A partir de los benchmarks de Kimi K2.6, DeepSeek V4, GPT-5.5 y Claude Opus 4.7, compáralos.
En conjunto: Claude Opus 4.7 parece liderar en razonamiento general y coding difícil, GPT 5.5 queda muy cerca y suele ser la opción “premium equilibrada”, Kimi K2.6 destaca por relación calidad/precio y código, y Deep...
En conjunto: Claude Opus 4.7 parece liderar en razonamiento general y coding difícil, GPT 5.5 queda muy cerca y suele ser la opción “premium equilibrada”, Kimi K2.6 destaca por relación calidad/precio y código, y DeepSeek V4 compite fuerte en coste pero queda por detrás en los benchmarks de frontera más duros. Los dato
Conclusiones clave
- En conjunto: Claude Opus 4.7 parece liderar en razonamiento general y coding difícil, GPT-5.5 queda muy cerca y suele ser la opción “premium equilibrada”, Kimi K2.6 destaca por relación calidad/precio y código, y DeepSeek V4 compite fuerte en coste pero queda por detrás en los be
- Los datos públicos no son perfectamente homogéneos: algunos benchmarks comparan variantes con herramientas, “high effort”, modos de razonamiento o configuraciones distintas, así que conviene leerlos como señales, no como ranking absoluto.
Respuesta de investigación
En conjunto: Claude Opus 4.7 parece liderar en razonamiento general y coding difícil, GPT-5.5 queda muy cerca y suele ser la opción “premium equilibrada”, Kimi K2.6 destaca por relación calidad/precio y código, y DeepSeek V4 compite fuerte en coste pero queda por detrás en los benchmarks de frontera más duros.
- Los datos públicos no son perfectamente homogéneos: algunos benchmarks comparan variantes con herramientas, “high effort”, modos de razonamiento o configuraciones distintas, así que conviene leerlos como señales, no como ranking absoluto.
- Donde hay cifras comparables, Opus 4.7 y GPT-5.5 tienden a estar arriba; Kimi K2.6 sorprende en coding/coste; DeepSeek V4 es competitivo por precio y contexto.
| Modelo | Lo más fuerte | Benchmarks / señales públicas | Coste y uso |
|---|---|---|---|
| Claude Opus 4.7 | Razonamiento, coding complejo, visión/documentos, contexto largo | Artificial Analysis lo describe como uno de los modelos líderes en inteligencia, aunque caro, lento y verboso; soporta entrada de texto e imagen y contexto de 1M tokens [ | Precio reportado: $5 por 1M tokens de entrada y $25 por 1M de salida, con disponibilidad vía API de Anthropic, Bedrock, Azure y Vertex [ |
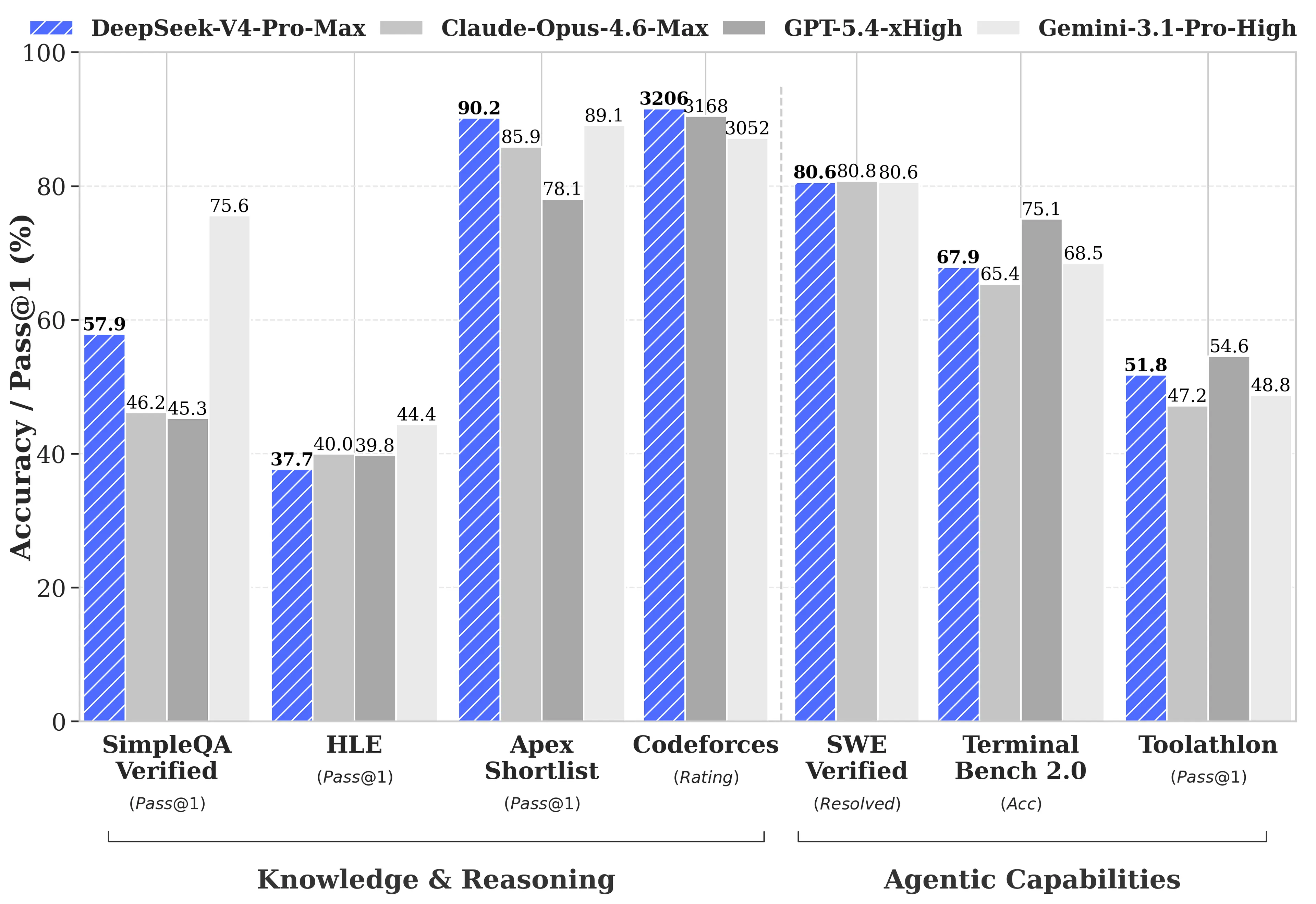
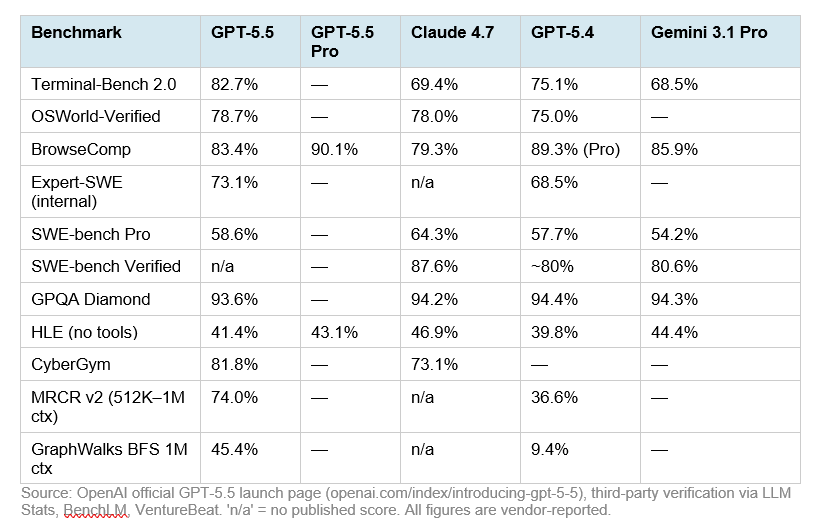
| GPT-5.5 | Equilibrio general, razonamiento con herramientas, ecosistema OpenAI/Codex | En HLE sin herramientas aparece con 41.4%, por detrás de Opus 4.7 pero por delante de DeepSeek V4; con herramientas sube a 52.2% [ | Una fuente reporta precio API de $5 por 1M tokens de entrada y $30 por 1M de salida, con contexto de 1M tokens [ |
| Kimi K2.6 | Coding agente y coste/rendimiento | CodeRouter lo describe como ganador de coste/calidad y dice que empata con GPT-5.5 en SWE-Bench Pro [ | Se reporta precio de $0.60/$4.00 por 1M tokens de entrada/salida, muy por debajo de Opus 4.7 y GPT-5.5 [ |
| DeepSeek V4 | Coste, API barata, buena opción si el presupuesto importa | En HLE sin herramientas aparece con 37.7%, por debajo de GPT-5.5 y Opus 4.7; con herramientas sube a 48.2%, pero sigue por debajo de GPT-5.5 y Opus 4.7 [ | Una fuente reporta precio de $1.74 por 1M tokens de entrada y $3.48 por 1M de salida, con contexto de 1M tokens [ |
Ranking práctico
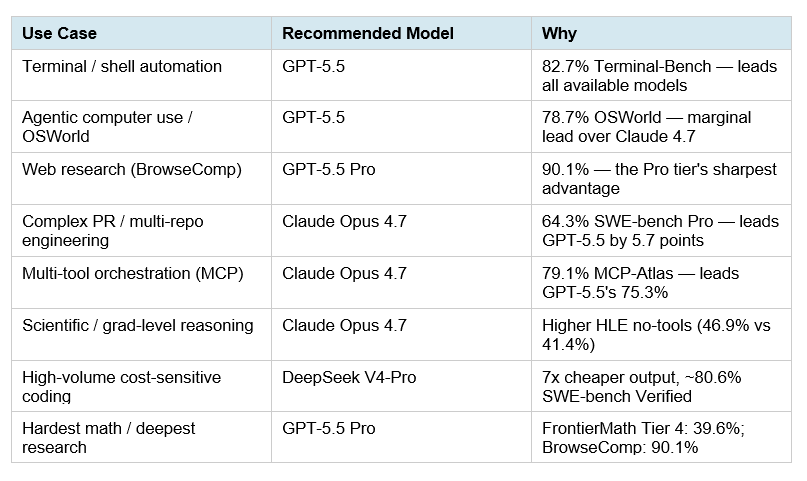
- Mejor calidad bruta: Claude Opus 4.7, especialmente si importan razonamiento difícil, documentos largos, visión y coding complejo [
2][
5][
8].
- Mejor equilibrio premium: GPT-5.5, cerca de Opus en HLE con herramientas y empatado con Kimi K2.6 en SWE-Bench Pro según una comparativa [
5][
8].
- Mejor coste/rendimiento para coding: Kimi K2.6, porque empata con GPT-5.5 en SWE-Bench Pro en la comparativa citada y cuesta bastante menos [
7][
8].
- Mejor opción barata con contexto largo: DeepSeek V4, aunque sus resultados HLE y SWE-Bench Pro quedan por detrás de Opus 4.7, GPT-5.5 y Kimi K2.6 en las cifras disponibles [
3][
5][
8].
Si tuviera que elegir uno: Opus 4.7 para máxima calidad, Kimi K2.6 para producción sensible a coste, GPT-5.5 para integración OpenAI/Codex, y DeepSeek V4 para alto volumen barato con rendimiento razonable.
Imágenes de apoyo









Conversación de investigación
Pregunta de investigación
A partir de los benchmarks de Kimi K2.6, DeepSeek V4, GPT-5.5 y Claude Opus 4.7, compáralos.
Respuesta citada
En conjunto: Claude Opus 4.7 parece liderar en razonamiento general y coding difícil, GPT-5.5 queda muy cerca y suele ser la opción “premium equilibrada”, Kimi K2.6 destaca por relación calidad/precio y código, y DeepSeek V4 compite fuerte en coste pero queda por detrás en los benchmarks de frontera más duros.
- Los datos públicos no son perfectamente homogéneos: algunos benchmarks comparan variantes con herramientas, “high effort”, modos de razonamiento o configuraciones distintas, así que conviene leerlos como señales, no como ranking absoluto.
- Donde hay cifras comparables, Opus 4.7 y GPT-5.5 tienden a estar arriba; Kimi K2.6 sorprende en coding/coste; DeepSeek V4 es competitivo por precio y contexto.
| Modelo | Lo más fuerte | Benchmarks / señales públicas | Coste y uso |
|---|---|---|---|
| Claude Opus 4.7 | Razonamiento, coding complejo, visión/documentos, contexto largo | Artificial Analysis lo describe como uno de los modelos líderes en inteligencia, aunque caro, lento y verboso; soporta entrada de texto e imagen y contexto de 1M tokens [ | Precio reportado: $5 por 1M tokens de entrada y $25 por 1M de salida, con disponibilidad vía API de Anthropic, Bedrock, Azure y Vertex [ |
| GPT-5.5 | Equilibrio general, razonamiento con herramientas, ecosistema OpenAI/Codex | En HLE sin herramientas aparece con 41.4%, por detrás de Opus 4.7 pero por delante de DeepSeek V4; con herramientas sube a 52.2% [ | Una fuente reporta precio API de $5 por 1M tokens de entrada y $30 por 1M de salida, con contexto de 1M tokens [ |
| Kimi K2.6 | Coding agente y coste/rendimiento | CodeRouter lo describe como ganador de coste/calidad y dice que empata con GPT-5.5 en SWE-Bench Pro [ | Se reporta precio de $0.60/$4.00 por 1M tokens de entrada/salida, muy por debajo de Opus 4.7 y GPT-5.5 [ |
| DeepSeek V4 | Coste, API barata, buena opción si el presupuesto importa | En HLE sin herramientas aparece con 37.7%, por debajo de GPT-5.5 y Opus 4.7; con herramientas sube a 48.2%, pero sigue por debajo de GPT-5.5 y Opus 4.7 [ | Una fuente reporta precio de $1.74 por 1M tokens de entrada y $3.48 por 1M de salida, con contexto de 1M tokens [ |
Ranking práctico
- Mejor calidad bruta: Claude Opus 4.7, especialmente si importan razonamiento difícil, documentos largos, visión y coding complejo [
2][
5][
8].
- Mejor equilibrio premium: GPT-5.5, cerca de Opus en HLE con herramientas y empatado con Kimi K2.6 en SWE-Bench Pro según una comparativa [
5][
8].
- Mejor coste/rendimiento para coding: Kimi K2.6, porque empata con GPT-5.5 en SWE-Bench Pro en la comparativa citada y cuesta bastante menos [
7][
8].
- Mejor opción barata con contexto largo: DeepSeek V4, aunque sus resultados HLE y SWE-Bench Pro quedan por detrás de Opus 4.7, GPT-5.5 y Kimi K2.6 en las cifras disponibles [
3][
5][
8].
Si tuviera que elegir uno: Opus 4.7 para máxima calidad, Kimi K2.6 para producción sensible a coste, GPT-5.5 para integración OpenAI/Codex, y DeepSeek V4 para alto volumen barato con rendimiento razonable.
La gente también pregunta
¿Cuál es la respuesta corta a "A partir de los benchmarks de Kimi K2.6, DeepSeek V4, GPT-5.5 y Claude Opus 4.7, compáralos."?
En conjunto: Claude Opus 4.7 parece liderar en razonamiento general y coding difícil, GPT-5.5 queda muy cerca y suele ser la opción “premium equilibrada”, Kimi K2.6 destaca por relación calidad/precio y código, y DeepSeek V4 compite fuerte en coste pero queda por detrás en los be
¿Cuáles son los puntos clave a validar primero?
En conjunto: Claude Opus 4.7 parece liderar en razonamiento general y coding difícil, GPT-5.5 queda muy cerca y suele ser la opción “premium equilibrada”, Kimi K2.6 destaca por relación calidad/precio y código, y DeepSeek V4 compite fuerte en coste pero queda por detrás en los be Los datos públicos no son perfectamente homogéneos: algunos benchmarks comparan variantes con herramientas, “high effort”, modos de razonamiento o configuraciones distintas, así que conviene leerlos como señales, no como ranking absoluto.
¿Qué tema relacionado debería explorar a continuación?
Continúe con "Busca más información sobre GPT-5.5." para conocer otro ángulo y citas adicionales.
Abrir página relacionada¿Con qué debería comparar esto?
Verifique esta respuesta con "¿Cómo puedo acceder a GPT-5.5 en España?".
Abrir página relacionadaContinúe su investigación
Fuentes
- [1] DeepSeek is back among the leading open weights models with V4 Pro ...artificialanalysis.ai
Benchmarks and Analysis of Kimi K2.6 April 21, 2026 ### Opus 4.7: Everything you need to know Benchmarks and Analysis of Opus 4.7 April 17, 2026 Artificial Analysis Subscribe to our newsletter Artificial Analysis Explore Company © 2026 Artificial Analysis [...] Gains in knowledge but an increase in hallucination rate: DeepSeek V4 Pro (Max) scores -10 on AA-Omniscience, an 11 point improvement over V3.2 (Reasoning, -21), driven primarily by higher accuracy. V4 Flash (Max) scores -23, broadly in line with V3.2. V4 Pro and V4 Flash both have a very high hallucination rate of 94% and 96% respecti…
- [2] DeepSeek V4 is here: How it compares to ChatGPT, Claude, Geminimashable.com
Credit: Long Wei/VCG via Getty Images Anything you can do I can do better... That may as well be the motto for the AI arms race, which is unfolding across multiple dimensions in 2026. There's the competition between Silicon Valley AI labs like Anthropic, OpenAI, and Google DeepMind, the race for chips and compute power, and, of course, the fierce competition between the U.S. and China. In the latest salvo in the East vs. West battle for AI supremacy, Chinese artificial intelligence company DeepSeek") has released a preview of its latest model, DeepSeek V4. You May Also Like --- Here's what we…
- [3] DeepSeek-V4 arrives with near state-of-the-art intelligence at 1/6th ...venturebeat.com
On Humanity’s Last Exam without tools, DeepSeek scores 37.7%, behind GPT-5.5 at 41.4%, GPT-5.5 Pro at 43.1% and Claude Opus 4.7 at 46.9%. With tools enabled, DeepSeek rises to 48.2%, but still trails GPT-5.5 at 52.2%, GPT-5.5 Pro at 57.2% and Claude Opus 4.7 at 54.7%. The agentic and software-engineering results are more mixed, but they still show DeepSeek-V4-Pro-Max trailing GPT-5.5 and Opus 4.7. On Terminal-Bench 2.0, DeepSeek’s 67.9% is competitive with Claude Opus 4.7’s 69.4%, but GPT-5.5 is much higher at 82.7%. On SWE-Bench Pro, DeepSeek’s 55.4% trails GPT-5.5 at 58.6% and Claude Opus 4…
- [4] GPT-5.5, DeepSeek V4, Kimi K2.6 at a Glance - CodeRoutercoderouter.io
TL;DR — In one week (April 20–23, 2026), four frontier coding models shipped: Kimi K2.6 (Moonshot, Apr 20), GPT-5.5 (OpenAI, Apr 23), DeepSeek V4 Pro + V4 Flash (preview, April). Claude Opus 4.7 is still the SWE-Bench Pro champion. Kimi K2.6 is the new cost/quality winner at $0.60/$4.00 (ties GPT-5.5 on SWE-Bench Pro, 10× cheaper). DeepSeek V4 Flash at $0.14/$0.28 with 1M context is the new baseline workhorse. This is a reference, not an essay — use the tables, skip the prose. ## The one table that matters [...] ### Related reading GPT-5.5 vs Claude Opus 4.7 for Coding DeepSeek V4 Pro vs V4…
- [5] Kimi K2.6 vs Claude Opus 4.6 vs GPT-5.4: Agentic Coding Benchmarks (2026) - Verdent Guidesverdent.ai
Yes. K2.6 weights are on Hugging Face and run on vLLM, SGLang, or KTransformers. Minimum viable hardware is 4× H100 for the INT4 variant at reduced context. Claude and GPT-5.4 are API-only — there is no self-hosted path. If data sovereignty is a requirement, K2.6 is the only option among these three. ### How stale are these numbers likely to get? Quickly. Anthropic released Opus 4.7 on April 16, 2026, four days before K2.6 launched. Opus 4.7's SWE-Bench Verified is 87.6%, already well ahead of K2.6's 80.2%. OpenAI updates the GPT-5.4 family and the SEAL leaderboard rolls continuously. This ta…
- [6] Kimi K2.6 vs Claude Opus 4.7 (Non-reasoning, High Effort): Model Comparisonartificialanalysis.ai
Highlights ## Model Comparison | Metric | Kimi logoKimi K2.6 | Anthropic logoClaude Opus 4.7 (Non-reasoning, High Effort) | Analysis | --- --- | | Creator | Kimi | Anthropic | | | Context Window | 256k tokens (~384 A4 pages of size 12 Arial font) | 1000k tokens (~1500 A4 pages of size 12 Arial font) | Kimi K2.6 is smaller than Claude Opus 4.7 (Non-reasoning, High Effort) | | Release Date | April, 2026 | April, 2026 | Kimi K2.6 has a more recent release date than Claude Opus 4.7 (Non-reasoning, High Effort) | | Image Input Support | Yes | Yes | Both Kimi K2.6 and Claude Opus 4.7 (Non-reasoning…
- [7] Kimi K2.6 vs DeepSeek V4 vs GPT-5.5 vs Claude Opus 4.7blog.laozhang.ai
As of Apr 24, 2026, this comparison should be built around DeepSeek V4, not an older DeepSeek label. Test Kimi K2.6 first when the job is low-cost coding-agent exploration, test DeepSeek V4 Flash or V4 Pro when you need a cheap callable API route today, use GPT-5.5 inside ChatGPT or Codex while its API contract is still pending, and keep Claude Opus 4.7 first when hidden defects, long context, and review cost matter more than token price. The practical rule is not "pick the model with the loudest launch week." Pick the route whose official contract matches the work, then run the same task bef…
- [8] We Gave Claude Opus 4.7 and Kimi K2.6 the Same Workflow ...blog.kilo.ai
Kilo Blog # We Gave Claude Opus 4.7 and Kimi K2.6 the Same Workflow Orchestration Spec Apr 22, 2026 Kimi K2.6 launched on April 20, 2026, four days after Anthropic released Claude Opus 4.7. We gave both models the same spec for FlowGraph, a persistent workflow orchestration API with DAG validation, atomic worker claims, lease expiry recovery, pause/resume/cancel, and SSE event streaming. Then we reviewed the code and reproduced the edge cases the models’ own tests did not cover. TL;DR: Claude Opus 4.7 scored 91/100 and Kimi K2.6 scored 68/100 on the same build. Kimi K2.6 reached 75% of Clau…
- [9] Bad Opus 4.7, Good Kimi K2.6, and Growing Codexaicodingdaily.substack.com
AI Coding Daily Apr 22, 2026 1 Share Another week in AI Coding world, and the main topic on social media are rants on Anthropic. How bad is Opus 4.7, how ridiculous is the token usage, how they don’t clearly communicate pricing changes, etc. Meanwhile, OpenAI is having a blast with growing Codex, and Chinese models like Kimi are catching up really fast. Also, seems that some companies literally run out of hardware resources for AI compute, like GitHub with Copilot, or maybe same Anthropic. So again, similar to last week, I feel the sayd of cheap subsidized AI usage is going towards the end. A…
- [10] Deep|DeepSeek V4 vs Claude vs GPT-5.4: A 38-Task ... - FundaAIfundaai.substack.com
DeepSeek V4 Flash averages 165s per task — faster than all three Claude Opus models (Opus 4.5: 138s, Opus 4.7: 227s, Opus 4.6: 267s). Pro is slower at 256s — comparable to Opus 4.7. Both models produce dense, token-efficient output: Pro averages ~4,200 output tokens and Flash ~3,800, compared to Claude’s ~7,500-8,800 characters. DeepSeek shows competitive quality per token — the content-to-padding ratio is notably higher, with fewer boilerplate disclaimers and more substantive tables, data points, and analysis per word.On cost, DeepSeek V4 shows a notable advantage in this benchmark. Flash at…
- [11] Gpt-5.5 vs claude opus 4.7 performance comparison - Facebookfacebook.com
Artificial Intelligence LLMs ● Generative AI (Images Video Audio) ● Robots | Claude Opus 4.7 came out… | Facebook Log In Log In Forgot Account? Image 1 Gpt-5.5 vs claude opus 4.7 performance comparison Summarized by AI from the post below ● Robots Noman Hassan · 18h · Claude Opus 4.7 came out… and for a moment, it felt like the race was over. Developers were impressed. It could reason better, write better, and handle complex tasks with less guidance. People started saying, “This is the closest thing to real intelligence we’ve seen.” Then 23 April 2026 happened. OpenAI dropped GPT-5.5. And t…
- [12] GPT-5.5, GPT-Image-2, DeepSeek V4, Kimi K2.6, Qwen 3.6, Gemma 4, Opus 4.7, GLM 5.1... No signs of AI progress slowing down in April. Or are there? Here are my initial impressions. 👉 Like I… | Pasi Vuoriolinkedin.com
👉 DeepSeek v4 was long due and seems to have awesome Opus 4.6 level benchmarks, but for some reason I've already turned my head more to Kimi and GLM. GLM 4.7 from Cerebras and Composer 2 (Kimi K2.5) are still my workhorse in quick tasks, but I'm really tempted to switch to Kimi 2.6. Or wait until Cursor runs their own training materials on it and launches Composer 3. These models give me hope that we are no longer depended on these big AI labs and can run our models locally here at Europe! 👉GPT-Image-2 is of course yet another leap in image generation, but I was already quite much satisfied…
- [13] [AINews] Moonshot Kimi K2.6: the world's leading Open Model ...latent.space
Arena results continued to matter for multimodal models. @arena reported Claude Opus 4.7 taking #1 in Vision & Document Arena, with +4 points over Opus 4.6 in Document Arena and a large margin over the next non-Anthropic models. Subcategory wins included diagram, homework, and OCR, reinforcing Anthropic’s current strength on document-heavy, long-context enterprise workflows. [...] Moonshot’s Kimi K2.6 was the clear release of the day: an open-weight 1T-parameter MoE with 32B active, 384 experts (8 routed + 1 shared), MLA attention, 256K context, native multimodality, and INT4 quantization, wi…
- [14] Claude Opus 4.7 (max) - Intelligence, Performance & Price Analysisartificialanalysis.ai
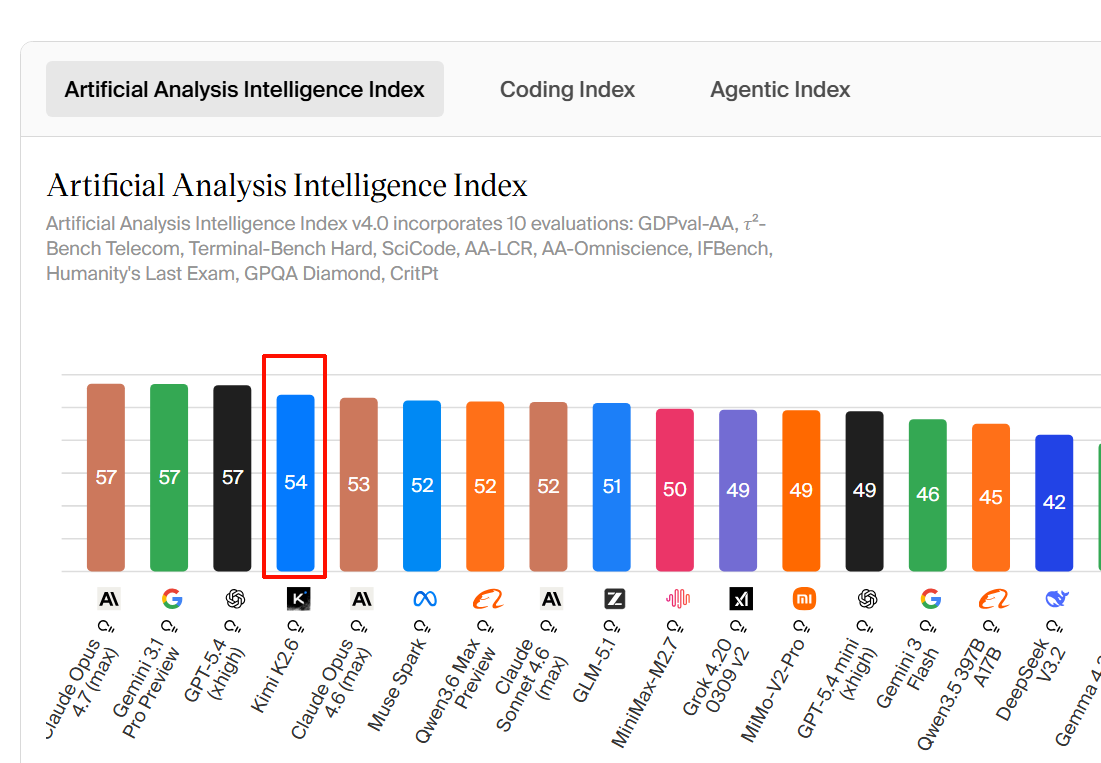
Comparison Summary Claude Opus 4.7 (Adaptive Reasoning, Max Effort) is amongst the leading models in intelligence, but particularly expensive when comparing to other models of similar price. It's also slower than average and very verbose. The model supports text and image input, outputs text, and has a 1m tokens context window with knowledge up to January 2026. Claude Opus 4.7 (Adaptive Reasoning, Max Effort) scores 57 on the Artificial Analysis Intelligence Index, placing it well above average among comparable models (averaging 32). When evaluating the Intelligence Index, it generated 11…
- [15] DeepSeek-V4-Pro-Max: Pricing, Benchmarks & Performancellm-stats.com
#14 of 11 Image 23: LLM Stats Logo Humanity's Last Exam (HLE) is a multi-modal academic benchmark with 2,500 questions across mathematics, humanities, and natural sciences, designed to test LLM capabilities at the frontier of human knowledge with unambiguous, verifiable solutions More 1Image 24Claude Mythos Preview 0.65 2Image 25Muse Spark 0.58 3Image 26GPT-5.5 Pro 0.57 4Image 27Claude Opus 4.7 0.55 5Image 28Claude Opus 4.6 0.53 6Image 29GLM-5.1 0.52 7Image 30GPT-5.5 0.52 8Image 31Gemini 3.1 Pro 0.51 9Image 32Kimi K2-Thinking-0905 0.51 10Image 33Grok-4 Heavy 0.51 ··· 14Image 34DeepSeek-V4-Pro…
- [16] Kimi K2.6 Review: The $0.60 Model That Matches GPT-5.5 on SWE-Bench Pro | CodeRouter Blogcoderouter.io
Benchmark numbers | Benchmark | Kimi K2.6 | GPT-5.5 | Claude Opus 4.7 | GPT-5.4 | DeepSeek V4-Pro | ---:---:---:| | SWE-Bench Pro | 58.6% | 58.6% | 64.3% | 57.7% | ~55% | | HLE (Humanity's Last Exam) w/ tools | 54.0 | — | 53.0\ | 52.1 | — | | AIME 2026 | 96.4% | — | — | 99.2% | — | | GPQA-Diamond | 90.5% | — | — | 92.8% | — | | Input $/M | $0.60 | $5.00 | $15.00 | $2.50 | $1.74 | | Output $/M | $4.00 | $30.00 | $75.00 | $15.00 | $3.48 | | Context | 256K | 1M | 200K | 1.05M | 1M | \Opus 4.6 was the benchmark reference — Opus 4.7 is incrementally higher but not dramatically so on HLE. The he…
- [17] Kimi K2.6 vs Claude Opus 4.6 (Non-reasoning): Model Comparisonartificialanalysis.ai
Which is the best reasoning model? Claude Opus 4.7 (Adaptive Reasoning, Max Effort) leads among 177 reasoning models with an Intelligence Index score of 57. Reasoning models use extended thinking to work through complex problems before providing answers. ### How are AI models compared on Artificial Analysis? Models are compared across multiple dimensions including intelligence (quality), pricing, output speed (tokens per second), latency (time to first token), end-to-end response time, and context window size. Performance metrics are measured directly using standardized prompts across 481…
- [18] Kimi K2.6 vs Claude Opus 4.7 - Detailed Performance & Feature Comparisondocsbot.ai
| SWE-Bench Verified Evaluates software engineering capabilities through verified code modifications and custom agent setups | 80.2% SWE-Bench Verified, thinking mode Source | Not available | | SWE-Bench Pro Evaluates software engineering on multi-language SWE-Bench Pro benchmark of real-world GitHub issues | 58.6% Thinking mode Source | 64.3% Public; reported in OpenAI GPT-5.5 comparison table. Source | | Toolathon Assesses agentic tool-calling performance across multi-step tasks | 50% Thinking mode Source | 48.8% Source | | Visual Acuity (XBOW) Evaluates high-resolution visual understanding…
- [19] Opus 4.7: Everything you need to know - Artificial Analysisartificialanalysis.ai
➤ Context window: 1M tokens (unchanged from Opus 4.6) ➤ Max output tokens: 128K tokens (unchanged from Opus 4.6) ➤ Pricing: $5/$25 per 1M input/output tokens (unchanged from Opus 4.5 and Opus 4.6) ➤ Availability: Claude Opus 4.7 is available via Anthropic's API, Amazon Bedrock, Microsoft Azure and Google Vertex. Also available in Claude App, Claude Code and Claude Cowork Opus 4.7 is the new leader on GDPval-AA, our primary benchmark for general agentic performance on real-world knowledge work tasks. Opus 4.7 scored 1,753 Elo, a 79 Elo lead over the next closest models, Sonnet 4.6 (Adaptive Re…
- [20] OpenAI's GPT-5.5 vs Claude Opus 4.7: Which is better? | Mashablemashable.com
\For Humanity's Last Exam, we're citing Artificial Analysis's verified HLE results"). Notably, Anthropic reports that Opus 4.7 scored 46.9 percent on this test. \See the full results at the Arc Prize website"). ## GPT 5.5 and Opus 4.7: Availability and pricing OpenAI says GPT 5.5 is "our smartest and most intuitive to use model yet." Claude Opus 4.7 is Anthropic's most advanced model available to Claude users, though Anthropic says the unreleased Claude Mythos Preview is the more capable model overall. As such, only paid subscribers can access these frontier models. [...] Thanks for signing…
- [21] Comparison of AI Models across Intelligence, Performance, and Priceartificialanalysis.ai
Comparison of Models: Intelligence, Performance & Price Analysis #### Intelligence Claude Opus 4.7 (max) logo Gemini 3.1 Pro Preview logo GPT-5.4 (xhigh) logo Kimi K2.6 logo #### Output Speed (tokens/s) Mercury 2 logo Granite 4.0 H Small logo Granite 3.3 8B logo Gemini 2.5 Flash-Lite logo #### Latency (seconds) Ministral 3 3B logo Qwen3.5 2B logo Qwen3.5 0.8B logo NVIDIA Nemotron 3 Nano logo #### Price ($ per M tokens) Qwen3.5 0.8B logo Qwen3.5 0.8B logo Gemma 3n E4B logo Qwen3.5 2B logo #### Context Window Llama 4 Scout logo Grok 4.20 0309 v2 logo Grok 4.20 0309 v2 logo Grok 4.1 Fast logo…
- [22] A bunch of model releases this week - Opus 4.7, GPT-5.5. And then there's also the second-tier stuff like Qwen3.6, Kimi K2.6, GLM-5.1, DeepSeek V4. Honestly, we keep obsessing over which frontier… | David Kaplanlinkedin.com
Looking at the months ahead, I think that the economics may start to shift. Right now teams are still throwing money at AI, exploring, willing to spend regardless of what it costs per inference. But I'd image that that's not going to last. Eventually someone's CFO is going to ask why they're paying frontier prices for a problem that a near-frontier model solves just fine. Speed matters too, I feel. Anyone who's actually used Cerebras or Groq knows the magic. In an agentic loop, if I can get 20x faster inference on a model that's slightly less capable, I often get better results just from the…