Was sind die Benchmarks von Claude Opus 4.7?
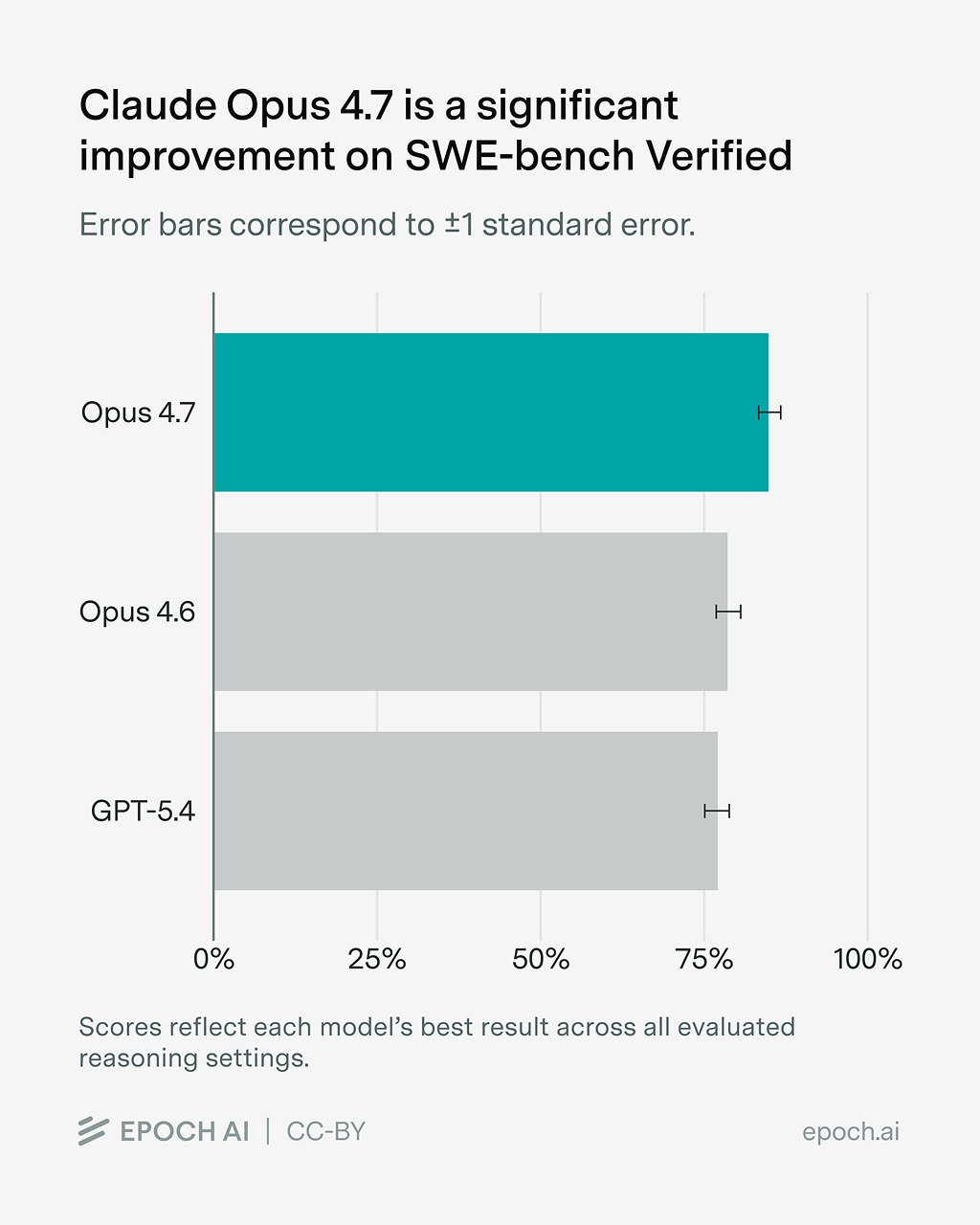
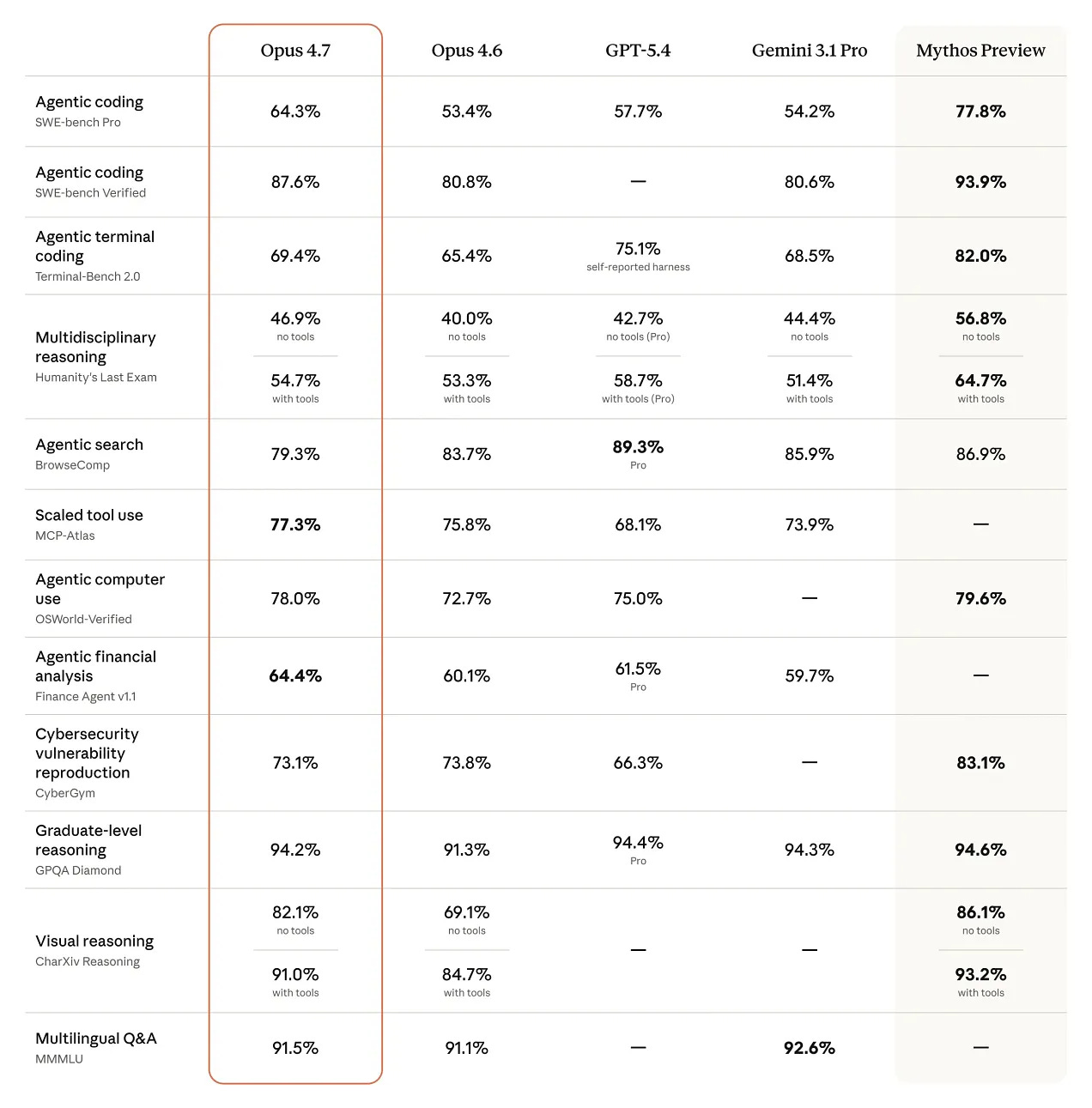
Die öffentlich auffindbaren Benchmark Werte für Claude Opus 4.7 sind nach den gefundenen Quellen vor allem 87,6 % auf SWE bench Verified und 94,2 % auf GPQA. Anthropic beschreibt Opus 4.7 außerdem als sein stärkstes a...
Die öffentlich auffindbaren Benchmark Werte für Claude Opus 4.7 sind nach den gefundenen Quellen vor allem 87,6 % auf SWE bench Verified und 94,2 % auf GPQA. Anthropic beschreibt Opus 4.7 außerdem als sein stärkstes allgemein verfügbares Modell; ein weiterer Treffer nennt 80,5 % auf SWE bench Multilingual. [5][6][1][15
Wichtige Erkenntnisse
- Die öffentlich auffindbaren Benchmark-Werte für Claude Opus 4.7 sind nach den gefundenen Quellen vor allem 87,6 % auf SWE-bench Verified und 94,2 % auf GPQA. Anthropic beschreibt Opus 4.7 außerdem als sein stärkstes allgemein verfügbares Modell; ein weiterer Treffer nennt 80,5 %
- **SWE-bench Verified:** 87,6 % [5][6]
Forschungsantwort
Die öffentlich auffindbaren Benchmark-Werte für Claude Opus 4.7 sind nach den gefundenen Quellen vor allem 87,6 % auf SWE-bench Verified und 94,2 % auf GPQA. Anthropic beschreibt Opus 4.7 außerdem als sein stärkstes allgemein verfügbares Modell; ein weiterer Treffer nennt 80,5 % auf SWE-bench Multilingual. [5][
6][
1][
15]
Wichtig:
- Der Wert für SWE-bench Verified wird in mehreren Treffern konsistent genannt. [
5][
6]
- GPQA 94,2 % habe ich in den Suchergebnissen nur in einem Benchmark-Zusammenfassungsartikel klar gesehen, nicht direkt im Snippet der offiziellen Anthropic-Seite. [
6]
- Für eine vollständige Benchmark-Tabelle direkt aus der offiziellen Release-Seite liegen mir über die Such-Snippets hinaus hier keine vollständig ausgelesenen Primärdaten vor. Wenn du willst, kann ich dir als Nächstes auch eine Einordnung gegen GPT, Gemini und andere Claude-Modelle machen.
Unterstützende Visuals
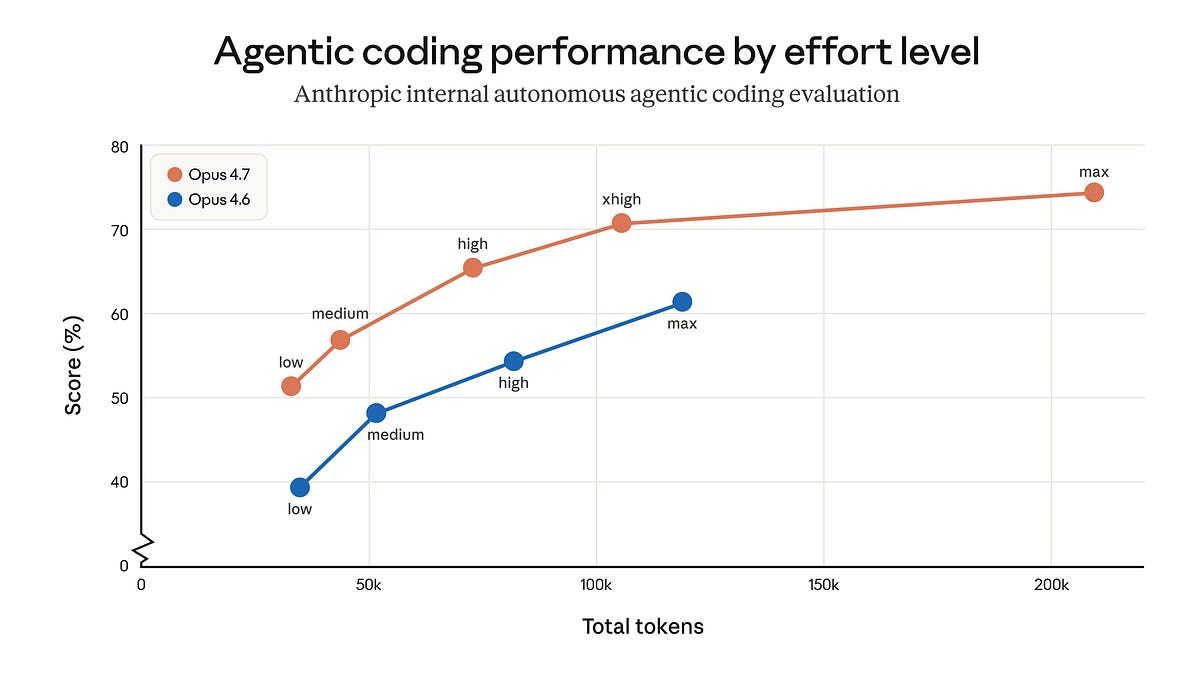
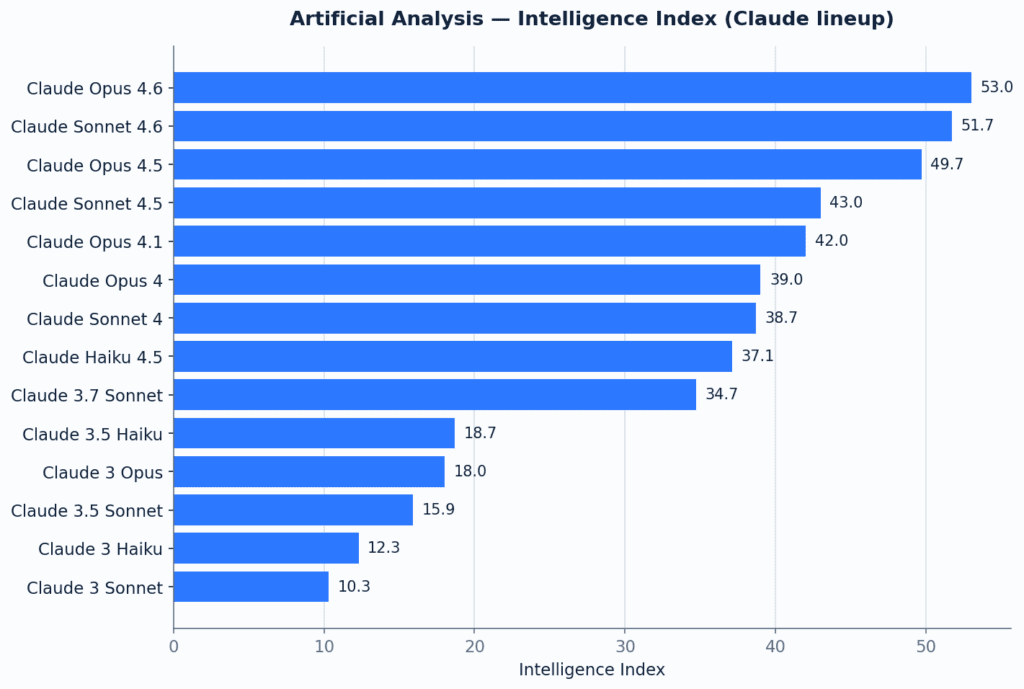
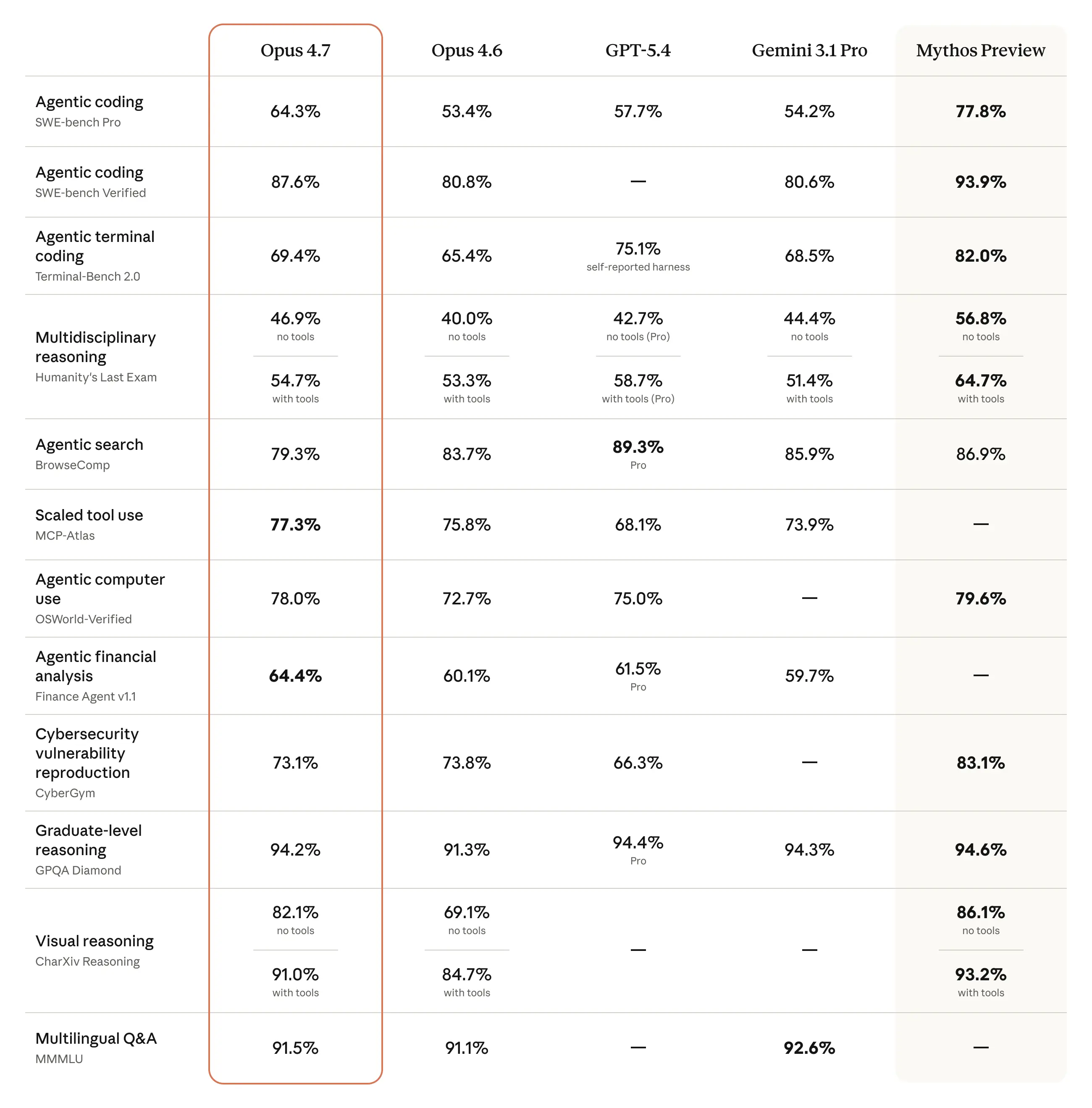


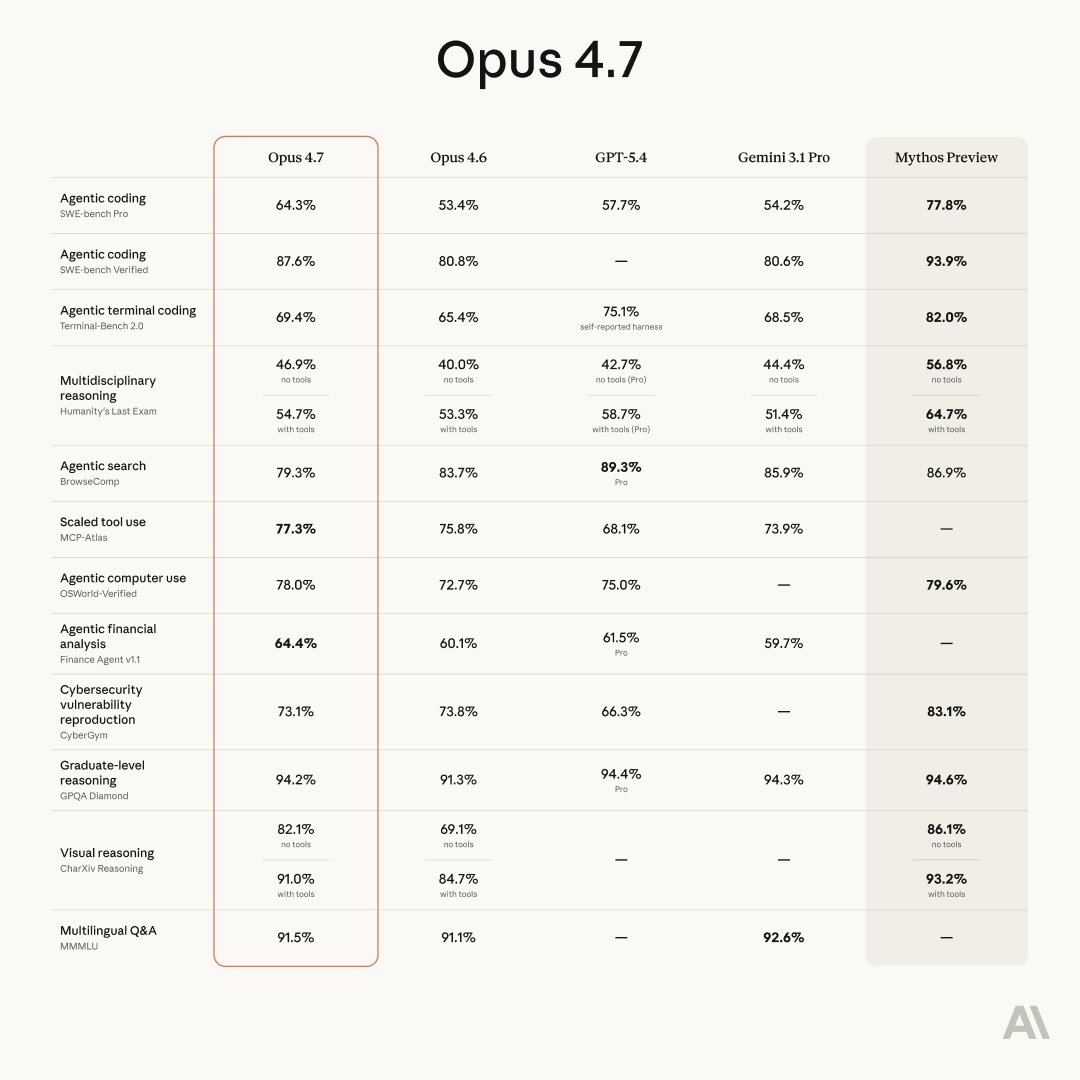


Forschungsgespräch
Forschungsfrage
Was sind die Benchmarks von Claude Opus 4.7?
Zitierte Antwort
Die öffentlich auffindbaren Benchmark-Werte für Claude Opus 4.7 sind nach den gefundenen Quellen vor allem 87,6 % auf SWE-bench Verified und 94,2 % auf GPQA. Anthropic beschreibt Opus 4.7 außerdem als sein stärkstes allgemein verfügbares Modell; ein weiterer Treffer nennt 80,5 % auf SWE-bench Multilingual. [5][
6][
1][
15]
Wichtig:
- Der Wert für SWE-bench Verified wird in mehreren Treffern konsistent genannt. [
5][
6]
- GPQA 94,2 % habe ich in den Suchergebnissen nur in einem Benchmark-Zusammenfassungsartikel klar gesehen, nicht direkt im Snippet der offiziellen Anthropic-Seite. [
6]
- Für eine vollständige Benchmark-Tabelle direkt aus der offiziellen Release-Seite liegen mir über die Such-Snippets hinaus hier keine vollständig ausgelesenen Primärdaten vor. Wenn du willst, kann ich dir als Nächstes auch eine Einordnung gegen GPT, Gemini und andere Claude-Modelle machen.
Die Leute fragen auch
Wie lautet die kurze Antwort auf „Was sind die Benchmarks von Claude Opus 4.7?“?
Die öffentlich auffindbaren Benchmark-Werte für Claude Opus 4.7 sind nach den gefundenen Quellen vor allem 87,6 % auf SWE-bench Verified und 94,2 % auf GPQA. Anthropic beschreibt Opus 4.7 außerdem als sein stärkstes allgemein verfügbares Modell; ein weiterer Treffer nennt 80,5 %
Was sind die wichtigsten Punkte, die zuerst validiert werden müssen?
Die öffentlich auffindbaren Benchmark-Werte für Claude Opus 4.7 sind nach den gefundenen Quellen vor allem 87,6 % auf SWE-bench Verified und 94,2 % auf GPQA. Anthropic beschreibt Opus 4.7 außerdem als sein stärkstes allgemein verfügbares Modell; ein weiterer Treffer nennt 80,5 % **SWE-bench Verified:** 87,6 % [5][6]
Welches verwandte Thema sollte ich als nächstes untersuchen?
Fahren Sie mit „Was sind die Benchmarks von Claude Mythos?“ für einen anderen Blickwinkel und zusätzliche Zitate fort.
Zugehörige Seite öffnenWomit soll ich das vergleichen?
Vergleichen Sie diese Antwort mit „Vergleiche die Benchmarks von DeepSeek V4, Kimi K2.6, Claude Opus 4.7 und GPT-5.5.“.
Zugehörige Seite öffnenSetzen Sie Ihre Recherche fort
Quellen
- [1] Anthropic releases Claude Opus 4.7, narrowly retaking lead for most ...venturebeat.com
Anthropic is publicly releasing its most powerful large language model yet, Claude Opus 4.7, today — as it continues to keep an even more powerful successor, Mythos, restricted to a small number of external enterprise partners for cybersecurity testing and patching vulnerabilities in the software said enterprises use (which Mythos exposed rapid…
- [2] Anthropic's Claude Opus 4.7 Beats GPT-5.4 in Coding Benchmark - iClarifiediclarified.com
Anthropic has launched Claude Opus 4.7, its latest flagship model that brings a notable improvement in advanced software engineering and upgraded high-resolution vision. Coming two months after the release of Claude Sonnet 4.6, the new model builds on that foundation with stronger performance on complex, long-running tasks that previously required closer supervision. For developers on the Mac, the model is well-suited for use with Apple's [Xcode 26.3](https://www.iclarified.com/10…
- [3] Claude Opus 4.7 Benchmarks Explained - Vellumvellum.ai
- Coding capabilities. * SWE-bench Verified. * SWE-bench Pro. * Terminal-Bench 2.0. * Agentic capabilities. * [MCP-Atlas (Scaled tool use)](https://www.vellum.ai/blog/claud…
- [4] Claude Opus 4.7: Benchmarks, Breaking Changes, Migration Guide | Rabinarayan Patrarabinarayanpatra.com
Claude Opus 4.7 ships 87.6% on SWE-bench Verified, a new tokenizer, xhigh effort, and four API breaking changes. create( model="claude-opus-4-7", model = "claude-opus-4-7 ", max_tokens=64000, max_tokens = 64000, output_config={"effort": "xhigh"}, output_config ={" effort ": " xhigh "}, messages=[{"role": "user", "content": "Refactor this service layer."}], messages =[{" role ": " user ", " content ": "Refactor this service layer. create( model="claude-opus-4-7", model = "claude-opus-4-7 ", max_tokens=128000, max_tokens = 128000, output_config={ output_config ={ "effort": "high", " effort ": "…
- [5] Claude Opus 4.7: Benchmarks, Pricing, Context & What's Newllm-stats.com
Claude Opus 4.7: Benchmarks, Pricing, Context & What's New. Claude Opus 4.7 scores 87.6% on SWE-bench Verified, 94.2% on GPQA, 1M token context, 3.3x higher-resolution vision, new xhigh effort level. Claude Opus 4.7 is a direct upgrade to Opus 4.6 at the same price ($5/$25 per million tokens), with 87.6% on SWE-bench Verified (+6.8pp), a new xhigh effort level, 3.3x higher-resolution vision, and self-verification on long-running agentic tasks. It's a direct upgrade to Opus 4.6 at the same price ($5 / $25 per million input / output tokens), with meaningful gains on the hardest software e…
- [6] Claude Opus 4.7: Pricing, Benchmarks & Context Window - ALM Corpalmcorp.com
Claude Opus 4.7 is Anthropic’s latest generally available Opus model, and the release matters for a simple reason: it is not just another benchmark update. Opus 4.7 keeps the same list price as Opus 4.6, adds stronger performance on hard coding and agentic workflows, improves high-resolution vision, introduces a new
xhigheffort level, and uses an updated tokenizer that can increase token counts for the same input. It is positioned as a premium model for advanced coding, long-running agentic tasks, document-heavy reasoning, high-resolution visual understanding, and professional workflows th… - [7] Introducing Claude Opus 4.7 - Anthropicanthropic.com
Skip to main contentSkip to footer.
 . Developers can use
. Developers can use claude-opus-4-7via the Claude API.  . * Extended thinking with tool use (beta): Both models can use tools—like web search—during extended thinking, allowing Clau…
. * Extended thinking with tool use (beta): Both models can use tools—like web search—during extended thinking, allowing Clau… - [15] Introducing Claude Sonnet 4.5 - Anthropicanthropic.com
Skip to main contentSkip to footer.
 . This is the most aligned frontier model we’ve ever released, showing large improvements across several areas of alignment compared to previous Claude models. ![Image 2: Chart showing frontier model performance on SWE-bench Veri…
. This is the most aligned frontier model we’ve ever released, showing large improvements across several areas of alignment compared to previous Claude models. ![Image 2: Chart showing frontier model performance on SWE-bench Veri… - [16] [PDF] Claude Opus 4.5 System Card - Anthropicanthropic.com
It then describes a wide range of safety evaluations: tests of model safeguards, honesty, and agentic safety; a comprehensive alignment assessment including investigations of sycophancy, sabotage capability, evaluation awareness, and many other factors; a model welfare report; and a set of evaluations mandated by our Responsible Scaling Policy. Our capabilities evaluations showed that Claude Opus 4.5 is state-of-the art among frontier models on software coding tasks and “agentic” tasks that require it to run autonomously on a user’s behalf. As outlined in our RSP framework, our standard capab…
- [17] [PDF] Claude Opus 4.6 System Card - Anthropicwww-cdn.anthropic.com
Claude Opus 4.6 is a frontier model with strong capabilities in software engineering, agentic tasks, and long context reasoning, as well as in knowledge work—including fi nancial analysis, document creation, and multi-step research work fl ows. The model shows signi fi cant improvements in long-context reasoning, knowledge work, research, and analysis; it has also increased its capabilities in some areas of agentic coding and tool use (on a few evaluations it performs similarly to, or slightly less well than, its predecessor). The primary purpose of this survey was to inform the Responsible S…
- [18] [PDF] Claude Sonnet 4.6 System Card - Anthropicanthropic.com
On some measures, Sonnet 4.6 showed the best degree of alignment we have yet seen in any Claude model. Informed by the testing described here—and similarly to Claude Sonnet 4.5—we have deployed Claude Sonnet 4.6 under the AI Safety Level 3 (ASL-3) Standard. 3 Abstract 3 1 Introduction 7 1.1 Model training and characteristics 8 1.1.1 Training data and process 8 1.1.2 Thinking modes and the effort parameter 9 1.1.3 Crowd workers 9 1.2 Release decision process 10 1.2.1 Overview 10 1.2.2 Iterative model evaluations 10 1.2.3 AI S…