¿Cuál es el benchmark de Claude Opus 4.7?
Depende de qué benchmark te interese. Para Claude Opus 4.7, los números más citados son de coding/agentes: 87.6% en SWE bench Verified, 64.3% en SWE bench Pro, 69.4% en Terminal Bench 2.0 y 64.4% en Finance Agent v1.1...
Depende de qué benchmark te interese. Para Claude Opus 4.7, los números más citados son de coding/agentes: 87.6% en SWE bench Verified, 64.3% en SWE bench Pro, 69.4% en Terminal Bench 2.0 y 64.4% en Finance Agent v1.1, según AWS citando datos de Anthropic [7]. Anthropic describe a Claude Opus 4.7 como una mejora sobre
Conclusiones clave
- Depende de qué benchmark te interese. Para Claude Opus 4.7, los números más citados son de coding/agentes: 87.6% en SWE-bench Verified, 64.3% en SWE-bench Pro, 69.4% en Terminal-Bench 2.0 y 64.4% en Finance Agent v1.1, según AWS citando datos de Anthropic [7].
- Anthropic describe a Claude Opus 4.7 como una mejora sobre Opus 4.6 en ingeniería de software avanzada, tareas largas, seguimiento de instrucciones y visión [8].
Respuesta de investigación
Depende de qué benchmark te interese. Para Claude Opus 4.7, los números más citados son de coding/agentes: 87.6% en SWE-bench Verified, 64.3% en SWE-bench Pro, 69.4% en Terminal-Bench 2.0 y 64.4% en Finance Agent v1.1, según AWS citando datos de Anthropic [7].
- Anthropic describe a Claude Opus 4.7 como una mejora sobre Opus 4.6 en ingeniería de software avanzada, tareas largas, seguimiento de instrucciones y visión [
8].
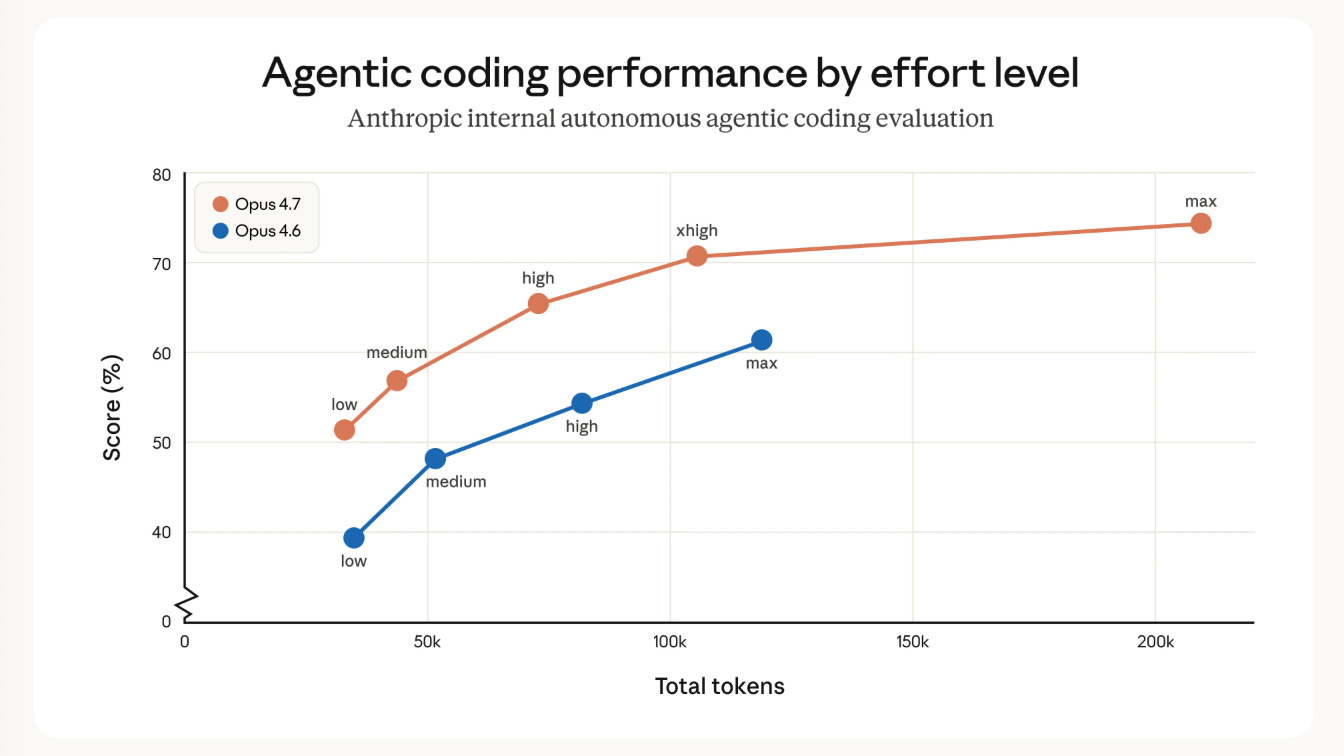
- En un benchmark interno de coding de 93 tareas, Opus 4.7 mejoró la “resolución” un 13% frente a Opus 4.6 [
8].
- En un benchmark interno de “research-agent”, Opus 4.7 empató el mejor score general con 0.715 y obtuvo 0.813 en el módulo de General Finance frente a 0.767 de Opus 4.6 [
8].
- En benchmarks públicos/semipúblicos citados por AWS: SWE-bench Pro 64.3%, SWE-bench Verified 87.6%, Terminal-Bench 2.0 69.4% y Finance Agent v1.1 64.4% [
7].
- Ojo: hay fuentes secundarias que reportan cifras distintas —por ejemplo, 82.4% en SWE-bench Verified—, así que para una cifra “oficial” conviene priorizar Anthropic/AWS y especificar el harness o configuración usada [
2][
7].
Si me dices si lo quieres comparar contra GPT-5.5, Gemini o Claude Sonnet 4.6, te preparo una tabla breve.
Imágenes de apoyo





Conversación de investigación
Pregunta de investigación
¿Cuál es el benchmark de Claude Opus 4.7?
Respuesta citada
Depende de qué benchmark te interese. Para Claude Opus 4.7, los números más citados son de coding/agentes: 87.6% en SWE-bench Verified, 64.3% en SWE-bench Pro, 69.4% en Terminal-Bench 2.0 y 64.4% en Finance Agent v1.1, según AWS citando datos de Anthropic [7].
- Anthropic describe a Claude Opus 4.7 como una mejora sobre Opus 4.6 en ingeniería de software avanzada, tareas largas, seguimiento de instrucciones y visión [
8].
- En un benchmark interno de coding de 93 tareas, Opus 4.7 mejoró la “resolución” un 13% frente a Opus 4.6 [
8].
- En un benchmark interno de “research-agent”, Opus 4.7 empató el mejor score general con 0.715 y obtuvo 0.813 en el módulo de General Finance frente a 0.767 de Opus 4.6 [
8].
- En benchmarks públicos/semipúblicos citados por AWS: SWE-bench Pro 64.3%, SWE-bench Verified 87.6%, Terminal-Bench 2.0 69.4% y Finance Agent v1.1 64.4% [
7].
- Ojo: hay fuentes secundarias que reportan cifras distintas —por ejemplo, 82.4% en SWE-bench Verified—, así que para una cifra “oficial” conviene priorizar Anthropic/AWS y especificar el harness o configuración usada [
2][
7].
Si me dices si lo quieres comparar contra GPT-5.5, Gemini o Claude Sonnet 4.6, te preparo una tabla breve.
La gente también pregunta
¿Cuál es la respuesta corta a "¿Cuál es el benchmark de Claude Opus 4.7?"?
Depende de qué benchmark te interese. Para Claude Opus 4.7, los números más citados son de coding/agentes: 87.6% en SWE-bench Verified, 64.3% en SWE-bench Pro, 69.4% en Terminal-Bench 2.0 y 64.4% en Finance Agent v1.1, según AWS citando datos de Anthropic [7].
¿Cuáles son los puntos clave a validar primero?
Depende de qué benchmark te interese. Para Claude Opus 4.7, los números más citados son de coding/agentes: 87.6% en SWE-bench Verified, 64.3% en SWE-bench Pro, 69.4% en Terminal-Bench 2.0 y 64.4% en Finance Agent v1.1, según AWS citando datos de Anthropic [7]. Anthropic describe a Claude Opus 4.7 como una mejora sobre Opus 4.6 en ingeniería de software avanzada, tareas largas, seguimiento de instrucciones y visión [8].
¿Qué tema relacionado debería explorar a continuación?
Continúe con "A partir de los benchmarks de Kimi K2.6, DeepSeek V4, GPT-5.5 y Claude Opus 4.7, compáralos." para conocer otro ángulo y citas adicionales.
Abrir página relacionada¿Con qué debería comparar esto?
Verifique esta respuesta con "Busca más información sobre GPT-5.5.".
Abrir página relacionadaContinúe su investigación
Fuentes
- [1] Models overview - Claude API Docsplatform.claude.com
| Feature | Claude Opus 4.7 | Claude Sonnet 4.6 | Claude Haiku 4.5 | --- --- | | Description | Our most capable generally available model for complex reasoning and agentic coding | The best combination of speed and intelligence | The fastest model with near-frontier intelligence | | Claude API ID | claude-opus-4-7 | claude-sonnet-4-6 | claude-haiku-4-5-20251001 | | Claude API alias | claude-opus-4-7 | claude-sonnet-4-6 | claude-haiku-4-5 | | AWS Bedrock ID | anthropic.claude-opus-4-73 | anthropic.claude-sonnet-4-6 | anthropic.claude-haiku-4-5-20251001-v1:0 | | GCP Vertex AI ID | claude-opus-4…
- [2] Claude Opus 4.7 Benchmark Breakdown: Vision, Coding, and ...mindstudio.ai
Claude Opus 4.7 posted 82.4% on SWE-bench Verified, up roughly 11 points from Opus 4.6 — the most meaningful coding benchmark available. Vision improvements were the largest percentage gains: MathVista jumped 9.5 points, enabling reliable visual math reasoning and structured chart interpretation. FinanceBench performance of 82.7% makes Opus 4.7 a strong choice for financial document analysis, handling most standard extraction and calculation tasks accurately. Opus 4.7 leads GPT-5.4 and Gemini 3.1 Pro across all five core benchmarks in this breakdown, with the most meaningful gap on SWE-bench.…
- [3] Claude Opus 4.7 Benchmark Full Analysis: Empirical Data Leading ...help.apiyi.com
Anthropic officially released Claude Opus 4.7 on April 16, 2026, taking the lead in 7 out of 10 core benchmarks. In this article, we’ll take a deep dive into the core data from the Claude Opus 4.7 benchmark and explore its practical use cases from a real-world testing perspective. This is not a recap of official marketing materials. All data comes from independent third-party evaluation agencies, covering both the strengths and the shortcomings of Opus 4.7, such as its performance in web search scenarios. Core Value: Through real-world benchmark data and hands-on experience, I’ll help you dec…
- [4] Claude Opus 4.7 Benchmarks 2026: Scores, Rankings & Performancebenchlm.ai
Knowledge ### Math ### Multilingual ### Multimodal ### Inst. Following ## Chatbot Arena Performance ## Benchmark Details Only benchmark rows with an attached exact-source record are shown here. Source-unverified manual rows and generated rows are hidden from model pages. ## Claude Opus 4.7 Family Base entry Related Earlier Model ## Compare This Model See how Claude Opus 4.7 stacks up against similar models ## Frequently Asked Questions ### How does Claude Opus 4.7 perform overall in AI benchmarks? Claude Opus 4.7 currently ranks #2 out of 110 models on BenchLM's provisional leaderboard wi…
- [5] Claude Opus 4.7 Benchmarks Explained - Vellumvellum.ai
Anthropic dropped Claude Opus 4.7 today, and the benchmark table tells a focused story. This is not a model that sweeps every leaderboard. Anthropic is explicit that Claude Mythos Preview remains more broadly capable. But for developers building production coding agents and long-running workflows, the improvements are real and well-targeted. Opus 4.7 is available now across the Claude API, Amazon Bedrock, Google Cloud Vertex AI, and Microsoft Foundry. Pricing stays the same as Opus 4.6: $5 per million input tokens and $25 per million output tokens. Here's what the numbers actually show. ## Ke…
- [6] Claude Opus 4.7: Pricing, Benchmarks & Context Window - ALM Corpalmcorp.com
For coding, the official materials point to several standout numbers. Anthropic says Opus 4.7 improved resolution by 13% over Opus 4.6 on a 93-task coding benchmark. AWS cites 64.3% on SWE-bench Pro, 87.6% on SWE-bench Verified, and 69.4% on Terminal-Bench 2.0. Anthropic also highlights gains such as 70% on CursorBench versus 58% for Opus 4.6, along with reports that the model resolves more production-grade tasks in internal and partner evaluations. Those numbers do not mean every coding workflow becomes 13% or 20% better overnight. What they do suggest is that Opus 4.7 is moving up where adv…
- [7] Introducing Anthropic’s Claude Opus 4.7 model in Amazon Bedrock | AWS News Blogaws.amazon.com
According to Anthropic, Claude Opus 4.7 model provides improvements across the workflows that teams run in production such as agentic coding, knowledge work, visual understanding,long-running tasks. Opus 4.7 works better through ambiguity, is more thorough in its problem solving, and follows instructions more precisely. The model is an upgrade from Opus 4.6 but may require prompting changes and harness tweaks to get the most out of the model. To learn more, visit Anthropic’s prompting guide. Claude Opus 4.7 model in action You can get started with Claude Opus 4.7 model in Amazon Bedrock conso…
- [8] Introducing Claude Opus 4.7 - Anthropicanthropic.com
Image 7: logo > Based on our internal research-agent benchmark, Claude Opus 4.7 has the strongest efficiency baseline we’ve seen for multi-step work. It tied for the top overall score across our six modules at 0.715 and delivered the most consistent long-context performance of any model we tested. On General Finance—our largest module—it improved meaningfully on Opus 4.6, scoring 0.813 versus 0.767, while also showing the best disclosure and data discipline in the group. And on deductive logic, an area where Opus 4.6 struggled, Opus 4.7 is solid. > > Michal Mucha > > Lead AI Engineer, Applied…
- [9] Anthropic releases Claude Opus 4.7: How to try it, benchmarks, safetymashable.com
Claude Mythos scored 56.8 percent on HLE Claude Opus 4.7 scored 46.9 percent Gemini 3.1 Pro scored 44.4 percent GPT-5-4 Pro scored 42.7 percent Claude Opus 4.6 scored 40.0 percent With tools, GPT-5-4-Pro scored 58.7 percent compared to Opus 4.7’s 54.7 percent. Mythos beat them both with 64.7 percent. Related Stories 'The AI Doc' director says cynicism is the only wrong answer to AI Anthropic sues Pentagon as Claude downloads soar Anthropic CEO warns that AI could bring slavery, bioterrorism, and unstoppable drone armies. I'm not buying it. Anthropic used mostly AI to build Claude Cowork tool…
- [10] Claude Opus 4.7anthropic.com
Enterprise workflows Opus 4.7 sets the standard for enterprise workflows, carrying context across sessions to manage complex, multi-day projects end-to-end with professional polish and strong performance on spreadsheets, slides, and docs. ## Benchmarks Claude Opus 4.7 is our most capable, generally available model, performing at the frontier across coding, agentic, and knowledge work capabilities. Image 3 ## Trust and safety Extensive testing and evaluation ensures the release of Opus 4.7 meets Anthropic’s standards for safety, security, and reliability. The accompanying model card covers…
- [11] Claude Opus 4.7 results: early benchmarks, real-world feedback ...boringbot.substack.com
Definitive head-to-head benchmarks for these specific model versions are still accumulating in the community, so treat these comparisons as directional rather than conclusive. What’s clear is that Claude Opus 4.7 benchmarks place it firmly in the top competitive tier for coding and agentic tasks, not a clean winner across the board, but a serious competitor in the scenarios that matter most to developers. Source: Anthropic | ### Multimodal capabilities — imaging and visual reasoning compared [...] Every time Anthropic drops a new model, my inbox fills up with the same question: “Is it actuall…
- [12] Official Benchmark of Anthropic's latest frontier model, ...facebook.com
Creator Inside - Official Benchmark of Anthropic's latest... | Facebook Log In Log In Forgot Account? ## Creator Inside's Post []( ### Creator Inside 16h · Official Benchmark of Anthropic's latest frontier model, Claude Opus 4.7Image 1: 🔥Image 2: 🤌🏻 Image 3: May be an image of text Image 4 Image 5 All reactions: 4 1 share Like Comment Image 6 Image 7 All reactions: 4 1 share Like Comment