答え公開済み12 ソース
企業AI導入ガイド:PoCを現場実装に変える5ステップとKPI
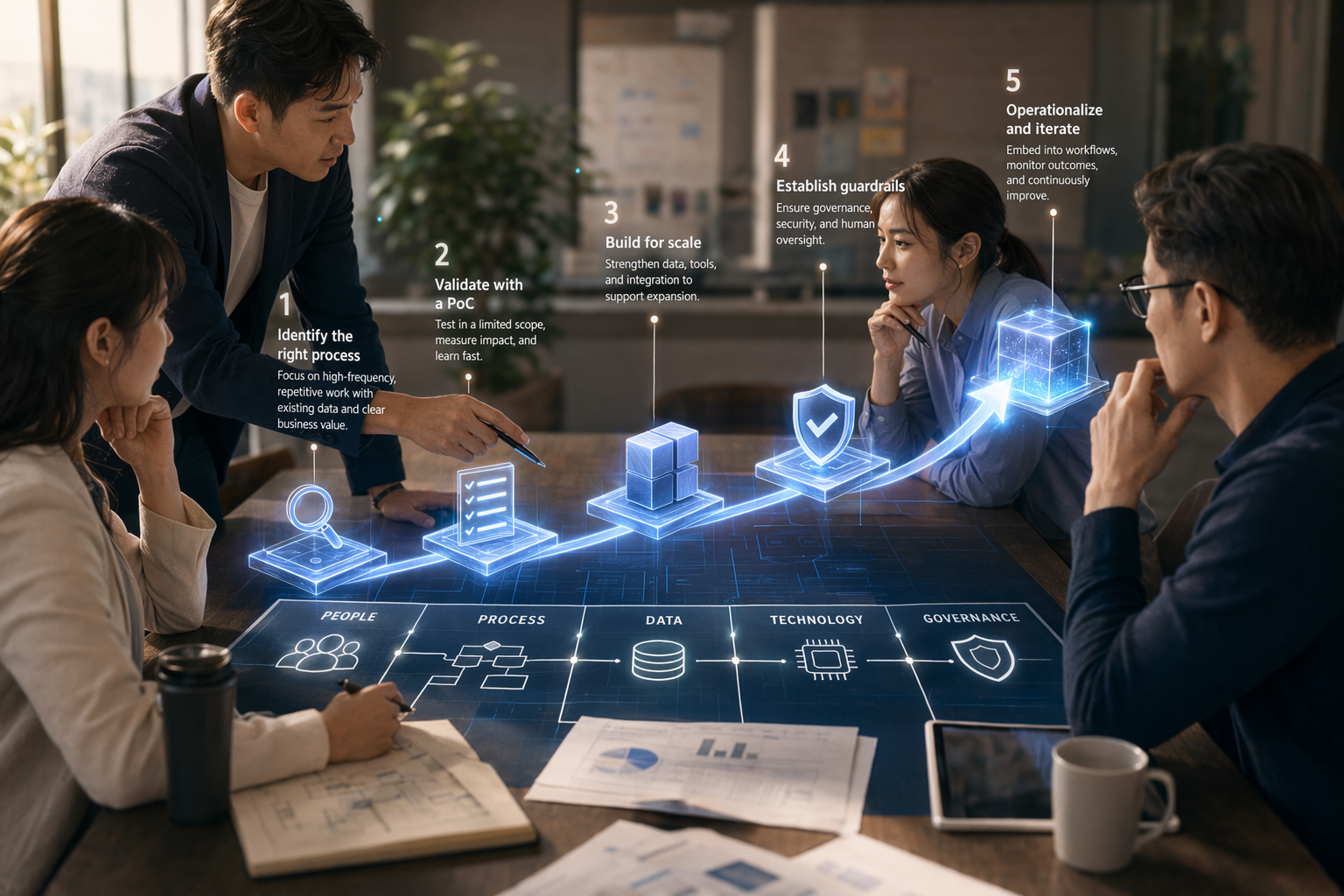
企業AIの成否は、モデルの性能だけでなく、業務プロセス・データ・権限・KPIを実運用に接続できるかで決まる。McKinsey調査を整理した報道では、88%の組織が少なくとも1つの業務機能でAIを使う一方、3分の2近くは実験または初期パイロット段階にとどまるとされている[5]。 実装までの基本手順は、ビジネス課題と責任者の定義、1〜3件のユースケース選定、データと権限の棚卸し、実業務につながるPoC、ガバナンス通過後の段階的拡大。
AI プロンプト
openai.comCreate a landscape editorial hero image for this Studio Global article: 企業 AI 導入指南:5 步把 PoC 變成可落地流程. Article summary: 企業導入 AI 應從高頻、重複、資料已存在且可人工覆核的流程開始,而不是先買模型;The Consulting Report 整理 McKinsey 調查指出,88% 組織已在至少一個業務功能使用 AI,但近三分之二仍停在實驗或早期 pilot。[5]. Topic tags: ai, enterprise ai, ai adoption, ai governance, agents. Reference image context from search candidates: Reference image 1: visual subject "## 洞察觀點. ## 企業如何導入AI才能見效?多數專案失敗關鍵藏在第一步. 你可能也聽過這樣的故事:公司投入大筆預算導入AI,卻在半年後發現「用不起來」。工具買了、資料也蒐集了,但成果遲遲沒有顯現。這時大家開始懷疑:「是不是AI不適合我們?」. 其實,多數導入失敗的企業問題都不在技術,而在方向一開始就沒對準。AI不是萬能解方,它更像一面鏡子——會放大企業" source context "企業如何導入AI才能見效?多數專案失敗關鍵藏在第一步 | 先行智庫|企業培訓與數位轉型領導品牌" Reference image 2: visual subject "在全面導入前,應先透過概念驗證(POC)進行小範圍測試,例如針對單一部門或流程進行試跑,觀察實際效果與數據回饋。這個階段的重點不是做到完美,而是快速驗證" source context "企業 AI 導入怎麼做?從 0 開始建立完整流程與 4 大盲點一次看 - Growth Strategy—你的成長績效策略部門" Style: premium digital editorial illustration, source-backed re
企業がAIを導入するとき、最初につまずくのは必ずしもモデル性能ではありません。むしろ、AIが正しいデータにアクセスできるか、出力が既存の業務システムに戻るか、誰がKPIに責任を持つか、権限・法務・セキュリティをどう管理するかが成否を分けます。
McKinseyの調査を整理した報道によると、88%の組織が少なくとも1つの業務機能でAIを使っている一方、3分の2近くは実験または初期パイロットの段階にとどまっています。つまり、多くの企業に足りないのはAIを試す意欲ではなく、PoCを安定した業務能力に変える設計です。
まず選ぶべきはモデルではなく、変える業務
AI導入の出発点は、どのモデルを買うかではなく、どの業務プロセスを作り直す価値があるかです。最初の案件は、会社で一番大きなテーマでなくてもかまいません。むしろ、頻度が高く、データの所在が明確で、成果を測りやすく、失敗時に人が確認できる業務が向いています。
優先候補になりやすい業務には、次の特徴があります。
- 毎日または毎週、同じ種類の作業が繰り返されている。
- 必要なデータが文書管理、CRM(顧客管理)、ERP(基幹業務システム)、チケット管理、データウェアハウス、社内ナレッジベースなどに存在する。
- 現状の痛みが明確である。たとえば検索に時間がかかる、コピー&ペーストが多い、回答品質がばらつく、手戻りが多いなど。
- AIの出力を人が確認、抽出検査、修正でき、必要に応じて人手に戻せる。
- 現場または事業部門のオーナーがいて、業務変更と成果に責任を持てる。
この条件がないままツールを買うと、見栄えのよいデモは作れても、日々使われる仕組みにはなりにくくなります。
PoCから本番運用へ進める5ステップ
1. 要件を測定可能なビジネス課題に書き換える
プロジェクト名を単にAI導入にしてはいけません。より実務的なのは、どの業務で、誰が、何に困っており、AIでどの指標をどこまで改善するのかを明文化することです。
たとえば、次のように書きます。
業務プロセスAにおいて、役割Bの担当者が毎週タスクCに多くの時間を使っている。AIにより指標Dを現在値から目標値まで改善し、業務オーナーEがプロセス変更と効果検証に責任を持つ。
開始前に、少なくとも次の5点を確認します。
- そのAI機能を毎日使うのは誰か。
- AIは既存業務のどの手順に入るのか。
- 現在の基準値は何か。処理時間、エラー率、成約率、問い合わせ件数、工数など。
- 成功KPIは効率、品質、売上、コスト、リスク低減、従業員体験のどれか。
- 業務プロセスを変更する権限を持ち、結果に責任を負う人は誰か。
業務オーナーと基準値がないPoCは、成功か失敗かを判断しにくく、拡大の稟議や投資判断にもつながりません。
2. 高頻度・反復型・データありのユースケースを1〜3件選ぶ
最初から全社横断で始める必要はありません。むしろ、頻度が高く、作業パターンが似ていて、データソースが明確で、失敗時の影響を管理できる業務から始める方が現実的です。
| 候補ユースケース | 初期導入に向く理由 | 最初に見るKPI例 |
|---|---|---|
| カスタマーサポートのナレッジ検索 | FAQ、製品資料、過去チケット、社内ナレッジを参照しやすい | 平均処理時間、一次解決率、抽出検査での正確率、苦情件数 |
| 社内文書Q&A | 社員が規程、手順、製品情報、技術資料を探す時間を減らせる | 検索時間、担当部署への転送回数、回答採用率 |
| レポート・会議メモの要約 | 入力形式が比較的固定され、繰り返し発生する | 作成時間、要約の採用率、修正回数 |
| 契約書・帳票の項目抽出 | 抽出項目が明確で、人による確認プロセスを設計しやすい |
Studio Global AI
Search, cite, and publish your own answer
Use this topic as a starting point for a fresh source-backed answer, then compare citations before you share it.
人々も尋ねます
「企業AI導入ガイド:PoCを現場実装に変える5ステップとKPI」の短い答えは何ですか?
企業AIの成否は、モデルの性能だけでなく、業務プロセス・データ・権限・KPIを実運用に接続できるかで決まる。McKinsey調査を整理した報道では、88%の組織が少なくとも1つの業務機能でAIを使う一方、3分の2近くは実験または初期パイロット段階にとどまるとされている[5]。
最初に検証する重要なポイントは何ですか?
企業AIの成否は、モデルの性能だけでなく、業務プロセス・データ・権限・KPIを実運用に接続できるかで決まる。McKinsey調査を整理した報道では、88%の組織が少なくとも1つの業務機能でAIを使う一方、3分の2近くは実験または初期パイロット段階にとどまるとされている[5]。 実装までの基本手順は、ビジネス課題と責任者の定義、1〜3件のユースケース選定、データと権限の棚卸し、実業務につながるPoC、ガバナンス通過後の段階的拡大。
次の実践では何をすればいいでしょうか?
AIエージェントは特に慎重に進めたい。McKinseyの2025年調査概要では、どの単一業務機能でもAIエージェントをスケール展開した回答者は10%を超えておらず、別稿ではセキュリティとリスクがagentic AI拡大の最大の障壁とされている[2][8]。
情報源
- theconsultingreport.comMcKinsey Report Reveals Surge in AI Use as Most Firms Struggle to Scale – The Consulting Report
- talyx.aiWhy 90% of Enterprise AI Implementations Fail (2026) - Talyx
- mckinsey.comThe State of AI: Global Survey 2025 - McKinsey
- mckinsey.comState of AI trust in 2026: Shifting to the agentic era - McKinsey
- hakia.comEnterprise AI Adoption Trends 2026: What's Driving the Revolution | Hakia
- aireadi.io