Claude Opus 4.7 vs GPT 5.5 introduction From https://www.anthropic.com/news/claude-opus-4-7, https://openai.com/index/introducing-gpt-5-5 Search more information & compare them in code, design, deep research, etc
Based on the evidence provided, Claude Opus 4.7 is much better documented than GPT 5.5, so a fair head to head is not possible. The strongest supported conclusion is that Claude Opus 4.7 looks especially strong for co...
Based on the evidence provided, Claude Opus 4.7 is much better documented than GPT 5.5, so a fair head to head is not possible. The strongest supported conclusion is that Claude Opus 4.7 looks especially strong for coding, tool use, and agentic workflows, while evidence for GPT 5.5 in code, design, and deep research is
Key takeaways
- Based on the evidence provided, Claude Opus 4.7 is much better documented than GPT-5.5, so a fair head-to-head is not possible. The strongest supported conclusion is that Claude Opus 4.7 looks especially strong for coding, tool use, and agentic workflows, while evidence for GPT-5
- ## What the evidence supports about Claude Opus 4.7
Research answer
Based on the evidence provided, Claude Opus 4.7 is much better documented than GPT-5.5, so a fair head-to-head is not possible. The strongest supported conclusion is that Claude Opus 4.7 looks especially strong for coding, tool use, and agentic workflows, while evidence for GPT-5.5 in code, design, and deep research is insufficient. [1][
2][
5][
7]
What the evidence supports about Claude Opus 4.7
- Anthropic publicly released Claude Opus 4.7 as its most powerful generally available model, and one report says it narrowly retook the lead for the most powerful generally available LLM. [
1]
- It is positioned for complex multi-step reasoning, long-running autonomous tasks, and multi-agent coordination. [
2]
- BenchLM lists Claude Opus 4.7 at #2 out of 110 models with an overall score of 97/100 on its provisional leaderboard. [
4]
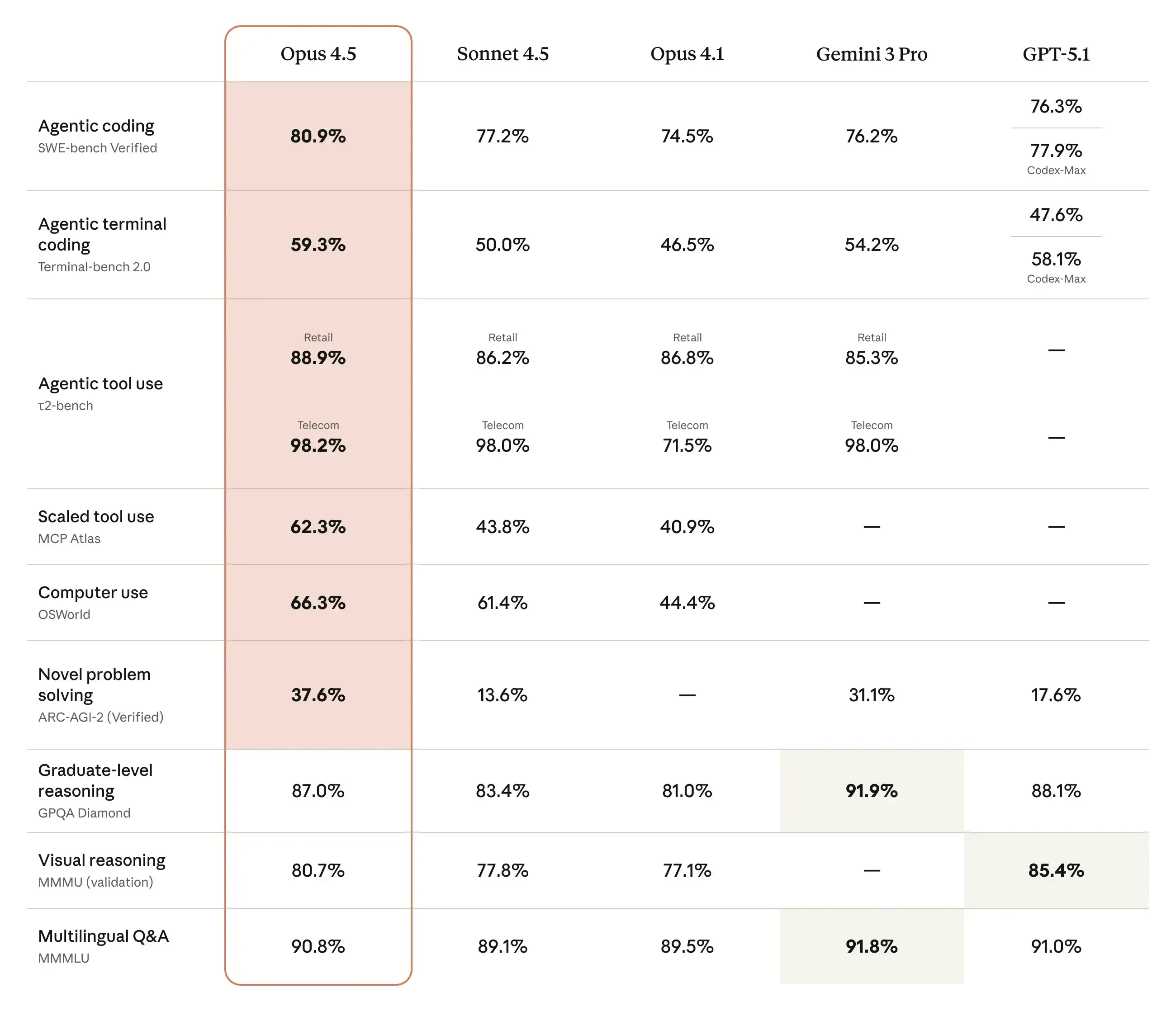
- A secondary benchmark summary reports 87.6% on SWE-bench Verified, 94.2% on GPQA, a 1M-token context window, 3.3x higher-resolution vision, and a new "xhigh" effort level. [
7]
- Another benchmark summary says its tool use is "best-in-class" on MCP-Atlas at 77.3%, ahead of GPT-5.4 at 68.1%, and that it leads GPT-5.4 on SWE-bench Pro at 64.3% versus 57.7%. [
5]
Claude Opus 4.7 vs GPT-5.5
- Code: The available evidence strongly supports Claude Opus 4.7 as a strong coding model, based on SWE-bench Verified and SWE-bench Pro results. [
5][
7]
- Code vs GPT-5.5 specifically: Insufficient evidence. The benchmark comparisons in the provided evidence are against GPT-5.4, not GPT-5.5. [
5]
- Deep research / agentic work: Claude Opus 4.7 is better supported in the evidence for long-running autonomous tasks, multi-step reasoning, and multi-agent coordination, but there is no direct GPT-5.5 comparison here. [
2]
- Design / creative work: Insufficient evidence. The provided sources do not include design-specific benchmarks or product details for either model.
- Overall: Claude Opus 4.7 has the stronger evidence base in this set, but that does not prove it is better than GPT-5.5 overall.
Important limitations
- Most of the concrete data in the provided evidence is about Claude Opus 4.7, not GPT-5.5.
- The only GPT-5.5 item in the evidence list is a Facebook snippet saying OpenAI introduced GPT-5.5 as its latest model, which is too limited and low-authority for a serious comparison. [
23]
- Several performance claims come from secondary summaries and leaderboard sites rather than original benchmark owners, so they should be treated as directional rather than definitive. [
4][
5][
7]
Practical takeaway
- If your priority is coding, tool use, or agentic workflows, the supplied evidence points more clearly to Claude Opus 4.7. [
2][
5][
7]
- If you want a real Claude Opus 4.7 vs GPT-5.5 comparison across code, design, and deep research, I need the actual content from the OpenAI GPT-5.5 announcement or benchmark excerpts, because the current evidence is not enough for a fair match-up.
Supporting visuals














Research conversation
Research question
Claude Opus 4.7 vs GPT 5.5 introduction From https://www.anthropic.com/news/claude-opus-4-7, https://openai.com/index/introducing-gpt-5-5 Search more information & compare them in code, design, deep research, etc
Cited answer
Based on the evidence provided, Claude Opus 4.7 is much better documented than GPT-5.5, so a fair head-to-head is not possible. The strongest supported conclusion is that Claude Opus 4.7 looks especially strong for coding, tool use, and agentic workflows, while evidence for GPT-5.5 in code, design, and deep research is insufficient. [1][
2][
5][
7]
What the evidence supports about Claude Opus 4.7
- Anthropic publicly released Claude Opus 4.7 as its most powerful generally available model, and one report says it narrowly retook the lead for the most powerful generally available LLM. [
1]
- It is positioned for complex multi-step reasoning, long-running autonomous tasks, and multi-agent coordination. [
2]
- BenchLM lists Claude Opus 4.7 at #2 out of 110 models with an overall score of 97/100 on its provisional leaderboard. [
4]
- A secondary benchmark summary reports 87.6% on SWE-bench Verified, 94.2% on GPQA, a 1M-token context window, 3.3x higher-resolution vision, and a new "xhigh" effort level. [
7]
- Another benchmark summary says its tool use is "best-in-class" on MCP-Atlas at 77.3%, ahead of GPT-5.4 at 68.1%, and that it leads GPT-5.4 on SWE-bench Pro at 64.3% versus 57.7%. [
5]
Claude Opus 4.7 vs GPT-5.5
- Code: The available evidence strongly supports Claude Opus 4.7 as a strong coding model, based on SWE-bench Verified and SWE-bench Pro results. [
5][
7]
- Code vs GPT-5.5 specifically: Insufficient evidence. The benchmark comparisons in the provided evidence are against GPT-5.4, not GPT-5.5. [
5]
- Deep research / agentic work: Claude Opus 4.7 is better supported in the evidence for long-running autonomous tasks, multi-step reasoning, and multi-agent coordination, but there is no direct GPT-5.5 comparison here. [
2]
- Design / creative work: Insufficient evidence. The provided sources do not include design-specific benchmarks or product details for either model.
- Overall: Claude Opus 4.7 has the stronger evidence base in this set, but that does not prove it is better than GPT-5.5 overall.
Important limitations
- Most of the concrete data in the provided evidence is about Claude Opus 4.7, not GPT-5.5.
- The only GPT-5.5 item in the evidence list is a Facebook snippet saying OpenAI introduced GPT-5.5 as its latest model, which is too limited and low-authority for a serious comparison. [
23]
- Several performance claims come from secondary summaries and leaderboard sites rather than original benchmark owners, so they should be treated as directional rather than definitive. [
4][
5][
7]
Practical takeaway
- If your priority is coding, tool use, or agentic workflows, the supplied evidence points more clearly to Claude Opus 4.7. [
2][
5][
7]
- If you want a real Claude Opus 4.7 vs GPT-5.5 comparison across code, design, and deep research, I need the actual content from the OpenAI GPT-5.5 announcement or benchmark excerpts, because the current evidence is not enough for a fair match-up.
People also ask
What is the short answer to "Claude Opus 4.7 vs GPT 5.5 introduction From https://www.anthropic.com/news/claude-opus-4-7, https://openai.com/index/introducing-gpt-5-5 Search more information & compare them in code, design, deep research, etc"?
Based on the evidence provided, Claude Opus 4.7 is much better documented than GPT-5.5, so a fair head-to-head is not possible. The strongest supported conclusion is that Claude Opus 4.7 looks especially strong for coding, tool use, and agentic workflows, while evidence for GPT-5
What are the key points to validate first?
Based on the evidence provided, Claude Opus 4.7 is much better documented than GPT-5.5, so a fair head-to-head is not possible. The strongest supported conclusion is that Claude Opus 4.7 looks especially strong for coding, tool use, and agentic workflows, while evidence for GPT-5 ## What the evidence supports about Claude Opus 4.7
Which related topic should I explore next?
Continue with "Search and fact-check: Why is there confusion about Grok 4.3’s actual specs and what has really shipped so far?" for another angle and extra citations.
Open related pageWhat should I compare this against?
Cross-check this answer against "Search and fact-check: Can Grok 4.3 act like a real voice assistant across Grok Voice, Tesla infotainment, and support surfaces?".
Open related pageContinue your research
Sources
- [1] Anthropic releases Claude Opus 4.7, narrowly retaking lead for most ...venturebeat.com
Anthropic is publicly releasing its most powerful large language model yet, Claude Opus 4.7, today — as it continues to keep an even more powerful successor, Mythos, restricted to a small number of external enterprise partners for cybersecurity testing and patching vulnerabilities in the software said enterprises use (which Mythos exposed rapid…
- [2] Claude Opus 4.7 Benchmarks 2026: Scores, Rankings & Performancebenchlm.ai
According to BenchLM.ai, Claude Opus 4.7 ranks #2 out of 110 models on the provisional leaderboard with an overall score of 97/100. ### How does Claude Opus 4.7 perform overall in AI benchmarks? Claude Opus 4.7 currently ranks #2 out of 110 models on BenchLM's provisional leaderboard with an overall score of 97. Claude Opus 4.7 ranks #1 out of 110 models in knowledge and understanding benchmarks with an average score of 99.2. Claude Opus 4.7 ranks #2 out of 110 models in coding and programming benchmarks with an average score of 95.3. Claude Opus 4.7 ranks #2 out of 110 models…
- [3] Claude Opus 4.7 Benchmarks Explained - Vellumvellum.ai
Tool use is best-in-class. Opus 4.7 leads MCP-Atlas at 77.3%, ahead of Opus 4.6 (75.8%), GPT-5.4 (68.1%), and Gemini 3.1 Pro (73.9%). Opus 4.7 leads GPT-5.4 on SWE-bench Verified (87.6% vs no published score), SWE-bench Pro (64.3% vs 57.7%), and MCP-Atlas tool use (77.3% vs 68.1%). Opus 4.7 leads on SWE-bench Pro (64.3% vs 54.2%), SWE-bench Verified (87.6% vs 80.6%), MCP-Atlas (77.3% vs 73.9%), Finance Agent (64.4% vs 59.7%), and Humanity's Last Exam with tools (54.7% vs 51.4%). Opus 4.7 leads among currently available (non-preview) models on: SWE-bench Verified (87.6%), SWE-bench Pro (64…
- [4] Claude Opus 4.7 vs GPT-5: Benchmarks, Features & Best Use Casesiweaver.ai
Claude Opus 4.7 vs GPT-5: Full Comparison, Benchmarks & Which AI Model Is Better in 2026. claude-opus-4-7-vs-gpt-5-comparison. Anthropic officially released Claude Opus 4.7 on April 16, 2026, marking a major upgrade in coding, tool use, and AI safety. ## Claude Opus 4.7 vs GPT-5 — Quick Comparison. | Feature | Claude Opus 4.7 | GPT-5 |. ### 👉 Choose Claude Opus 4.7 if you:. 👉 iWeaver Chat with Claude Opus 4.7 Free. ## How does Claude 4.7 Opus perform against GPT-5.4 benchmarks? | Metric | GPT-5.4 | Claude Opus 4.7 (Beta) |. ## Is Claude Opus 4.7 better for complex coding t…
- [5] AI Model Benchmarks Apr 2026 | Compare GPT-5, Claude 4.5 ...lmcouncil.ai
AI Model Benchmarks Apr 2026 | Compare GPT-5, Claude 4.5, Gemini 2.5, Grok 4 | LM Council. # AI Model Benchmarks Apr 2026. | 3 | GPT-5 Pro | 31.64% ±1.82 |. | 4 | GPT-5.2 | 27.80% ±1.76 |. Try Top 4Full Results. METR's time horizon is the human task duration at which an AI model reaches 50% success. | 2 | GPT-5.2 (high) | 352.2 ±335.5 |. Try Top 4Full Results. | 2 | GPT-5.4 (high) | 76.9% ±1.9 |. Try Top 4Full Results. Try Top 4[Full Results](https:/…
- [6] OpenAI Launches GPT-5.5 to Challenge Anthropic’s Claude Opus 4.7cryptoadventure.com
Rakebit vs Jackbit vs Rainbet vs Flush vs Coins.Game: Which Crypto Casino Has the Best Originals? Altcoins Bitcoin Crypto Market Snapshot Ethereum. Altcoins Bitcoin Crypto Market Snapshot Ethereum. The brands that actually work in this category usually get four things right at the same time: the sportsbook feels like a real product rather than a token add-on, the casino side is deep enough to matter after the match ends, the crypto payment flow is simple, and the site remains comfortable on mobile…. Coins.Game vs Jackbit vs Rakebit vs Flush vs Rainbet: Which Crypto Casino Is Best for Small De…
- [7] ChatGPT vs Claude 2026: Full Comparison [Tested] - Tech Insidertech-insider.org
- Model Capabilities: GPT-5.4 vs Claude Opus 4.6. 5. Coding and Development Performance. 3. What the April 2026 Data Means for Development Teams Choosing an AI Assistant. 6. Real Prompt Test: Same Task, Two AIs — Side by Side Results. 1. Test 1 — Coding: Longest Palindromic Substring. 2. [Test 2 — Writing:…
- [8] GPT-5.5 just raised the bar OpenAI introduced GPT-5.5 as its latest ...facebook.com
Chatgptricks - GPT-5.5 just raised the bar OpenAI... Log In. Forgot Account?. ## Chatgptricks's Post. [](https://www.facebook.com/chatgptricks?__cft__[0]=AZZPM3cU4nNdKgFHcJO9PAzV87S7LaToUrmerMaBxqq_461Kdqem-N7I-VRy1_D8wu8hptiLA9lfWqywmgTScB-8aQb3zZxAg3dEWKYNP4pk-DeWlby7iczUDiaqz2GztOlaoBGRVh…
- [9] GPT 5.5 is out. Here are the benchmarks. - Facebookfacebook.com
My updated stack as of today: Claude Code with Opus 4.7 for building. Skills, templates, workflows, architecture. OpenClaw with GPT-5.4 and
- [10] I Tested GPT 5.5 vs Claude Opus 4.7 - YouTubeyoutube.com
OpenAI just dropped GPT 5.5. They're calling it a new class of intelligence for real work and powering agents. I ran the same prompt I gave
- [11] The 2026 AI Frontier Rivalry: Claude Opus 4.7 vs GPT-5.5 - YouTubeyoutube.com
Discover the ultimate 2026 AI showdown between Anthropic's Claude Opus 4.7 and OpenAI's upcoming GPT-5.5 "Spud" model.
- [12] Claude Opus 4.7overchat.ai
Claude Opus 4.7 is Anthropic's most advanced AI model, purpose-built for complex multi-step reasoning, long-running autonomous tasks, and seamless multi-agent coordination. ### Claude Opus 4.6 is now on Overchat AI — Anthropic's Best Model Sets New Records. Claude Opus 4.7 is the latest flagship AI model from Anthropic, succeeding Opus 4.6 which was released in l 2025. Claude Opus 4.7 is accessible through Overchat AI. Claude Opus 4.7 is Anthropic's most advanced AI model, released in April 2026 as the successor to Opus 4.6. The easiest way to use Claude Opus 4.7 is through Overchat AI. Visit…
- [13] Claude Opus 4.7 - Anthropicanthropic.com
Skip to main contentSkip to footer.
 .
.  . Read more. Read more. Read more. [Rea…
. Read more. Read more. Read more. [Rea… - [14] Claude Opus 4.7: Benchmarks, Pricing, Context & What's Newllm-stats.com
Claude Opus 4.7: Benchmarks, Pricing, Context & What's New. Claude Opus 4.7 scores 87.6% on SWE-bench Verified, 94.2% on GPQA, 1M token context, 3.3x higher-resolution vision, new xhigh effort level. Claude Opus 4.7 is a direct upgrade to Opus 4.6 at the same price ($5/$25 per million tokens), with 87.6% on SWE-bench Verified (+6.8pp), a new xhigh effort level, 3.3x higher-resolution vision, and self-verification on long-running agentic tasks. It's a direct upgrade to Opus 4.6 at the same price ($5 / $25 per million input / output tokens), with meaningful gains on the hardest software e…
- [15] Claude Opus 4.7: Detailed Review of Anthropic's 2026 Modelwebscraft.org
Official Announcement: Introducing Claude Opus 4.7 — Anthropic. Anthropic's main positioning: Opus 4.7 "follows instructions more accurately, verifies its own output before reporting results, and handles long tasks with greater thoroughness." In practice, this means the model is designed for agentic scenarios – where the model operates autonomously without constant supervision. Important context: Alongside Opus 4.7, Anthropic mentions Claude Mythos Preview – their most powerful model, which outperforms Opus 4.7 on all benchmarks. However, on key business benchmarks (SWE-bench, MCP-Atlas),…
- [16] Introducing Claude Opus 4.7 - Anthropicanthropic.com
Skip to main contentSkip to footer.
 . Developers can use
. Developers can use claude-opus-4-7via the Claude API.  by a full 10 points, and Mythos — available only to Project Glasswing consortium members — leads Opus 4.7 by 6-14 points on coding benchmarks. CyberGym is also worth noting: Opus 4.7 scores 73.1% vs GPT 5.4's 66.3% — a 6.8-point lead in cybersecurity tasks, even though Anthropic says they intentionally reduced cyber capabilities. * SWE-bench Verified: Mythos 93.9% vs Opus 4.7's 87.6% — a 6.3-point gap. * **SWE-bench…
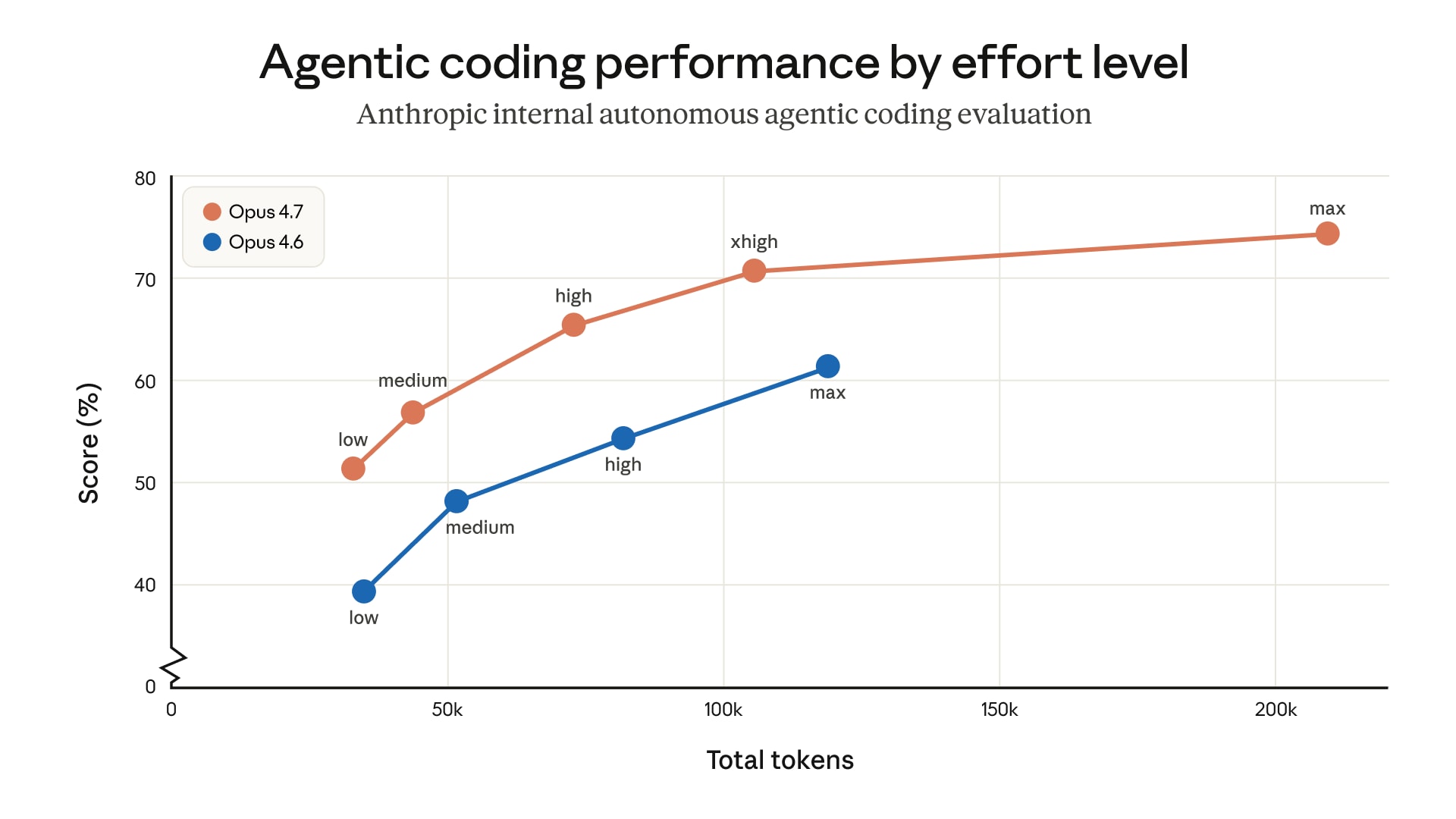
- [18] I Tested All 5 Effort Levels of Claude Opus 4.7 on the Same 12 Coding ...pub.towardsai.net
I Tested All 5 Effort Levels of Claude Opus 4.7 on the Same 12 Coding Problems — The 'Max' Setting Is a Trap (And 'Low' Quietly Killed Opus 4.6) | by Chew Loong Nian - AI ENGINEER | Apr, 2026 | Towards AI. Open in app. [Sign in](https://medium.com/m/signin?operation=login&redirect=https%3A%2F%2Fpub.towardsai.net%2Fi-tested-all-5-effort-levels-of-claude-opus-4-7-2f335c626786&source=post_page---top_nav_layout_nav--…
- [19] How to Use Claude Opus 4.7: Complete Guide to Anthropic's New ...tosea.ai
A practical review of Claude Opus 4.7 — Anthropic's April 2026 release with 87.6% SWE-bench Verified, 64.3% SWE-bench Pro, improved vision,
- [20] Anthropic's Claude Opus 4.7 Benchmarks and Updates | Lim.ai posted on the topic | LinkedInlinkedin.com
Tool Use: For teams building with external APIs, Opus 4.7 now leads the MCP-Atlas benchmark at 77.3%. ... At Lim.ai, the MCP-Atlas and SWE-bench
- [21] Instagraminstagram.com
Claude Opus 4.7 just went live and the benchmarks are insane: → 64.3% on SWE-bench Pro (20% jump over Opus 4.6) → 87.6% on SWE-bench Verified
- [22] GPT-5.5 is here! Available in Codex and ChatGPT todaycommunity.openai.com
GPT-5.5 is here! Available in Codex and ChatGPT today. MAN… THEY BURNED 100 BUCKS IN A MATTER OF AN HOUR… YES! and no i used not to say anything i was burning through 100 perhaps every two days, thats considerable but not insane considering the output you can generate… BUT 100 BUCKS IN AN HOUR??? | Introducing the New Codex for (almost) everything Announcements codex , codex-app | 24 | 2744 | April 23, 2026 |. | GPT-5.1-Codex-Max is now available in the API Announcements | 11 | 2877 | December 11, 2025 |. | Upgrades to Codex — gpt-5-codex Announcements codex , gpt-5-codex | 26 | 4017 | Octo…
- [23] GPT-5.5 is here! Available in Codex and ChatGPT today - Announcementscommunity.openai.com
Skip to last replySkip to top. Skip to main content.
 . * Topics. * [A…
. * Topics. * [A… - [24] Introducing GPT-5.5 - OpenAIopenai.com
OnGDPval, which tests agents’ abilities to produce well-specified knowledge work across 44 occupations, GPT‑5.5 scores 84.9%. * **We are deploying industry-leading safeguards for this level of cyber capability.**We first introduced cyber-specific safeguards with GPT‑5.2(opens in a new window) last year, which we have continued to test, refine, and build on in subsequent deployments. * **We are expanding access to accelerate cyber defense at every level.**We are making our cyber-permissive models av…
- [25] OpenAI Releases GPT-5.5, Bringing Company One Step ...ground.news
OpenAI Upgrades ChatGPT and Codex with GPT-5.5: 'a New Class of Intelligence for Real Work'. ## OpenAI says the upgrade is faster and more token-efficient, with stronger safeguards and higher benchmark scores for coding, research and other multi-step work. #### OpenAI rolls out GPT-5.5 with improved contextual understanding, Plus and up. OpenAI just announced that ChatGPT is getting a model upgrade to GPT-5.5. OpenAI's GPT-5.5 promises more intuitive, agentic performance and fewer hallucinations for business users, OpenAI says. OpenAI has officially released the upgraded version of its chat…
- [26] OpenAI Releases GPT-5.5: Faster, Smarter—And Pricier - Yahoo Techtech.yahoo.com
- Best AirPods. + Best budget headphones. + Best soundbar of 2026. + Best headphones. + Best cheap wireless earbuds. + Best outdoor speakers. + [Best wireless…
- [27] Introducing GPT-5.5: OpenAI's New Class of Intelligence for Real ...kingy.ai
This article unpacks everything OpenAI shared about GPT-5.5 and its bigger sibling GPT-5.5 Pro: the capabilities, the benchmarks, the real-world use cases from early testers, the new inference efficiency breakthroughs, the cybersecurity safeguards, and what the availability and pricing look like for developers and ChatGPT subscribers alike. OpenAI says this efficiency is a “game-changer” for GPT-5.5 Pro — a model that was previously impractical for many demanding tasks because of its latency profile, but is now genuinely usable day-to-day. On BixBench, a benchmark built around real-world…
- [28] OpenAI Unveils GPT-5.5: The Dawn of Real-Time Reasoning | atal upadhyayatalupadhyay.wordpress.com
GPT-5.5 introduces a groundbreaking new capability: Real-Time Reasoning. This feature promises to pull back the curtain on AI's “thought process
- [29] Introducing GPT-5.5—a new class of intelligence for real work.instagram.com
 . [![Image 6: saas.mot…
. [![Image 6: saas.mot… - [30] Model Drop: GPT-5.5 - by Jake Handyhandyai.substack.com
 . #
. #  . [!…
. [!… - [31] OpenAI GPT-5.5 Leaked: Super Powerful AI Model! Beats Opus 4.7 ...youtube.com
- [32] GPT-5.5: The First AI That Never Forgets | by Marvis Bills | Mediummedium.com
OpenAI's newest model doubles its memory, sharpens its reasoning, and moves us one step closer to truly persistent AI assistants.
- [33] Introducing GPT-5.5 - YouTubeyoutube.com
Introducing GPT-5.5 A new class of intelligence for real work and ... Introducing GPT-5.5. 128K views · 6 hours ago ...more. OpenAI. 1.94M.