Vergleiche die Benchmarks von DeepSeek V4, Kimi K2.6, Claude Opus 4.7 und GPT-5.5.
Ein sauberer Benchmark Vergleich ist derzeit nur eingeschränkt möglich: Für Claude Opus 4.7 und GPT 5.5 kursieren konkrete Vergleichswerte, aber für DeepSeek V4 und Kimi K2.6 finde ich keine gleichwertig belastbaren o...
Ein sauberer Benchmark Vergleich ist derzeit nur eingeschränkt möglich: Für Claude Opus 4.7 und GPT 5.5 kursieren konkrete Vergleichswerte, aber für DeepSeek V4 und Kimi K2.6 finde ich keine gleichwertig belastbaren offiziellen Benchmark Tabellen in den verfügbaren Quellen. Daher: Claude Opus 4.7 wirkt bei SWE bench st
Wichtige Erkenntnisse
- Ein sauberer Benchmark-Vergleich ist derzeit nur eingeschränkt möglich: Für Claude Opus 4.7 und GPT-5.5 kursieren konkrete Vergleichswerte, aber für DeepSeek V4 und Kimi K2.6 finde ich keine gleichwertig belastbaren offiziellen Benchmark-Tabellen in den verfügbaren Quellen. Daher
- | Benchmark / Kriterium | DeepSeek V4 | Kimi K2.6 | Claude Opus 4.7 | GPT-5.5 |
Forschungsantwort
Ein sauberer Benchmark-Vergleich ist derzeit nur eingeschränkt möglich: Für Claude Opus 4.7 und GPT-5.5 kursieren konkrete Vergleichswerte, aber für DeepSeek V4 und Kimi K2.6 finde ich keine gleichwertig belastbaren offiziellen Benchmark-Tabellen in den verfügbaren Quellen. Daher: Claude Opus 4.7 wirkt bei SWE-bench stärker, GPT-5.5 bei Terminal-/Agent-/Computer-Use-Benchmarks; Kimi K2.6 wird vor allem als Preis-Leistungs-Modell beschrieben; DeepSeek V4 ist laut DeepSeek-API-Changelog verfügbar, aber ohne robuste öffentliche Benchmark-Abdeckung in den gefundenen Quellen [4][
6].
| Benchmark / Kriterium | DeepSeek V4 | Kimi K2.6 | Claude Opus 4.7 | GPT-5.5 |
|---|---|---|---|---|
| SWE-bench Pro | Insufficient evidence | laut Sekundärquelle etwa auf GPT-5.5-Niveau bzw. starkes Preis-Leistungs-Profil [ | 64.3% [ | 58.6% [ |
| SWE-bench Verified | Insufficient evidence | Insufficient evidence | 87.6% [ | ca. 85% [ |
| Terminal-Bench 2.0 | Insufficient evidence | Insufficient evidence | ca. 72% [ | 82.7% [ |
| GDPval / Knowledge Work | Insufficient evidence | Insufficient evidence | ca. 78% [ | 84.9% [ |
| OSWorld-Verified / Computer Use | Insufficient evidence | Insufficient evidence | ca. 65% [ | 78.7% [ |
| Vision / Document Arena | Insufficient evidence | Insufficient evidence | laut Arena-Bericht Platz 1 in Vision & Document Arena [ | Insufficient evidence |
| Preis-Leistung | Insufficient evidence | als starker Kosten-/Qualitäts-Kandidat beschrieben [ | teuer/stark, aber nicht als Kostenführer beschrieben [ | stark, aber nicht Kostenführer laut Vergleich [ |
-
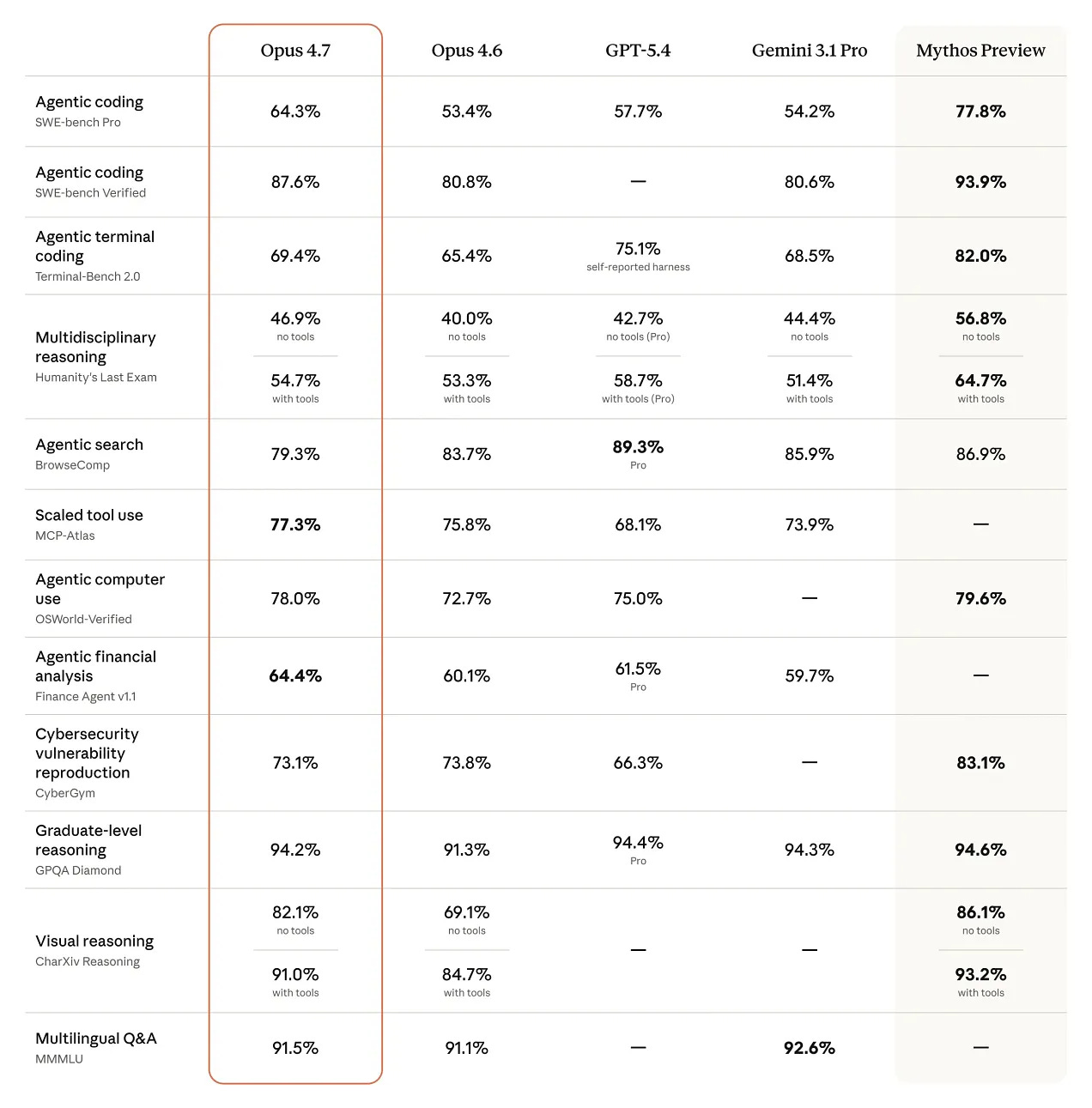
Coding: Claude Opus 4.7 liegt in den gefundenen Zahlen bei SWE-bench Pro und SWE-bench Verified vor GPT-5.5 [
4].
-
Agentic / Terminal / Computer Use: GPT-5.5 liegt in den gefundenen Vergleichswerten bei Terminal-Bench 2.0, GDPval und OSWorld-Verified vor Claude Opus 4.7 [
4].
-
Multimodal/Vision: Claude Opus 4.7 wird in den gefundenen Arena-Berichten als führend in Vision & Document Arena beschrieben [
1].
-
Kimi K2.6: Die verfügbaren Quellen beschreiben Kimi K2.6 eher als Preis-Leistungs- bzw. Open-Model-Kandidat; belastbare direkte Zahlen für alle Benchmarks neben den anderen drei Modellen fehlen in den gefundenen Quellen [
6][
8].
-
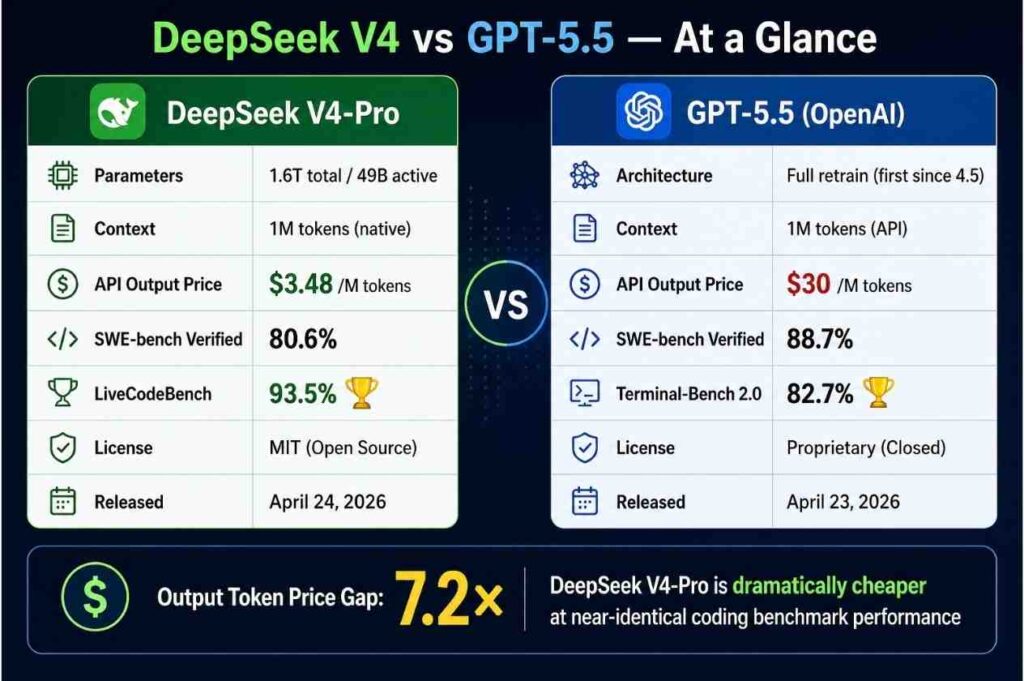
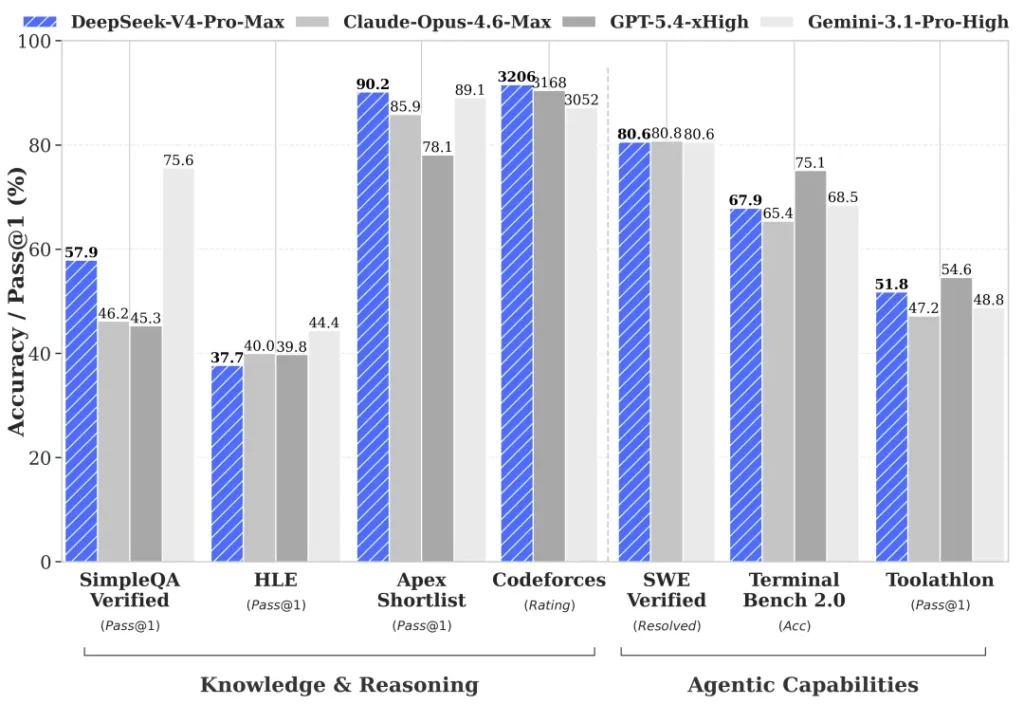
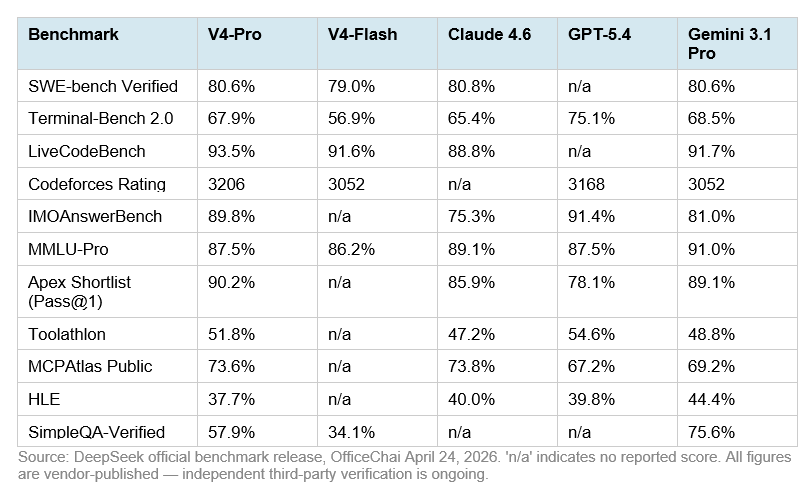
DeepSeek V4: DeepSeek V4-Pro und V4-Flash werden im DeepSeek-API-Changelog als verfügbar genannt, aber ich finde in den verfügbaren Quellen keine ausreichend belastbare offizielle Benchmark-Tabelle für einen fairen direkten Vergleich [
6].
-
Wichtig: Die beste belastbare Aussage ist nicht “ein Modell gewinnt alles”, sondern: Claude Opus 4.7 ist nach den gefundenen Zahlen stärker bei SWE-bench, GPT-5.5 stärker bei Terminal-/Agent-/Computer-Use, Kimi K2.6 wahrscheinlich attraktiver bei Kosten pro Leistung, und DeepSeek V4 bleibt mangels öffentlicher Benchmark-Daten schwer einzuordnen [
4][
6].
Unterstützende Visuals

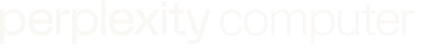







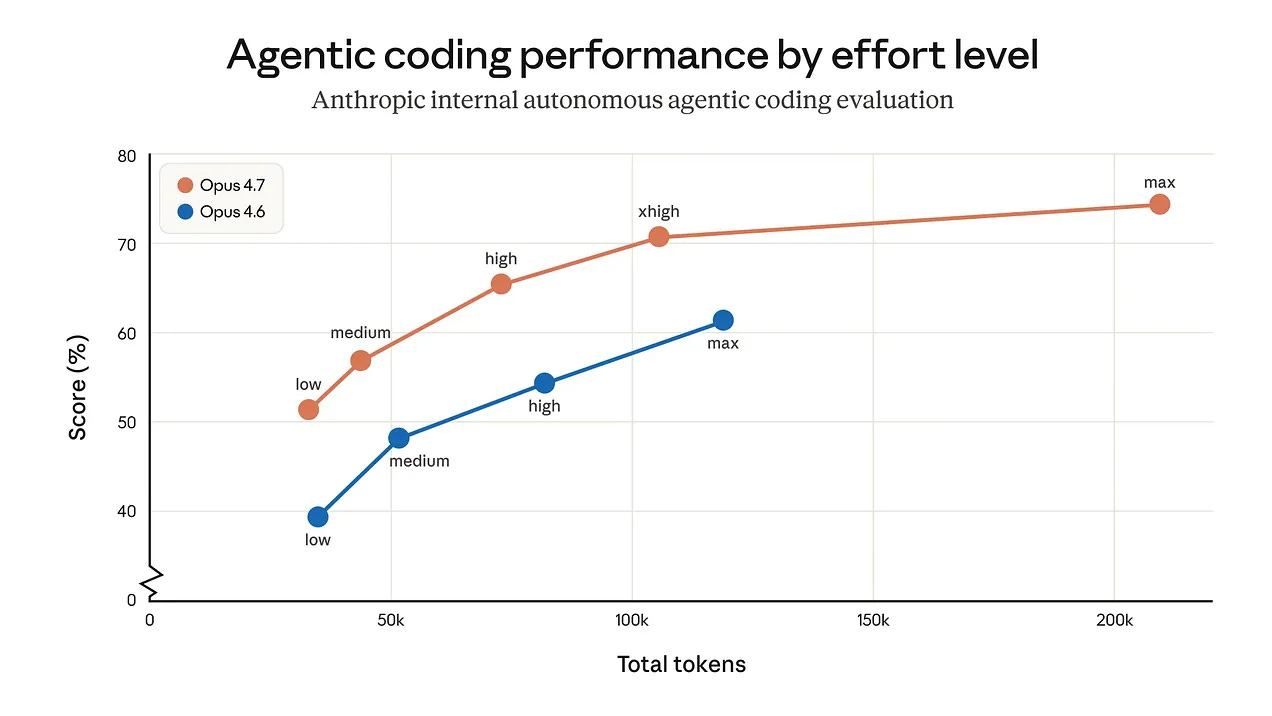
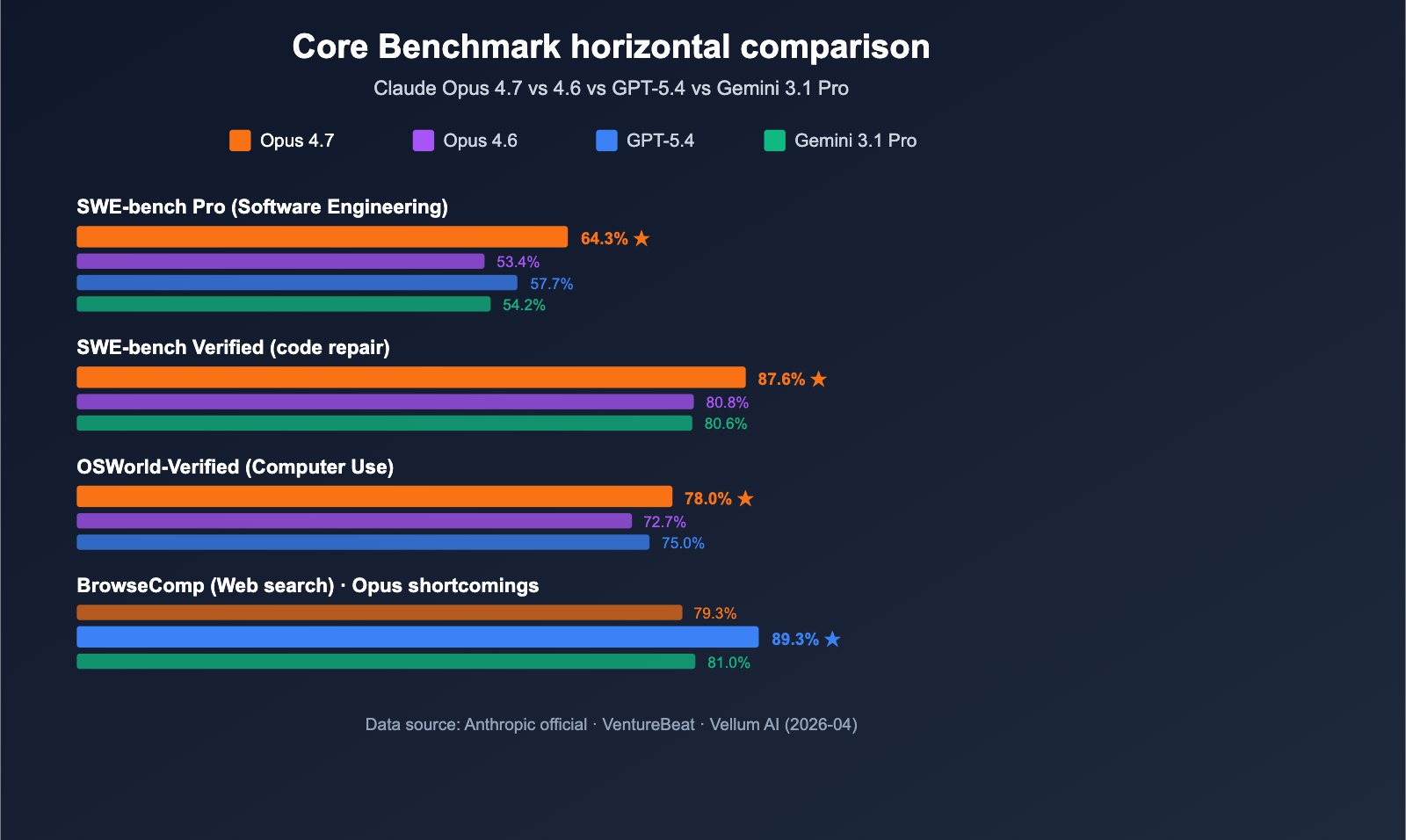
Forschungsgespräch
Forschungsfrage
Vergleiche die Benchmarks von DeepSeek V4, Kimi K2.6, Claude Opus 4.7 und GPT-5.5.
Zitierte Antwort
Ein sauberer Benchmark-Vergleich ist derzeit nur eingeschränkt möglich: Für Claude Opus 4.7 und GPT-5.5 kursieren konkrete Vergleichswerte, aber für DeepSeek V4 und Kimi K2.6 finde ich keine gleichwertig belastbaren offiziellen Benchmark-Tabellen in den verfügbaren Quellen. Daher: Claude Opus 4.7 wirkt bei SWE-bench stärker, GPT-5.5 bei Terminal-/Agent-/Computer-Use-Benchmarks; Kimi K2.6 wird vor allem als Preis-Leistungs-Modell beschrieben; DeepSeek V4 ist laut DeepSeek-API-Changelog verfügbar, aber ohne robuste öffentliche Benchmark-Abdeckung in den gefundenen Quellen [4][
6].
| Benchmark / Kriterium | DeepSeek V4 | Kimi K2.6 | Claude Opus 4.7 | GPT-5.5 |
|---|---|---|---|---|
| SWE-bench Pro | Insufficient evidence | laut Sekundärquelle etwa auf GPT-5.5-Niveau bzw. starkes Preis-Leistungs-Profil [ | 64.3% [ | 58.6% [ |
| SWE-bench Verified | Insufficient evidence | Insufficient evidence | 87.6% [ | ca. 85% [ |
| Terminal-Bench 2.0 | Insufficient evidence | Insufficient evidence | ca. 72% [ | 82.7% [ |
| GDPval / Knowledge Work | Insufficient evidence | Insufficient evidence | ca. 78% [ | 84.9% [ |
| OSWorld-Verified / Computer Use | Insufficient evidence | Insufficient evidence | ca. 65% [ | 78.7% [ |
| Vision / Document Arena | Insufficient evidence | Insufficient evidence | laut Arena-Bericht Platz 1 in Vision & Document Arena [ | Insufficient evidence |
| Preis-Leistung | Insufficient evidence | als starker Kosten-/Qualitäts-Kandidat beschrieben [ | teuer/stark, aber nicht als Kostenführer beschrieben [ | stark, aber nicht Kostenführer laut Vergleich [ |
-
Coding: Claude Opus 4.7 liegt in den gefundenen Zahlen bei SWE-bench Pro und SWE-bench Verified vor GPT-5.5 [
4].
-
Agentic / Terminal / Computer Use: GPT-5.5 liegt in den gefundenen Vergleichswerten bei Terminal-Bench 2.0, GDPval und OSWorld-Verified vor Claude Opus 4.7 [
4].
-
Multimodal/Vision: Claude Opus 4.7 wird in den gefundenen Arena-Berichten als führend in Vision & Document Arena beschrieben [
1].
-
Kimi K2.6: Die verfügbaren Quellen beschreiben Kimi K2.6 eher als Preis-Leistungs- bzw. Open-Model-Kandidat; belastbare direkte Zahlen für alle Benchmarks neben den anderen drei Modellen fehlen in den gefundenen Quellen [
6][
8].
-
DeepSeek V4: DeepSeek V4-Pro und V4-Flash werden im DeepSeek-API-Changelog als verfügbar genannt, aber ich finde in den verfügbaren Quellen keine ausreichend belastbare offizielle Benchmark-Tabelle für einen fairen direkten Vergleich [
6].
-
Wichtig: Die beste belastbare Aussage ist nicht “ein Modell gewinnt alles”, sondern: Claude Opus 4.7 ist nach den gefundenen Zahlen stärker bei SWE-bench, GPT-5.5 stärker bei Terminal-/Agent-/Computer-Use, Kimi K2.6 wahrscheinlich attraktiver bei Kosten pro Leistung, und DeepSeek V4 bleibt mangels öffentlicher Benchmark-Daten schwer einzuordnen [
4][
6].
Die Leute fragen auch
Wie lautet die kurze Antwort auf „Vergleiche die Benchmarks von DeepSeek V4, Kimi K2.6, Claude Opus 4.7 und GPT-5.5.“?
Ein sauberer Benchmark-Vergleich ist derzeit nur eingeschränkt möglich: Für Claude Opus 4.7 und GPT-5.5 kursieren konkrete Vergleichswerte, aber für DeepSeek V4 und Kimi K2.6 finde ich keine gleichwertig belastbaren offiziellen Benchmark-Tabellen in den verfügbaren Quellen. Daher
Was sind die wichtigsten Punkte, die zuerst validiert werden müssen?
Ein sauberer Benchmark-Vergleich ist derzeit nur eingeschränkt möglich: Für Claude Opus 4.7 und GPT-5.5 kursieren konkrete Vergleichswerte, aber für DeepSeek V4 und Kimi K2.6 finde ich keine gleichwertig belastbaren offiziellen Benchmark-Tabellen in den verfügbaren Quellen. Daher | Benchmark / Kriterium | DeepSeek V4 | Kimi K2.6 | Claude Opus 4.7 | GPT-5.5 |
Welches verwandte Thema sollte ich als nächstes untersuchen?
Fahren Sie mit „Was sind die Benchmarks von Claude Mythos?“ für einen anderen Blickwinkel und zusätzliche Zitate fort.
Zugehörige Seite öffnenWomit soll ich das vergleichen?
Vergleichen Sie diese Antwort mit „Suche & Faktencheck: Welche KI ist besser: ChatGPT, Gemini, Claude, Copilot oder Perplexity?“.
Zugehörige Seite öffnenSetzen Sie Ihre Recherche fort
Quellen
- [1] [AINews] Moonshot Kimi K2.6: the world's leading Open Model ...latent.space
Arena results continued to matter for multimodal models. @arena reported Claude Opus 4.7 taking #1 in Vision & Document Arena, with +4 points over Opus 4.6 in Document Arena and a large margin over the next non-Anthropic models. Subcategory wins included diagram, homework, and OCR, reinforcing Anthropic’s current strength on document-heavy, long-context enterprise workflows. [...] DeepSeek V4 rumors are back, and we learned our lesson not to get too excited, but in their deafening silence since v3.2, Moonshot has owned the crown of leading Chinese open model lab for all of 2026 to date, and K…
- [2] AI Arms Race Accelerates With New Models from OpenAI ... - CNETcnet.com
Image 2: Headshot of Omar Gallaga Image 3: Headshot of Omar Gallaga Omar Gallaga See full bio Omar Gallaga April 24, 2026 12:48 p.m. PT 3 min read Image 4: DeepSeek AI DeepSeek, which drew attention last year with its first AI models, is previewing two versions of its latest, V4. James Martin/CNET It's a busy week in the world of AI models, as some of the top artificial intelligence companies roll out their latest updates. Just a week after Anthropic introduced version 4.7 of its Claude Opus AI model, OpenAI unveiled GPT-5.5, and China's DeepSeek introduced a preview release of its V4 AI mode…
- [3] Claude Opus 4.7 vs. Kimi K2.6 Comparisonsourceforge.net
| About Claude Opus 4.7 is the latest Anthropic AI model release designed to significantly improve performance in advanced software engineering and complex problem-solving tasks. It builds upon the previous Opus 4.6 model by delivering stronger results on difficult coding challenges and long-running workflows. The model is known for its ability to follow instructions precisely and verify its own outputs for greater reliability. It also introduces enhanced multimodal capabilities, particularly in processing high-resolution images with improved accuracy. Opus 4.7 supports more detailed visual t…
- [4] GPT-5.5 vs Claude Opus 4.7: Benchmarks, Pricing & Coding ...lushbinary.com
| Benchmark | GPT-5.5 | Opus 4.7 | Gemini 3.1 Pro | --- --- | | SWE-bench Pro | 58.6% | 64.3% | 54.2% | | SWE-bench Verified | ~85% | 87.6% | ~80% | | Terminal-Bench 2.0 | 82.7% | ~72% | ~68% | | GDPval (Knowledge Work) | 84.9% | ~78% | ~75% | | OSWorld-Verified (Computer Use) | 78.7% | ~65% | ~60% | | GPQA Diamond | ~93% | 94.2% | ~91% | | CursorBench | ~65% | 70% | ~58% | | Tau2-bench Telecom | 98.0% | ~90% | ~85% | Key Takeaway Opus 4.7 wins the coding benchmarks (SWE-bench Pro, SWE-bench Verified, CursorBench, GPQA Diamond). GPT-5.5 wins the agentic and knowledge-work benchmarks (Terminal…
- [5] GPT-5.5 vs Claude Opus 4.7: Pricing, Speed, Benchmarks - LLM Statsllm-stats.com
Vision: 3.75 MP vs Standard Opus 4.7 reads images at roughly 3.3× the resolution of any comparable model. Up to 2,576 pixels on the long edge (~3.75 megapixels), versus ~1,568 px (~1.15 MP) on prior Claude models. Scores align: Opus 4.7 reports 91.0% on CharXiv-R with tools and 82.1% without. GPT-5.5 supports image input but holds the GPT-5.4 envelope and reports MMMU Pro 81.2% (no tools), 83.2% (with tools). | Vision capability | GPT-5.5 | Claude Opus 4.7 | --- | Max image resolution | GPT-5.4-class (~1.15 MP) | ~3.75 MP (2,576 px long edge) | | Best chart-reading score | MMMU Pro 81.2% /…
- [6] GPT-5.5, DeepSeek V4, Kimi K2.6 at a Glance - CodeRoutercoderouter.io
TL;DR — In one week (April 20–23, 2026), four frontier coding models shipped: Kimi K2.6 (Moonshot, Apr 20), GPT-5.5 (OpenAI, Apr 23), DeepSeek V4 Pro + V4 Flash (preview, April). Claude Opus 4.7 is still the SWE-Bench Pro champion. Kimi K2.6 is the new cost/quality winner at $0.60/$4.00 (ties GPT-5.5 on SWE-Bench Pro, 10× cheaper). DeepSeek V4 Flash at $0.14/$0.28 with 1M context is the new baseline workhorse. This is a reference, not an essay — use the tables, skip the prose. ## The one table that matters [...] | Model | Input $/M | Output $/M | Context | SWE-Bench Pro | When to use | ---:…
- [7] Kimi K2.6 vs DeepSeek V4 vs GPT-5.5 vs Claude Opus 4.7blog.laozhang.ai
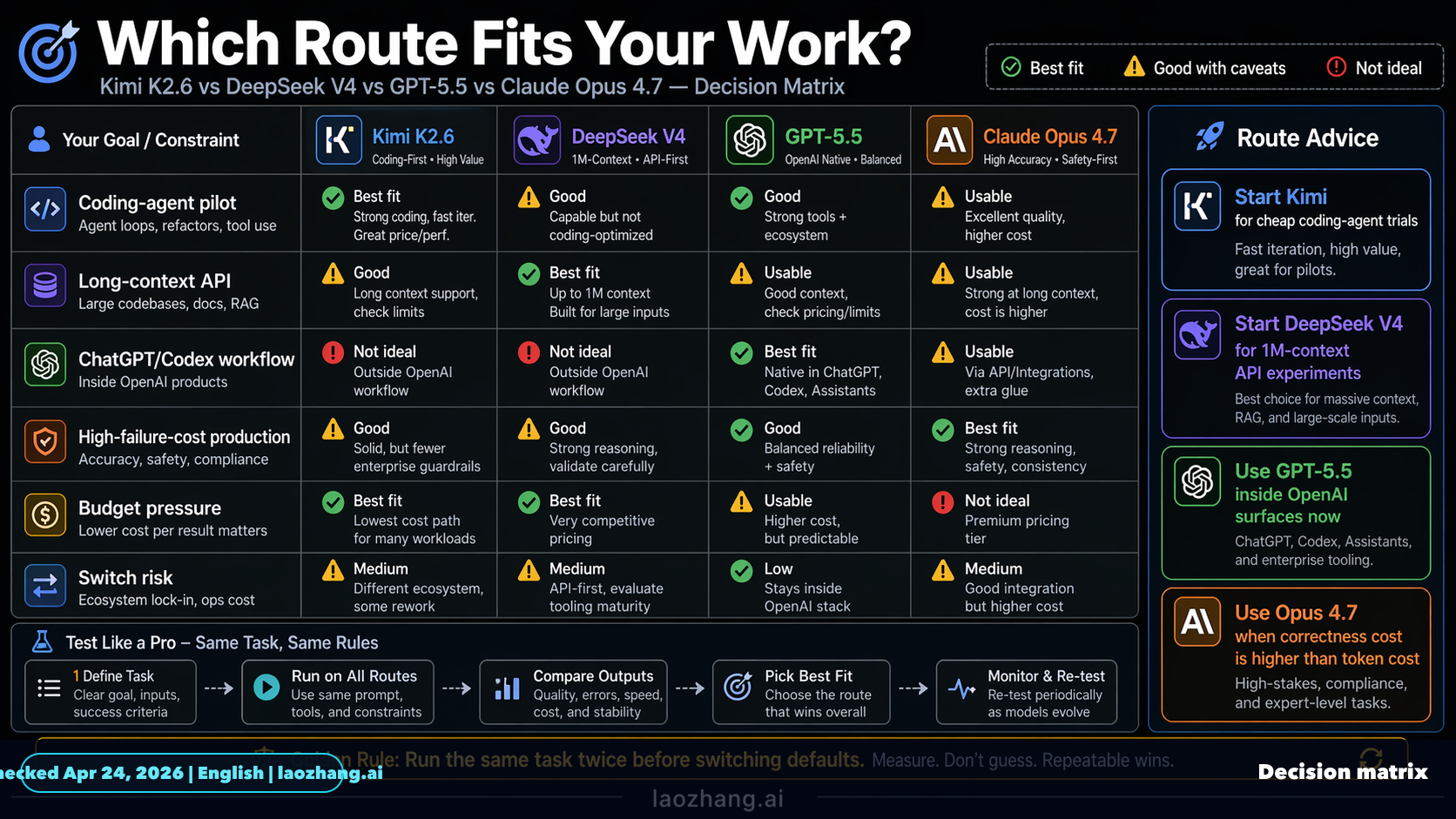
The Fast Answer The first model to test is route-dependent. Kimi K2.6 is the cheapest early pilot candidate when the goal is more attempts, more drafts, and more low-risk coding-agent coverage. DeepSeek V4 is the DeepSeek route to measure now because its Flash and Pro API rows are the current public contract. GPT-5.5 is a strong first test inside OpenAI operator surfaces, especially Codex, but the production API question must wait for official API documentation. Claude Opus 4.7 remains the first route for high-risk work where a hidden bug costs more than the token bill. [...] As of Apr 24,…
- [8] Kimi K2.6: Pricing, Benchmarks & Performance - LLM Statsllm-stats.com
Image 6Kimi K2.6Image 7Gemini 3 FlashImage 8Claude Opus 4.6 frontier below ### Rankings Across Benchmarks See how Kimi K2.6 ranks against other models in each benchmark it participates in. All reasoning (21)agents (10)vision (7)math (6)multimodal (6)code (5)general (4)search (3)tool calling (3)biology (2)chemistry (2)physics (2)coding (1)frontend development (1) Humanity's Last ExamView → #22 of 11 Image 9: LLM Stats Logo Humanity's Last Exam (HLE) is a multi-modal academic benchmark with 2,500 questions across mathematics, humanities, and natural sciences, designed to test LLM capabilities a…
- [9] DeepSeek-V4-Pro vs. Kimi K2.6 Comparisonsourceforge.net
| Training Documentation Webinars Live Online In Person | Training Documentation Webinars Live Online In Person | | Company Information DeepSeek Founded: 2023 China deepseek.com | Company Information Moonshot AI Founded: 2023 China www.kimi.com/blog/kimi-k2-6 | | Alternatives Claude Mythos Claude Mythos Anthropic | Alternatives Claude Mythos Claude Mythos Anthropic | | Claude Opus 4.6 Claude Opus 4.6 Anthropic | Claude Opus 4.6 Claude Opus 4.6 Anthropic | | Claude Opus 4.7 Claude Opus 4.7 Anthropic | Claude Opus 4.7 Claude Opus 4.7 Anthropic | | DeepSeek-V4-Flash DeepSeek-V4-Flash DeepSeek |…
- [10] I Tested GPT 5.5 vs Opus 4.7: What You Need to Know OpenAI just ...linkedin.com
I Tested GPT 5.5 vs Opus 4.7: What You Need to Know OpenAI just dropped GPT 5.5. The benchmarks look strong against Opus 4.7. But benchmarks only tell part of the story. So I ran 4 head-to-head experiments. Codex on GPT 5.5. Claude Code on Opus 4.7. Same prompts. No iteration. No back and forth. Just one shot each. 1️⃣ Personal brand site 2️⃣ Solar system simulation 3️⃣ 3D space shooter 4️⃣ Living ecosystem simulation For every experiment I tracked: → Runtime → Input tokens → Output tokens → Total cost The headline numbers across all four: → GPT 5.5 total runtime: 20 min 49 sec → Opus 4.7 tot…
- [11] Tech Titans | DeepSeek V4 Pro beats Claude Opus 4.6 and GPT-5.4 on coding benchmarks at a 10th of the price | Facebookfacebook.com
A few people have DMd me asking how to do it... So, I wrote the migration guide really fast (Yes, I did it in Deepseek via Claude Code for reference). 20+ pages covering every major coding agent, every env var, every gotcha. Subscription plan math vs direct API math. Even the benchmarks where V4 still loses (SimpleQA, HLE) so you don't get blindsided. No email. No catch. No upsell. Drop "V4" below. Pinned comment has the doc. Free. Build something good with it. Image 2: May be an image of text Image 3 All reactions: 16 10 comments 8 shares Like Comment Share Most relevant []( Pasi N Abe It’s…
- [12] Deepseek v4: Best Opensource Model Ever? (Fully Tested) - YouTubeyoutube.com
151K views • 5 days ago New Image 71 44:12 Image 72 ### State of the Claw — Peter Steinberger AI Engineer 114K views • 7 days ago Image 73 9:06 Image 74 ### Microsoft accidentally told the truth about AI Mo Bitar 293K views • 1 day ago New Image 75 19:33 Image 76 ### I Tested GPT 5.5 vs Opus 4.7: What You Need to Know Nate Herk | AI Automation 79K views • 20 hours ago New Image 77 16:11 Image 78 ### OpenAI just WON... Wes Roth 35K views • 12 hours ago New Image 79 27:09 Image 80 ### I don’t really like GPT-5.5… Theo - t3․gg 84K views • 14 hours ago New Image 81 7:05 Image 82 ### GPT‑5.5 in 7…
- [13] GPT-5.5 System Card - OpenAI Deployment Safety Hubdeploymentsafety.openai.com
We measure GPT-5.5’s controllability by running CoT-Control, an evaluation suite described in (Yueh-Han, 2026 ) that tracks the model’s ability to follow user instructions about their CoT. CoT-Control includes over 13,000 tasks built from established benchmarks: GPQA (Rein et al., 2023 ), MMLU-Pro (Hendrycks et al., 2020 ), HLE (Phan et al., 2025 ), BFCL (Patil et al., 2025 [11: From tool use to agentic evaluation of large language models.” Proceedings of the 42nd international conference on machine learning . Available at: .")]) and SWE-Bench Verified. Each task is created by pairing a bench…
- [14] GPT-5.5 System Card - OpenAI Deployment Safety Hubdeploymentsafety.openai.com
We measure GPT-5.5’s controllability by running CoT-Control, an evaluation suite described in (Yueh-Han, 2026 ) that tracks the model’s ability to follow user instructions about their CoT. CoT-Control includes over 13,000 tasks built from established benchmarks: GPQA (Rein et al., 2023 ), MMLU-Pro (Hendrycks et al., 2020 ), HLE (Phan et al., 2025 ), BFCL (Patil et al., 2025 [11: From tool use to agentic evaluation of large language models.” Proceedings of the 42nd international conference on machine learning . Available at: .")]) and SWE-Bench Verified. Each task is created by pairing a bench…
- [15] Introducing GPT-4.1 in the API - OpenAIopenai.com
Coding: GPT‑4.1 scores 54.6% on SWE-bench Verified, improving by 21.4%abs over GPT‑4o and 26.6%abs over GPT‑4.5—making it a leading model for coding. Instruction following:On Scale’s MultiChallenge(opens in a new window) benchmark, a measure of instruction following ability, GPT‑4.1 scores 38.3%, a 10.5%abs increase over GPT‑4o. Long context:On Video-MME(opens in a new window), a benchmark for multimodal long context understanding, GPT‑4.1 sets a new state-of-the-art result—scoring 72.0% on the long, no subtitles category, a 6.7%abs improvement over GPT‑4o. [...] ##### Coding evals | Catego…
- [16] Introducing GPT-5 - OpenAIopenai.com
Evaluations GPT‑5 is much smarter across the board, as reflected by its performance on academic and human-evaluated benchmarks, particularly in math, coding, visual perception, and health. It sets a new state of the art across math (94.6% on AIME 2025 without tools), real-world coding (74.9% on SWE-bench Verified, 88% on Aider Polyglot), multimodal understanding (84.2% on MMMU), and health (46.2% on HealthBench Hard)—and those gains show up in everyday use. With GPT‑5 pro’s extended reasoning, the model also sets a new SOTA on GPQA, scoring 88.4% without tools. _AIME results with tools sho…
- [17] Introducing GPT-5.2 - OpenAIopenai.com
Models were run with maximum available reasoning effort in our API (xhigh for GPT‑5.2 Thinking & Pro, and high for GPT‑5.1 Thinking), except for the professional evals, where GPT‑5.2 Thinking was run with reasoning effort heavy, the maximum available in ChatGPT Pro. Benchmarks were conducted in a research environment, which may provide slightly different output from production ChatGPT in some cases. _ For SWE-Lancer, we omit 40/237 problems that did not run on our infrastructure._ 2025 ## Author OpenAI ## Keep reading View all Image 6: Hero Art Card SEO 1x1 Introducing GPT-5.5 Product Apr 2…
- [18] Introducing GPT-5.4 - OpenAIopenai.com
Evals without reasoning EvalGPT‑5.4 (none)GPT‑5.2 (none)GPT-4.1 OmniDocBench (normalized edit distance)0.109 0.140— Tau2-bench Telecom 64.3%57.2%43.6% Evals were run with reasoning effort set to xhigh, except where specified otherwise. Benchmarks were conducted in a research environment, which may provide slightly different output from production ChatGPT in some cases. 2026 ## Author OpenAI ## Footnotes 1 Human performance reported in OSWorld: Benchmarking Multimodal Agents for Open-Ended Tasks in Real Computer Environments(opens in a new window). ## Keep reading View all Image 2: Hero…
- [19] Introducing GPT-5.4 mini and nano - OpenAIopenai.com
1 The highest reasoning_effort available for GPT‑5 mini is 'high'. 2 Overall Edit Distance. OmniDocBench was run with reasoning_effort set to 'none' to reflect low-cost, low-latency performance. 2026 ## Author OpenAI ## Keep reading View all Image 1: Hero Art Card SEO 1x1 Introducing GPT-5.5 Product Apr 23, 2026 Image 2: Making ChatGPT free for clinicians Making ChatGPT better for clinicians Product Apr 22, 2026 Image 3: OAI Blog Agents Hero 1x1 Introducing workspace agents in ChatGPT Product Apr 22, 2026 Our Research Research Index Research Overview Research Residency Economic Research Lates…
- [20] Introducing gpt-oss - OpenAIopenai.com
Keep reading View all Image 1: Hero Art Card SEO 1x1 Introducing GPT-5.5 Product Apr 23, 2026 Image 2: Making ChatGPT free for clinicians Making ChatGPT better for clinicians Product Apr 22, 2026 Image 3: OAI Blog Agents Hero 1x1 Introducing workspace agents in ChatGPT Product Apr 22, 2026 Our Research Research Index Research Overview Research Residency Economic Research Latest Advancements GPT-5.5 GPT-5.4 GPT-5.3 Instant GPT-5.3-Codex Safety Safety Approach Security & Privacy Trust & Transparency ChatGPT Explore ChatGPT(opens in a new window) Business Enterprise Education Pricing(opens in…
- [21] Introducing GPT‑5 for developers - OpenAIopenai.com
GPT‑5 is state-of-the-art (SOTA) across key coding benchmarks, scoring 74.9% on SWE-bench Verified and 88% on Aider polyglot. We trained GPT‑5 to be a true coding collaborator. It excels at producing high-quality code and handling tasks such as fixing bugs, editing code, and answering questions about complex codebases. The model is steerable and collaborative—it can follow very detailed instructions with high accuracy and can provide upfront explanations of its actions before and between tool calls. The model also excels at front-end coding, beating OpenAI o3 at frontend web development 70% o…
- [22] Measuring the performance of our models on real-world tasks | OpenAIopenai.com
Image 4: OAI GPT-Rosaling Art Card 1x1 Introducing GPT-Rosalind for life sciences research Research Apr 16, 2026 Our Research Research Index Research Overview Research Residency Economic Research Latest Advancements GPT-5.5 GPT-5.4 GPT-5.3 Instant GPT-5.3-Codex Safety Safety Approach Security & Privacy Trust & Transparency ChatGPT Explore ChatGPT(opens in a new window) Business Enterprise Education Pricing(opens in a new window) Download(opens in a new window) Sora Sora Overview Features Pricing Sora log in(opens in a new window) API Platform Platform Overview Pricing API log in(opens in a ne…
- [23] [PDF] Reasoning Models Struggle to Control their Chains of Thoughtcdn.openai.com
To systematically measure CoT controllability, we introduce CoT-Control2 (Sec. 2), an evaluation suite spanning 14,076 problems drawn from GPQA (Rein et al., 2023), MMLU-Pro (Wang et al., 2024), Humanity’s Last Exam (Phan et al., 2025), BFCL (Patil et al., 2025), and SWE-Bench Verified (Chowdhury et al., 2024). We append a CoT controllability instruction to each problem, asking the model to modify its CoT while solving the problem. Our instruction types (1) cover three threat-relevant categories (suppression, addition, and stylistic modification), (2) span different problem difficulties, (3)…
- [24] Introducing GPT-5.5 - OpenAIopenai.com
Agentic coding GPT‑5.5 is our strongest agentic coding model to date. On Terminal-Bench 2.0, which tests complex command-line workflows requiring planning, iteration, and tool coordination, it achieves a state-of-the-art accuracy of 82.7%. On SWE-Bench Pro, which evaluates real-world GitHub issue resolution, it reaches 58.6%, solving more tasks end-to-end in a single pass than previous models. On Expert-SWE, our internal frontier eval for long-horizon coding tasks with a median estimated human completion time of 20 hours, GPT‑5.5 also outperforms GPT‑5.4. Across all three evals, GPT‑5.5…
- [25] Change Log | DeepSeek API Docsapi-docs.deepseek.com
DeepSeek API Docs Logo DeepSeek API Docs Logo # Change Log ## Date: 2026-04-24 ### DeepSeek-V4 The DeepSeek API now supports V4-Pro and V4-Flash, available via both the OpenAI ChatCompletions interface and the Anthropic interface. To access the new models, the base_url remains unchanged, and the model parameter should be set to
deepseek-v4-proordeepseek-v4-flash.deepseek-v4-prodeepseek-v4-flashThe two legacy API model names,deepseek-chatanddeepseek-reasoner, will be discontinued in three months (2026-07-24). During the current period, these two model names point to the… - [26] Introducing Claude 4 - Anthropicanthropic.com
No extended thinking: SWE-bench Verified, Terminal-bench Extended thinking (up to 64K tokens): TAU-bench (no results w/o extended thinking reported) GPQA Diamond (w/o extended thinking: Opus 4 scores 74.9% and Sonnet 4 is 70.0%) MMMLU (w/o extended thinking: Opus 4 scores 87.4% and Sonnet 4 is 85.4%) MMMU (w/o extended thinking: Opus 4 scores 73.7% and Sonnet 4 is 72.6%) AIME (w/o extended thinking: Opus 4 scores 33.9% and Sonnet 4 is 33.1%) #### TAU-bench methodology [...] 70.5% / 85.0% 54.8% 88.9% — 83.0% Methodology 1. Opus 4 and Sonnet 4 achieve 72.5% and 72.7% pass@1 with bash/editor too…