타임, 건당 투입 인력 시간, 보고서 작성 시간
고객지원, 보고서, 증빙 문서, 문서 질의응답
품질
샘플 정답률, 사람이 채택한 비율, 재작업률, 고객 불만 건수
고객 답변, 계약 항목 추출, 콘텐츠 초안
사용성
주간 활성 사용자, 업무 커버리지, 반복 사용률, 다른 담당자에게 재질문한 횟수
내부 AI 비서, 지식 검색, 부서 도구
비즈니스 결과
전환율, 응답 속도, 사건 종결률, 건당 비용
영업, 고객지원, 구매, 운영 프로세스
리스크·거버넌스
사람에게 넘긴 비율, 정책 위반 건수, 민감정보 처리 예외, 감사 지적
고위험 데이터, 외부 답변, AI 에이전트
KPI는 처음부터 많을 필요는 없다. 다만 반드시 업무 흐름과 연결돼야 한다. PoC가 AI의 문장 생성 능력만 보여주고, 업무가 더 빨라졌는지, 더 정확해졌는지, 인력이 절감됐는지, 통제가 쉬워졌는지를 입증하지 못한다면 아직 현업 적용이라고 보기 어렵다.
많은 AI 프로젝트가 현업에 남지 못하는 이유
1. 도구를 먼저 사고 과제를 나중에 찾는다
많은 프로젝트가 공급사 데모나 모델 기능에서 출발한다. 그러면 보기에는 화려하지만 매일 써야 할 사람이 없는 기능이 나오기 쉽다. Talyx가 정리한 RAND 연구도 문제보다 기술을 앞세우는 접근을 AI 프로젝트 실패의 주요 원인 중 하나로 제시했다.
2. 문제 정의가 흐려 부서마다 기대가 다르다
현업은 고객지원 시간을 줄이고 싶어 하고, IT는 모델 정확도를 높이고 싶어 하며, 경영진은 비용 절감을 기대하고, 법무는 리스크를 우려할 수 있다. 목표가 정렬되지 않으면 프로젝트는 서로 다른 기대 사이에서 흔들린다. 문제 정의에 대한 오해 역시 AI 프로젝트 실패 원인으로 지목됐다.
3. 데이터와 시스템이 연결되지 않는다
AI가 정확한 문서, 고객 정보, 문의 이력, 거래 데이터를 가져올 수 없다면 일반적인 답변에 머물 가능성이 높다. 또 결과물이 CRM, ERP, 문서 저장소, 티켓 시스템으로 돌아가지 않으면 사용자는 여전히 복사·붙여넣기를 해야 한다. 이 경우 AI가 만든 가치가 업무 비용에 먹힌다. 부족한 인프라도 Talyx가 정리한 RAND 연구의 주요 실패 원인 중 하나다.
4. PoC가 실제 일하는 방식을 바꾸지 않는다
기업의 AI 사용률이 높아졌다는 사실이 곧 규모 있는 운영 정착을 뜻하지는 않는다. McKinsey 조사를 정리한 보도에 따르면 조직의 88%가 최소 1개 업무 기능에서 AI를 사용하지만, 거의 3분의 2는 실험이나 초기 파일럿 단계에 머물러 있다. PoC가 실제 업무 흐름에 들어가지 않고, 현업 오너와 KPI도 없다면 프로젝트는 전시용 사례로 끝나기 쉽다.
5. 리스크 거버넌스를 너무 늦게 붙인다
보안, 개인정보, 준법, 감사, 권한 통제를 출시 직전에 검토하면 프로젝트를 다시 설계해야 할 수 있다. AI 에이전트는 더 그렇다. 자율성이 높아질수록 데이터 경계, 실행 권한, 사람 검토, 책임 소재가 더 명확해야 하기 때문이다. McKinsey는 보안과 리스크가 agentic AI 확장의 최우선 장벽이라고 설명했다.
먼저 할 과제와 미뤄야 할 과제 구분하기
먼저 검토하기 좋은 과제
일단 보류하는 편이 나은 과제
매주 또는 매월 자주 반복되는 업무
1년에 몇 번 발생하지 않는 특수 업무
데이터가 전자화돼 있고 출처가 명확한 업무
자료가 개인 파일, 구두 경험, 비공식 기록에 흩어진 업무
규칙이 비교적 분명하고 답변 근거를 추적할 수 있는 업무
문제 정의가 불명확하고 부서마다 해석이 다른 업무
오류를 사람이 검토하고 수정할 수 있는 업무
오류가 곧바로 중대한 법무·재무·안전 문제로 이어지는 업무
현업 오너가 프로세스 변경에 참여하는 업무
IT나 컨설턴트만 추진하고 사용 부서가 관여하지 않는 업무
시간, 정확도, 비용, 고객 불만처럼 KPI를 수치화할 수 있는 업무
‘혁신’이나 ‘AI화’만 말하고 성과 정의가 없는 업무
오른쪽에 있는 과제가 영원히 불가능하다는 뜻은 아니다. 다만 먼저 데이터 정비, 프로세스 표준화, 책임 구분, 거버넌스 설계를 마친 뒤 AI를 붙이는 편이 안전하다.
AI 도입 전 10문항 체크리스트
새 AI 프로젝트를 시작하기 전에 다음 질문을 한 번에 점검해보자.
이 과제는 어떤 구체적 비즈니스 문제를 해결하는가?
현재 업무 기준값은 얼마인가? 예: 시간, 오류율, 비용, 고객 불만.
현업 오너는 누구인가? 프로세스 변경을 결정할 권한이 있는가?
사용자가 실제로 이 문제를 자주 겪는가?
필요한 데이터는 이미 존재하고, 접근 가능하며, 업데이트되는가?
권한, 개인정보, 법무, 보안, 감사 요구가 명확한가?
AI 결과는 어떤 실제 시스템이나 업무 흐름으로 들어가는가?
어떤 상황에서는 반드시 사람이 검토해야 하는가?
성공, 확대, 중단을 판단할 KPI 기준은 무엇인가?
두 번째 부서로 확장할 때도 데이터, 프로세스, 리스크 조건이 유효한가?
결론: 전사 AI보다 먼저 한 업무를 제대로 바꿔야 한다
기업 AI 도입은 모델 구매가 아니라 프로세스 개선에서 출발해야 한다. 모델은 필요한 역량이지만, 현업 적용 그 자체는 아니다. PoC가 운영으로 넘어갈 수 있는지는 데이터가 쓸 수 있는 상태인지, 권한이 명확한지, 업무 방식이 실제로 바뀌는지, 리스크가 통제되는지, KPI가 가치를 증명하는지에 달려 있다.
가장 현실적인 전략은 작게 시작하되 진짜 업무에 붙이는 것이다. 한 업무에서 성과와 통제 구조를 만든 뒤 다음 부서로 넓혀야 AI가 실험실을 벗어나 회사의 운영 능력이 된다.
Why 80% of Enterprise AI Projects Fail | AI Readi Blog