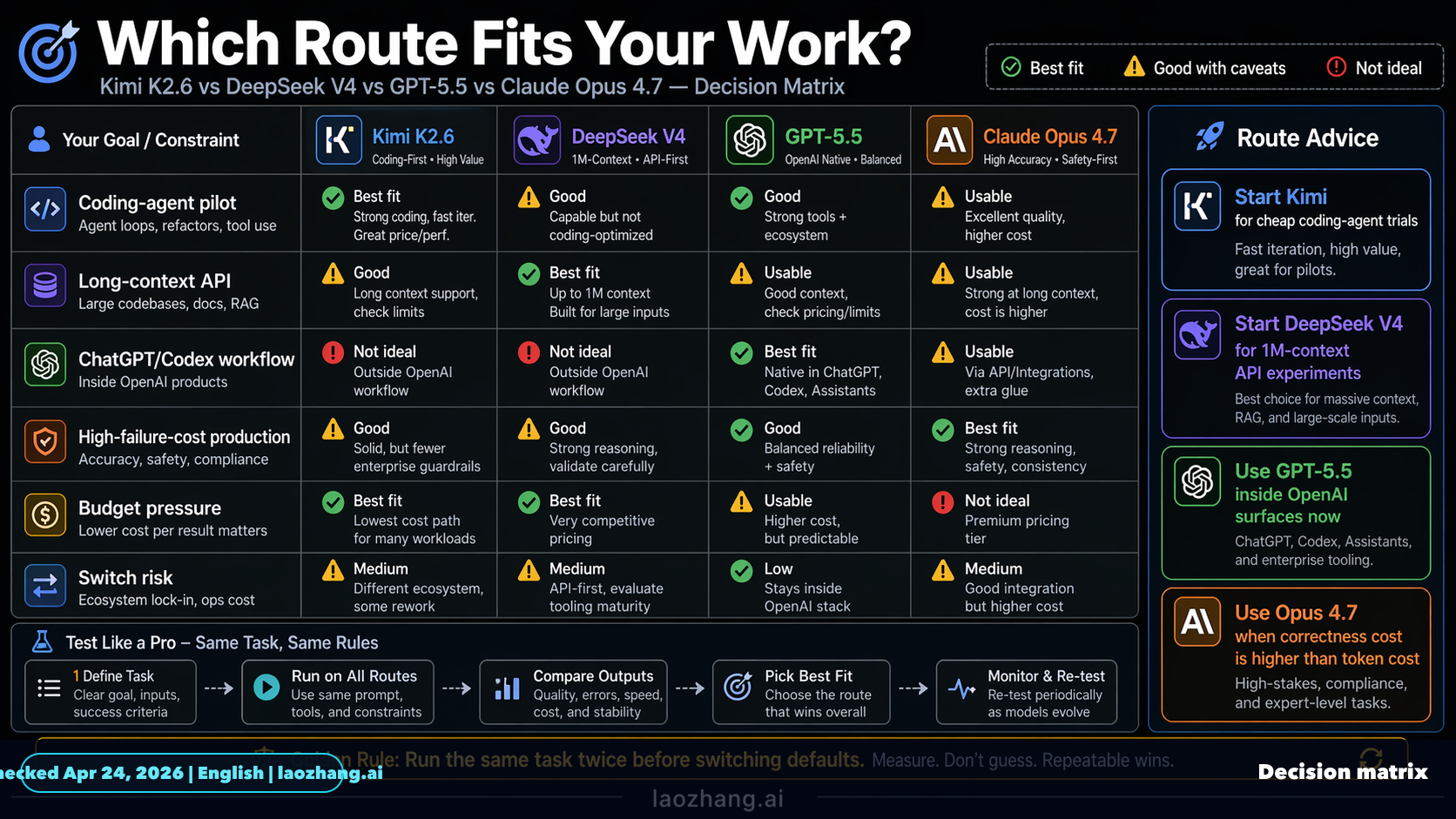
Teliti benchmark Claude Opus 4.7, GPT-5.5, DeepSeek V4, dan Kimi K2.6.
Saya menemukan bukti publik yang cukup untuk membandingkan sebagian benchmark Claude Opus 4.7, GPT 5.5, DeepSeek V4, dan Kimi K2.6, tetapi belum ada satu sumber independen kuat yang menguji keempatnya secara lengkap d...
Saya menemukan bukti publik yang cukup untuk membandingkan sebagian benchmark Claude Opus 4.7, GPT 5.5, DeepSeek V4, dan Kimi K2.6, tetapi belum ada satu sumber independen kuat yang menguji keempatnya secara lengkap dan seragam. Jadi kesimpulan terbaik saat ini: Claude Opus 4.7 dan GPT 5.5 tampak berada di tier frontie
Poin-poin penting
- Saya menemukan bukti publik yang cukup untuk membandingkan sebagian benchmark Claude Opus 4.7, GPT-5.5, DeepSeek V4, dan Kimi K2.6, tetapi belum ada satu sumber independen kuat yang menguji keempatnya secara lengkap dan seragam. Jadi kesimpulan terbaik saat ini: Claude Opus 4.7 d
- ## Temuan utama
Jawaban penelitian
Saya menemukan bukti publik yang cukup untuk membandingkan sebagian benchmark Claude Opus 4.7, GPT-5.5, DeepSeek V4, dan Kimi K2.6, tetapi belum ada satu sumber independen kuat yang menguji keempatnya secara lengkap dan seragam. Jadi kesimpulan terbaik saat ini: Claude Opus 4.7 dan GPT-5.5 tampak berada di tier frontier, DeepSeek V4 kuat di rasio harga/kinerja, sementara Kimi K2.6 terutama sering disebut kompetitif untuk coding/agentic workflow, tetapi buktinya lebih lemah.
Temuan utama
-
Claude Opus 4.7 punya halaman resmi dari Anthropic, jadi keberadaan model ini paling kuat terverifikasi dibanding klaim komunitas lain [
5].
-
Artificial Analysis mencatat Claude Opus 4.7 “Adaptive Reasoning, Max Effort” mendapat skor 57 pada Artificial Analysis Intelligence Index, jauh di atas rata-rata model pembanding yang disebut 33 [
1].
-
Artificial Analysis juga menyediakan perbandingan Claude Opus 4.7 vs DeepSeek V4 Pro berdasarkan intelligence, price, speed, dan context window, tetapi cuplikan hasil pencarian tidak memberikan semua angka benchmark rinci [
3].
-
Untuk GPT-5.5 vs Claude Opus 4.7, LLM Stats melaporkan keduanya saling unggul di 10 benchmark: Opus 4.7 unggul di GPQA, HLE, SWE-Bench Pro, MCP Atlas, dan FinanceAgent v1.1; GPT-5.5 unggul di Terminal-Bench 2.0, BrowseComp, OSWorld, dan CyberGym [
4].
-
LLM Stats juga melaporkan harga GPT-5.5 sebesar $5 input / $30 output per 1 juta token, sedangkan Claude Opus 4.7 sebesar $5 input / $25 output per 1 juta token dengan surcharge 2× untuk long prompt di atas 200K token [
4].
-
Mashable melaporkan DeepSeek V4 Preview sebagai model open-source terbaru DeepSeek, tetapi sumber itu tidak cukup untuk menyimpulkan performa benchmark lengkap terhadap semua model lain [
2].
-
Lushbinary mengklaim DeepSeek V4-Pro jauh lebih murah untuk output, yaitu $3.48 per 1 juta token dibanding $25 untuk Opus 4.7 dan $30 untuk GPT-5.5, tetapi ini perlu dianggap sekunder sampai diverifikasi dari pricing resmi masing-masing vendor [
7].
-
Untuk Kimi K2.6, bukti benchmark yang muncul lebih banyak berasal dari komunitas, Reddit, Substack, YouTube, dan artikel opini; itu tidak sekuat sumber resmi atau benchmark independen terstruktur [
10][
11][
14].
Ringkasan per model
| Model | Kesan benchmark | Kekuatan yang terlihat | Catatan keandalan |
|---|---|---|---|
| Claude Opus 4.7 | Sangat kuat | Reasoning, GPQA/HLE, SWE-Bench Pro menurut LLM Stats | Paling kuat terverifikasi karena ada sumber resmi Anthropic dan Artificial Analysis [ |
| GPT-5.5 | Sangat kuat | Terminal-Bench 2.0, BrowseComp, OSWorld, CyberGym menurut LLM Stats | Data publik ada, tetapi perlu konfirmasi dari benchmark independen lain [ |
| DeepSeek V4 / V4-Pro | Kuat, terutama value | Harga/kinerja dan open-source positioning | Angka performa lengkap terhadap semua model belum cukup kuat dari sumber yang tersedia [ |
| Kimi K2.6 | Menjanjikan untuk coding/agentic | Sering disebut kompetitif di coding workflow | Insufficient evidence untuk ranking final karena sumber kuat masih terbatas [ |
Kesimpulan praktis
-
Jika prioritas Anda adalah kemampuan umum dan reasoning: pilih Claude Opus 4.7 atau GPT-5.5.
-
Jika prioritasnya coding benchmark tertentu: Claude Opus 4.7 terlihat kuat di SWE-Bench Pro, sementara GPT-5.5 terlihat kuat di terminal/browser/OS/cyber task menurut LLM Stats [
4].
-
Jika prioritasnya biaya: DeepSeek V4-Pro tampak paling menarik, tetapi validasi ulang harga dan kualitas output di workload Anda sendiri tetap penting [
7].
-
Jika prioritasnya eksperimen coding agent murah/alternatif: Kimi K2.6 layak diuji, tetapi belum cukup bukti untuk menyebutnya mengalahkan Opus 4.7 atau GPT-5.5 secara umum.
Insufficient evidence untuk membuat ranking absolut 1–4 yang adil, karena benchmark yang tersedia tidak semuanya memakai metodologi, effort setting, harga, context length, dan tool environment yang sama.
Visual pendukung






Percakapan penelitian
Pertanyaan penelitian
Teliti benchmark Claude Opus 4.7, GPT-5.5, DeepSeek V4, dan Kimi K2.6.
Jawaban yang dikutip
Saya menemukan bukti publik yang cukup untuk membandingkan sebagian benchmark Claude Opus 4.7, GPT-5.5, DeepSeek V4, dan Kimi K2.6, tetapi belum ada satu sumber independen kuat yang menguji keempatnya secara lengkap dan seragam. Jadi kesimpulan terbaik saat ini: Claude Opus 4.7 dan GPT-5.5 tampak berada di tier frontier, DeepSeek V4 kuat di rasio harga/kinerja, sementara Kimi K2.6 terutama sering disebut kompetitif untuk coding/agentic workflow, tetapi buktinya lebih lemah.
Temuan utama
-
Claude Opus 4.7 punya halaman resmi dari Anthropic, jadi keberadaan model ini paling kuat terverifikasi dibanding klaim komunitas lain [
5].
-
Artificial Analysis mencatat Claude Opus 4.7 “Adaptive Reasoning, Max Effort” mendapat skor 57 pada Artificial Analysis Intelligence Index, jauh di atas rata-rata model pembanding yang disebut 33 [
1].
-
Artificial Analysis juga menyediakan perbandingan Claude Opus 4.7 vs DeepSeek V4 Pro berdasarkan intelligence, price, speed, dan context window, tetapi cuplikan hasil pencarian tidak memberikan semua angka benchmark rinci [
3].
-
Untuk GPT-5.5 vs Claude Opus 4.7, LLM Stats melaporkan keduanya saling unggul di 10 benchmark: Opus 4.7 unggul di GPQA, HLE, SWE-Bench Pro, MCP Atlas, dan FinanceAgent v1.1; GPT-5.5 unggul di Terminal-Bench 2.0, BrowseComp, OSWorld, dan CyberGym [
4].
-
LLM Stats juga melaporkan harga GPT-5.5 sebesar $5 input / $30 output per 1 juta token, sedangkan Claude Opus 4.7 sebesar $5 input / $25 output per 1 juta token dengan surcharge 2× untuk long prompt di atas 200K token [
4].
-
Mashable melaporkan DeepSeek V4 Preview sebagai model open-source terbaru DeepSeek, tetapi sumber itu tidak cukup untuk menyimpulkan performa benchmark lengkap terhadap semua model lain [
2].
-
Lushbinary mengklaim DeepSeek V4-Pro jauh lebih murah untuk output, yaitu $3.48 per 1 juta token dibanding $25 untuk Opus 4.7 dan $30 untuk GPT-5.5, tetapi ini perlu dianggap sekunder sampai diverifikasi dari pricing resmi masing-masing vendor [
7].
-
Untuk Kimi K2.6, bukti benchmark yang muncul lebih banyak berasal dari komunitas, Reddit, Substack, YouTube, dan artikel opini; itu tidak sekuat sumber resmi atau benchmark independen terstruktur [
10][
11][
14].
Ringkasan per model
| Model | Kesan benchmark | Kekuatan yang terlihat | Catatan keandalan |
|---|---|---|---|
| Claude Opus 4.7 | Sangat kuat | Reasoning, GPQA/HLE, SWE-Bench Pro menurut LLM Stats | Paling kuat terverifikasi karena ada sumber resmi Anthropic dan Artificial Analysis [ |
| GPT-5.5 | Sangat kuat | Terminal-Bench 2.0, BrowseComp, OSWorld, CyberGym menurut LLM Stats | Data publik ada, tetapi perlu konfirmasi dari benchmark independen lain [ |
| DeepSeek V4 / V4-Pro | Kuat, terutama value | Harga/kinerja dan open-source positioning | Angka performa lengkap terhadap semua model belum cukup kuat dari sumber yang tersedia [ |
| Kimi K2.6 | Menjanjikan untuk coding/agentic | Sering disebut kompetitif di coding workflow | Insufficient evidence untuk ranking final karena sumber kuat masih terbatas [ |
Kesimpulan praktis
-
Jika prioritas Anda adalah kemampuan umum dan reasoning: pilih Claude Opus 4.7 atau GPT-5.5.
-
Jika prioritasnya coding benchmark tertentu: Claude Opus 4.7 terlihat kuat di SWE-Bench Pro, sementara GPT-5.5 terlihat kuat di terminal/browser/OS/cyber task menurut LLM Stats [
4].
-
Jika prioritasnya biaya: DeepSeek V4-Pro tampak paling menarik, tetapi validasi ulang harga dan kualitas output di workload Anda sendiri tetap penting [
7].
-
Jika prioritasnya eksperimen coding agent murah/alternatif: Kimi K2.6 layak diuji, tetapi belum cukup bukti untuk menyebutnya mengalahkan Opus 4.7 atau GPT-5.5 secara umum.
Insufficient evidence untuk membuat ranking absolut 1–4 yang adil, karena benchmark yang tersedia tidak semuanya memakai metodologi, effort setting, harga, context length, dan tool environment yang sama.
Orang-orang juga bertanya
Apa jawaban singkat untuk "Teliti benchmark Claude Opus 4.7, GPT-5.5, DeepSeek V4, dan Kimi K2.6."?
Saya menemukan bukti publik yang cukup untuk membandingkan sebagian benchmark Claude Opus 4.7, GPT-5.5, DeepSeek V4, dan Kimi K2.6, tetapi belum ada satu sumber independen kuat yang menguji keempatnya secara lengkap dan seragam. Jadi kesimpulan terbaik saat ini: Claude Opus 4.7 d
Apa poin penting yang harus divalidasi terlebih dahulu?
Saya menemukan bukti publik yang cukup untuk membandingkan sebagian benchmark Claude Opus 4.7, GPT-5.5, DeepSeek V4, dan Kimi K2.6, tetapi belum ada satu sumber independen kuat yang menguji keempatnya secara lengkap dan seragam. Jadi kesimpulan terbaik saat ini: Claude Opus 4.7 d ## Temuan utama
Topik terkait manakah yang harus saya jelajahi selanjutnya?
Lanjutkan dengan "Bandingkan Codex dengan Claude Code." untuk sudut pandang lain dan kutipan tambahan.
Buka halaman terkaitDengan apa saya harus membandingkannya?
Periksa ulang jawaban ini dengan "Bandingkan harga Codex dengan Claude Code.".
Buka halaman terkaitLanjutkan penelitian Anda
Sumber
- [1] DeepSeek V4 is here: How it compares to ChatGPT, Claude, Geminimashable.com
West battle for AI supremacy, Chinese artificial intelligence company DeepSeek has released a preview of its latest model, DeepSeek V4. DeepSeek V4 Preview is a new open-source AI model. Anthropic, OpenAI, xAI, and other U.S. companies fiercely protect their frontier models, whereas DeepSeek is available for anyone to download and modify under an MIT license. Just days before the launch of DeepSeek V4, another Chinese AI company, Moonshot AI, released the [open-source m…
- [2] Introducing Claude Opus 4.7 - Anthropicanthropic.com
Skip to main contentSkip to footer.
 . Developers can use
. Developers can use claude-opus-4-7via the Claude API.  vs Kimi 2.6 - Redditreddit.com
The benchmarks are close enough that real world workflow fit matters more than the numbers. For coding specifically K2.6's strength is long
- [7] I did a 25 minute task in a real codebase with > deepseek v4 pro ...x.com
I did a 25 minute task in a real codebase with > deepseek v4 pro (opencode) > kimi k2.6 (opencode) > opus 4.7 max (Claude code) > gpt 5.5
- [8] A bunch of model releases this week - Opus 4.7, GPT-5.5. And then there's also the second-tier stuff like Qwen3.6, Kimi K2.6, GLM-5.1, DeepSeek V4. Honestly, we keep obsessing over which frontier… | David Kaplanlinkedin.com
A bunch of model releases this week - Opus 4.7, GPT-5.5. And then there's also the second-tier stuff like Qwen3.6, Kimi K2.6, GLM-5.1,
- [9] GPT-5.5 VS Deepseek V4 Pro VS Opus 4.7 - YouTubeyoutube.com
In this video, I'll be comparing GPT 5.5, Deepseek V4, and Opus 4.7 across a series of coding and frontend benchmarks to see which model
- [10] let them battle! Claude Opus 4.7 vs Kimi K2.6 - YouTubeyoutube.com
My curriculum of AI courses: https://edwarddonner.com/curriculum Anthropic just released Claude Opus 4.7, their strongest LLM aside from
- [11] I Tested DeepSeek V4 vs Opus 4.7 vs GPT 5.5 - YouTubeyoutube.com
Master Claude Code, Build Your Agency, Land Your First Client⚡ https://www.skool.com/chase-ai FREE community with the prompts
- [12] Claude Opus 4.7 (max) - Intelligence, Performance & Price Analysisartificialanalysis.ai
Claude Opus 4.7 (Adaptive Reasoning, Max Effort) scores 57 on the Artificial Analysis Intelligence Index, placing it well above average among comparable models (averaging 33). Claude Opus 4.7 (Adaptive Reasoning, Max Effort) scores 57 on the Artificial Analysis Intelligence Index, placing it well above average among other reasoning models in a similar price tier (median: 33). Claude Opus 4.7 (Adaptive Reasoning, Max Effort) generates output at 48.6 tokens per second (based on Anthropic's API), which is below average compared to other reasoning models in a similar price tier (median: 61.5 t/s)…
- [13] DeepSeek V4 Pro (Reasoning, High Effort) vs Claude Opus 4.7 (Adaptive Reasoning, Max Effort): Model Comparisonartificialanalysis.ai
Comparison between DeepSeek V4 Pro (Reasoning, High Effort) and Claude Opus 4.7 (Adaptive Reasoning, Max Effort) across intelligence, price, speed, context window and more. The cost to run the evaluations in the Artificial Analysis Intelligence Index, calculated using the model's input and output token pricing and the number of tokens used across evaluations (excluding repeats). Seconds to output 500 Tokens, calculated based on time to first token, 'thinking' time for reasoning models, and output speed. GPT-5.5 (xhigh) currently leads the Artificial Analysis Intelligence Index with a score of…
- [14] GPT-5.5 vs Claude Opus 4.7: Pricing, Speed, Benchmarks - LLM Statsllm-stats.com
GPT-5.5 ($5/$30 per 1M) and Claude Opus 4.7 ($5/$25 per 1M, with a 2× long-prompt surcharge above 200K) trade leads across 10 shared benchmarks: Opus 4.7 leads on GPQA, HLE, SWE-Bench Pro, MCP Atlas, and FinanceAgent v1.1; GPT-5.5 leads on Terminal-Bench 2.0, BrowseComp, OSWorld, and CyberGym. Both ship 1M-token context.
 . Within seven days, I had two new frontier models to compare against the workloads I run for LLM Stats:[Clau…
. Within seven days, I had two new frontier models to compare against the workloads I run for LLM Stats:[Clau… - [15] Kimi K2 vs Claude 4 Opus (Reasoning): Model Comparisonartificialanalysis.ai
Comparison between Kimi K2 and Claude 4 Opus (Reasoning) across intelligence, price, speed, context window and more. The cost to run the evaluations in the Artificial Analysis Intelligence Index, calculated using the model's input and output token pricing and the number of tokens used across evaluations (excluding repeats). Seconds to output 500 Tokens, calculated based on time to first token, 'thinking' time for reasoning models, and output speed. GPT-5.5 (xhigh) currently leads the Artificial Analysis Intelligence Index with a score of 60, out of 356 models evaluated. The top AI models by I…
- [16] DeepSeek V4 vs Claude Opus 4.7 vs GPT-5.5: Benchmarks & Pricing | Lushbinarylushbinary.com
We compare DeepSeek V4-Pro, Claude Opus 4.7, and GPT-5.5 across coding, reasoning, agentic tasks, pricing, and licensing to help you build a multi-model strategy. The headline numbers: V4-Pro output costs $3.48/M tokens vs $25/M for Opus 4.7 and $30/M for GPT-5.5. Processing 10M output tokens costs $34.80 with V4-Pro, $250 with Opus 4.7, and $300 with GPT-5.5. A well-designed routing layer that sends 60–70% of traffic to V4-Flash, escalates coding to Opus 4.7, and uses GPT-5.5 for agentic desktop tasks can reduce costs 40–60% compared to a single-model approach while maintaining or improving…
- [17] I reviewed how DeepSeek V4-Pro, Kimi 2.6, Opus 4.6, and Opus 4.7 ...news.ycombinator.com
| | | | --- | | ozgune 1 day ago | parent | context | favorite | on: DeepSeek v4 I reviewed how DeepSeek V4-Pro, Kimi 2.6, Opus 4.6, and Opus 4.7 across the same AI benchmarks. DeepSeek V4-Pro roughly matches it across the board, Kimi K2.6 edges it on agentic/coding benchmarks, and Opus 4.7 surpasses it on nearly everything except web search. reply | | | | | | --- | | bbertelsen 17 hours ago | prev ) I'd be interested to know when that Opus 4.6 baseline is from given their recent recognition of performance issues. reply | | | | | | --- | | ozgune 5 hours ago | parent ) Ack. I took the benchma…
- [18] AI Unraveled: Latest AI News, ChatGPT, Gemini, Claude, DeepSeek ...open.spotify.com
We break down the "Enterprise Battlefield," analyzing how Claude Opus 4.7 dominates coding benchmarks (hitting 64.3% on SWE-bench Pro) and visual acuity , while
- [19] Kimi K2.6 vs. Claude Opus 4.7: The New Coding Model Warpub.towardsai.net
Benchmark chart showing Claude Opus 4.7 leading SWE-Bench Pro at 87.6% vs Kimi. Opus 4.7 reclaims the accuracy crown on verified benchmarks
- [20] Opus 4.7 V/S GPT-5.4 V/S Kimi K2.6 Code - YouTubeyoutube.com
In this video, I'll be comparing Claude Opus 4.7, GPT-5.4, and Kimi K2.6 Code, and breaking down which model is best for backend work,
